The Era of Agentic Organization: Learning to Organize with Language Models
Abstract: We envision a new era of AI, termed agentic organization, where agents solve complex problems by working collaboratively and concurrently, enabling outcomes beyond individual intelligence. To realize this vision, we introduce asynchronous thinking (AsyncThink) as a new paradigm of reasoning with LLMs, which organizes the internal thinking process into concurrently executable structures. Specifically, we propose a thinking protocol where an organizer dynamically assigns sub-queries to workers, merges intermediate knowledge, and produces coherent solutions. More importantly, the thinking structure in this protocol can be further optimized through reinforcement learning. Experiments demonstrate that AsyncThink achieves 28% lower inference latency compared to parallel thinking while improving accuracy on mathematical reasoning. Moreover, AsyncThink generalizes its learned asynchronous thinking capabilities, effectively tackling unseen tasks without additional training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for AI to think called “asynchronous thinking” (AsyncThink). Instead of one big AI doing all the thinking in a straight line, the AI organizes itself like a team: one “organizer” plans and several “workers” solve parts of the problem at the same time. The goal is to solve hard problems faster and more accurately by working together, not just harder.
What questions did the researchers ask?
They focused on three simple questions:
- How can we make AI think in teams so it can work on different parts of a problem at the same time?
- Can the AI learn when to split a problem into sub-tasks and when to combine answers, instead of following a fixed, hand‑made plan?
