Robot Learning: A Tutorial
Abstract: Robot learning is at an inflection point, driven by rapid advancements in machine learning and the growing availability of large-scale robotics data. This shift from classical, model-based methods to data-driven, learning-based paradigms is unlocking unprecedented capabilities in autonomous systems. This tutorial navigates the landscape of modern robot learning, charting a course from the foundational principles of Reinforcement Learning and Behavioral Cloning to generalist, language-conditioned models capable of operating across diverse tasks and even robot embodiments. This work is intended as a guide for researchers and practitioners, and our goal is to equip the reader with the conceptual understanding and practical tools necessary to contribute to developments in robot learning, with ready-to-use examples implemented in $\texttt{lerobot}$.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is a friendly, step-by-step guide to “robot learning,” which means teaching robots to do things using data and machine learning instead of only relying on precise physics equations and hand-written rules. The authors explain why learning-based methods are becoming popular, how they work, and how to use an open-source library called LeRobot to try them yourself. They cover key ideas like Reinforcement Learning (learning by trial and error), Behavioral Cloning (copying from demonstrations), and newer “generalist” models that can follow language instructions and work across many tasks and robot types.
Key Questions and Objectives
The tutorial is built around clear, practical goals:
- How can machine learning help robots operate in the messy, real world?
- What are the limits of traditional, physics-based robotics methods?
- How do modern robot learning techniques like Reinforcement Learning (RL) and Behavioral Cloning (BC) actually work?
- How can we collect, organize, and share robot data so that many people can benefit?
- Can we train general-purpose robot models that understand language and handle multiple tasks and robot bodies?
Methods and Approach
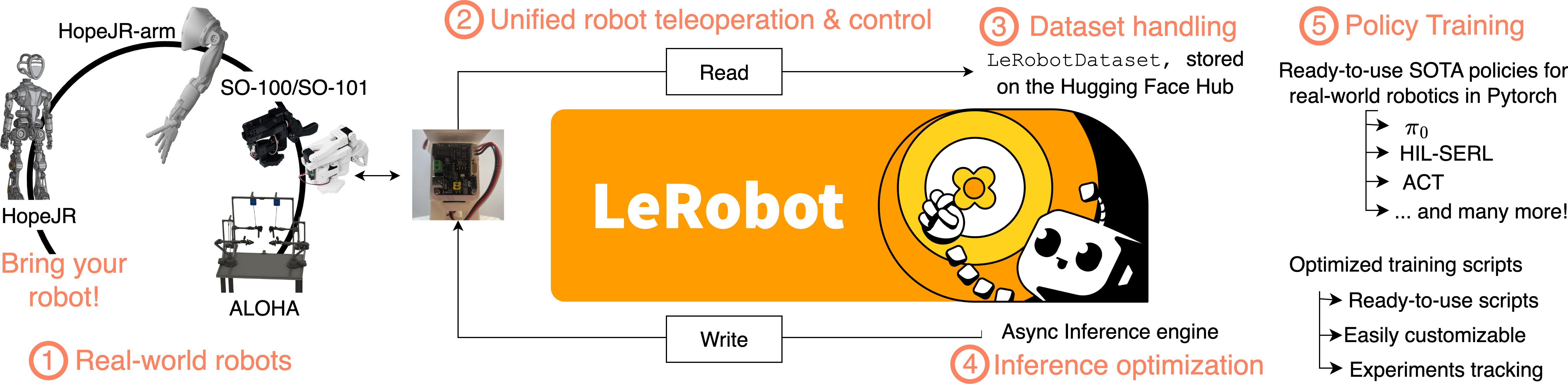
The paper teaches through explanations, simple examples, and working code using LeRobot, an open-source library by Hugging Face. Think of LeRobot as a toolkit that connects all the parts you need for robot learning: controlling real robots, handling data, and training modern machine learning policies.
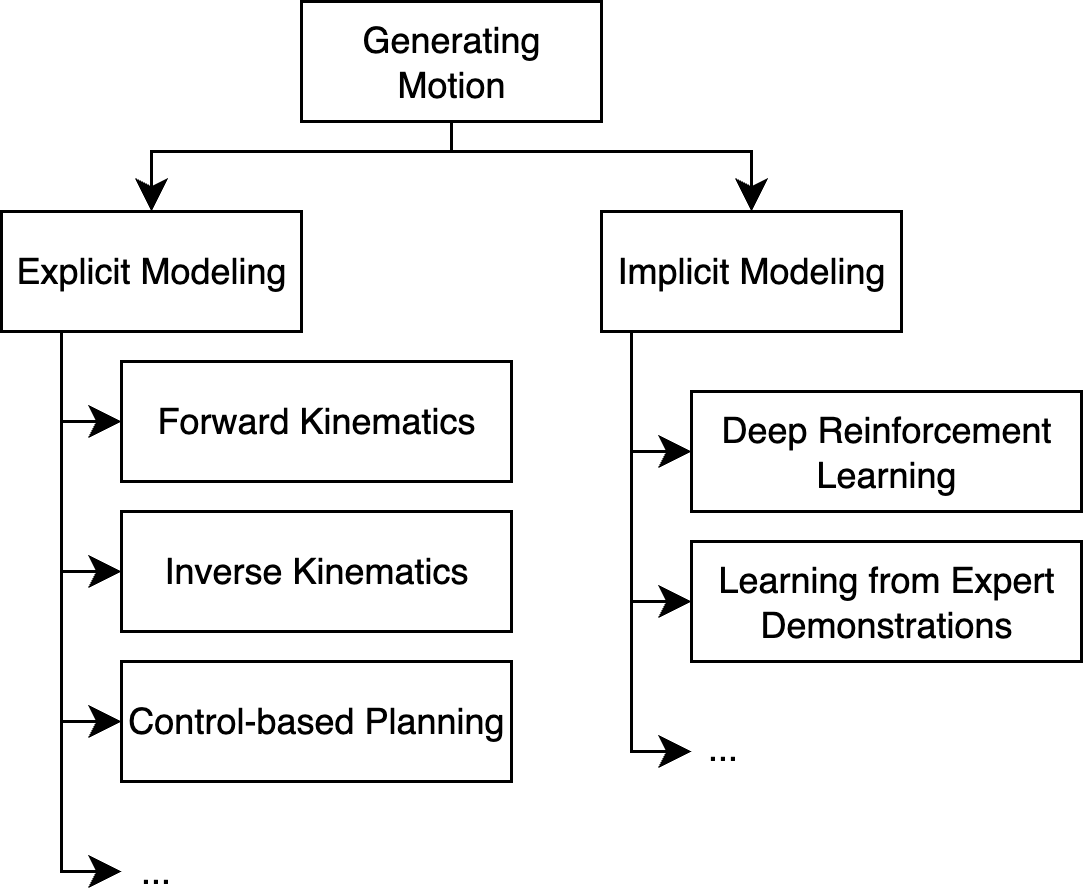
Classical Robotics vs. Learning-Based Robotics
- Classical robotics uses detailed math and physics to plan and control robot motion. For example:
