Jasmine: A Simple, Performant and Scalable JAX-based World Modeling Codebase
Abstract: While world models are increasingly positioned as a pathway to overcoming data scarcity in domains such as robotics, open training infrastructure for world modeling remains nascent. We introduce Jasmine, a performant JAX-based world modeling codebase that scales from single hosts to hundreds of accelerators with minimal code changes. Jasmine achieves an order-of-magnitude faster reproduction of the CoinRun case study compared to prior open implementations, enabled by performance optimizations across data loading, training and checkpointing. The codebase guarantees fully reproducible training and supports diverse sharding configurations. By pairing Jasmine with curated large-scale datasets, we establish infrastructure for rigorous benchmarking pipelines across model families and architectural ablations.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces Jasmine, a fast and easy-to-scale software “toolkit” that helps researchers build and train world models. A world model is an AI that learns how a world (like a video game level or a robot’s surroundings) changes over time, so you can practice or test actions inside that “learned” world instead of the real one.
The big idea: make it simple and quick for anyone to train these models—from one computer to hundreds—while being fully reproducible, so results are trustworthy and easy to compare.
The main goals and questions
The authors set out to:
- Build a simple, high-performance, open-source codebase (Jasmine) for world modeling using JAX (a fast machine learning library).
- Reproduce a known case study (“CoinRun,” a simple platformer game used in research) much faster than previous open tools.
- Test and clarify a small but important design choice in the model—how to feed “actions” into the model—so the model’s generated videos match the game better.
- Provide everything needed for fair, repeatable experiments: code, training settings, checkpoints, datasets, and even a unique dataset of months of coding activity for future research.
How Jasmine works (in plain language)
Think of a world model like a very smart video-game replay and prediction system:
- It watches short clips (frames) of a game.
- It learns the “actions” that cause changes between frames (like jump, move left, etc.), even when those actions aren’t labeled.
- It then predicts the next frames based on past frames and the actions.
Here are the main pieces, with simple analogies:
- Video tokenizer (VQ-VAE): This turns each image frame into a small set of “tokens,” like turning a photo into a small bag of Lego pieces that still captures the important visual details.
- Latent Action Model (LAM): This discovers “hidden” actions from video by compressing the change between frames into a small code (like guessing the button pressed from seeing how the character moves).
- Dynamics model (Transformer): This predicts the next tokens (the next frame) from previous tokens and actions—like a storyteller who continues a comic strip after seeing the last few panels and the chosen move.
During training, the model learns by filling in missing pieces (a “mask and guess” game, similar to how some LLMs learn by predicting missing words). During sampling (generation), the model uses user-supplied actions to produce the next frames.
Behind the scenes, Jasmine adds lots of speed and reliability features:
- Fast data loading and storage formats to keep the GPUs busy (like laying out parts on a workbench so you don’t waste time searching).
- Mixed-precision math and optimized attention (FlashAttention) to crunch numbers faster without losing important accuracy.
- Support to run on many machines and chips with minimal code changes.
- Bitwise-deterministic training: if you use the same seed and setup, you get exactly the same results, which is great for science.
What they tested and found
They focused on the CoinRun case study to compare with prior work:
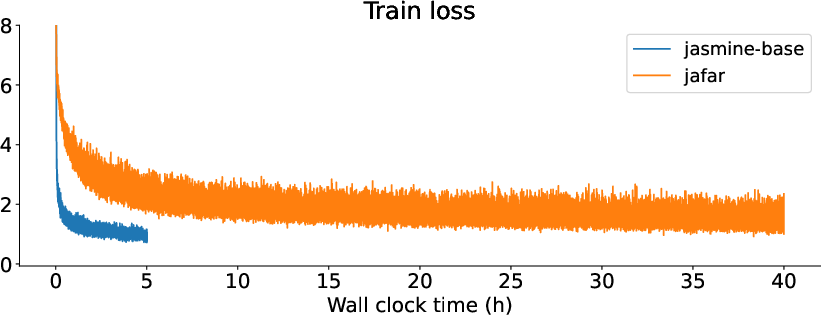
- Speed: Jasmine reproduces the CoinRun setup about 10× faster than a previous open implementation (called Jafar). For example, a training that used to take over 100 hours can now finish in under 9 hours on a single GPU in a similar setting.
