PointSt3R: Point Tracking through 3D Grounded Correspondence
Abstract: Recent advances in foundational 3D reconstruction models, such as DUSt3R and MASt3R, have shown great potential in 2D and 3D correspondence in static scenes. In this paper, we propose to adapt them for the task of point tracking through 3D grounded correspondence. We first demonstrate that these models are competitive point trackers when focusing on static points, present in current point tracking benchmarks ($+33.5\%$ on EgoPoints vs. CoTracker2). We propose to combine the reconstruction loss with training for dynamic correspondence along with a visibility head, and fine-tuning MASt3R for point tracking using a relatively small amount of synthetic data. Importantly, we only train and evaluate on pairs of frames where one contains the query point, effectively removing any temporal context. Using a mix of dynamic and static point correspondences, we achieve competitive or superior point tracking results on four datasets (e.g. competitive on TAP-Vid-DAVIS 73.8 $\delta_{avg}$ / 85.8\% occlusion acc. for PointSt3R compared to 75.7 / 88.3\% for CoTracker2; and significantly outperform CoTracker3 on EgoPoints 61.3 vs 54.2 and RGB-S 87.0 vs 82.8). We also present results on 3D point tracking along with several ablations on training datasets and percentage of dynamic correspondences.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
PointSt3R: Point Tracking through 3D Grounded Correspondence — A Simple Explanation
What this paper is about
This paper introduces PointSt3R, a computer vision method that can follow any tiny point in a video (like a speck on a ball or a corner of a box) as it moves from frame to frame. It does this by matching points using 3D information, even when objects move, disappear behind something (occlusion), or the camera shakes.
In short: it’s a new way to “track any point” by comparing just two frames at a time, rather than relying on long video history.
The main questions the paper asks
- Can a model designed for building 3D scenes from images (MASt3R) be adapted to track points in videos, including moving objects?
- If we only look at two frames at a time, can we still track points well over a whole video?
- Can we predict whether a point is visible or hidden (occluded) in a frame?
- How does this approach compare to popular point trackers that use many frames and temporal context (like CoTracker)?
How the method works (in everyday language)
Think of tracking a point like finding the same sticker in two photos of the same scene:
- Traditional trackers watch the whole video like a movie, remembering how things move over time.
- PointSt3R treats it like a flipbook: it only looks at two pages at once and asks, “Where is this exact sticker in the next picture?”
Here’s the idea, step by step:
- The model learns to turn each pixel into a “feature,” which is like a unique fingerprint describing what’s around that pixel.
- To track a point, it compares the point’s fingerprint in one frame to all fingerprints in the other frame and chooses the best match (this is like finding the most similar pattern; they use a measure called cosine similarity).
- It uses 3D clues learned from MASt3R so the model understands the scene’s shape and layout, not just colors or textures. This helps when the camera moves or objects rotate.
- The authors add a “visibility head,” which is a small extra piece that predicts whether a point is visible in the other frame or hidden behind something.
- They teach (fine-tune) the model using synthetic videos where everything is known: where points move, when they’re occluded, and the 3D positions. This makes training reliable and diverse.
Two helpful terms explained:
- Static vs. dynamic: “Static” points are on things that don’t move (like a wall). “Dynamic” points are on moving or deforming things (like a person or a toy car).
- Occlusion: When a point is temporarily hidden (e.g., your hand goes behind a box).
What’s different here is that PointSt3R does not need:
- A long memory of earlier frames,
- Video-specific motion models,
- Or ground-truth depth at test time. It just needs pairs of frames and uses strong 3D-aware matching to track points.
What the researchers did to improve point tracking
- They started from MASt3R (a model great at 3D reconstruction and matching in static scenes).
- They fine-tuned it to handle moving points by adding:
- A special training loss that teaches the model to match moving points across frames.
- A visibility predictor to tell if a point should be visible in the other frame.
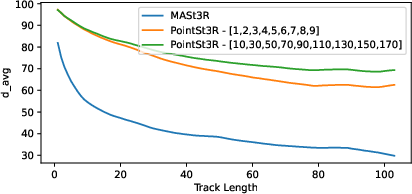
- They trained mostly on pairs of frames that are far apart in time (“long strides”), so the model learns to handle big motions and changes.
What they found (key results)
Across several benchmarks, PointSt3R performs competitively with top point trackers, even though it only looks at two frames at a time.