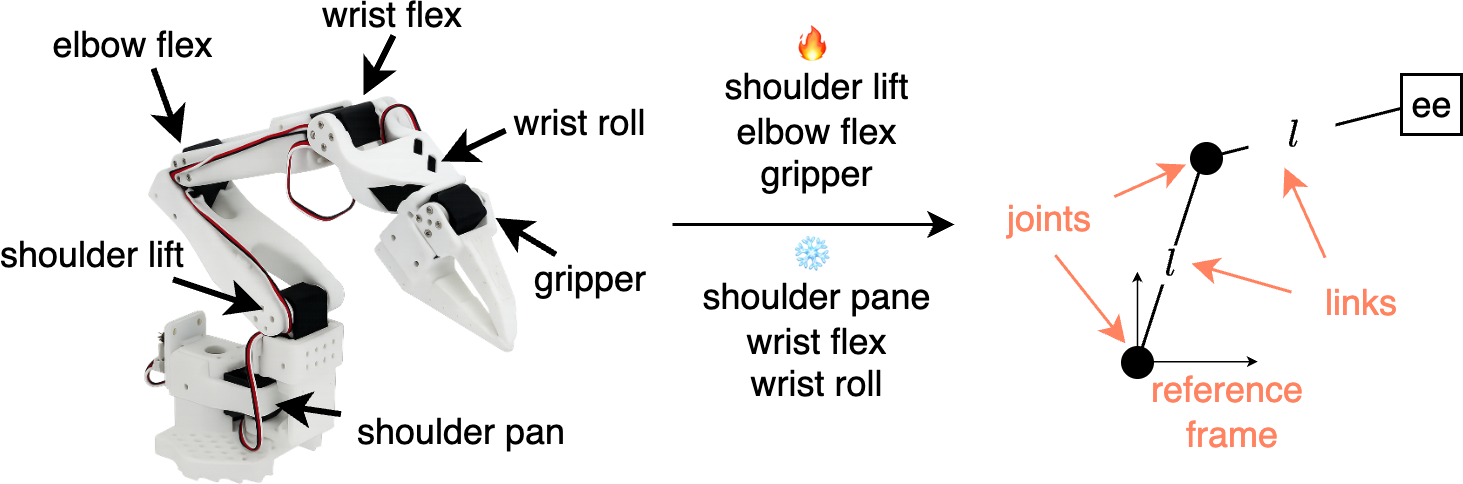
- Forward Kinematics (FK): If you know a robot’s joint angles (like your shoulder and elbow), you can calculate where its hand is.
- Inverse Kinematics (IK): If you want the hand to reach a certain spot, you figure out what angles the joints should have.
- Differential IK and feedback control: Methods that adjust joint speeds and add correction loops to track a path even if things are slightly off.
- These methods work well in neat, controlled settings, but they can be hard to scale when the environment is complicated, objects move unpredictably, or the robot faces many different tasks. They also require a lot of expert tuning.
Learning-based robotics takes a different path: instead of carefully modeling everything, it lets the robot learn patterns from data. For example:
- Reinforcement Learning: The robot tries actions, gets rewards when it does well (like scoring points for putting a block into a box), and improves over time.
- Behavioral Cloning: The robot watches demonstrations (videos, sensor data) and learns to imitate them, like copying an expert’s moves.
- Generalist models: Large models trained on many tasks and robots that can follow natural language instructions and work across different situations.
The LeRobot Library and LeRobotDataset
LeRobot helps you collect data, train policies, and run them on real robots. It supports many affordable robot platforms and integrates smoothly with PyTorch and the Hugging Face ecosystem. A key piece is LeRobotDataset, a standardized format for robot data.
To make the data easy to use and scale well, the dataset is organized into three parts:
- Tabular data: Compact, time-stamped numbers like joint angles and actions, stored efficiently.
- Visual data: Camera frames grouped into videos (MP4) so reading them is fast and friendly for large datasets.
- Metadata: JSON files that describe the dataset structure (like feature names, frame rates, episode boundaries), making it easy to reconstruct exactly what happened and when.
The dataset supports “windowing” (grabbing short time slices around a moment, like a quick memory of recent frames) and “streaming” from the cloud so you can train on massive data without downloading everything first.
Hands-On Examples
The tutorial includes code for:
- Recording datasets from a robot.
- Batching and streaming data for training, so models see well-mixed, random samples and learn faster.
It also walks through a simple “planar arm” example to explain FK/IK, obstacles, and why feedback control is needed—using plain language and diagrams rather than heavy math.
