- The paper demonstrates that RL-based congestion control mechanisms achieve competitive fairness and TCP friendliness, yet struggle with rapid network dynamics.
- The paper finds that experiments using Mininet reveal models like Astraea maintain superior fairness under intra- and inter-RTT variability compared to traditional algorithms.
- The paper concludes that despite potential gains in throughput and responsiveness, further improvements in adaptability and training data are essential.
Learning-Based vs Human-Derived Congestion Control: An In-Depth Experimental Study
This essay provides an analysis and summary of the paper "Learning-Based vs Human-Derived Congestion Control: An In-Depth Experimental Study" (2510.25105). The paper conducts a systematic experimental evaluation comparing learning-based congestion control approaches with traditional human-derived algorithms, focusing on elements such as fairness, efficiency, and responsiveness.
Methodology and Experimental Setup
The authors conduct their experimental evaluations using Mininet to emulate network conditions, given its balance between high fidelity and reproducibility. The congestion control (CC) algorithms tested include both human-derived policies like TCP Cubic and BBR (version 3), and various reinforcement learning (RL) based models such as Orca, Sage, Astraea, and PCC Vivace.
Selected CC Approaches
The study evaluates several well-known CC algorithms:
- Orca incorporates AIMD heuristics and promises fairness by embedding power within its reward function.
- Sage uses pre-collected trace data including established schemes like Cubic and Vegas.
- Astraea introduces fairness directly into its reward mechanism.
- PCC Vivace implements gradient ascent to dynamically adapt sending rates, promoting fairness in flow allocations.
The performance of these RL-based models is compared against Cubic and BBRv3 through experiments involving both single- and multi-bottleneck scenarios.
Fairness Evaluation
An extensive evaluation of fairness in bandwidth allocation considers various scenarios, including intra-RTT fairness, inter-RTT fairness, and fairness under variable bandwidths.
- Intra-RTT Fairness: Astraea performs remarkably well within its training parameter range, while Orca and Sage exhibit variability based on queuing conditions and RTT values.
- Inter-RTT Fairness: Astraea continues to perform strongly (Fig. 1), whilst Vivace and Orca experience significant fairness degradation when competing flows have differing RTTs.
- Fairness in Parking Lot Topology: In a multi-bottleneck setting, Astraea maintains a near-proportional allocation, demonstrating excellent fairness across different flow configurations.

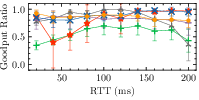
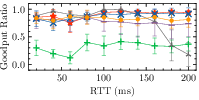
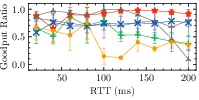
Figure 1: TCP flow first, Buffer Size: 0.2\times BDP
Backward Compatibility (TCP Friendliness)
The paper also investigates how RL-based models coexist with Cubic, measuring TCP friendliness through two-flow and multi-flow setups:
- Two-Flow Setup: Astraea is generally TCP friendly, allowing Cubic flows to share the bandwidth effectively under larger buffer settings.
- Multi-Flow Setup: Astraea and Sage exhibit consistent friendliness to Cubic as the count of concurrent Cubic flows increases (Fig. 2).
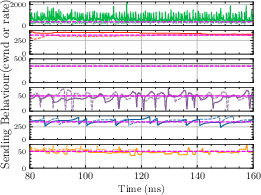
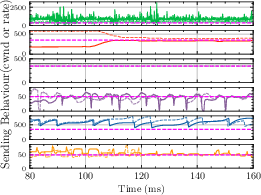
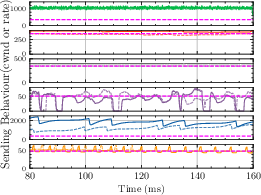
Figure 2: Buffer Size: 0.2\times BDP
Efficiency and Responsiveness
The authors measure efficiency through aggregate network throughput and latency, revealing that:
- Orca shows inefficiencies in environments with fluctuating RTTs, largely due to its reliance on static minimum RTT estimates.
- Astraea and Sage offer slightly better adaptability but struggle during frequent bandwidth changes, heavily influenced by the parameter spaces used during training (Fig. 3).
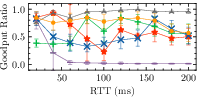
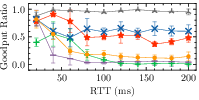
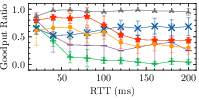
Figure 3: Buffer Size: 0.2\times BDP
The responsiveness analysis also underscores limitations in RL models’ ability to adapt to sudden changes in network conditions, demonstrating marked performance gaps compared to human-driven models like Cubic.
Conclusion
The study concludes that while RL-based congestion control mechanisms display promising adaptability and fairness within certain conditions, significant challenges remain. Specifically, generalizability and responsiveness to fast-changing network dynamics require further enhancement.
Future directions should include refining training datasets to encompass a broader range of network conditions and further integrating fairness and latency considerations directly into the learning objective. It suggests the exploration of hybrid models that dynamically adjust policies based on real-time environmental cues as a potential direction for future research efforts.