- The paper introduces MMOA-RAG, modeling retrieval-augmented generation as a multi-agent RL task to optimize system performance and F1 scores.
- It employs Multi-Agent Proximal Policy Optimization to jointly train the Query Rewriter, Selector, and Generator for cohesive system improvement.
- Experiments demonstrate significant performance gains over state-of-the-art methods, underscoring the efficacy of cooperative multi-agent training.
Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning
This essay examines the implementation of a multi-agent reinforcement learning (MARL) approach to enhance Retrieval-Augmented Generation (RAG) systems. The paper introduces a novel framework termed MMOA-RAG which models the RAG process as a multi-agent task, optimizing individual modules as reinforcement learning (RL) agents aiming for a shared reward goal, such as maximizing F1 score. Below, we detail the core components and the implementation process, highlight experiments, and assess the implications of the study.
Framework and Methodology
Multi-Module Joint Optimization Algorithm (MMOA-RAG)
MMOA-RAG aims to harmonize the entire RAG pipeline by viewing each component as a distinct RL agent under the cooperative multi-agent reinforcement learning (Co-MARL) paradigm. This strategy varies from existing singularly-focused approaches by optimizing the system collectively to overcome the limitations of independently polished modules.
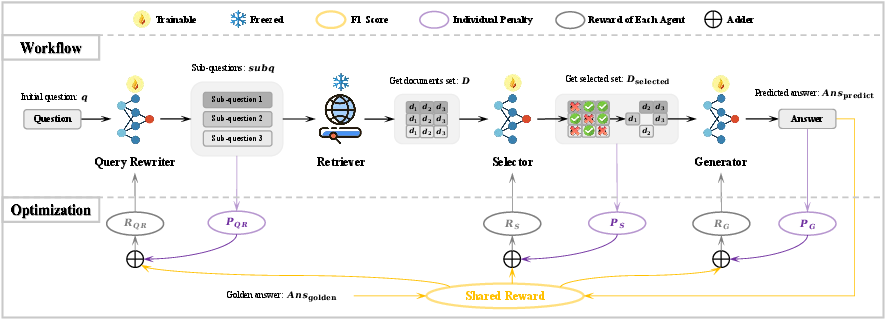
Figure 1: The overall framework of MMOA-RAG.
In MMOA-RAG, the individual components are:
- Query Rewriter (QR): Reformulates complex or ambiguous queries into manageable sub-questions to allow effective document retrieval.
- Selector (S): Further refines retrieved documents, selecting a pertinent subset to underpin superior answer generation.
- Generator (G): Produces final answers based on the selected subset of documents.
Multi-Agent PPO Implementation
To enable joint optimization, a Multi-Agent Proximal Policy Optimization (MAPPO) approach is adopted. This extends the classic PPO to enable shared reward scenarios in a multi-agent environment, supporting alignment toward a singular objective of generating higher-quality answers.
Key elements of the framework are:
- Observation, Action, and Reward: Each agent, QR, S, and G operates with defined observations, action spaces, and reward functions that encapsulate the collective and individual goals.
- Shared and Penalty-based Rewards: Alongside the overall performance metric as a shared reward (Rshared), specific penalties are encoded to curb inefficiencies such as excessive question division by QR or format violations in S's actions.
Training and Optimization
The training process includes an initial supervised fine-tuning (SFT) phase for a warm start, enabling the LLM to adeptly follow instructions. Next, the MAPPO framework orchestrates multi-agent optimization, leveraging the alignment of agent objectives through reward sharing and constraint-based penalties.
Experiments and Results
Comprehensive testing across datasets such as HotpotQA and AmbigQA showcased significant performance improvements upon application of MMOA-RAG compared to state-of-the-art RAG methodologies. The observed gains—exceeding previous baselines—affirm the effectiveness of multi-agent cooperation in RAG systems.
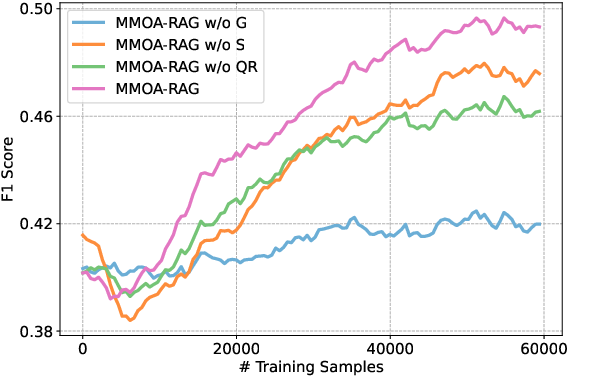
Ablation Studies
Implications and Future Work
The introduction of multi-agent strategies in RAG systems presents tangible advancements in generative accuracy and efficiency. By enabling modules to act as cooperative agents, MMOA-RAG offers a blueprint for optimizing complex AI tasks requiring granular interaction between components.
Future endeavors could explore the application of such frameworks across diverse domains and their adaptability in dynamically changing environments, further refining RAG pipelines and extending their robust capabilities for real-world applications. Additionally, the potential for leveraging different architectures and reward-structures can provide deeper insights into enhanced collaborative dynamics among AI systems.