Main Findings and Why They Matter
While this is a tutorial (not a single experiment), it delivers several important takeaways:
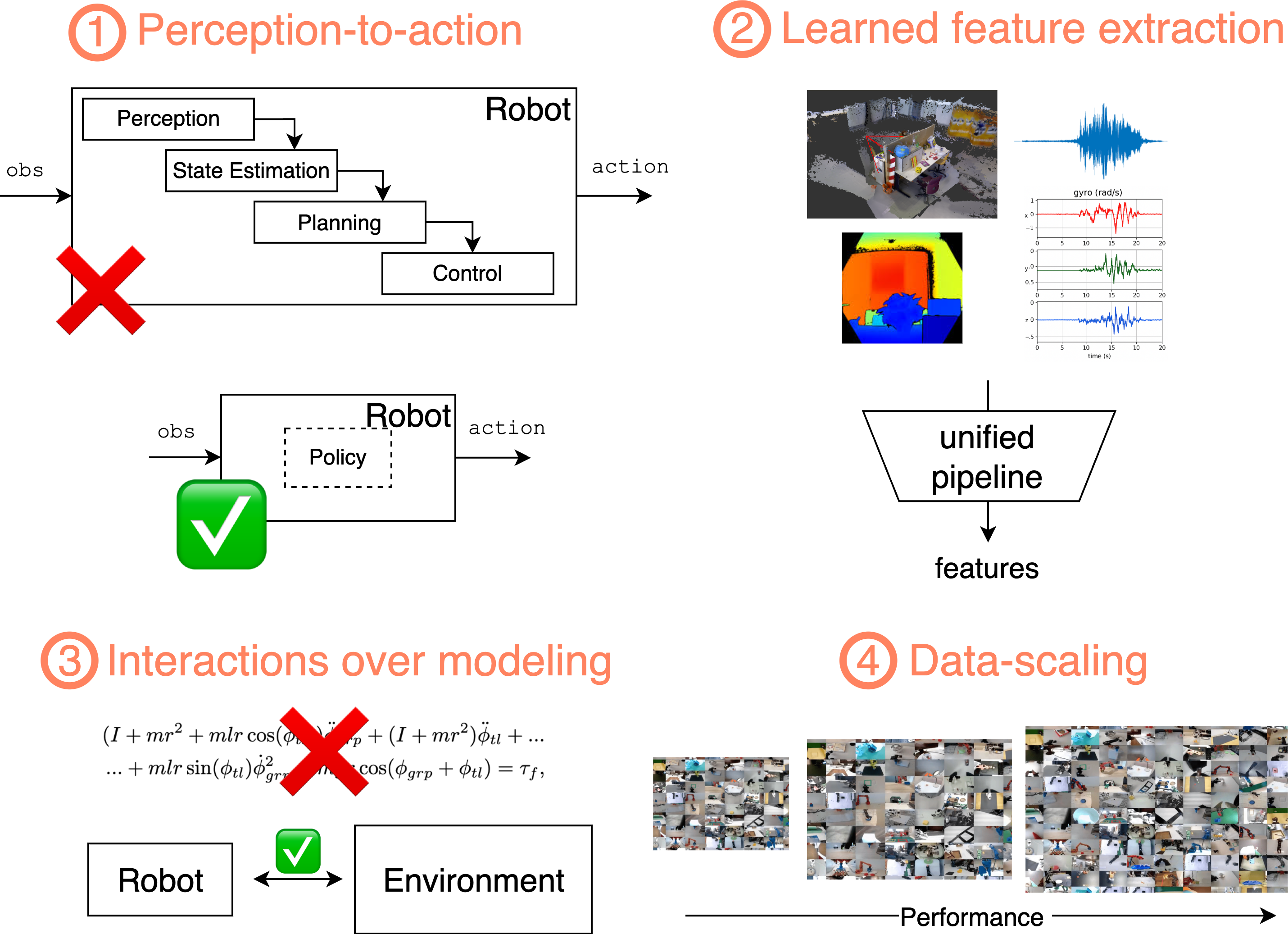
- Learning-based methods simplify the pipeline: Instead of stitching together many brittle parts (sensing → mapping → planning → control), a learned policy can map sensors directly to actions, which is more flexible and often more robust.
- Data scales performance: Just like in vision and language AI, more and better robot data leads to stronger models. The tutorial shows how to structure and share that data so everyone benefits.
- Combining old and new is powerful: Classical methods are valuable, but adding learning helps handle uncertainty, complex contacts, and real-world messiness.
- LeRobot makes robot learning accessible: By supporting affordable hardware and offering ready-to-use implementations (RL, BC, and generalist policies), more students and researchers can try real robot learning without huge budgets.
- Foundation-style, language-conditioned models are promising: They can follow natural language instructions, generalize across tasks, and even work on different robot bodies, moving toward “generalist” robots.
Implications and Potential Impact
If we organize robot data well and make high-quality tools easy to use, many more people—including students, hobbyists, and small labs—can teach robots practical skills. This could:
- Speed up progress toward robots that help with everyday tasks, dangerous work, or disaster response.
- Reduce the need for perfect physics models by leaning on learning from experience.
- Encourage open collaboration and reproducible results through shared datasets and code.
- Push the field toward generalist robot models that understand language, adapt to new tasks, and work across different machines.
In short, this tutorial shows how modern machine learning—paired with thoughtful data design and open-source tools—can make robots smarter, more adaptable, and more useful in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and unresolved questions the tutorial leaves open, organized to guide future research and tooling improvements.
Data and dataset format
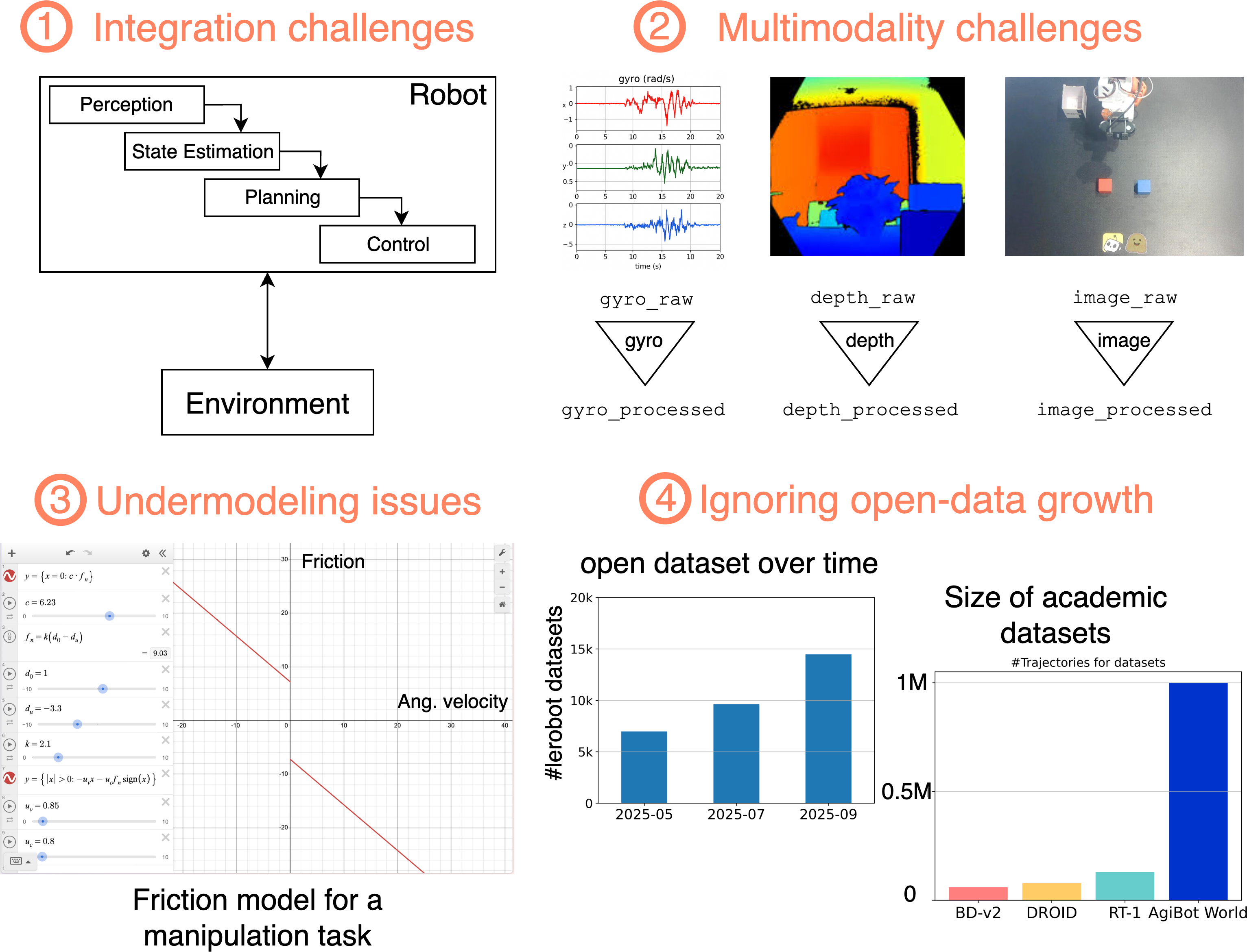
- Random access and synchronization: Evaluate the latency and accuracy trade-offs of concatenating frames into MP4 (GOP/keyframe seeking, codec artifacts, chroma subsampling) for multi-camera, multi-fps data; compare with alternatives (e.g., Zarr/HDF5/RAW frames, GPU-native decoders) for training throughput and fidelity.
- Cross-modal alignment: Specify and test mechanisms for cross-sensor timestamp alignment, clock drift correction, dropped-frame handling, and per-stream jitter bounds; document windowing policies when modalities have different sampling rates.
- Schema/versioning and provenance: Define a formal, versioned metadata schema (including sensor intrinsics/extrinsics, units and frames, time offsets, checksums) with migration tools and provenance tracking for reproducibility and data integrity.
- Interoperability: Provide robust converters and schema alignment for ROS bags and major open corpora (e.g., Open-X Embodiment, RT-X, BridgeData), including harmonized action/observation spaces, coordinate frames, and unit conventions.