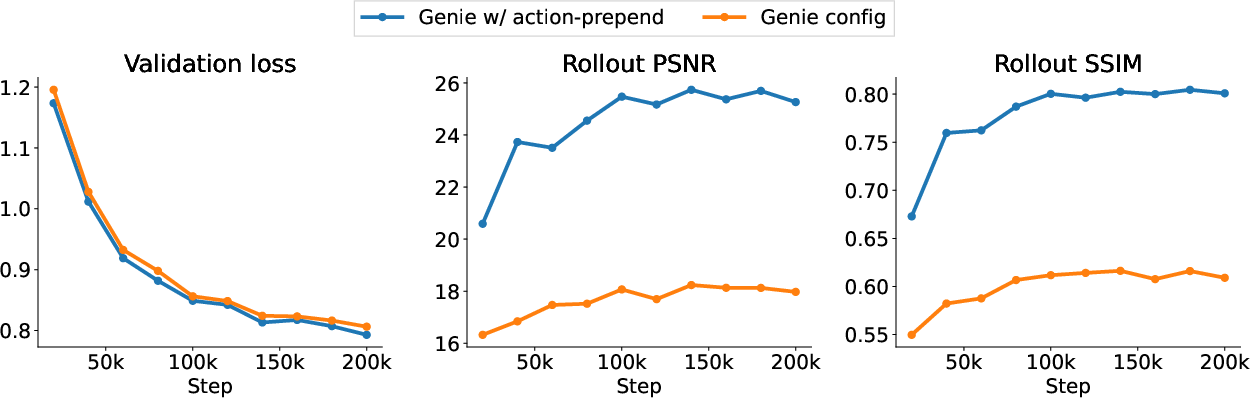
- A small but key model tweak: Instead of “adding” the action information into the video tokens, they “prepend” it (place it in front). This simple change made the generated videos match the real game behavior much better during long rollouts.
- Architecture experiments:
- Using standard good practices from LLMs (like a larger feedforward part but fewer layers) kept quality while improving speed.
- A diffusion-based variant (“diffusion forcing”) sometimes beat the default masking approach even without heavy tuning.
- A fully causal baseline (a different prediction style) lagged behind in short training but might catch up with more training time.
- Infrastructure matters a lot: The biggest speedups came from better data loading, modern attention kernels (FlashAttention), and mixed precision. Together, these make a huge difference in wall-clock time.
Why this matters
- Faster experiments: Researchers can try more ideas in less time, which speeds up progress.
- Fair comparisons: Fully reproducible training and standardized datasets make it easier to trust and compare results.
- Better world models: The action “prepend” trick and other findings help make generated worlds more faithful to reality.
- Broader impact: World models can help in areas like robotics, where collecting real-world data is expensive or risky. If you can learn a good “simulated world” from videos, you can train agents more safely and cheaply.
What this could lead to
- A stronger open ecosystem for world modeling, similar to what already exists for LLMs.
- More reliable benchmarks across different model styles (masking, diffusion, causal).
- Practical tools for training agents inside learned worlds, potentially reducing the need for massive real-world data collection.
- New research directions using the released code, datasets, checkpoints, and a rare dataset of months of coding activity for studying how to train AI to assist with software development.
In short, Jasmine is like handing the community a well-tuned racing car and a safe, repeatable track: it lets researchers go faster, compare fairly, and explore further in building smart, useful world models.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future work.
- Generality of the “prepend latent actions” modification is untested beyond CoinRun; evaluate whether concatenation vs addition (and other conditioning mechanisms like cross-attention) consistently improves fidelity across diverse environments (Atari, Doom, robotics) and resolutions.
- Ambiguity in extending MaskGIT to videos remains unresolved; formalize the design space (mask schedules, token ordering, temporal masking strategies) and run systematic ablations to identify a principled, reproducible formulation.
- Long-horizon fidelity is not quantified; measure compounding error over much longer horizons (≫16 frames) using standardized metrics (e.g., FVD, LPIPS, dynamics consistency, controllability accuracy), and release evaluation scripts.
- No agent-in-the-loop results; demonstrate training and evaluating agents inside the learned world model, quantify transfer to real or original environments, and study how agent performance scales with model capacity, data size, and horizon length.
- Unlabeled video learning is not validated end-to-end; show that LAM can learn actionable, controllable latents from genuinely unlabeled videos (without ground-truth actions) and that user inputs reliably steer dynamics.
- Latent action interpretability and consistency are unexamined; analyze whether LAM codebook entries align with semantic actions, are stable across environments, and support compositionality and generalization.
- Architectural alternatives to ST-Transformer are not explored; compare full attention, ViViT, hybrid CNN–Transformer, and hierarchical temporal models for throughput–quality trade-offs.
- Diffusion-based baselines are under-tuned and not assessed for interactive control; rigorously tune diffusion-forcing and other diffusion models, evaluate controllability latency, sample efficiency, and long-horizon stability under matched budgets.
- Scaling claims (single host to hundreds of accelerators) lack empirical scaling curves; provide strong/weak scaling results, efficiency vs cluster size, communication overhead, and bottleneck analyses under different sharding strategies.
- Determinism guarantees are not validated across heterogeneous settings; test bitwise determinism across different accelerator types (GPU vs TPU), driver versions, multi-host configurations, and XLA variants; document nondeterminism sources and mitigations.
