LangHOPS: Language Grounded Hierarchical Open-Vocabulary Part Segmentation
Abstract: We propose LangHOPS, the first Multimodal LLM (MLLM) based framework for open-vocabulary object-part instance segmentation. Given an image, LangHOPS can jointly detect and segment hierarchical object and part instances from open-vocabulary candidate categories. Unlike prior approaches that rely on heuristic or learnable visual grouping, our approach grounds object-part hierarchies in language space. It integrates the MLLM into the object-part parsing pipeline to leverage its rich knowledge and reasoning capabilities, and link multi-granularity concepts within the hierarchies. We evaluate LangHOPS across multiple challenging scenarios, including in-domain and cross-dataset object-part instance segmentation, and zero-shot semantic segmentation. LangHOPS achieves state-of-the-art results, surpassing previous methods by 5.5% Average Precision (AP) (in-domain) and 4.8% (cross-dataset) on the PartImageNet dataset and by 2.5% mIOU on unseen object parts in ADE20K (zero-shot). Ablation studies further validate the effectiveness of the language-grounded hierarchy and MLLM driven part query refinement strategy. The code will be released here.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
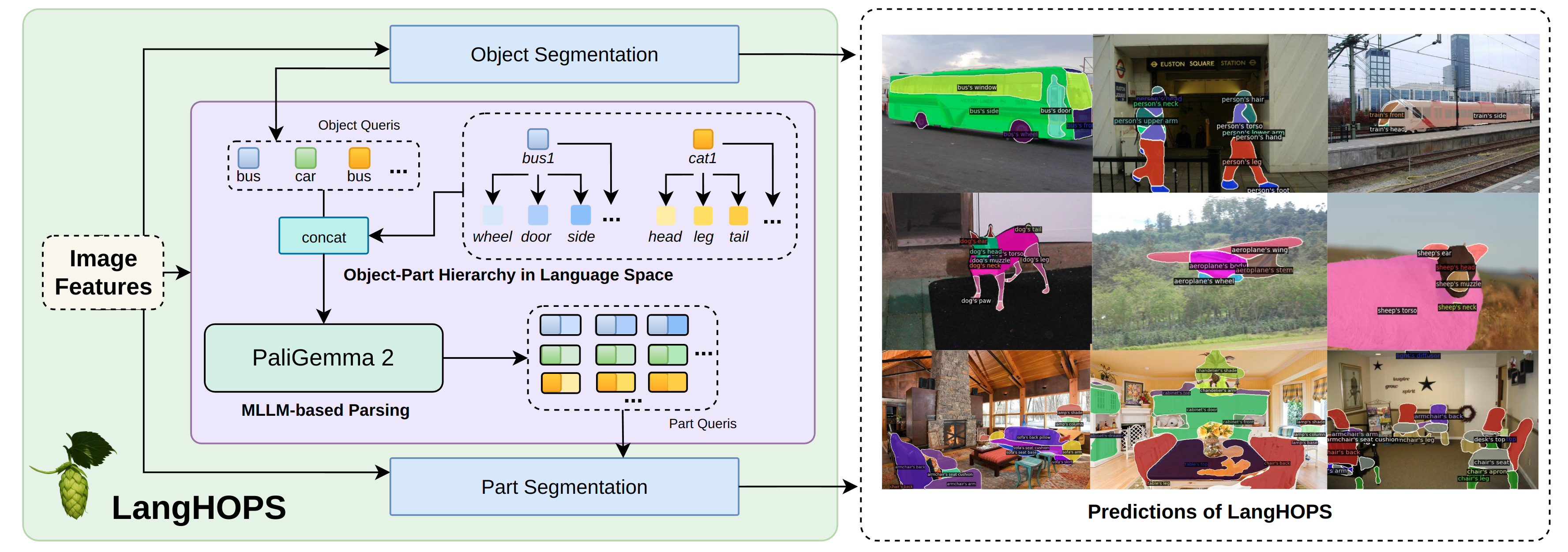
This paper introduces LangHOPS, a new AI system that can look at a picture, find the objects in it (like a bus or a cat), and then carefully cut out their parts (like wheels, windows, head, tail) even if it has never seen those exact part names before. This job is called “open-vocabulary object–part instance segmentation.” “Open-vocabulary” means it can handle new, user-given labels; “instance” means it separates different copies of the same thing (cat 1 vs. cat 2); and “part segmentation” means it finds the pieces that make up each object.