- Will this team-style thinking be both faster and more accurate than today’s common methods?
How did they do it?
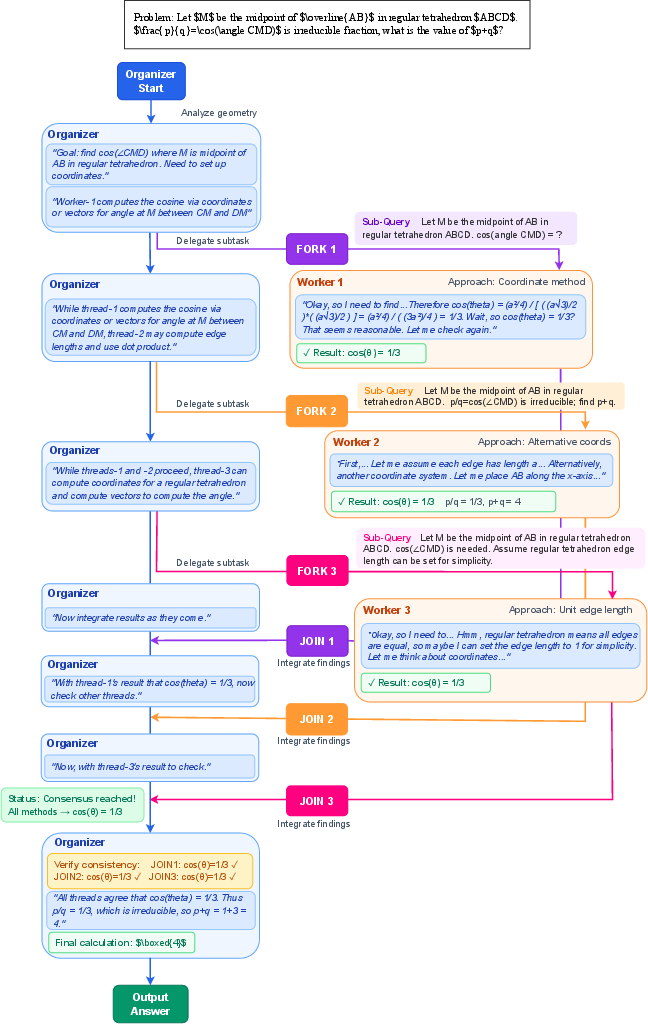
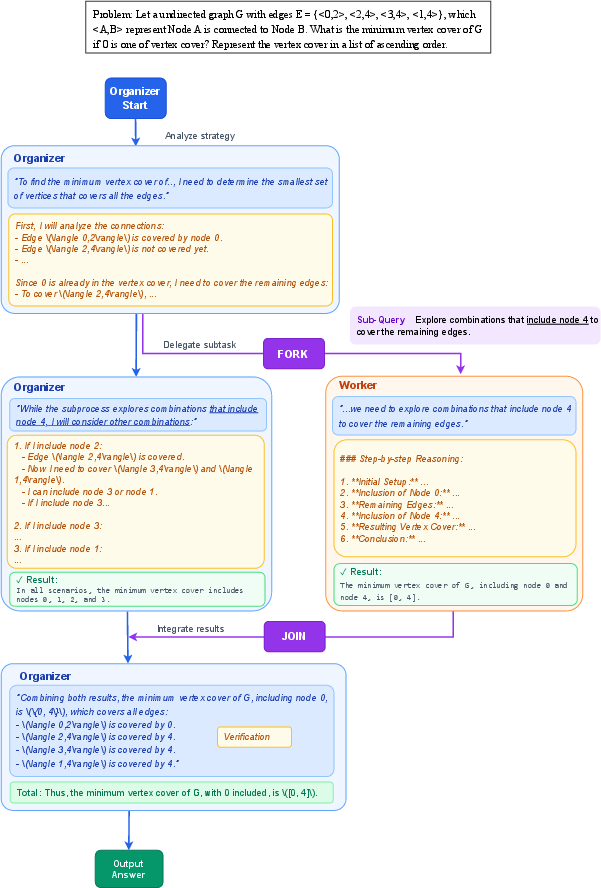
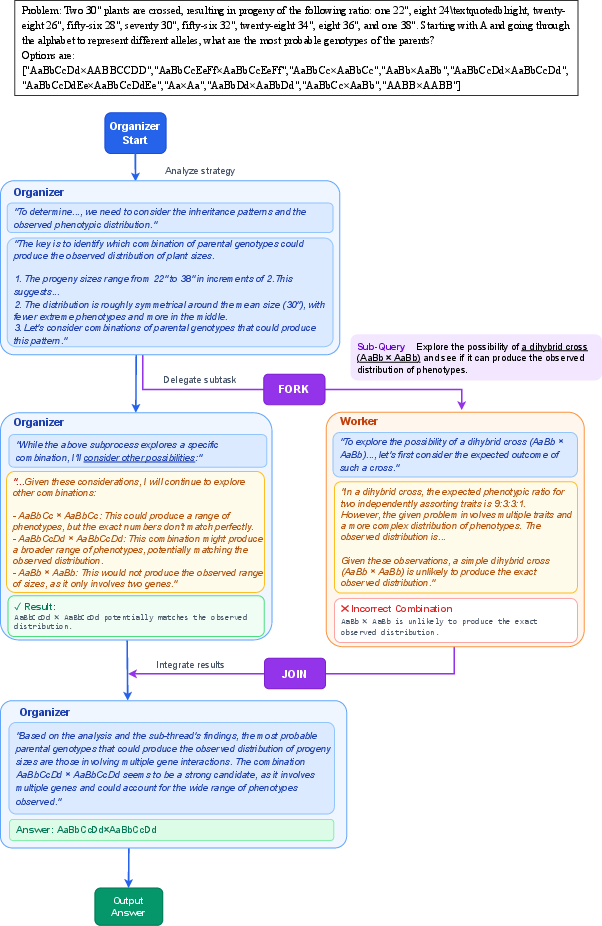
The organizer–worker idea (think: a teacher and helpers)
Imagine a classroom project. The teacher (the organizer) decides which parts of the project to give to different students (the workers). Each student works on their piece, and the teacher later collects their work and combines it into a final report.
In AsyncThink:
- The organizer is an AI that plans the thinking process.
- The workers are copies of the same AI that handle sub-questions.
- Everyone is the same model under the hood; they just play different roles.
“Fork” and “Join” actions (think: assign and collect)
The organizer uses two simple actions, written as plain text:
- Fork: “Give this sub-question to a worker.” (Like assigning a mini-task.)
- Join: “Bring me the result from that worker.” (Like collecting a student’s work and adding it to the main report.)
While workers are busy, the organizer can keep thinking or assign more tasks. When the organizer hits a Join, it waits if needed, then merges the worker’s result and continues.
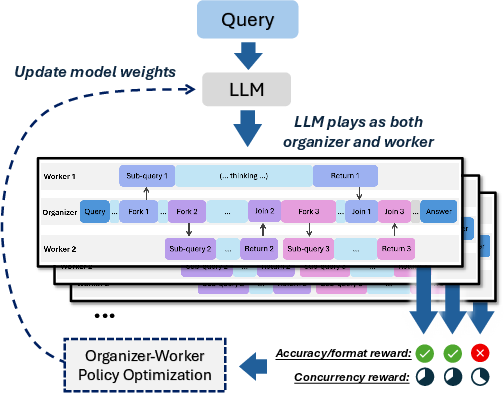
Learning in two stages (practice, then try-and-improve)
- Cold-start format fine-tuning: First, the model practices the “teamwork format” (how to write Forks/Joins correctly) using examples. This is like learning the rules of the game.
- Reinforcement learning (RL): Next, the model learns by trial and reward. It tries different ways to split and combine work and gets rewards for:
- Accuracy: Did it get the right answer?
- Format: Did it follow the Fork/Join rules correctly?
- Concurrency: Did it actually use workers at the same time to speed things up?