- Data pipeline generality is untested; compare ArrayRecord+Grain to TFRecord, WebDataset, and streaming from remote storage (object stores/NFS), stress-test under network variance, and quantify throughput–latency trade-offs.
- Checkpointing robustness and elasticity are not studied; evaluate failure recovery, host elasticity (adding/removing workers), correctness of LR schedule resumption, and determinism of dataloader states after restarts.
- Inference latency for interactive use is not reported; benchmark per-frame generation latency under user control, GPU utilization, and memory footprint, and identify optimization levers to reach real-time responsiveness.
- Evaluation metrics are not standardized; define and adopt a consistent metric suite that correlates with rollout quality and agent success (FVD, LPIPS, dynamics consistency, action-condition accuracy), and ensure comparability across baselines.
- Dataset coverage is limited by random-policy collection; assess the impact of exploration-driven or curriculum-guided data on model coverage of rare events and downstream agent success.
- OOD generalization is not analyzed; measure performance on unseen seeds, difficulty modes, altered physics, and environment variations to identify failure modes and robustness gaps.
- Resolution, patch size, and sequence length scaling are not systematically studied; map quality and throughput as resolution and horizon increase, identify memory/IO bottlenecks, and propose remedies (e.g., hierarchical tokenization).
- Co-training vs pre-training ambiguity persists; provide a clear co-training loss formulation (including gradient flow/stop-gradients), and quantify memory, speed, and quality impacts vs sequential training.
- Ground-truth action conditioning utility is context-dependent; determine when explicit actions outperform latent actions, explore hybrid conditioning (explicit+latent), and address settings without action labels.
- Sharding best practices are unspecified; benchmark data-, model-, and pipeline-parallel sharding with Shardy, document auto-partitioning behavior, failure cases, and tuning guidelines.
- Effects of FlashAttention and bf16 on stability/quality are not quantified; analyze numerical stability, gradient noise, and convergence impacts across sequence lengths and attention variants; provide practical guardrails.
- Tokenizer design space is only partially ablated; vary VQ-VAE codebook sizes, commitment/reconstruction losses, and patch sizes; compare to alternative tokenizers (e.g., MAE, DALL·E) and report reconstruction vs dynamics trade-offs.
- Mask schedules for video MaskGIT are underspecified; systematically explore masking distributions and curricula (per-frame vs per-token; rising/falling schedules) and their effect on temporal dependency learning.
- Mentioned datasets/checkpoints (Atari, Doom) lack corresponding benchmarks; add cross-environment evaluations to substantiate generality claims and enable fair comparison to prior work.
- Safety and ethical considerations are absent; address potential misuse of interactive world models, dataset licenses, and propose alignment/verification strategies for agent training in learned environments.
- IDE interaction dataset utility is unclear; detail privacy safeguards, intended tasks, and provide baselines demonstrating usefulness for code agents (e.g., behavior cloning, goal conditioning, verification signal mining).
Practical Applications
Immediate Applications
The following applications can be deployed today using Jasmine’s open-source codebase, released datasets, and engineering practices documented in the paper.
Industry
- World-model training platform for simulation R&D (software, robotics, gaming)
- Use Jasmine as a performant, reproducible training stack to prototype and benchmark world models from unlabeled video (e.g., internal “Genie-like” models).
- Sectors: software, robotics, gaming, autonomous systems.
- Tools/workflows: ArrayRecord-based data curation; Grain data loader with process-parallel prefetch; VQ-VAE tokenizer training; latent action modeling; ST-Transformer dynamics; evaluation via rollout metrics; Orbax checkpointing; mixed precision + cuDNN SDPA FlashAttention; Shardy-based sharding configs.
- Assumptions/dependencies: JAX/XLA-capable accelerators (NVIDIA/TPU), cuDNN SDPA availability, stable storage throughput for ArrayRecord, operator familiarity with JAX stack.
- Rapid prototyping of interactive environments from video for content teams
- Convert gameplay or UI recordings into controllable, interactive sequences for design iteration or previsualization.
- Sectors: gaming, media, UX prototyping.
- Tools/products: internal “video-to-interactive” prototyping tool built on Jasmine’s tokenizer + dynamics; simple interface to inject actions at sampling time (using the paper’s prepend-actions fix).
- Assumptions/dependencies: Visual domains similar to CoinRun/Atari/Doom perform best; fidelity and long-horizon stability remain limited.
- Cost- and time-efficient benchmarking of world-model architectures
- Run ablations (MaskGIT vs fully causal vs diffusion forcing) and training schedules (WSD) with bitwise-deterministic runs for fair comparisons.
- Sectors: software, model platform teams, cloud/HPC vendors.
- Tools/workflows: standardized ablation harness; deterministic seeds; automated regression checks on rollout metrics; infra flags for FlashAttention, activation checkpointing.
- Assumptions/dependencies: Reproducibility still requires careful handling of seeds, XLA versions, and input pipelines.
