Game-TARS: Pretrained Foundation Models for Scalable Generalist Multimodal Game Agents
Abstract: We present Game-TARS, a generalist game agent trained with a unified, scalable action space anchored to human-aligned native keyboard-mouse inputs. Unlike API- or GUI-based approaches, this paradigm enables large-scale continual pre-training across heterogeneous domains, including OS, web, and simulation games. Game-TARS is pre-trained on over 500B tokens with diverse trajectories and multimodal data. Key techniques include a decaying continual loss to reduce causal confusion and an efficient Sparse-Thinking strategy that balances reasoning depth and inference cost. Experiments show that Game-TARS achieves about 2 times the success rate over the previous sota model on open-world Minecraft tasks, is close to the generality of fresh humans in unseen web 3d games, and outperforms GPT-5, Gemini-2.5-Pro, and Claude-4-Sonnet in FPS benchmarks. Scaling results on training-time and test-time confirm that the unified action space sustains improvements when scaled to cross-game and multimodal data. Our results demonstrate that simple, scalable action representations combined with large-scale pre-training provide a promising path toward generalist agents with broad computer-use abilities.
First 10 authors:





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Game-TARS, a smart computer agent that can play many different video games and use computers in a human-like way. Instead of relying on special controls for each game, Game-TARS uses the same basic actions humans use—moving the mouse and pressing keys—to work across lots of environments (like desktop apps, web pages, 2D/3D games, and simulators). The authors show that by training this agent on a huge amount of mixed data, it becomes more general and powerful, handling new games and tasks much better than previous models.
Key Objectives
Here are the main questions the paper tries to answer:
- Can we build one agent that works well across many games and computer environments without redesigning controls each time?
- Will using “human-native” actions (mouse and keyboard) make training scalable and help the agent generalize to new tasks?
- Can combining “thinking” (reasoning) with “doing” (actions) help the agent plan better, act more accurately, and remember long tasks?
- Does large-scale pretraining and targeted fine-tuning lead to real performance gains in tough benchmarks like open-world Minecraft and fast-paced FPS games?
Methods and Approach (Explained Simply)
The authors designed and trained Game-TARS with several key ideas. Think of these like building blocks:
One Action Space for Everything: Keyboard + Mouse
- Instead of writing custom action commands for each game (like “craft item” in Minecraft or “open folder” on Windows), the agent only uses three simple actions:
- Move the mouse:
mouseMove(dx, dy) - Click the mouse:
mouseClick(button) - Press keys:
keyPress(keys)
- Move the mouse:
- Analogy: It’s like teaching someone to use any computer by just showing them how to move the mouse and press keys—these are universal. The agent learns timing and rhythm (how long to hold keys, how fast to move the mouse) from experience.
Think Then Act, But Only When It Matters (Sparse ReAct)
- The agent follows a “ReAct” pattern: it reasons (thinks) and then takes an action.
- “Sparse thinking” means it doesn’t think out loud every single frame (50–100 ms); it only explains its reasoning at important moments—like planning, changing strategy, or summarizing.
- Analogy: In sports, you don’t stop and explain every step; you think carefully at key times (before a play, during a tough decision), then move quickly.