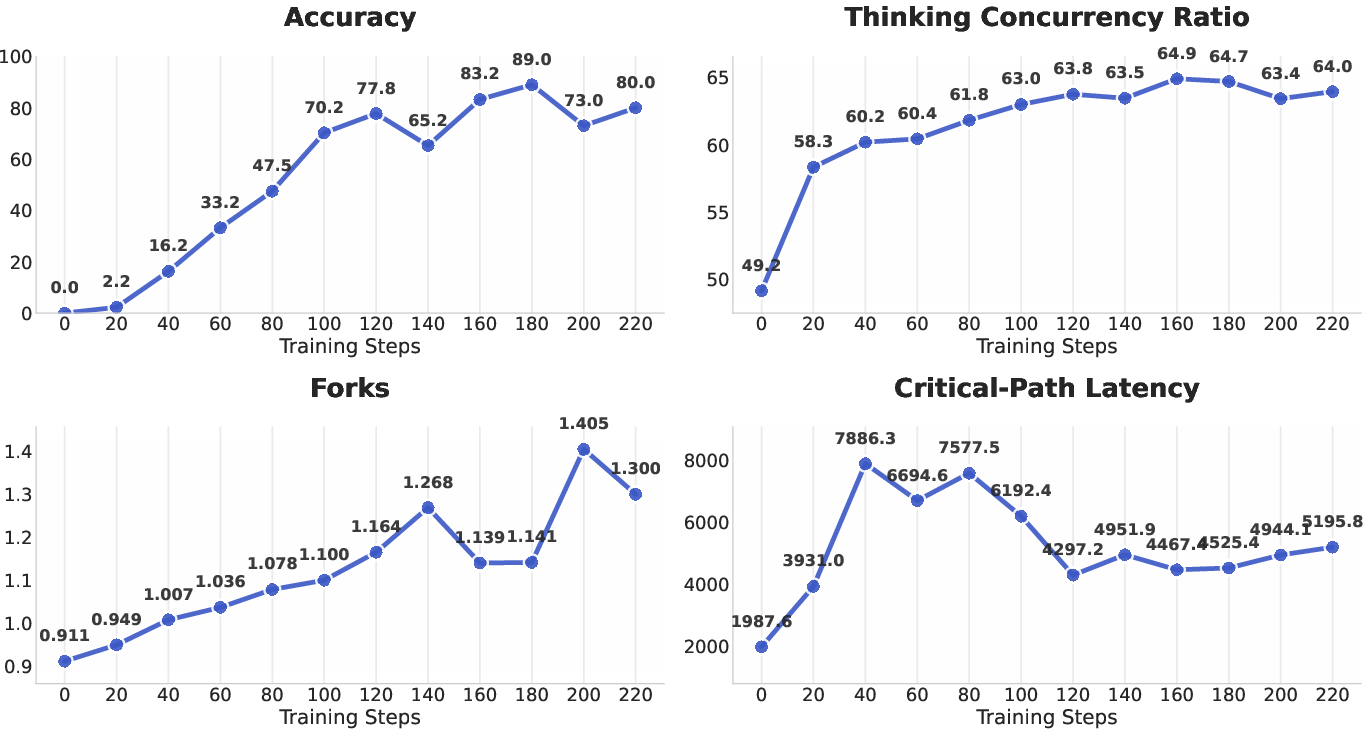
Over time, the organizer learns smart patterns: when to Fork, when to Join, and how to coordinate workers for the best speed and accuracy.
How they measured speed: “critical-path latency”
Speed isn’t just “how many tokens did we write.” The important part is: how long do we have to wait for the slowest necessary part? That’s the “critical path,” like the longest line you must stand in before you can leave. The researchers calculate the minimum time you’d need if everything ran efficiently and you only waited when the organizer had to Join a worker’s result.
What tasks did they test?
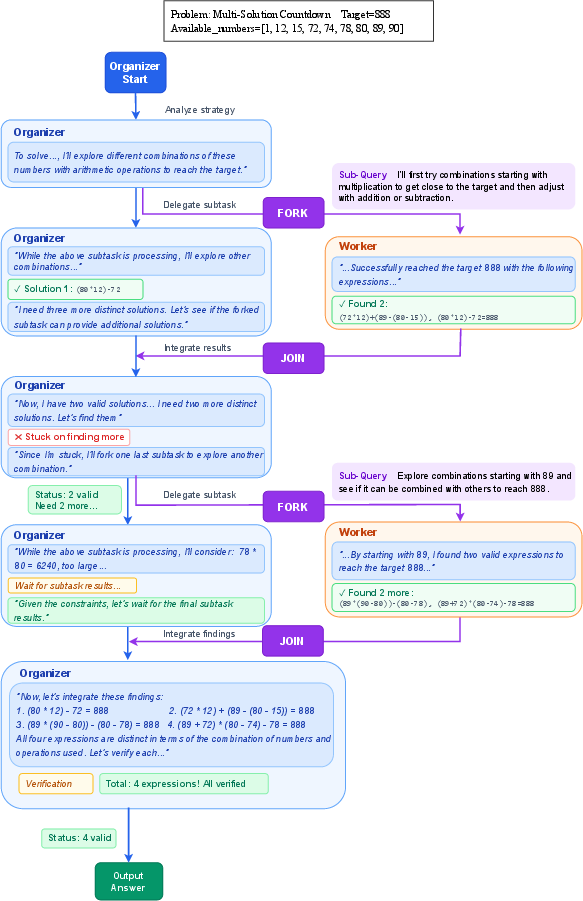
- Multi-solution Countdown: Given numbers and basic operations (+, −, ×, ÷), find four different expressions that reach a target number.
- Math contests: AMC-23 and AIME-24 style problems.
- 4×4 Sudoku: Fill a small grid with numbers under simple rules.
What did they find?
Across tasks, AsyncThink was both faster (lower latency) and often more accurate than common alternatives.