- MLOps reference implementation for deterministic large-scale training
- Adopt Jasmine’s bitwise determinism, distributed checkpointing, and sharding patterns as internal templates for other model families.
- Sectors: software platforms, cloud MLOps.
- Tools/workflows: “deterministic training recipe” (Orbax checkpointing of model/optimizer/dataloader states, ArrayRecord index-shuffling, seed control); Shardy templates for scaling to hundreds of accelerators.
- Assumptions/dependencies: Some determinism can be sensitive to library versions, kernels, and hardware; verification needed per environment.
- Data pipeline upgrade: ArrayRecord + Grain for video-scale IO
- Replace ad-hoc TFRecord/ZIP pipelines with ArrayRecord + Grain for random-access video tokenization and high-throughput training.
- Sectors: software, media, robotics.
- Tools/workflows: preprocessing scripts to shard/pack arrays; process-parallel data loading; chunking strategies verified by the paper’s throughput ablations.
- Assumptions/dependencies: Storage layout and chunk sizes must be tuned to workload; index-shuffling requires enough RAM/IO bandwidth.
- Code intelligence R&D using the released dense IDE interaction dataset
- Train behavioral cloning or goal-conditioned models for coding agents using months-long, high-resolution IDE telemetry captured during Jasmine’s development.
- Sectors: software tooling, AI coding assistants.
- Tools/products: pretraining datasets for cursor-level modeling; evaluation setups for long-horizon code-edit rollouts.
- Assumptions/dependencies: Strong privacy/governance practices; domain shift to other orgs’ workflows; license compliance and filtering for sensitive content.
Academia
- Reproducible baseline for world modeling courses and labs
- Teach VQ-VAE tokenization, latent action modeling, and video MaskGIT/diffusion baselines with a codebase that runs on a single GPU in hours.
- Tools/workflows: “lab-in-a-box” notebooks for tokenizer/LAM/dynamics; rollout metric dashboards; duplication detection scripts.
- Assumptions/dependencies: GPU access; familiarity with JAX; small visual benchmarks (CoinRun/Atari) fit academic budgets.
- Fair architecture/scaling studies with bitwise determinism
- Perform controlled studies on compounding error, masking schemes, action conditioning (prepend vs add), and scaling laws for world models.
- Tools/workflows: seed-controlled ablation grids, checkpoint rewind to WSD warmup points, standardized rollout metrics.
- Assumptions/dependencies: Results may be domain-dependent (e.g., action-prepending may not generalize across all datasets).
Policy
- Reproducibility standards and benchmarks for simulator-like models
- Use Jasmine as an exemplar of bitwise-deterministic training, transparent data pipelines, and checkpointing standards in grant calls or evaluation protocols.
- Tools/workflows: standardized checklists for deterministic runs; artifact release templates (code, seeds, checkpoints, data manifest).
- Assumptions/dependencies: Determinism can be brittle across hardware stacks; policy guidelines should include allowed variance envelopes.
Daily Life and Open-Source Community
- Single-GPU learning and tinkering
- Hobbyists can reproduce a modern world-model case study in under a day and explore architectural changes.
- Tools/workflows: minimal configs for 64×64, short-horizon settings; community forks for new environments.
- Assumptions/dependencies: Requires a single recent GPU with enough VRAM; reduced-fidelity domains.
Long-Term Applications
These rely on further research, scaling, and fidelity improvements—especially to reduce compounding error over long horizons and to generalize beyond small video benchmarks.
Industry
- Simulation-as-a-service using learned world models
- Offer fast, customizable simulators for training and evaluating agents (RL, planning) in domains where traditional simulators are expensive or unavailable.
- Sectors: robotics, autonomous driving, logistics, gaming, AR/VR.
- Potential products: cloud-hosted “learned simulator” endpoints; curriculum generation and domain randomization pipelines.
- Assumptions/dependencies: High-fidelity long-horizon accuracy; robust safety constraints; coverage of edge cases; strong evaluation protocols.
- Data-efficient robotics training and sim-to-real transfer
- Use video-based world models trained from lab/field footage to pretrain policies and reduce real-world trial costs.
- Sectors: robotics, manufacturing, warehousing.
- Workflows: collect unlabeled robot video; learn latent action spaces; co-train dynamics; fine-tune policies in the learned simulator before real deployment.
- Assumptions/dependencies: Reduction of sim-to-real gap; sensor/actuator modeling; faithful dynamics and contact modeling; safety validation.
- Digital twins for operations and predictive maintenance
- Learn environment dynamics directly from operational video streams to simulate rare events, test interventions, and optimize schedules.
- Sectors: energy, industrial automation, smart buildings.
- Products: video-driven digital twin modules; “what-if” scenario generators guided by latent actions.
- Assumptions/dependencies: Integration with telemetry beyond video (multimodal); domain adaptation; regulatory approvals.