What were the researchers trying to do?
They had three main goals:
- Make a system that can find objects and their parts at the same time, not just objects.
- Handle different “levels” of detail—sometimes you want big parts (like “car body”), other times tiny parts (like “screws”).
- Work even when the part names are new or come from different datasets, so it can generalize to new situations.
How did they do it?
Think of the system as a team with four steps, using both pictures and language to reason:
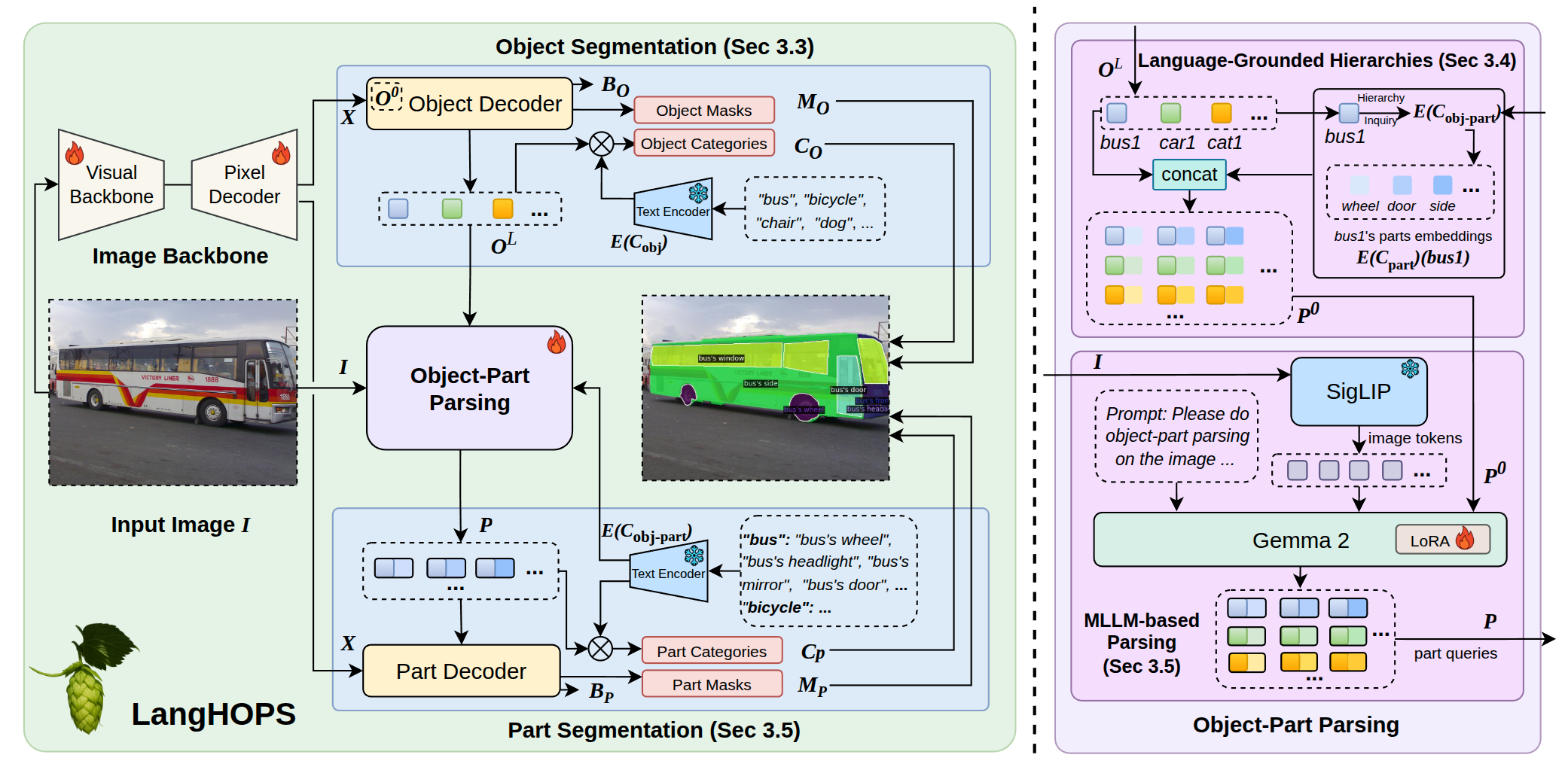
- Step 1: Find the objects
- The system first detects and outlines each object in the image (for example, “bus 1,” “bus 2”). This is like drawing a neat outline around every bus in a photo.