Highlights:
- On TAP-Vid-DAVIS (a popular real-world benchmark), PointSt3R gets strong accuracy (73.8 average), close to advanced trackers that use temporal context (CoTracker2/3 at about 75–77).
- It also predicts occlusion well (85.8% accuracy), again close to the specialized trackers.
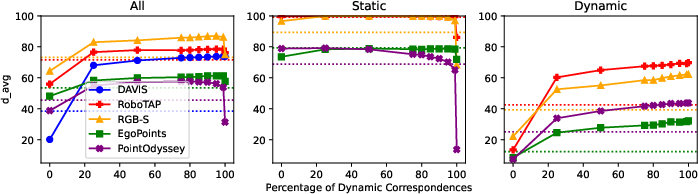
- On datasets with a lot of static background (like RGB-Stacking and RoboTAP), PointSt3R does very well and even beats some trackers in certain cases.
- On EgoPoints (egocentric videos with big camera motion), it improves over MASt3R and beats CoTracker2 on dynamic points, while being close to CoTracker3.
3D tracking:
- PointSt3R can also track points in 3D. When paired with a depth estimator (like ZoeDepth) or using its own 3D maps, it gets close to state-of-the-art 3D tracking performance on the TAP-Vid-3D mini benchmark.
Ablation insights (what makes it work better):
- Training with more dynamic examples helps a lot, but keeping a small mix of static cases avoids forgetting 3D grounding.
- Training with large time gaps between frames improves long-term tracking (useful for longer videos or faster motions).
- Using a mix of synthetic datasets makes the model more robust.
Why this is important
- Simplicity: PointSt3R shows you can get strong tracking by only comparing two frames at a time. That means fewer moving parts and easier deployment.
- Flexibility: It works for both 2D and 3D tracking and can tell when a point is occluded.
- Generalization: Because it’s grounded in 3D understanding, it handles camera motion and scene changes well, not just object motion.
- Practical impact: This could help in robotics (following a point on an object a robot is moving), video editing (tracking details without manual annotation), AR/VR (keeping virtual content attached to real-world points), and sports or science analysis (following small features precisely over time).
Final takeaway
PointSt3R turns point tracking into a simple “find-the-best-match” problem using strong 3D-aware features. By fine-tuning a 3D reconstruction model (MASt3R) to handle moving objects and occlusions, it reaches performance close to specialized multi-frame trackers—without needing their extra temporal machinery. This suggests that powerful 3D grounding plus smart pairwise matching is a clean, effective path for tracking points in dynamic, real-world videos.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These are framed to be actionable for future research.
- Lack of temporal modeling: The approach is strictly pairwise and does not exploit temporal consistency across frames. Explore lightweight temporal aggregation, cycle-consistency, or test-time refinement across multiple frames without sacrificing the pairwise simplicity.
- No trajectory-level post-processing: Tracks are formed by framewise nearest-neighbor matches without smoothing or outlier rejection. Evaluate the gains from simple post-processing (mutual checks, forward–backward consistency, temporal filtering) and quantify the trade-off with computational cost.
- Absence of geometric verification: Matching ignores estimated camera pose and epipolar constraints, increasing risk of mismatches in repetitive textures. Integrate pose-based search pruning, homography/epipolar checks, or geometric RANSAC within the pairwise pipeline.
- Limited occlusion reasoning: The model predicts visibility but does not use it to gate or suppress erroneous matches during tracking. Assess visibility-aware tracking strategies (e.g., output “untracked” during occlusion) and calibrate visibility confidence on real data.
- Synthetic-only training supervision: Fine-tuning uses synthetic datasets exclusively; domain gap to real videos is unquantified. Investigate pseudo-labeling on real videos, self-training, or domain adaptation techniques to close the synthetic-to-real gap.
- Encoder frozen during fine-tuning: Only decoders and heads are updated; the impact of unfreezing the encoder on dynamic correspondence and 3D consistency is unknown. Study partial/full encoder fine-tuning, with regularization or distillation to preserve 3D grounding.
- Catastrophic forgetting under dynamic-only supervision: The model loses 3D grounding when trained with 100% dynamic correspondences. Develop curriculum schedules, multi-task loss balancing, or knowledge distillation to retain static 3D competence while learning dynamics.
- Incomplete evaluation of 3D reconstruction quality: The paper reports 3D point tracking APD but not standard 3D reconstruction metrics post fine-tuning. Quantify how dynamic fine-tuning affects camera pose, depth, and pointmap accuracy on standard 3D benchmarks.