- Generative interactive engines for content creation
- Move toward real-time, controllable video/game engines powered by diffusion-forcing or next-generation world models.
- Sectors: gaming, film/TV, advertising.
- Products: “Genie-like” engines for previsualization and interactive storytelling; toolchains for action-conditioned scene editing.
- Assumptions/dependencies: Efficient high-resolution, long-horizon generation; controllability and consistency; IP/licensing for training data.
Academia
- Scaling laws and generalization studies for world models
- Systematic investigations of data/compute trade-offs, compounding error, and curriculum design across diverse domains (beyond CoinRun/Atari).
- Workflows: multi-domain datasets; unified rollout metrics; cross-architecture comparisons (MaskGIT, causal, diffusion).
- Assumptions/dependencies: Access to large curated datasets; harmonized metrics; community adoption of standards.
- From latent actions to interpretable control abstractions
- Study whether learned latent actions align with human/robot affordances and can be grounded in symbolic or task-level planning.
- Workflows: probing/interpretability toolkits; goal-conditioned evaluation; causal intervention testing.
- Assumptions/dependencies: Progress in mechanistic interpretability for video/sequence models; robust probing methodologies.
- Long-horizon code-agent research using dense IDE telemetry
- Train multi-hour, session-level coding agents that plan, reflect, and correct over extended horizons.
- Workflows: hierarchical sequence modeling; verification-signal mining; goal-conditioned behavior cloning.
- Assumptions/dependencies: Privacy-preserving data collection at scale; generalization across organizations/tools; safe deployment policies.
Policy
- Evaluation sandboxes for AI agents in learned simulators
- Establish standardized testbeds to probe safety, robustness, and alignment before real-world deployment (e.g., AV/robotic policies).
- Workflows: regulator-approved scenario suites; reproducible seeds; adverse event replay; transparent audit logs.
- Assumptions/dependencies: Trustworthy fidelity metrics; governance for training data (bias, IP); auditability of learned simulators.
- Data governance for developer telemetry and video-derived training
- Define norms for collecting IDE interactions and operational video for model training (consent, minimization, retention, redaction).
- Assumptions/dependencies: Legal harmonization (IP, privacy); reproducible redaction/traceability pipelines; stakeholder buy-in.
Daily Life
- Personalized training simulators from personal recordings
- Generate practice environments for driving, sports, or craft skills, tailored to a user’s own videos and actions.
- Assumptions/dependencies: On-device/private training flows; domain-specific safety constraints; robustness across user devices.
- On-device AR/VR assistants with predictive scene models
- Low-latency, action-aware scene prediction to assist navigation or task completion.
- Assumptions/dependencies: Efficient, small-footprint world models; hardware acceleration; strong privacy guarantees.
Cross-cutting assumptions and risks (impacting feasibility)
- Model fidelity and compounding error: Long-horizon stability and causal faithfulness remain active research challenges.
- Domain shift and generalization: Findings (e.g., action-prepending) may be environment-specific; validation across domains is needed.
- Compute and memory: High-resolution, long-context models require substantial accelerators and IO bandwidth.
- Safety and governance: Learned simulators must not mask hazards or produce misleading confidence; IDE data requires strict privacy/IP controls.
- Ecosystem dependencies: JAX/XLA/cuDNN features and versions affect determinism and performance; reproducibility should be verified per stack.
Glossary
- Activation checkpointing: A memory-saving technique that recomputes certain activations during backpropagation instead of storing them. Example: "To enable efficient large-scale experimentation, Jasmine integrates mixed-precision, FlashAttention via cuDNN SDPA \citep{NVIDIA_cuDNN_Attention}, activation checkpointing, host memory offloading, and index-shuffling during data loading."
- ArrayRecords: A file format optimized for efficient random-access storage of arrays used for dataset IO. Example: "We use Grain for data loading with prefetching enabled and preprocess datasets into ArrayRecords \citep{ArrayRecord}, a file format optimized for random access indexing."
- Asynchronous distributed checkpointing: Saving model and training state across multiple processes/devices without pausing training. Example: "It provides asynchronous distributed checkpointing with configurable policies, process-parallel dataloading, and checkpointing of model, optimizer, and data loader states."
- Autoregressive sampling: Generating sequences step-by-step where each step conditions on previous outputs. Example: "Autoregressive sampling of Jafar \citep{willi2024jafar} (middle row) and Jasmine (bottom row) on the CoinRun case study with four conditioning frames (conditioning frames not shown)."
- bfloat16: A 16-bit floating-point format that preserves exponent range of FP32, commonly used to speed up training with minimal accuracy loss. Example: "Jasmine further leverages FlashAttention \citep{dao2022flashattention} via cuDNN SDPA \citep{NVIDIA_cuDNN_Attention} and mixed precision training with bfloat16."