Key results:
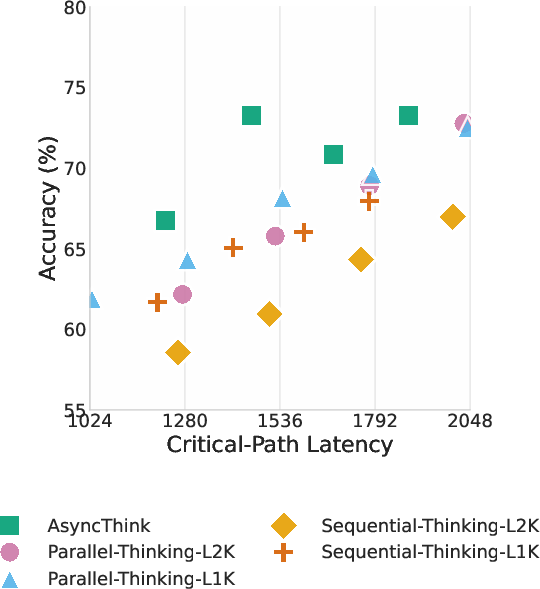
- Faster than parallel thinking: On math problems, AsyncThink cut the critical-path latency by about 28% compared to a “parallel thinking” baseline, while also matching or beating accuracy.
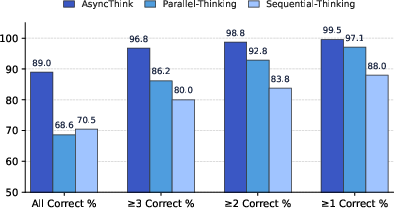
- More accurate on Countdown: AsyncThink found all four correct solutions 89% of the time, clearly higher than baselines (about 69–71%).
- Strong math performance: On AMC-23 and AIME-24, AsyncThink reached top accuracy while using shorter worker responses and still lowering overall latency.
- Generalizes to new tasks: Even when trained on Countdown, AsyncThink performed best on 4×4 Sudoku without extra training, showing it learned a general teamwork skill, not just a trick for one task.
- Why the rewards matter: Removing the “concurrency” reward made it slower and a bit less accurate. Skipping the format training or the RL step hurt accuracy a lot. This shows each part of the training pipeline is useful.
Why these matter:
- Better accuracy means more reliable reasoning.
- Lower latency means answers arrive faster in real use (like tutoring, coding help, or planning).
- Generalization means the teamwork skill transfers to new problems.
Why does this matter? What could it change?
- Smarter teamwork in AI: Instead of fixed, hand-crafted workflows, the AI learns to organize itself—deciding how to split work and when to merge results—based on the problem.
- Faster problem solving: AsyncThink cuts waiting by running different parts at the same time, like a well-coordinated team.
- Scales to bigger challenges: The paper hints at future systems with many specialized workers (math, coding, web search) and even human-in-the-loop setups where people can act as organizers or workers for judgment calls.
- Flexible and adaptive: The Fork/Join idea is simple but powerful—it can mimic classic single-threaded thinking, basic parallel thinking, or more advanced, adaptive plans as needed.
Simple takeaways
- AsyncThink turns one big model into a well-run team: a planner and helpers who work in parallel.
- It learns when to split tasks and when to combine answers, not just following a fixed script.
- It’s both faster and more accurate than common baselines on several reasoning tasks.
- It transfers its teamwork skills to new problems without extra training.
- This could be a step toward AI systems that organize large groups of agents—and even collaborate smoothly with humans—to solve complex, real-world problems.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single list of unresolved knowledge gaps, limitations, and open questions that remain after this paper. Each item is framed to be concrete and actionable for future research.
- Real-world latency: The paper reports “critical-path latency” derived from token counts rather than wall-clock measurements; it does not evaluate AsyncThink on actual inference hardware (GPU/CPU clusters) with real scheduling, networking, batching, or memory constraints.
- Concurrency overhead modeling: Join/communication overhead is acknowledged qualitatively but not quantified; there is no empirical decomposition of latency into thinking, waiting, merge, and context-growth costs under realistic serving conditions.
- Baseline fairness: Parallel baselines use longer token budgets (e.g., 2K) while AsyncThink enforces shorter per-worker budgets (e.g., 512), potentially conflating algorithmic gains with budget choices; head-to-head comparisons under matched compute/token caps are missing.
- Reward hacking and stability: The thinking concurrency reward can be gamed (authors add a threshold τ to mitigate), but no robust analysis shows whether the learned policy balances accuracy vs. concurrency across diverse tasks; the “leverage” reward caused mode collapse, indicating fragile reward shaping.
- Credit assignment granularity: The GRPO extension assigns a shared advantage across organizer and worker tokens; there is no finer-grained credit assignment per Fork/Join action or per worker, which likely impedes learning nuanced organization policies.
- Task adaptivity criteria: The organizer’s decision rule for when to Fork vs. proceed sequentially is not characterized; no interpretable decision criteria or policy diagnostics are provided to explain when concurrent structure helps or hurts.
- Scaling laws with agent pool size: Results are limited to c=2 (MCD) and c=4 (math); there is no empirical scaling curve for accuracy, latency, and efficiency as c increases (e.g., up to dozens/hundreds of workers), nor an analysis of diminishing returns or Amdahl-like bounds.