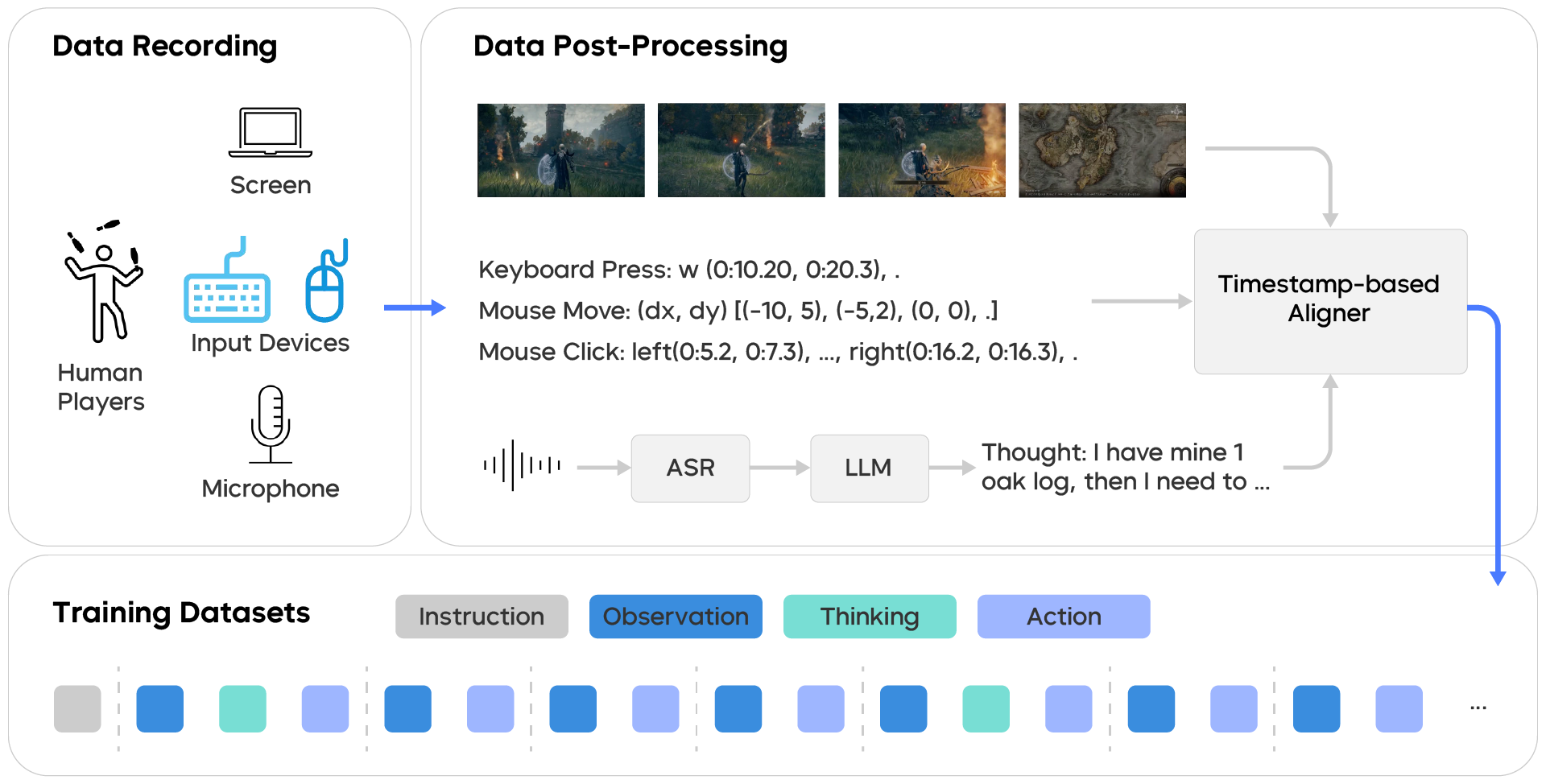
Collecting Smart Training Data: Think-Aloud + Precise Syncing
- Humans played games while speaking out their thoughts (“think-aloud”), and the system recorded:
- Screen images (what the agent sees)
- Mouse/keyboard inputs (what the agent does)
- Audio of thoughts (what the human is thinking)
- The audio is transcribed to text and cleaned up. Then everything is carefully aligned:
- They track the on-screen cursor position to line up mouse movements with the exact screen frame (fixing timing delays). This keeps cause (observation) and effect (action) correctly matched.
- Analogy: Like matching dance steps to the beat—actions must line up with what’s on screen so the agent learns the right timing.
Training Trick: Decaying Loss to Focus on Important Changes
- In games, you often repeat simple actions (like holding “W” to walk forward). If the agent learns mostly from these repeats, it misses learning the important moments (switching tools, opening menus, aiming, etc.).
- The authors reduce the training weight of repeated actions over time (a “decaying loss”), so the agent pays more attention to changes and decisions.
- Analogy: Instead of giving a gold star for holding “W” for 10 seconds, you give more credit when the player makes a smart change—like turning at the right moment.
Post-Training: Make the Agent Follow Instructions, Learn In-Context, and Reason Efficiently
- Instruction following:
- The same action (like “jump”) might be bound to different keys in different games. They randomly swap key bindings during training and describe the controls in the prompt. This forces the agent to read instructions and not rely on habits.