- Step 2: Build a “parts map” using language
- Instead of guessing parts just from image patterns, LangHOPS uses language knowledge to understand which parts belong to which objects—like a dictionary that knows a bus has wheels, windows, and doors, while a cat has a head, body, legs, and tail. This “language space” acts like an idea map that links objects to their parts.
- Step 3: Ask a multimodal LLM (MLLM) for help
- A multimodal LLM is an AI that can read text and look at images. LangHOPS gives it the object information and the possible part names (like “bus’s wheel,” “bus’s door”) and asks it to refine these “questions” so they match the actual image. This helps the system choose the right parts and the right level of detail (coarse vs. fine).
- Step 4: Cut out the parts
- With the refined “part questions,” the system then segments (cuts out) each part from the image, producing clean masks for “bus 1’s wheel 1,” “bus 1’s wheel 2,” and so on.
Two extra notes in simple terms:
- “Language-grounded” means the system uses words and descriptions to guide what to look for, not just pixel patterns.
- “Granularity” means how detailed you want to be—like breaking a LEGO model into big chunks or tiny bricks.
What did they find?
The team tested LangHOPS on several challenging benchmarks and scenarios:
- Stronger accuracy than previous methods:
- On a car-and-animals parts dataset called PartImageNet, LangHOPS beat earlier methods by about 5.5% (when trained and tested on similar data) and by about 4.8% (when trained on one dataset and tested on a different one).
- In a “zero-shot” test (where the model must segment unseen parts) on ADE20K, LangHOPS improved unseen-part accuracy by about 2.5% mIoU.
- Better at adapting to different detail levels:
- When trained with more varied datasets (including ones with different part granularities), LangHOPS gained up to +10% in overall performance on PartImageNet.
- Parts help objects, too:
- Training the system to segment parts didn’t just help parts—it also improved object segmentation by about 5.4% on one dataset. In other words, learning parts sharpened the model’s understanding of whole objects.
Overall, the results show that connecting images to language (to understand object–part hierarchies) and using an MLLM for reasoning leads to cleaner, more accurate part segmentation—especially when the labels are new or the detail level changes.
Why does this matter?
- Practical uses:
- Robotics: A robot needs to know not just “this is a microwave,” but also “this is the handle” or “this is the door hinge” to interact correctly.
- Image editing and AR: Want to recolor only a car’s wheels or replace a laptop’s screen in a photo? Precise part masks make that easy.
- Education and search: Systems can better explain what things are made of and help people find exactly the parts they care about.
- Bigger picture:
- LangHOPS shows that mixing vision with language (especially using powerful LLMs) helps computers understand scenes in a more human-like, structured way. It can handle new terms and switch between coarse and fine detail on demand.
- Limitations and next steps:
- It’s more computationally heavy than some older methods because it uses a big LLM.
- It mainly trained on common objects and parts, so very specialized tasks might still need fine-tuning.
- A promising future direction is extending these ideas from 2D images to 3D understanding, which could help in AR, VR, and robotics.
In short, LangHOPS is a step toward smarter vision systems that can understand not just what is in a picture, but how the pieces fit together—much like how people think about “wholes” and “parts.”
Collections
Sign up for free to add this paper to one or more collections.