- Bitwise deterministic: Producing exactly identical numerical results (bit-for-bit) when run with the same seeds and configuration. Example: "Training runs are bitwise deterministic, yielding identical loss curves under identical seeds (Appendix \ref{sec:bitwise_deterministic})."
- Commitment losses: Loss terms in VQ-VAE encouraging encoder outputs to commit to discrete codebook entries. Example: "The tokenizer uses a VQ-VAE \citep{van2017neural} to encode image patches using reconstruction, vector-quantization, and commitment losses."
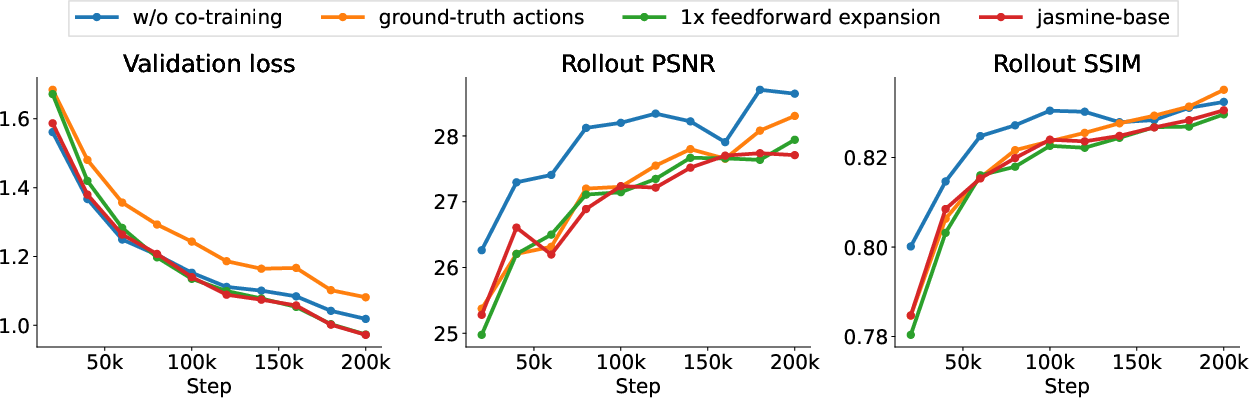
- Co-training: Jointly training multiple components (e.g., LAM and dynamics model) in one optimization process. Example: "We further compare co-training LAM and dynamics model (as done in \citet{bruce2024genie}) with pre-training the LAM (as done in \citet{willi2024jafar}), embedding ground-truth actions instead of using the latent action model (Appendix \ref{sec:ablation-gt}), and replacing MaskGIT with fully causal and diffusion baselines."
- cuDNN SDPA: NVIDIA’s cuDNN implementation of Scaled Dot-Product Attention for accelerated attention operations. Example: "Jasmine further leverages FlashAttention \citep{dao2022flashattention} via cuDNN SDPA \citep{NVIDIA_cuDNN_Attention} and mixed precision training with bfloat16."
- Decoder-only transformer: A transformer architecture using only decoder blocks, typically for autoregressive generation. Example: "The dynamics model is a decoder-only transformer that predicts future frames conditioned on past frames and corresponding latent actions."
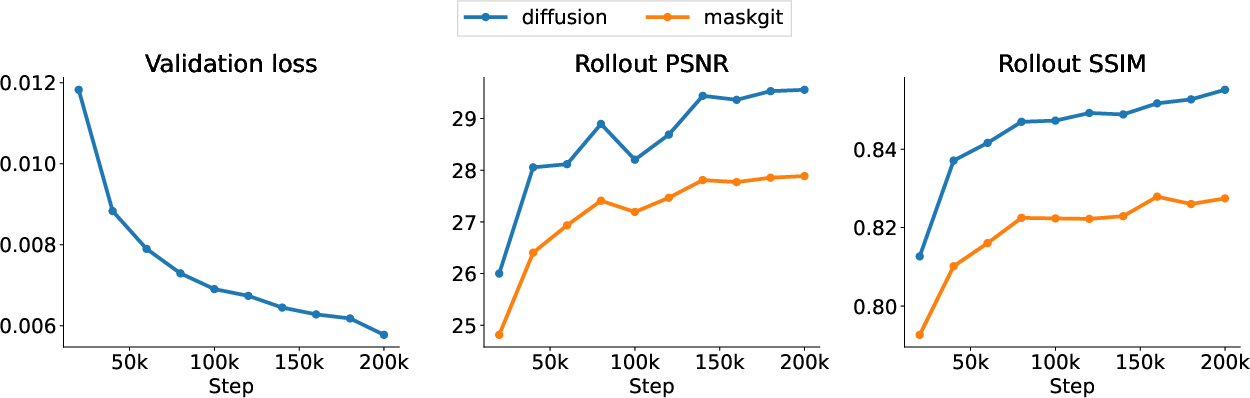
- Diffusion-forcing: A training strategy combining next-token prediction with sequence-level diffusion objectives. Example: "Diffusion-forcing \citep{chen2024diffusion} outperforms MaskGIT, even when using identical per-frame sampling step counts and untuned hyperparameters (Figure \ref{fig:diffusion-plot}, Appendix \ref{sec:diffusion-baseline})."