- Adaptive budget allocation: Worker token budgets are fixed; there is no mechanism (or learning objective) to dynamically allocate sub-query budgets based on difficulty, expected utility, or time-to-merge.
- Heterogeneous agents and tools: All agents share the same backbone model without tool-use; the paper does not test orchestration of heterogeneous experts (code, math, search, database) or tool-equipped workers, which is central to agentic organization claims.
- Hierarchical recursion: The proposed “recursive agentic organization” (workers becoming sub-organizers) is not implemented or evaluated; open questions include grammar design for nested Fork/Join, stability, credit assignment across hierarchies, and latency impacts.
- Formal protocol semantics: The tag-based protocol lacks a formally specified grammar/runtime (e.g., typed actions, nested scopes, error recovery rules); parsing robustness, nested tags, and malformed sequences beyond simple format penalties remain unaddressed.
- Robustness to adversarial or malformed inputs: There is no analysis of how user-injected tags, adversarial prompts, or ambiguous sub-queries affect organizer-worker coordination or cause deadlocks, stalls, or mis-merges; recovery strategies are not described.
- Intermediate verification: Workers’ outputs are appended, but there are no verifiers for step-level correctness or conflict resolution when workers disagree; reliance on only final-answer rewards leaves integration quality underexplored.
- Information sharing architecture: Workers share state only via natural-language merges; there is no blackboard/memory mechanism, structured scratchpad, or shared embeddings to support efficient cross-worker knowledge reuse and deduplication.
- Deduplication rigor in MCD: The uniqueness criterion for multi-solution countdown (distinct numbers or operation counts) is informally stated; the exact algorithm for solution deduplication, collision handling, and correctness verification is not documented.
- Generalization breadth: Out-of-domain evaluation is limited to 4×4 Sudoku; broader domains (code generation, multi-hop QA, scientific reasoning, planning, tool-use) are not assessed, leaving generalization claims narrow.
- Failure mode analysis: The paper lacks qualitative error analyses (e.g., common miscoordination patterns, premature joins, over-forking, worker redundancy), which are essential for improving the organization policy.
- Memory and context growth: Merging multiple worker returns inflates organizer context; there is no measurement of memory footprint, context overflow risks, or strategies (pruning, summarization) to control prompt length and its impact on latency/accuracy.
- Implementation realism: The “asynchronous thinking” protocol is described at the text I/O level, but there is no system-level design for concurrent decoding, stream coordination, or batching on modern inference servers where concurrency is limited and costly.
- Baseline coverage: There are no direct empirical comparisons with closely related concurrent methods (APR, Parallel-R1, AutoGen-style multi-agent orchestration) using matched model sizes and budgets, leaving the relative advantage unclear.
- Data synthesis validity: Cold-start SFT relies on GPT-4o to detect “conditionally independent fragments” and produce organizer traces; the method’s reliability, biases, and errors (especially for c>2 topologies) are not audited or reported.
- Sensitivity to hyperparameters: The paper reports limited seeds and training steps; there is no systematic study of sensitivity to learning rates, τ thresholds, max lengths, worker counts, sampling temperatures, or GRPO group sizes.
- Catastrophic forgetting and base capabilities: Post-training effects on general language tasks, calibration, and knowledge retention are not evaluated; it remains unknown whether AsyncThink harms non-reasoning capabilities.
- Metric completeness: Only accuracy and critical-path latency are reported; metrics for reliability (variance), coverage, calibration, and solution diversity are not included, limiting assessment of organizational benefits beyond speed.
- Tokenization dependence: Latency is computed from token counts; differences in tokenization (model-specific) could skew latency estimates; cross-tokenizer normalization or wall-clock benchmarking is needed.
- Scheduling and stall minimization: The organizer does not learn explicit anti-stall scheduling (e.g., prioritizing sub-queries to minimize Join wait times); no heuristics or learned schedulers are explored to reduce idle periods.
- Worker diversity and redundancy: The organizer does not explicitly manage diversity (e.g., sampling strategies) to avoid redundant worker effort; mechanisms to encourage complementary exploration are missing.
- Step-level rewards: RL uses final-answer rewards (and format/concurrency) without intermediate, verifiable sub-goals; the absence of step-level rewards may limit sample efficiency and fine-grained control of organization quality.
- Reproducibility and release: Details on data, prompts, synthesized traces, and code are insufficient for full reproduction; no release of the protocol grammar, latency calculator, or RL pipeline is indicated.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented now by adapting the organizer–worker “Fork–Join” protocol, reward shaping, and latency profiling introduced in the paper.
- Async orchestration layer for LLM apps (software)
- Use AsyncThink’s text-based Fork–Join protocol to turn single-agent LLM workflows into concurrent, coordinated ones without changing the model architecture.
- Tools/products/workflows: “AsyncThink Orchestrator SDK” for LangChain/AutoGen-style stacks; “Agent Pool Manager” to set pool capacity c; “Critical-Path Profiler” to instrument latency.
- Assumptions/dependencies: Access to an LLM with sufficient reasoning ability; multi-threaded inference infrastructure to run organizer and workers concurrently; verifiable tasks or lightweight correctness checks.