- Weak re-identification under severe appearance change: On EgoPoints dynamic points, performance lags CoTracker3. Analyze failure modes (illumination change, long-term occlusion, motion blur) and evaluate feature augmentation or contrastive strategies tailored for re-ID.
- Resolution and scalability constraints: Inference is fixed at 512×384 with dense all-pairs feature similarity. Characterize runtime, memory, and accuracy scaling with image resolution; evaluate coarse-to-fine search, approximate nearest neighbor, or patch-level acceleration.
- No per-match uncertainty estimates: The model does not output confidence on 2D correspondences at inference. Add calibrated uncertainty or score heads and evaluate their utility for downstream applications and robust track filtering.
- Limited use of relative pose and intrinsics for 3D: 3D lifting is compared both with DUSt3R pointmaps and ZoeDepth; however, end-to-end estimation of intrinsics/pose is not explored. Investigate joint learning of intrinsics and pose (e.g., DUSt3R/VGGT-style) to improve 3D tracking without GT intrinsics.
- Sparse analysis of stride generalization: Stride ablations are shown mainly on TAP-Vid-DAVIS; generalization to very long time gaps and other datasets is underexplored. Benchmark performance vs. time gap across datasets and content types.
- Limited dataset diversity for dynamics: Synthetic motion types may not cover complex non-rigid, specular, reflective, or thin-structure cases found in the wild. Expand training with richer dynamic phenomena, photometric effects, lens artifacts, and more varied real-world dynamics.
- No breakdown by scene/content attributes: There is no quantitative failure analysis by texture density, motion magnitude, occlusion length, or camera motion type. Provide stratified analyses to pinpoint when pairwise matching fails and guide targeted improvements.
- Visibility head training–testing mismatch: Visibility is trained on synthetic labels and evaluated on real occlusions with only modest accuracy gaps. Investigate domain adaptation for visibility or multi-task learning that ties visibility to geometric features.
- No identity management across very long occlusions: Re-appearance handling and identity switches are not addressed. Study cycle-closure constraints, memory-based re-identification, or graph-based linking while retaining the pairwise core.
- Matching strategy simplicity: Pure cosine-similarity nearest neighbor may underperform in crowded or repetitive regions. Test optimal transport/Sinkhorn matching, mutual nearest neighbor enforcement, or learned retrieval heads.
- Use of feature interpolation untested: Bilinear interpolation for feature sampling is used without ablation. Evaluate nearest-neighbor vs. bilinear vs. learned sub-pixel refinement and their impact on accuracy.
- Efficiency of negative sampling: When positives are scarce at large strides, negatives are padded. Examine hard-negative mining, temperature schedules, or queue-based contrastive schemes to stabilize InfoNCE training at long strides.
- Intrinsics-free 3D tracking limitations: Results without ground-truth intrinsics are competitive but still lag behind with GT intrinsics. Explore jointly estimating or refining intrinsics at inference and quantify gains across focal length ranges and distortion profiles.
- Occlusion granularity and depth ordering: The visibility head predicts binary visible/occluded only. Extend to occlusion depth ordering, occlusion duration prediction, or z-order reasoning and assess benefits for long-term tracking.
- Lack of integration with motion priors: The model does not exploit even weak motion models (e.g., constant velocity) that could regularize tracking. Evaluate minimalistic motion priors or consistency penalties that keep the pairwise spirit but boost robustness.
- No analysis of query density scaling: While all queries in a frame can be tracked simultaneously, scaling with thousands of points is not benchmarked. Profile throughput vs. number of queries and test batched or shared-computation strategies.
- Robustness to camera artifacts: Rolling shutter, auto-exposure/white balance changes, and lens distortion are unaddressed. Introduce data augmentation and/or distortion-aware modules and quantify robustness.
- Limited 3D metric scope: APD with fixed thresholds and median scaling is reported; alternative metrics (ATE, RPE, scale-consistent APD, long-horizon drift) are not evaluated. Provide a broader 3D evaluation suite to diagnose failure modes.
- Data scaling laws unknown: The method is fine-tuned with 10k samples; performance vs. data size is not studied. Characterize scaling curves and identify diminishing returns or needed data diversity.
- Benchmark labeling approximations: Dynamic splits for RoboTAP/RGB-S are heuristically defined (static camera + movement >10% of screen). Assess sensitivity to this heuristic and, if possible, release standardized dynamic labels or evaluation protocols.