- Scalability under streaming: Characterize performance limits for billion-frame datasets on local filesystems and cloud storage (HF Hub/S3), including sharding, multi-worker prefetch, cache policies, resumption after network failures, and OS-specific mmap behavior.
- Data quality and labeling: Establish task taxonomy standards, language description normalization, inter-annotator agreement protocols, automated QA (e.g., action–state consistency, duplicate removal), and ethical filtering for community-contributed datasets.
- Non-visual modalities: Clarify support and best practices for tactile, force/torque, audio, event cameras (compression, timestamping, calibration), and how these are represented and synchronized in
lerobotdataset.
Algorithmic and modeling
- Decoupled inference stack: Provide stability/safety analyses and empirical bounds for the proposed decoupling of planning and execution (jitter tolerance, missed deadlines, preemption, recovery policies).
- RL vs BC vs foundation models: Conduct controlled, head-to-head comparisons across identical tasks/embodiments on sample efficiency, compute/energy cost, robustness, and negative transfer; articulate scaling laws with data, model size, and modalities.
- Language grounding: Standardize task text encoding/tokenization, define alignment objectives to low-level control, and evaluate instruction-following reliability (hallucinations, ambiguity resolution) across embodiments.
- Cross-embodiment generalization: Develop and test embodiment-agnostic representations and action spaces (e.g., SE(3)-aligned, goal-parameterized, skill primitives), including alignment losses and control-rate normalization.
- Hierarchical control: Specify interfaces and reference implementations to integrate skills/options or MPC with learned visuomotor layers, including arbitration and safety supervisors.
- Safety-aware learning: Detail safe exploration strategies for online RL/IL on hardware (constraints, shielded policies, recovery/reset strategies), and quantify risk/efficiency trade-offs.
- Robustness and OOD: Establish procedures for measuring robustness to sensor noise, occlusions, lighting changes, latency spikes, and introduce OOD detection and fallback behaviors; explore formal verification where feasible.
Systems and deployment
- Real-time and embedded constraints: Benchmark end-to-end latency budgets, determinism, and throughput on target hardware; provide tooling for quantization/pruning, mixed precision, and real-time schedulability analyses.
- Drivers and hardware abstraction: Offer detailed guidelines and templates for adding new robots (coordinate frames, calibration, safety limits), including conformance tests and real-time safety layers (e-stops, torque/velocity bounds).
- Sim-to-real transfer: Provide recommended pipelines and tools for domain randomization, calibration, contact modeling, and quantifying transfer gaps; document best practices per embodiment/task type.
- Windowing semantics: Clarify
delta_timestempssemantics for variable-length episodes, padding masks, and their statistical impact on training (non-i.i.d. effects, leakage); benchmark randomization quality in streaming mode.