- Faster multi-hop retrieval and synthesis (software, enterprise search)
- Organizer forks sub-queries to workers for retrieving different facets (documents, tables, code snippets), then joins and synthesizes answers. Expect lower end-to-end latency versus naïve parallel responders due to reduced aggregation overhead.
- Assumptions/dependencies: RAG connectors (search API, vector DB); structured Join output for safe merging; simple verifiers for citation coverage/consistency.
- Math and puzzle assistants with verifiable rewards (education, consumer apps)
- Apply concurrency reward shaping and GRPO-style RL to tasks with automatic verification (math problems, Sudoku), yielding higher accuracy and reduced latency versus sequential/majority-vote approaches.
- Tools/products/workflows: “Verifiable Reasoning Trainer” that combines accuracy and format rewards; curriculum of synthetic cold-start traces to teach the Fork–Join syntax before RL.
- Assumptions/dependencies: Access to validators (answer checkers); careful token-budget management per worker.
- Code assistance with concurrent subtasking (software engineering)
- Organizer decomposes debugging into parallel hypotheses (e.g., test case generation, log inspection, static checks), then joins validated findings into a fix plan.
- Assumptions/dependencies: Tool use (test runners, linters, CI logs); guardrails to avoid tool/resource thrashing; simple verifiers (unit-test pass/fail).
- Data analysis pipelines with concurrent scenario evaluation (data/finance)
- Fork parallel analyses (e.g., sensitivity runs, backtesting variants), then join results to deliver summaries and decisions faster.
- Assumptions/dependencies: Sandbox execution for analyses; caching and provenance; budgeted worker response limits to control cost.
- Helpdesk and customer support triage (enterprise operations)
- Workers concurrently explore root causes (knowledge base search, past tickets, policy constraints), organizer merges steps into resolutions.
- Assumptions/dependencies: Access to internal KB; privacy controls; format-compliant logging of Fork–Join for auditability.
- Meeting and document synthesis with angle-wise coverage (productivity/daily life)
- Organizer forks workers to extract action items, risks, decisions, and open questions in parallel; joins into a coherent summary.
- Assumptions/dependencies: Document segmentation and basic verifiers (e.g., key-point coverage checks).
- Accuracy–latency benchmarking and scheduling policy design (academia/engineering)
- Adopt “critical-path latency” as a standardized metric for non-sequential LLM reasoning; compare frontier trade-offs when tuning worker token budgets and pool size.
- Tools/products/workflows: Open-source latency DP calculator; dashboards for accuracy–latency curves across configs.
- Assumptions/dependencies: Model-agnostic instrumentation; reproducible prompts and action tags.
- Teaching collaborative problem-solving (education)
- Use the organizer–worker protocol to train students on decomposition and synthesis, mirroring Fork–Join thinking in labs or contests.
- Assumptions/dependencies: Simple tasks with verifiable outcomes; rubric for structure (correct Fork–Join usage, coverage, clarity).
- Governance and audit trails for multi-agent LLMs (policy, compliance)
- Log explicit Fork–Join tags and worker returns to enable traceability of decisions and resource usage in regulated environments.
- Assumptions/dependencies: Tag standardization; data retention policies; role-based access control to sub-query content.
Long-Term Applications
These opportunities require further research, scaling, integration with heterogeneous tools/agents, or regulatory validation before broad deployment.
- Heterogeneous expert organizations at scale (software, enterprise AI)
- Replace homogeneous workers with tool-augmented experts (coders, solvers, retrievers, planners), selected dynamically by the organizer to lower latency and raise accuracy.
- Tools/products/workflows: Skill registry; “Capability Router” for sub-query assignment; unified Join schemas for heterogeneous returns.
- Assumptions/dependencies: Reliable tool adapters; robust cross-agent context handling; cost and resource scheduling.
- Massive agent pools and scaling laws (academia/HPC)
- Systematically study accuracy–latency trade-offs as agent pool capacity grows from tens to thousands, informing optimal concurrency and scheduling policies.
- Assumptions/dependencies: Cluster-grade infrastructure; parallel decoding engines; measurement frameworks for contention and overhead.
- Recursive agentic organization (software, robotics, complex planning)
- Promote workers to sub-organizers to create hierarchical Fork–Join trees, enabling deep problem decomposition (e.g., multi-level planning in robotics or large software refactors).
- Assumptions/dependencies: Hierarchical memory management; failure isolation and recovery; structured result merging across levels.
- Human–AI co-organization (industry, policy, healthcare)
- “Human-as-Organizer” dispatches to AI workers, or “Human-as-Worker” handles judgment-sensitive subtasks; collaborative planning before execution.
- Assumptions/dependencies: UX for live Fork–Join control; consent and accountability models; human-in-the-loop verifiers.
- Clinical decision support with concurrent differentials (healthcare)
- Organizer forks hypotheses (differential diagnoses, guideline checks, drug interactions) and joins into explainable recommendations.
- Assumptions/dependencies: FDA/CE approval pathways; stringent verifiers; EHR integration; bias/fairness assessment; clinical liability frameworks.