- Dynamics model: The component that predicts future states/frames given past context and actions. Example: "The dynamics model is a decoder-only transformer that predicts future frames conditioned on past frames and corresponding latent actions."
- Feedforward expansion factor: The multiple by which the hidden dimension in transformer feedforward layers exceeds the model dimension. Example: "Specifically, we use a feedforward expansion factor of four relative to the model dimension, following common practice in large-scale language modeling \citep{raffel2020exploring,radford2019language,brown2020language}."
- FlashAttention: A memory- and IO-efficient exact attention algorithm that accelerates transformer attention. Example: "Jasmine further leverages FlashAttention \citep{dao2022flashattention} via cuDNN SDPA \citep{NVIDIA_cuDNN_Attention} and mixed precision training with bfloat16."
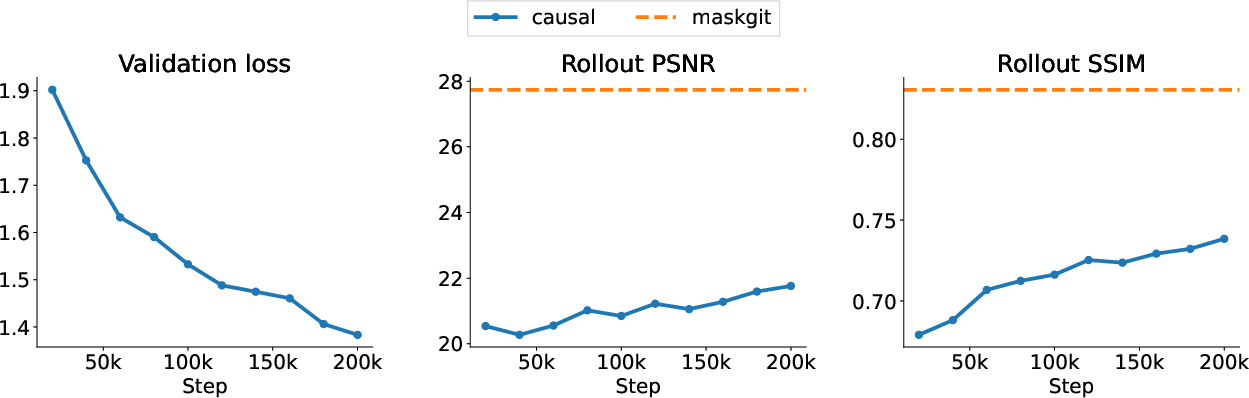
- Fully causal baseline: A baseline model that uses only causal (unidirectional) attention for generation. Example: "Co-training, pre-training the LAM, and using ground-truth actions are all competitive (Figure \ref{fig:arch-ablations}), while the fully causal baseline underperforms in the 200k steps training regime (\Cref{fig:causal-ablations})."
- Grain: A JAX-friendly data loading library supporting prefetching and efficient pipelines. Example: "We use Grain for data loading with prefetching enabled and preprocess datasets into ArrayRecords \citep{ArrayRecord}, a file format optimized for random access indexing."
- Host memory offloading: Moving tensors/activations to host (CPU) memory to reduce device memory pressure. Example: "To enable efficient large-scale experimentation, Jasmine integrates mixed-precision, FlashAttention via cuDNN SDPA \citep{NVIDIA_cuDNN_Attention}, activation checkpointing, host memory offloading, and index-shuffling during data loading."
- Index-shuffling: Randomizing dataset indices during loading to improve training stability and mixing. Example: "To enable efficient large-scale experimentation, Jasmine integrates mixed-precision, FlashAttention via cuDNN SDPA \citep{NVIDIA_cuDNN_Attention}, activation checkpointing, host memory offloading, and index-shuffling during data loading."
- JAX: A high-performance numerical computing library with composable transformations for machine learning. Example: "This speedup is the result of infrastructure optimizations, including a fully reproducible, scalable training and data pipeline built on the JAX \citep{jax2018github} ecosystem."
- Latent action model (LAM): A model that infers discrete latent actions from video frames to condition dynamics. Example: "The architecture includes a video tokenizer, which encodes videos into tokens, a latent action model (LAM) that extracts latent actions between video frames, and a dynamics model that predicts the tokens of the next frame based on the previous tokens and corresponding latent actions."
- Latent actions: Discrete or compact representations of actions learned from unlabeled video data. Example: "To train an action-conditioned video-generation model from unlabeled videos, Genie learns latent actions \citep{schmidt2023learning}."
- MaskGIT: A masked token modeling approach for generative transformers, masking inputs during training. Example: "Genie uses MaskGIT \citep{chang2022maskgit}, which masks input-tokens at training time, similar in spirit to BERT \citep{devlin2019bert}."