Evaluation, benchmarks, and reproducibility
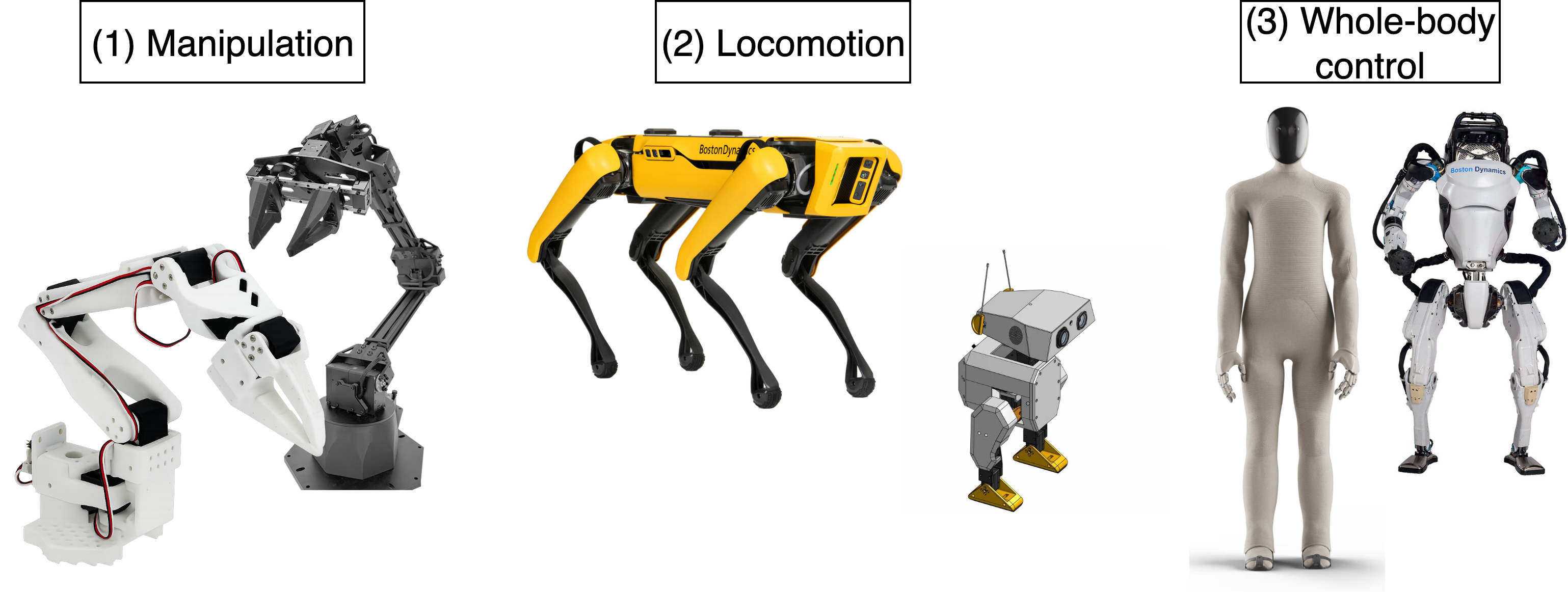
- Standardized benchmarks: Release a suite of reference tasks (manipulation, locomotion, whole-body) with fixed splits, success metrics, and evaluation scripts aligned with
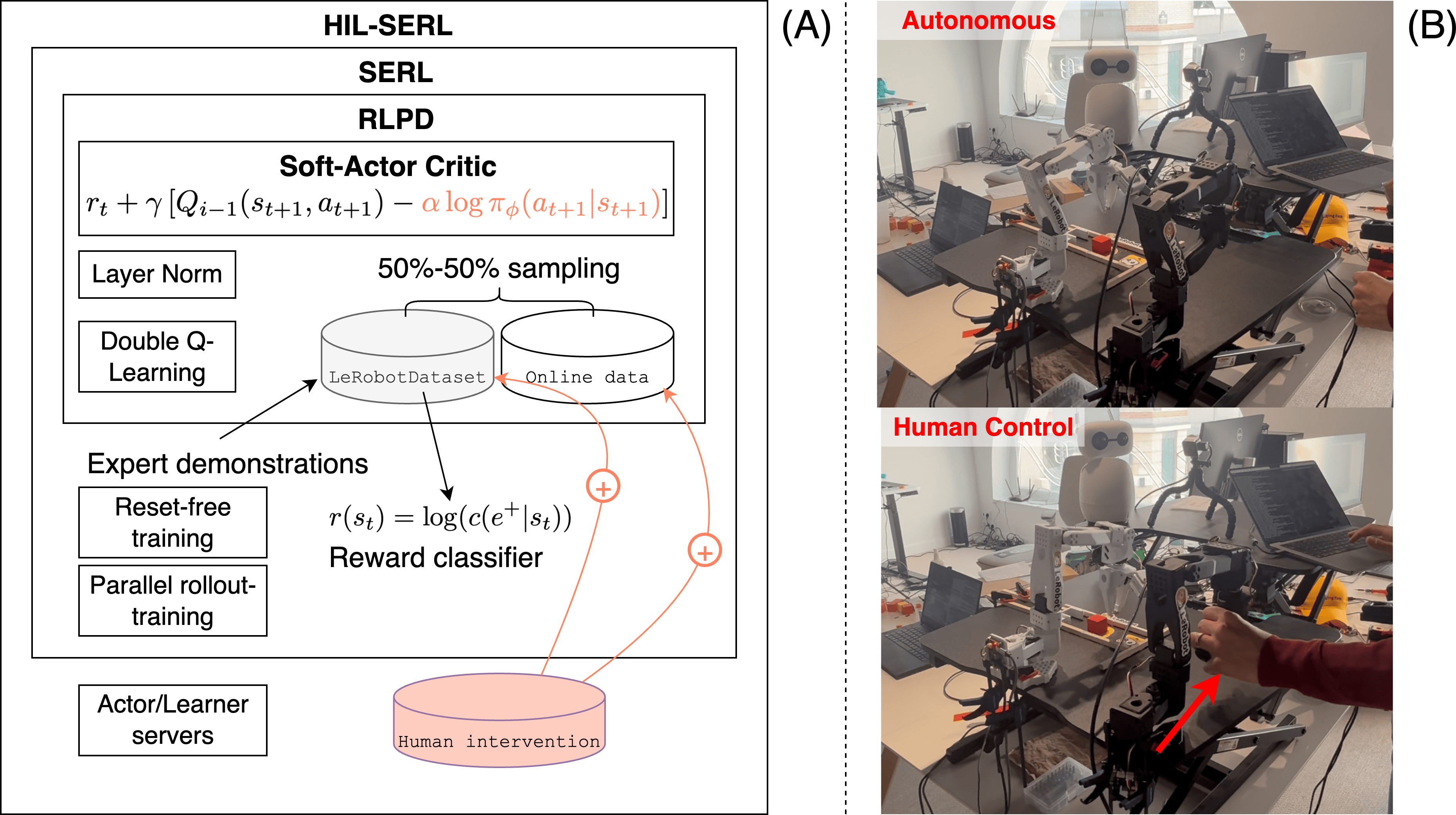
lerobotdataset. - Reference baselines and results: Provide reproducible training/evaluation recipes with expected metrics, seeds, and checkpoints across methods (ACT, Diffusion Policy, VQ-BeT, TD-MPC, HIL-SERL, π₀, SmolVLA).