- Integration with temporal trackers as a hybrid: The paper compares to trackers but does not test PointSt3R features as inputs to temporal trackers (à la VGGT+CoTracker). Evaluate hybrid schemes and measure gains vs. added complexity.
Glossary
- 3D grounded correspondence: Framing point tracking as establishing matches using 3D geometry rather than temporal context or depth. "This allows us to formulate point tracking as a 3D grounded correspondence task, which is attractive as it does not require temporal context or depth whilst simultaneously being able to track in both 2D and 3D."
- 4D correlations: Similarity computations across space and time used in some tracking approaches. "A number of new models have since appeared with different methods such as 4D correlations \cite{cho2024local}..."
- Ablations: Controlled experiments that remove or vary components to assess their impact. "We also present results on 3D point tracking along with several ablations on training datasets and percentage of dynamic correspondences."
- APD (Average Points under Distance): A 3D tracking metric measuring the proportion of points within fixed distance thresholds. "APD (average points under distance) metric with the fixed thresholds of used in \cite{feng2025st4rtrack}, and median global scaling on the PStudio minival set."
- Balanced cross-entropy loss: A class-balanced variant of cross-entropy to handle skewed visibility distributions. "We use a balanced cross-entropy loss for training the visibility heads, as the distribution is often skewed in the direction of visible points."
- Bilinear interpolation: A method for continuous indexing of feature maps at non-integer coordinates. "For all inference, we use the input resolution of and bilinear interpolation when indexing correspondence features."
- Bootstrapping (on real-world data): Self-labeling or iterative refinement using real data to improve models. "...and bootstrapping on real-world data~\cite{sun2024refining, doersch2024bootstap, karaev2024cotracker3}."
- Camera pose estimation: Determining the position and orientation of the camera in 3D space. "...accommodates a number of downstream tasks including 3D reconstruction, camera pose estimation, and depth estimation."
- Camera-stabilized coordinates: 3D coordinates expressed in a frame where camera motion is compensated. "For a pixel correspondence between images from two timesteps, $i_{\textrm{img},j_{\textrm{img} \in \mathbb{R}^2$, we obtain their 3D camera-stabilized coordinates $i_{\textrm{world}, j_{\textrm{world} \in \mathbb{R}^3$."
- Confidence maps: Per-pixel confidence estimates used to weight losses. "In practice we use a confidence-weighted version of this loss, sharing confidence maps with the regression loss."
- Confidence-weighted regression: A regression loss that down-weights uncertain predictions. "The confidence weighted regression is given by..."
- Cosine similarity: A measure of similarity between feature vectors based on the cosine of the angle between them. "compute its cosine similarity to each feature in the target frame"
- Descriptors (feature descriptors): Learned per-pixel feature vectors used for matching across images. "produces descriptors for cross-image matching"
- Dynamic correspondences: Matches between points that move in the world across frames. "We also present results on 3D point tracking along with several ablations on training datasets and percentage of dynamic correspondences."
- Egocentric (videos): First-person video perspectives with large camera motion and re-identification challenges. "...a benchmark of 517 egocentric videos with an emphasis on large camera motion and point re-id."
- Extrinsics: Camera parameters describing its position and orientation relative to the world. "camera parameters (intrinsics and extrinsics) and depth for each pixel."
- Feature-based pixel correspondence head: A network head that outputs features for per-pixel matching across images. "We then use nearest-neighbour correspondence from the feature-based pixel correspondence head as the base of point tracking."
- Feature matching: The process of associating features across images to establish correspondences. "...has shown that learning 3D geometry and feature matching together benefits both tasks..."
- Global median scaling: A normalization technique to resolve scale ambiguity by scaling trajectories to the median. "We choose to follow St4RTrack~\cite{feng2025st4rtrack} and use global median scaling, due to scale ambiguity..."
- Ground truth intrinsics matrix: The true camera calibration matrix used for accurate 3D lifting. "``w G.T'': Results with the ground truth intrinsics matrix for lifting to 3D."
- InfoNCE loss: A contrastive learning objective used to train correspondence matching. "This is achieved with an infoNCE loss~\cite{oord2018representation}, applied for the ground-truth correspondences..."
- Intrinsics matrix: Camera parameters describing focal length and principal point used to project between 2D and 3D. "...the camera intrinsics matrix (or an estimate) to lift these to 3D."