- “Inverse dynamics” training teaches the agent to infer what action caused a change it sees—like a detective figuring out which key press led to a door opening.
- Multimodal prompts for in-context learning:
- Text alone often can’t capture complex game mechanics. They add short video examples that show “action → effect” pairs so the agent learns by example.
- For mouse movements (continuous actions), they randomly scale values and use longer histories, so the agent learns to calibrate sensitivity based on feedback.
- Sparse Thinking via Rejection Fine-Tuning:
- The agent generates thoughts, predicts the next action, and only keeps thoughts that lead to the correct action. This filters out vague or unhelpful reasoning.
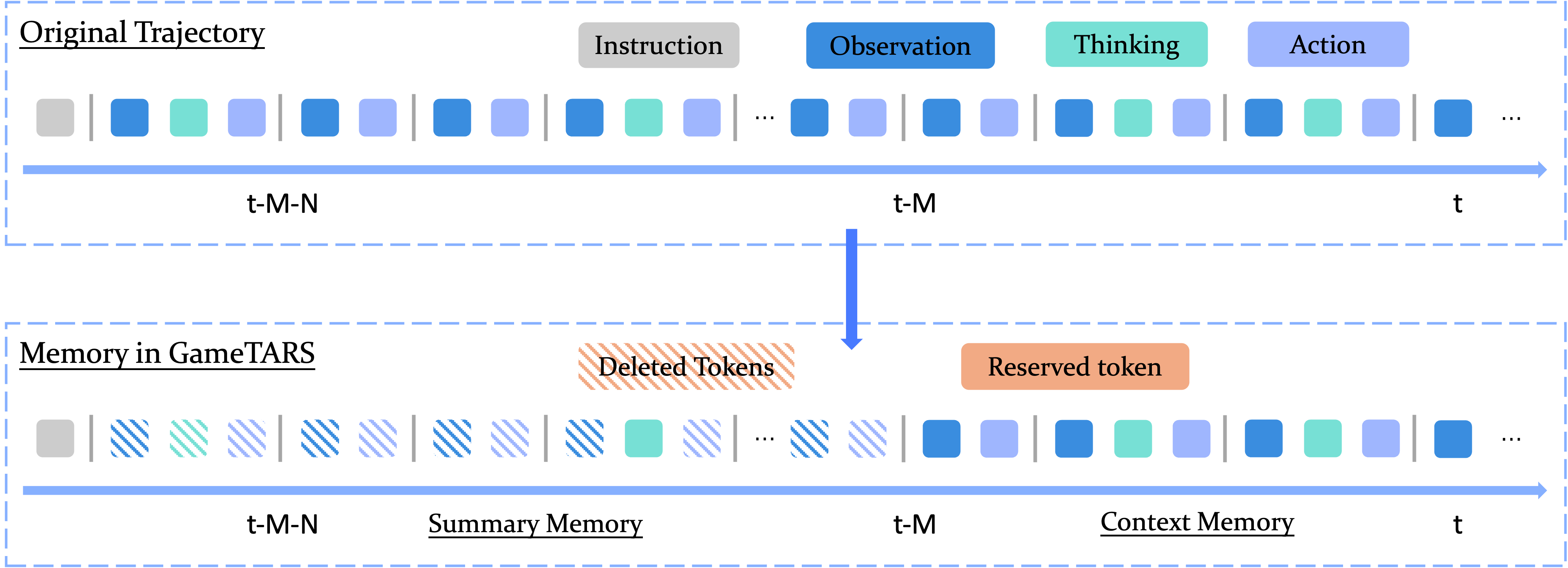
- Two-tier memory:
- Short-term memory: keeps recent images, thoughts, and actions (like a working clipboard).
- Long-term memory: stores compact summaries of past “thoughts” without heavy images—so it can remember over thousands of steps.
- They also train with ultra-long contexts (up to 128k tokens) to handle long tasks.