- Metrics beyond success rate: Incorporate safety incidents, energy/torque usage, latency, smoothness, and human factors (teleop comfort, intervention rate) for a holistic evaluation.
- Lifecycle and drift: Define dataset/model versioning policies, deprecation strategies, and procedures to detect evaluation drift when datasets or drivers are updated.
Ethics, safety, and legal
- Data governance: Establish consent, licensing, and privacy guidelines for decentralized data contributions; implement automated screening for unsafe or privacy-sensitive content.
- Operational safety: Document risk assessments and compliance considerations for real-world deployments, including liability and adherence to relevant safety standards.
These gaps can be addressed by a combination of empirical studies (benchmarks and ablations), formal specifications (schemas, interfaces, safety envelopes), and systems work (tooling for synchronization, real-time inference, and deployment).
Practical Applications
Immediate Applications
The following applications can be deployed now using the methods, tooling, and workflows described in the paper and the LeRobot library.
- Standardized, reproducible robotics data pipelines (Industry, Academia, Software)
- Use case: Adopt the LeRobotDataset schema (meta/info.json, meta/stats.json, meta/tasks.jsonl, episode indexing, parquet + MP4) to standardize multi-modal time-series capture and sharing across labs and teams.
- Tools/workflows: LeRobot’s dataset class, Hugging Face Hub for hosting and streaming; native windowing for stacked observations/actions; PyTorch DataLoader integration.
- Assumptions/dependencies: Consistent sensor calibration and time sync; adequate storage/network bandwidth; adherence to metadata conventions.
- Rapid prototyping of visuomotor policies for manipulation on accessible hardware (Industry: manufacturing; Academia; Education; Daily life/hobbyist)
- Use case: Train task-specific BC policies (e.g., ACT, Diffusion Policy, VQ-BeT) for pick-and-place, drawer opening, sorting, and assembly tasks on low-cost robots (SO-100/SO-101, ALOHA-2).
- Tools/workflows: Teleoperation data collection (LeRobot snippets), LeRobot training scripts, streaming large datasets for faster i.i.d. batches, optimized inference stack decoupling planning from execution.
- Assumptions/dependencies: Sufficient high-quality demonstrations; safe work envelopes; basic guarding and human-robot interaction protocols.
- Sample-efficient on-hardware reinforcement learning (Industry: robotics R&D; Academia)
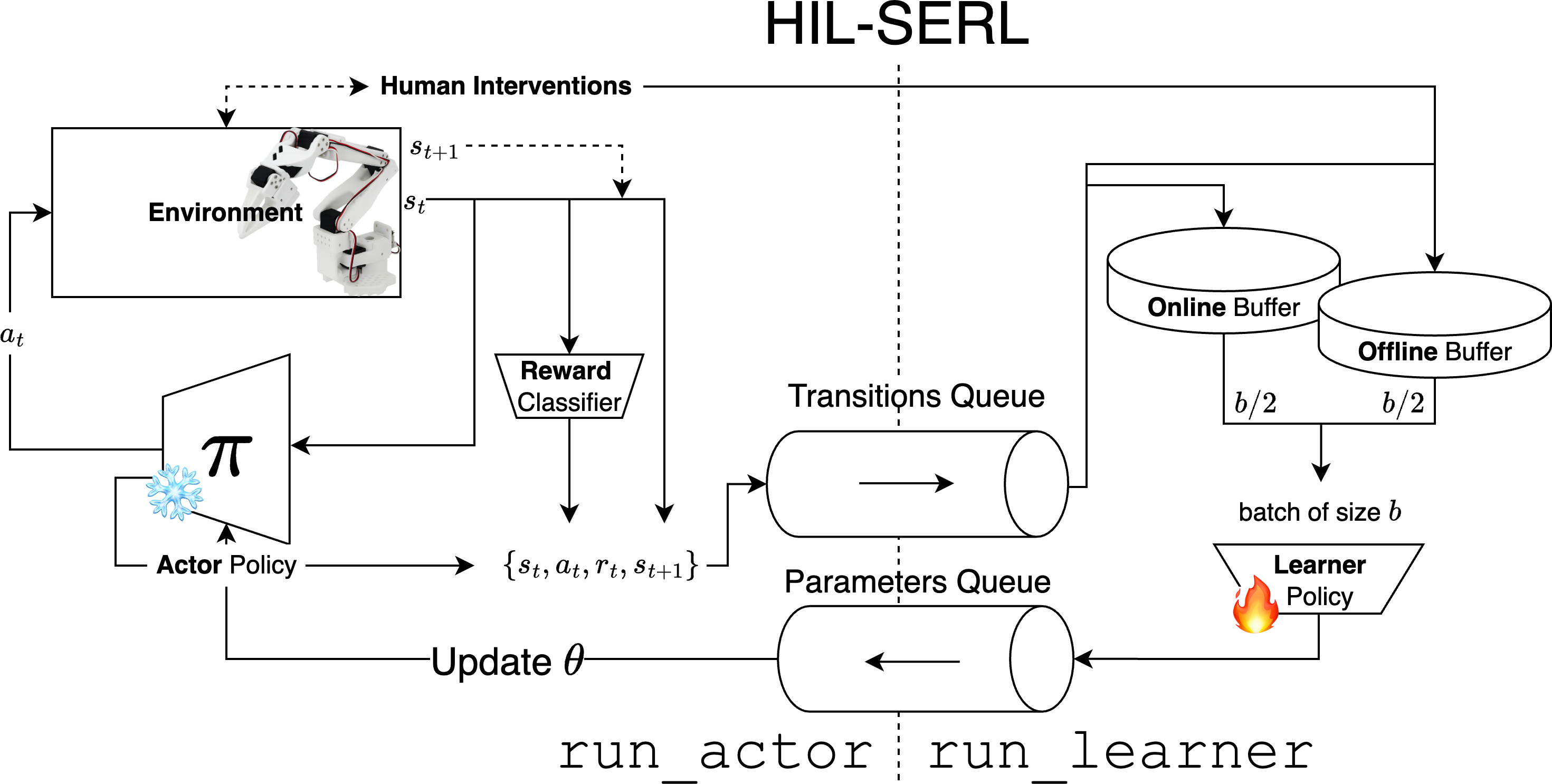
- Use case: Use TD-MPC and HIL-SERL to learn locomotion or fine-grained dexterous control directly on hardware with human-in-the-loop guidance, minimizing simulator reliance.