- Mixed-precision: Training using lower-precision datatypes to speed up computation and reduce memory use. Example: "To enable efficient large-scale experimentation, Jasmine integrates mixed-precision, FlashAttention via cuDNN SDPA \citep{NVIDIA_cuDNN_Attention}, activation checkpointing, host memory offloading, and index-shuffling during data loading."
- NNX: A JAX ecosystem library used in the codebase stack for modeling and training. Example: "The codebase depends solely on battle-tested libraries from the Google ecosystem (JAX, NNX, Grain \citep{grain2023github}, Orbax, Optax, Treescope \citep{johnson2024penzai}, ArrayRecord \citep{ArrayRecord}), and scales from single hosts to hundreds of accelerators using XLA."
- Optax: A gradient processing and optimization library for JAX. Example: "The codebase depends solely on battle-tested libraries from the Google ecosystem (JAX, NNX, Grain \citep{grain2023github}, Orbax, Optax, Treescope \citep{johnson2024penzai}, ArrayRecord \citep{ArrayRecord}), and scales from single hosts to hundreds of accelerators using XLA."
- Orbax: A checkpointing and model management library in the JAX ecosystem. Example: "The codebase depends solely on battle-tested libraries from the Google ecosystem (JAX, NNX, Grain \citep{grain2023github}, Orbax, Optax, Treescope \citep{johnson2024penzai}, ArrayRecord \citep{ArrayRecord}), and scales from single hosts to hundreds of accelerators using XLA."
- Procgen: A benchmark suite of procedurally generated RL environments. Example: "We run the reproducible case study described in \citet{bruce2024genie} by generating a dataset containing 50M transitions of CoinRun, an environment of the Procgen benchmark \citep{cobbe2019leveraging} (Appendix \ref{sec:coinrun-case-study})."
- Process-parallel dataloading: Loading data across multiple processes in parallel to improve throughput. Example: "It provides asynchronous distributed checkpointing with configurable policies, process-parallel dataloading, and checkpointing of model, optimizer, and data loader states."
- Rollout metrics: Evaluation statistics computed on model-generated sequences during environment rollouts. Example: "While the loss (left) is similar between the default Genie configuration and our minimal modification, rollout metrics (middle and right, refer to \Cref{sec:experiment-metrics}) differ substantially."
- Sharding: Partitioning tensors and computation across devices for parallelism. Example: "The codebase guarantees fully reproducible training and supports diverse sharding configurations."
- Shardy: An MLIR-based tensor partitioning system used to specify sharding patterns. Example: "Jasmine supports complex sharding configurations in a few lines of code through Shardy \citep{openxla-shardy}."
- ST-Transformer: A spatiotemporal transformer performing spatial attention within frames followed by temporal attention across frames. Example: "All modules use an ST-Transformer \citep{ho2019axial} backbone which approximates full attention by performing intra-frame (spatial) followed by inter-frame (temporal) attention, thus reducing the attention sequence length."
- Temporal causal mask: A masking scheme that prevents information flow from future to past in temporal sequences. Example: "A temporal causal mask allows the entire sequence to be processed in a single forward pass."
- Treescope: A toolkit for interpreting and visualizing models in the JAX ecosystem. Example: "The codebase depends solely on battle-tested libraries from the Google ecosystem (JAX, NNX, Grain \citep{grain2023github}, Orbax, Optax, Treescope \citep{johnson2024penzai}, ArrayRecord \citep{ArrayRecord}), and scales from single hosts to hundreds of accelerators using XLA."
- Vector-quantization: Discretizing continuous vectors into nearest entries from a learned codebook. Example: "The tokenizer uses a VQ-VAE \citep{van2017neural} to encode image patches using reconstruction, vector-quantization, and commitment losses."
- VQ-VAE: A variational autoencoder with a discrete codebook for vector-quantized latent representations. Example: "The tokenizer uses a VQ-VAE \citep{van2017neural} to encode image patches using reconstruction, vector-quantization, and commitment losses."
- Warmup-stable-decay (WSD): A learning rate schedule with a warmup, a stable phase, and a decay phase enabling flexible training length. Example: "We employ the warmup-stable-decay (WSD) learning rate schedule \citep{zhai2022scaling, mahajan2018exploring}, which allows flexible training durations by resuming from a checkpoint prior to the decay phase."
- XLA: A compiler for accelerating linear algebra that scales computation across accelerators. Example: "The codebase depends solely on battle-tested libraries from the Google ecosystem (JAX, NNX, Grain \citep{grain2023github}, Orbax, Optax, Treescope \citep{johnson2024penzai}, ArrayRecord \citep{ArrayRecord}), and scales from single hosts to hundreds of accelerators using XLA."
Collections
Sign up for free to add this paper to one or more collections.