Main Findings and Why They Matter
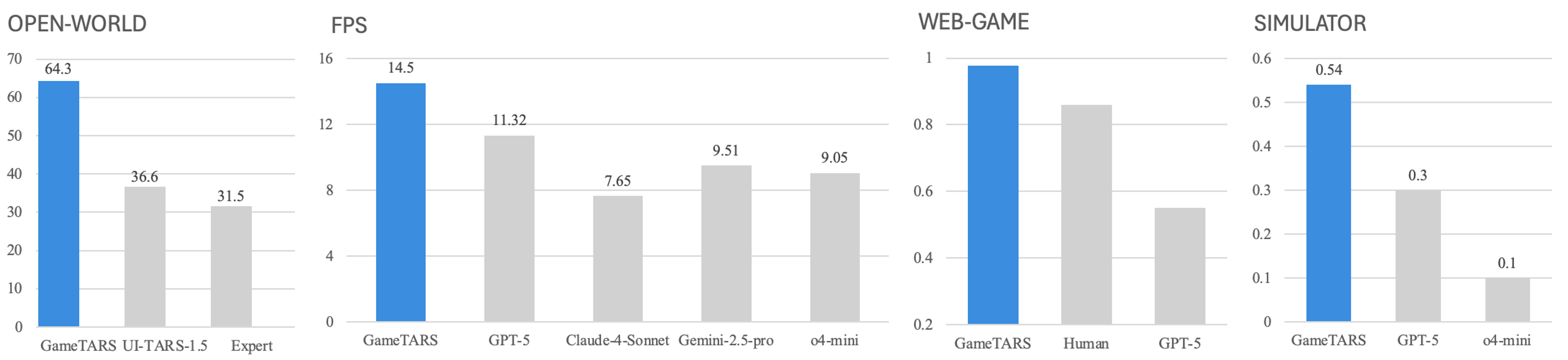
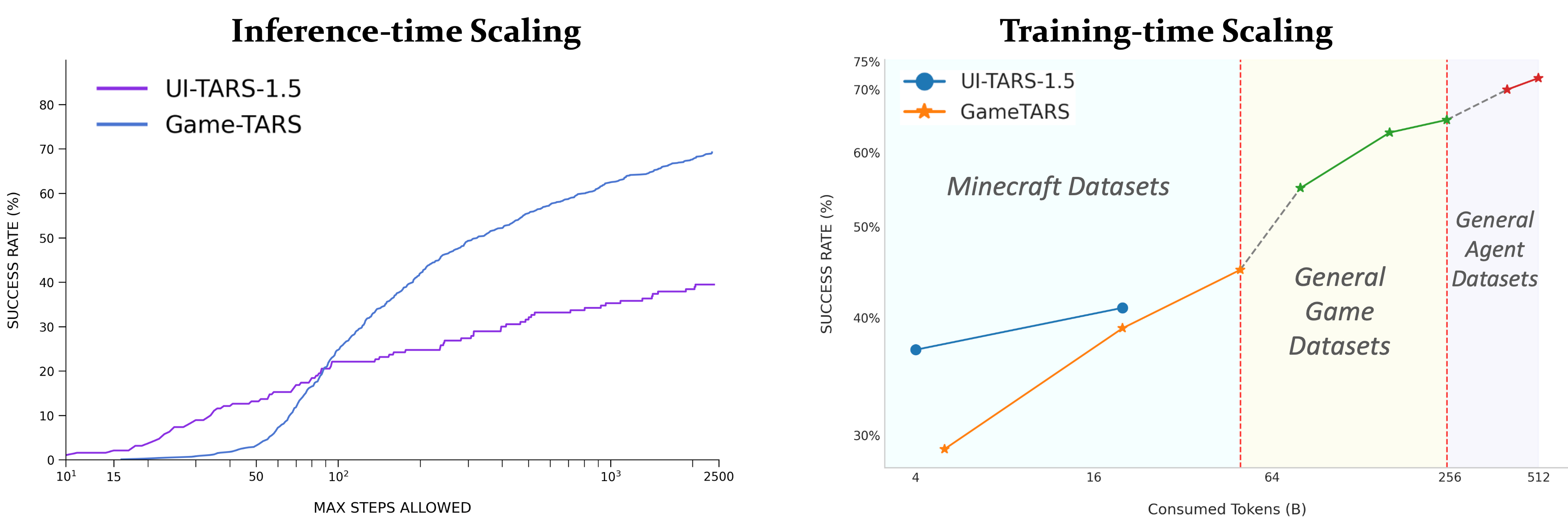
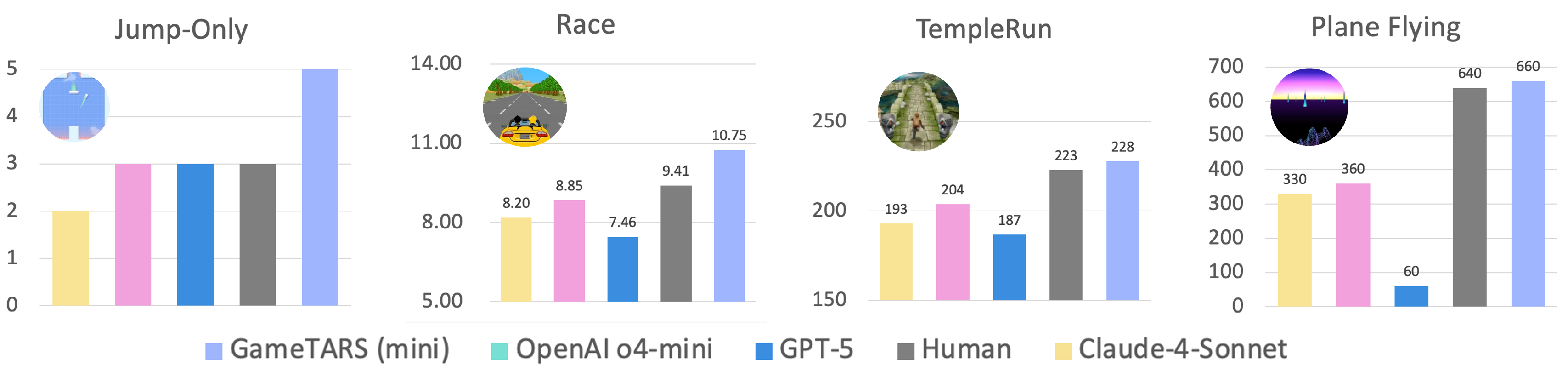
- In open-world Minecraft tasks, Game-TARS achieved