- Tools/workflows: LeRobot’s RL implementations, reward shaping and safety monitors, policy checkpoints, telemetry dashboards.
- Assumptions/dependencies: Safety supervisors and e-stop; conservative exploration settings; stable sensing; well-defined task rewards.
- Unified low-level control and device abstraction across robot embodiments (Industry; Academia; Software)
- Use case: Integrate multiple robot platforms (manipulators, mobile bases, humanoid arms/hands) under LeRobot’s unified read/write configuration API to reduce integration overhead and code duplication.
- Tools/workflows: LeRobot device adapters; hardware interface layer; common observation/action schemas.
- Assumptions/dependencies: Supported drivers/interfaces; real-time constraints; testing across firmware versions.
- Data-centric robotics development in teams (Industry; Academia)
- Use case: Establish continuous data collection → curation → training → deployment cycles that leverage streaming datasets and policy retraining from real-world interaction logs.
- Tools/workflows: HF Hub dataset versioning; windowed batching; experiment tracking; A/B deployment with decoupled inference.
- Assumptions/dependencies: Organizational processes for data governance; labeling/annotation where needed; privacy controls in shared spaces.
- Teaching and curriculum integration (Education)
- Use case: Undergraduate/graduate courses and bootcamps use this tutorial and LeRobot examples to teach end-to-end robot learning (dataset handling, BC/RL training, deployment).
- Tools/workflows: 3D-printed SO-100 kits; course notebooks; shared datasets; cloud GPU sessions for training; local inference on embedded PCs.
- Assumptions/dependencies: Access to affordable hardware and basic lab safety; institutional support for open data sharing.
- Baseline benchmarks and cross-embodiment evaluation (Academia; Industry)
- Use case: Compare BC and RL methods across tasks and platforms using consistent dataset schemas and evaluation routines; aggregate multi-robot datasets for robust generalization tests.
- Tools/workflows: LeRobot policy zoo (ACT, Diffusion Policy, VQ-BeT, TD-MPC, HIL-SERL), common metrics, mixed simulation + real-world datasets.
- Assumptions/dependencies: Task definitions harmonized across embodiments; synchronized camera and proprioception streams; comparable evaluation hardware.
- Policy and standards prototyping for robotics data documentation (Policy; Academia; Industry consortia)
- Use case: Pilot the LeRobotDataset metadata fields and episode structure as a recommended documentation template for publicly funded projects and shared testbeds.
- Tools/workflows: meta/info.json and meta/stats.json schema references; tasks.jsonl for language-conditioned labels; best-practices guides.
- Assumptions/dependencies: Multi-stakeholder alignment; lightweight compliance processes; versioning and provenance tracking.
- Hobbyist/home tasks with teleoperated data-driven policies (Daily life; Education)
- Use case: Train a simple home robot to sort items, open drawers, or tidy surfaces from teleop data, leveraging BC with decoupled inference for smoother runtime control.
- Tools/workflows: SO-100 kits; camera streams; demonstration recording scripts; policy deployment on small form-factor compute.
- Assumptions/dependencies: Basic safety (no sharp tools/heavy loads); reliable Wi-Fi; sufficient demonstrations in the home environment.
Long-Term Applications
These applications require further research, scaling, or development to achieve robust, safe, and regulated deployment.
- Generalist, language-conditioned household and facility robots (Healthcare: assistive; Logistics/warehousing; Education; Daily life)
- Use case: Deploy Pi_0- and SmolVLA-style policies to follow natural-language instructions across many tasks and embodiments (e.g., “clear the table,” “bring me the yellow box”).
- Tools/workflows: Multi-task/multi-robot datasets at scale; language-conditioned training; on-device policy distillation; robust decoupled inference with safety layers.
- Assumptions/dependencies: Large, diverse datasets capturing in-the-wild variability; reliable grounding from language to actions; strong safety assurance and interpretability.
- Whole-body humanoid control for dynamic mobile manipulation (Robotics; Manufacturing; Inspection)
- Use case: Learning-based whole-body control (e.g., WoCoCo-like approaches combined with TD-MPC) for coordinated locomotion, balance, and manipulation in cluttered real-world settings.
- Tools/workflows: Rich proprioceptive + visual sensing; contact-aware training data; hybrid BC/RL; real-time inference optimizations.
- Assumptions/dependencies: High-fidelity sensing and latency constraints; advanced fall-detection and recovery; extensive safety validation.
- Fleet learning and continual improvement in the field (Industry: RaaS; Logistics; Agriculture; Energy)
- Use case: Distributed robots collect interaction data to continuously update shared policies (data flywheel), with staged rollouts and remote supervision.
- Tools/workflows: Data ops pipelines; federated/edge training; streaming updates; evaluation gates; rollback mechanisms.
- Assumptions/dependencies: Robust networking; privacy/security; standardized hardware interfaces; regulatory compliance for remote updates.
- Hazardous environment operations (Energy, Nuclear decommissioning, Space)
- Use case: Learn manipulation and inspection tasks in high-risk settings where explicit dynamics models are inadequate (variable friction, deformable materials), relying on interaction-driven policies.
- Tools/workflows: Teleoperation with BC; HIL-SERL for cautious on-device learning; domain randomization and sim-to-real bridging where feasible.
- Assumptions/dependencies: Specialized safety envelopes; radiation/EMI-hardened sensors; limited human access; strong fail-safes.
- Autonomous clinical logistics and assistive manipulation (Healthcare)
- Use case: Non-critical tasks like fetching supplies, opening cabinets, or tray handling in hospitals; assistive arms for patients in controlled environments.
- Tools/workflows: Language-conditioned BC for task generalization; perception-to-action pipelines with safety monitors; controlled deployment protocols.
- Assumptions/dependencies: Medical device regulations; rigorous HRI safety; robust hygiene and contamination control; reliability under variable lighting and occlusion.