- Nearest-neighbour correspondence: Assigning matches by choosing the closest feature in the target frame under a similarity metric. "We then use nearest-neighbour correspondence from the feature-based pixel correspondence head as the base of point tracking."
- Occlusion: Situations where points become invisible due to being blocked or leaving the field of view. "To model occlusion, we add a new head to each branch to predict the visibility of each pixel..."
- Occlusion accuracy (OA): The accuracy of predicting whether points are visible or occluded. "Occlusion accuracy () on TAP-Vid-DAVIS"
- Pairwise (processing): Operating on two frames at a time without temporal sequences. "As PointSt3R is inherently pairwise, % we feed the model and ..."
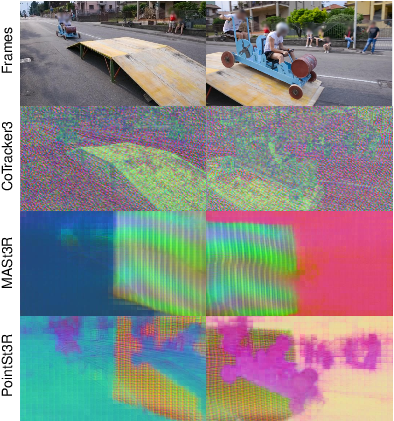
- PCA (Principal Component Analysis): A dimensionality reduction technique used to visualize feature maps. "Here we perform PCA on the two feature maps output by MASt3R..."
- Pointmaps: Dense 3D coordinate maps assigning a 3D point to each pixel. "DUSt3R~\cite{wang2024dust3r} introduced a powerful approach that produces a pair of 3D pointmaps for a pair of images..."
- Point re-id (re-identification): Recognizing the same point across large time or viewpoint changes. "...with an emphasis on large camera motion and point re-id."
- Regression heads: Network components that directly predict continuous quantities like 3D coordinates. "...they can be easily modified with new regression heads to compute a number of related downstream tasks..."
- Scale ambiguity: The inherent indeterminacy of absolute scale when reconstructing from monocular inputs. "...use global median scaling, due to scale ambiguity..."
- Static/dynamic segmentation: Classifying scene elements as stationary or moving to aid reconstruction/tracking. "...introducing additional components to solve the problems posed by dynamic scenes, such as static/dynamic segmentation..."
- Temporal context: Using information from multiple consecutive frames to inform tracking. "...using 3D grounded correspondence on pairs of frames across a video, without any temporal modelling."
- Temporal strides: The time gaps between sampled frames used during training to learn long-term correspondences. "...image pairs of temporal strides ..."
- Time-aware reconstruction: Methods that explicitly model time to handle motion in 3D reconstruction. "...such as static/dynamic segmentation, 3D tracking, and time-aware reconstruction."
- Triplane representations: Efficient 3D scene representations using three orthogonal feature planes. "Works include SpaTracker~\cite{xiao2024spatialtracker}, which utilises pre-trained depth estimators and triplane representations for efficiency..."
- Visibility head: A prediction head that estimates whether each point is visible or occluded across frames. "We propose to combine the reconstruction loss with training for dynamic correspondence along with a visibility head..."
- World coordinate frame: A common 3D reference frame in which scene points are expressed. "...represent all points in one image in the world coordinate frame of the second, as done in standard 3D reconstruction."
- δ_avg (average tracking accuracy): A 2D tracking metric averaging accuracy over multiple pixel thresholds. "The metric used exclusively for all 2D point tracking results is the average tracking accuracy $\delta_{\text{avg$."
Practical Applications
Immediate Applications
Below are applications that can be deployed now with PointSt3R’s pairwise 2D/3D correspondence and visibility prediction, given typical modern GPU resources and standard video inputs.
- Track-any-point plug-in for video editing and VFX
- Sector: Media/Entertainment, Software
- Potential tools/products/workflows: A Nuke/After Effects/Premiere plug-in that lets editors select arbitrary pixels (not just keypoints) and track them across frames for rotoscoping, paint-out, stabilization, motion transfer, and match-moving. Visibility head helps automate occlusion handling, reducing manual keyframing.
- Assumptions/dependencies: GPU acceleration for reasonable latency; variable performance on highly repetitive textures; 2D-only workflows require no intrinsics; 3D tasks may need depth or camera intrinsics.