- Grid and energy optimization with parallel scenario testing (energy)
- Concurrent evaluations of dispatch strategies, demand response, and contingency plans; organizer merges KPIs and constraints into optimal schedules.
- Assumptions/dependencies: High-fidelity simulators; domain verifiers; real-time data feeds; safety guarantees.
- Portfolio construction and risk stress testing (finance)
- Parallel scenario generation (macro shocks, liquidity stress, factor tilts); join consistent risk and return profiles for allocation decisions.
- Assumptions/dependencies: Model risk management; regulatory reporting; robust backtesting verifiers; audit logs.
- Legal and compliance review with role-specialized workers (legal/policy)
- Workers specialize in statute extraction, precedent mapping, risk flags; organizer composes an opinion with traceable citations.
- Assumptions/dependencies: Verified corpora; conflict-of-law handling; confidentiality and privilege controls.
- Standardization of Fork–Join action schema and safety checks (policy/standards)
- Define common tag formats, concurrency rewards, and format error penalties to reduce systemic errors and “hacks” (e.g., gratuitous forking).
- Assumptions/dependencies: Multi-stakeholder standards bodies; open benchmarks; safety red-teaming.
- Cost-aware scheduling and green AI operations (industry/ops)
- Use critical-path latency and concurrency metrics to build schedulers that minimize cloud cost and energy while maintaining accuracy SLAs.
- Assumptions/dependencies: Real-time cost/energy telemetry; quota and throttling policies; adaptive token budgets per worker.
- Generalized RL for non-sequential thought (academia, tooling)
- Extend GRPO-like methods to multi-trace episodes with shared advantages; study reward shaping (accuracy, format, concurrency) and stability at scale.
- Assumptions/dependencies: Robust RL infrastructure; diverse verifiers; curriculum design for cold-start format learning.
- Consumer meta-planners for life admin (daily life)
- Long-horizon trip planning, shopping optimization, and scheduling via hierarchical Fork–Join; concurrent vendor queries and constraints merging.
- Assumptions/dependencies: Reliable external APIs; data privacy; cost caps; graceful degradation when sub-queries fail.
Glossary
- Accuracy-Latency Frontier: The trade-off curve showing how answer accuracy varies with inference latency for different methods. "we further analyze its performance through ablation studies and accuracy-latency frontier comparisons"
- Accuracy Reward: A verifiable reinforcement learning signal that scores the correctness of final answers, often binary for single-answer tasks. "Accuracy Reward: This reward measures the accuracy of the predicted final answers"
- Agent Pool: The set of concurrent agents available; its capacity defines how many agents can run simultaneously. "an agent pool represents a group of agents that run concurrently."
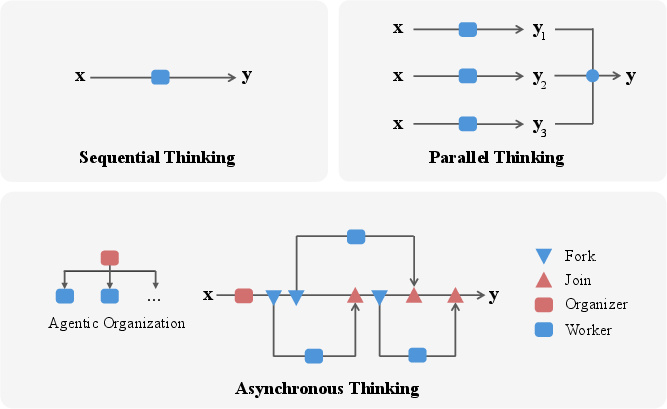
- Agentic Organization: A system in which multiple agents collaborate concurrently to solve complex problems beyond individual capabilities. "We envision a new era of AI, termed agentic organization, where agents solve complex problems by working collaboratively and concurrently, enabling outcomes beyond individual intelligence."
- AIME-24: A math reasoning benchmark used to evaluate model performance on competition-style problems. "We also assess AsyncThink on math reasoning benchmarks, including AMC-23 and AIME-24~\cite{aime2024}."
- AMC-23: A math reasoning benchmark focused on contest-level questions used for evaluation. "We also assess AsyncThink on math reasoning benchmarks, including AMC-23 and AIME-24~\cite{aime2024}."
- AsyncThink (Asynchronous Thinking): A reasoning paradigm where an LLM organizes its internal thinking into concurrently executable structures via Fork-Join actions. "we introduce asynchronous thinking (AsyncThink) as a new paradigm of reasoning with LLMs"
- Autoregressive Text Decoding: Token-by-token generation where the next token depends on previously generated tokens. "both perform autoregressive text decoding."
- Causal Language Modeling Objective: The standard training objective that predicts the next token given a left-to-right context. "fine-tune the LLM using the standard causal language modeling objective."
- Cold-Start Format Fine-Tuning: An initial SFT stage that teaches the model the syntax of protocol actions before RL training. "we perform a cold-start format fine-tuning on synthetic role-specific data to learn the syntax of AsyncThink actions."