- Open robotic data commons and governance frameworks (Policy; Academia; Industry)
- Use case: National or global repositories of multi-modal, multi-embodiment datasets with standardized schemas, licensing, privacy controls, and benchmarking protocols.
- Tools/workflows: LeRobotDataset-like standards; dataset cards and provenance; tooling for anonymization; shared evaluation suites.
- Assumptions/dependencies: Multi-party agreements; funding and maintenance; legal frameworks for liability and data rights; mechanisms for quality assurance.
- Interoperable hardware abstraction layers and runtime safety certification (Industry; Policy; Software)
- Use case: Certifiable runtime stacks that decouple planning and execution with safety interlocks, compatible across robot families and firmware.
- Tools/workflows: Formalized device APIs; real-time monitors; interpretable policy constraints; certification processes.
- Assumptions/dependencies: Industry adoption; standardization bodies; audits; performance guarantees under worst-case latency.
- Large-scale education initiatives with accessible robotics kits (Education; Policy)
- Use case: Regional programs that pair low-cost manipulators with cloud training resources and open datasets, creating a talent pipeline and democratizing robot learning.
- Tools/workflows: Public datasets on HF Hub; course templates; device loan programs; community contribution workflows.
- Assumptions/dependencies: Funding and infrastructure; equitable access; teacher training; safe classroom practices.
- Cross-domain simulation-to-real transfer for complex contacts and deformables (Academia; Industry)
- Use case: Improve transfer methods for tasks where explicit modeling fails (soft objects, fluids), combining learned perception-action with limited physics priors.
- Tools/workflows: Mixed simulators; data augmentation and randomization; hybrid loss functions; multi-modal sensing (vision, tactile, audio).
- Assumptions/dependencies: Better simulators for contact-rich tasks; sensor fusion robustness; careful validation against real-world dynamics.
- Sustainable, energy-efficient robot learning and inference (Energy; Industry; Policy)
- Use case: Optimize training and runtime (edge inference, model compression, event-driven sensing) to reduce the energy footprint of large-scale robot fleets.
- Tools/workflows: Distillation of foundation policies; quantization/pruning; scheduling; low-power hardware accelerators.
- Assumptions/dependencies: Hardware support; acceptable accuracy-energy tradeoffs; monitoring and reporting standards.
In all cases, feasibility hinges on the quality, diversity, and scale of data; robust safety and human-robot interaction practices; real-time constraints; reliable hardware/software integration; and appropriate governance for open data and deployment in shared spaces.
Glossary
- Action Chunking with Transformers (ACT): A behavioral cloning method that predicts sequences of low-level actions (chunks) using a transformer architecture for fine-grained control. "Action Chunking with Transformers (ACT)"
- Behavioral Cloning (BC): An imitation learning approach that learns a policy by regressing expert actions from demonstrations, mapping observations directly to actions. "Behavioral Cloning (BC)"
- Contact modeling: The mathematical representation of interactions at contact points (e.g., friction, compliance) between a robot and its environment. "rigid-body dynamics, contact modeling, planning under uncertainty"
- Differential inverse kinematics (diff-IK): A velocity-space IK method that uses the Jacobian to compute joint velocities achieving a desired end-effector velocity. "Differential inverse kinematics (diff-IK) complements IK via closed-form solution of a variant of eq.~\ref{eq:ik_problem}."
- Diffusion Policy: A class of visuomotor policies that uses diffusion models to generate action sequences conditioned on observations. "Diffusion Policy~\citep{chiDiffusionPolicyVisuomotor2024}"
- End-effector: The terminal tool or part of a robot manipulator (e.g., gripper) that interacts with the environment. "connected to an end-effector"
- Feedback linearization: A nonlinear control technique that cancels system nonlinearities via feedback to yield an effectively linear closed-loop system. "consisting in feedback linearization, PID control, Linear Quatratic Regulator (LQR) or Model-Predictive Control (MPC)"
- Foundation models: Large models trained on broad data that can be adapted to many tasks; in robotics, generalist policies trained on diverse multimodal robot data. "foundation models capable of semantic reasoning across multiple modalities"
- Forward Kinematics (FK): The mapping from joint configuration to the robot’s end-effector pose (position and orientation). "forward and inverse kinematics (FK, IK)"
- Hybrid dynamics: Dynamics involving both continuous evolution and discrete mode switches, often induced by intermittent contacts. "hybrid dynamics (mode switches)"
- Inverse Kinematics (IK): The problem of finding joint configurations that achieve a desired end-effector pose. "inverse kinematics (IK)"
- Jacobian: The matrix of partial derivatives relating joint velocities to end-effector velocity (twist) in kinematic chains. "Let J(q) denote the Jacobian matrix"
- Linear Quadratic Regulator (LQR): An optimal control method for linear systems that minimizes a quadratic cost over states and control inputs. "Linear Quatratic Regulator (LQR)"
- Model-Predictive Control (MPC): A control strategy that repeatedly solves a finite-horizon optimization using a dynamics model to compute the next control action. "Model-Predictive Control (MPC)"
- Moore-Penrose pseudo-inverse: A generalized matrix inverse used to compute least-squares solutions, e.g., for Jacobian inversion in IK. "Moore-Penrose pseudo-inverse"
- PID control: A feedback control method combining proportional, integral, and derivative terms to reduce tracking error. "PID control"
- Reinforcement Learning (RL): Learning to select actions by maximizing cumulative reward through trial-and-error interaction with the environment. "Reinforcement Learning (RL)"
- Rigid-body dynamics: The physics governing motion of idealized non-deformable bodies connected by joints under forces/torques. "rigid-body dynamics, contact modeling"
- Temporal Difference (TD)-learning: An RL method that updates value estimates using bootstrapping from subsequent estimates rather than waiting for final outcomes. "Temporal Difference (TD)-learning"
- Vector-Quantized Behavior Transformer (VQ-BeT): A BC approach that discretizes behaviors into a codebook via vector quantization and models them with a transformer. "Vector-Quantized Behavior Transformer (VQ-BeT)"
- Visuomotor policies: End-to-end policies that map visual (and other sensorimotor) inputs directly to motor commands. "(visuomotor policies)"
- Whole-body control: Coordinated control of many joints/limbs (e.g., humanoids) to execute tasks while satisfying balance and contact constraints. "whole-body control"
Collections
Sign up for free to add this paper to one or more collections.