- AR point anchoring for mobile and wearable devices
- Sector: AR/VR, Software
- Potential tools/products/workflows: SDK that anchors AR overlays to arbitrary scene points using only pairwise frames, improving overlay stability in egocentric scenarios and during occlusions; works without temporal models and can be parallelized per frame pair.
- Assumptions/dependencies: Mobile inference may need model distillation/quantization; 3D anchoring benefits from intrinsics or monocular depth (e.g., ZoeDepth) and calibration.
- Robotics imitation learning and teleoperation tracking
- Sector: Robotics, Industrial Automation
- Potential tools/products/workflows: Drop-in tracker for few-shot visual imitation (RoboTAP-style) to follow target points on objects without dedicated temporal models; visibility predictions flag when a point is occluded, preventing control drift.
- Assumptions/dependencies: Real-time performance depends on hardware and model optimization; strong domain gap possible if trained mostly on synthetic data; 3D tracking requires depth or camera intrinsics.
- Egocentric assistance and wearable capture (hands/objects)
- Sector: Consumer Tech, Accessibility
- Potential tools/products/workflows: Assistive apps that follow fingertip/tool/object points for guidance, instruction overlay, and logging (EgoPoints-style); enables robust tracking across large camera motions without maintaining long temporal windows.
- Assumptions/dependencies: Challenging dynamic points may still benefit from temporal smoothing; occlusion head thresholding may need tuning per device.
- Industrial inspection and maintenance video analytics
- Sector: Manufacturing, Energy, Infrastructure
- Potential tools/products/workflows: Tracking cracks, bolts, weld seams, or wear points across inspection footage (drones/handheld), leveraging pairwise matching to rapidly process large video batches; occlusion-aware flags when targets leave view.
- Assumptions/dependencies: Lighting/texture variability can cause ambiguous matches; 3D analysis requires intrinsics and calibrated lenses or depth estimation.
- Sports analytics and broadcast augmentation
- Sector: Sports, Media
- Potential tools/products/workflows: Tracking the ball, line markers, or player gear points for trajectory visualization and augmented replays; pairwise operation supports fast parallelization for multi-camera feeds.
- Assumptions/dependencies: High-speed motion and blur may reduce accuracy; domain adaptation for stadium lighting and repetitive textures; 3D requires known intrinsics or external calibration.
- Semi-automatic dataset annotation and bootstrapping for point tracking research
- Sector: Academia, Software
- Potential tools/products/workflows: Use PointSt3R to pre-label correspondences and occlusion states in real-world videos, then human-correct; feed pseudo-labels to train/finetune temporal trackers (CoTracker-like) or geometry backbones (VGGT).
- Assumptions/dependencies: Quality depends on domain gap and video diversity; QA tooling is needed to surface uncertain matches.
- SLAM/visual odometry support in dynamic scenes (2D/3D correspondence module)
- Sector: Robotics, Mapping
- Potential tools/products/workflows: Plug-in correspondence module to complement SLAM systems in the presence of dynamic objects (static/dynamic point separation via 3D grounded matching), reducing drift in front-end feature association.
- Assumptions/dependencies: Full SLAM still needs temporal filtering and pose graph optimization; accurate intrinsics and lens distortion handling are critical for robust 3D grounding.
Long-Term Applications
These applications are promising but may need further research, real-world data scaling, optimization for embedded deployment, regulatory compliance, or additional pipeline components.
- Autonomous driving and mobile robotics perception under occlusions
- Sector: Automotive, Robotics
- Potential tools/products/workflows: Point-level tracking of dynamic scene elements (pedestrians, cyclists, vehicle parts) with occlusion-aware signals to improve perception stacks; pairwise tracking parallelizes across time windows.
- Assumptions/dependencies: Real-time constraints on embedded hardware; extensive domain adaptation; safety-critical validation; multi-sensor fusion.
- Surgical tool and anatomy tracking for intraoperative guidance
- Sector: Healthcare
- Potential tools/products/workflows: Point-level 2D/3D tracking of instruments and tissue landmarks in endoscopy or surgical videos, assisting augmented guidance and motion analysis during occlusions.
- Assumptions/dependencies: Medical-grade latency and accuracy; regulatory approval; robust performance across patient variability and imaging systems; reliable intrinsics and sterile runtime setups.
- Persistent world anchoring in AR glasses with 3D tracking
- Sector: AR/VR
- Potential tools/products/workflows: Long-term anchoring of UI elements and digital twins to arbitrary real-world points across sessions, leveraging pairwise 3D correspondence without heavy temporal state.