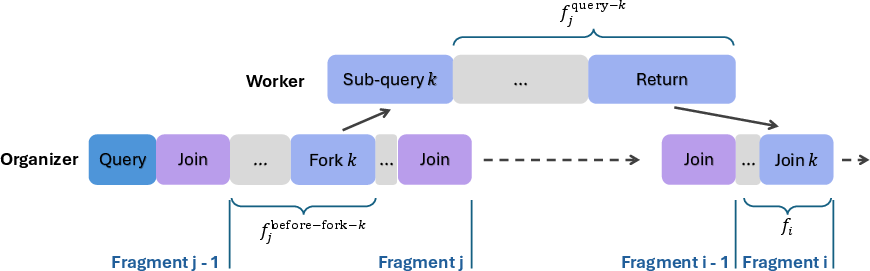
- Critical-Path Latency: The minimal sequential depth of an asynchronous execution, serving as a theoretical lower bound on inference time. "Critical-Path Latency measures the minimum sequential depth required for asynchronous thinking."
- DeepSeek-R1-style Reinforcement Learning: An RL training recipe inspired by DeepSeek-R1 that supervises outcome-verifiable reasoning. "which train the model with DeepSeek-R1-style reinforcement learning."
- Directed Acyclic Graph: A graph with no cycles used to model the structure of AsyncThink trajectories and their dependencies. "the thinking trajectory takes the form of as a directed acyclic graph"
- Dynamic Programming: A method used to compute critical-path latency by decomposing the latency across Join positions. "We present a dynamic programming method to compute the overall AsyncThink inference latency"
- Format Reward: A reinforcement learning penalty or bonus based on compliance with required action/output formats. "Format Reward: We penalize the organizer outputs that have format errors"
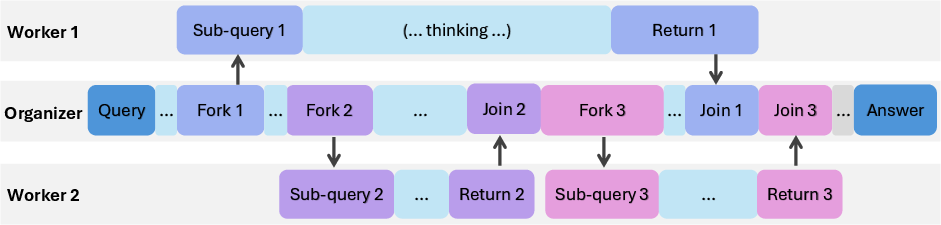
- Fork Tag: An action marker that assigns a sub-query to a worker to begin concurrent processing. "When a Fork tag appears, AsyncThink proposes a sub-query and assigns it to an available worker."
- Group Relative Policy Optimization (GRPO): A critic-free RL algorithm extended here to handle organizer-worker multi-trace episodes. "We extend the group relative policy optimization (GRPO) to handle the non-sequential thought samples in the reinforcement learning for AsyncThink."
- Group-Relative Advantages: Shared advantage estimates computed over organizer and worker traces within an episode. "we treat the organizer trace together with its corresponding worker traces as a single unit when computing rewards and group-relative advantages."
- Join Tag: An action marker where the organizer requests and merges a worker’s returned output, possibly pausing until completion. "Upon encountering a Join tag, AsyncThink synchronizes with the corresponding worker"
- Multi-Solution Countdown (MCD): A harder variant of the countdown task requiring multiple distinct valid solutions per query. "we extend the task to a harder version, named multi-solution countdown (MCD)."
- Organizer-Worker Thinking Protocol: A role-based scheme where an organizer coordinates workers via Fork-Join to structure concurrent reasoning. "The organizer-worker thinking protocol introduces two classes of roles for thinking"
- Organization Policy: The strategy that decides how agents collaborate and run concurrently to solve a task efficiently. "Organization policy refers to the strategy of organizing agents to work collaboratively and concurrently to complete tasks."
- Parallel Thinking: A method that generates multiple independent reasoning traces and aggregates outcomes afterward. "Current parallel thinking approaches, which typically generate independent thinking traces and aggregate them afterward"
- Reinforcement Learning with Verifiable Rewards (RLVR): Post-training that optimizes models using automatically checkable outcome signals. "reinforcement learning with verifiable rewards (RLVR) has emerged as a key post-training paradigm."
- Return Tag: A worker-side format marker delimiting the concise takeaways returned to the organizer. "The expected output format is ... thoughts ... \textlangle RETURN\textrangle~some takeaways\textlangle RETURN\textrangle~..."
- Sequential Thinking: A reasoning approach that proceeds along a single decoding trajectory without concurrency. "Sequential thinking employs a purely sequential decoding trajectory;"
- Sub-Query: A decomposed portion of the original problem assigned to a worker for concurrent processing. "Assign a thinking job to an available worker with a sub-query."
- Thinking Concurrency Ratio: A metric averaging the number of active workers over the critical path to quantify parallelism. "We define thinking concurrency ratio as"
- Thinking Concurrency Reward: An RL signal that incentivizes organizing work into concurrently executable parts without sacrificing correctness. "Thinking Concurrency Reward: This reward encourages the model to efficiently organize the thinking processes into concurrently executable parts."
Collections
Sign up for free to add this paper to one or more collections.