- Assumptions/dependencies: Device calibration, consistent intrinsics estimation, environment changes; low-power inference and on-device optimization.
- Industrial digital twins with dynamic 3D tracking of components
- Sector: Manufacturing, Energy
- Potential tools/products/workflows: Continuous 3D point tracking of moving and deforming components to sync video streams and CAD models for predictive maintenance, line optimization, and quality assurance dashboards.
- Assumptions/dependencies: Accurate depth/intrinsics; integration with PLM/MES systems; robust handling of repetitive textures and specular surfaces.
- Large-scale satellite/aerial video tracking for environmental monitoring
- Sector: Earth Observation, Public Policy
- Potential tools/products/workflows: Tracking arbitrary terrain points, infrastructure features, or moving assets across aerial sequences to measure change, erosion, or construction progress; visibility head helps handle cloud occlusions.
- Assumptions/dependencies: Domain adaptation to large scales and varying optics; georegistration and altitude data; regulatory considerations for surveillance use.
- Privacy-conscious surveillance analytics with occlusion-aware tracking
- Sector: Policy, Public Safety
- Potential tools/products/workflows: Systems that track points on objects rather than identities, supporting anonymized analytics (e.g., flow patterns, occupancy) with explicit occlusion handling; configurable to reduce re-identification risk.
- Assumptions/dependencies: Governance frameworks for ethical use; bias auditing; technical mechanisms to avoid identity inference and maintain compliance (GDPR/CCPA).
- Physics-informed motion analysis in sports, biomechanics, and education
- Sector: Sports Science, Education
- Potential tools/products/workflows: 3D point tracking to estimate motion trajectories and measure kinematics of limbs or equipment for coaching and lab settings; pairwise approach eases data-parallel processing of long recordings.
- Assumptions/dependencies: Accurate scale via intrinsics or external calibration; integration with biomechanical models; public datasets covering domain variability.
- Real-time embedded point tracking for low-power devices
- Sector: IoT, Edge Computing
- Potential tools/products/workflows: Distilled/quantized PointSt3R variants enabling pairwise point tracking and occlusion prediction on edge devices (e.g., glasses, robots, drones) without large temporal buffers.
- Assumptions/dependencies: Significant model compression and hardware-aware optimizations; potential trade-offs in accuracy; robust operation under limited memory and variable lighting.
- Automated content creation pipelines (video-to-3D motion retargeting)
- Sector: Media/Entertainment, Software
- Potential tools/products/workflows: End-to-end pipeline where tracked 2D points are lifted to 3D (via depth/intrinsics) and retargeted onto 3D rigs for animation and special effects, with occlusion-aware continuity checks.
- Assumptions/dependencies: Reliable camera calibration or depth estimation; scale ambiguity resolution; integration with DCC tools and motion clean-up modules.
- Research platforms for generalized 2-frame dynamic correspondence
- Sector: Academia
- Potential tools/products/workflows: Open benchmarks and toolkits building on PointSt3R’s pairwise formulation to study dynamic matching losses, occlusion prediction, stride training, and static/dynamic separation; teacher–student pipelines for multi-frame trackers.
- Assumptions/dependencies: Broader real-world datasets beyond synthetic training; standardized protocols for 2D/3D evaluation and occlusion metrics; reproducible intrinsics estimation workflows.
Common assumptions and dependencies across applications
- Depth and camera intrinsics: 3D tracking often needs reliable intrinsics or depth estimation (e.g., ZoeDepth). Without ground-truth intrinsics, accuracy can drop; global scale remains ambiguous for monocular setups.
- Domain gap: The model is fine-tuned on synthetic data (PointOdyssey, Kubric, DynamicReplica). Real-world deployment may require domain adaptation, additional finetuning, or robust post-processing.
- Real-time constraints: PointSt3R is pairwise and parallelizable, but inference speed and memory footprint depend on hardware; embedded use may require distillation/quantization.
- Occlusion handling: The visibility head provides useful signals but may need threshold calibration per environment and camera.
- Texture ambiguity and repetitive patterns: Pairwise nearest-neighbor matching can mis-associate features on repetitive textures; workflows benefit from geometric checks or temporal smoothing when permissible.
- Long-track robustness: Larger stride training improves long-track accuracy, but extremely long sequences may still benefit from optional temporal post-processing in production pipelines.
Collections
Sign up for free to add this paper to one or more collections.