about 2× the success rate of the previous best expert model.
- In brand-new 3D web games, its generalization (handling unseen environments) was close to fresh human players.
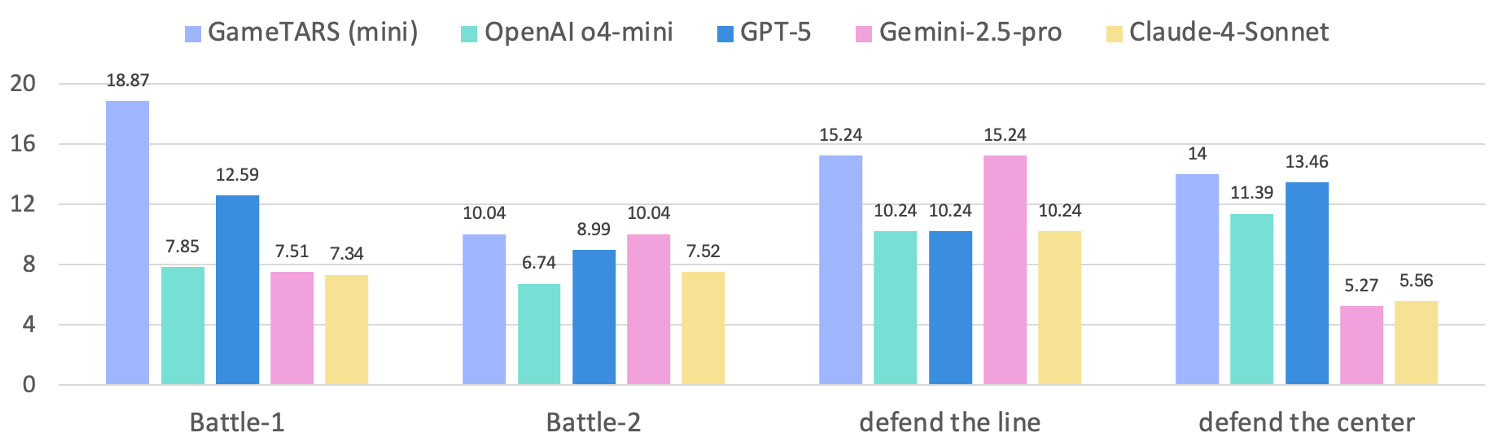
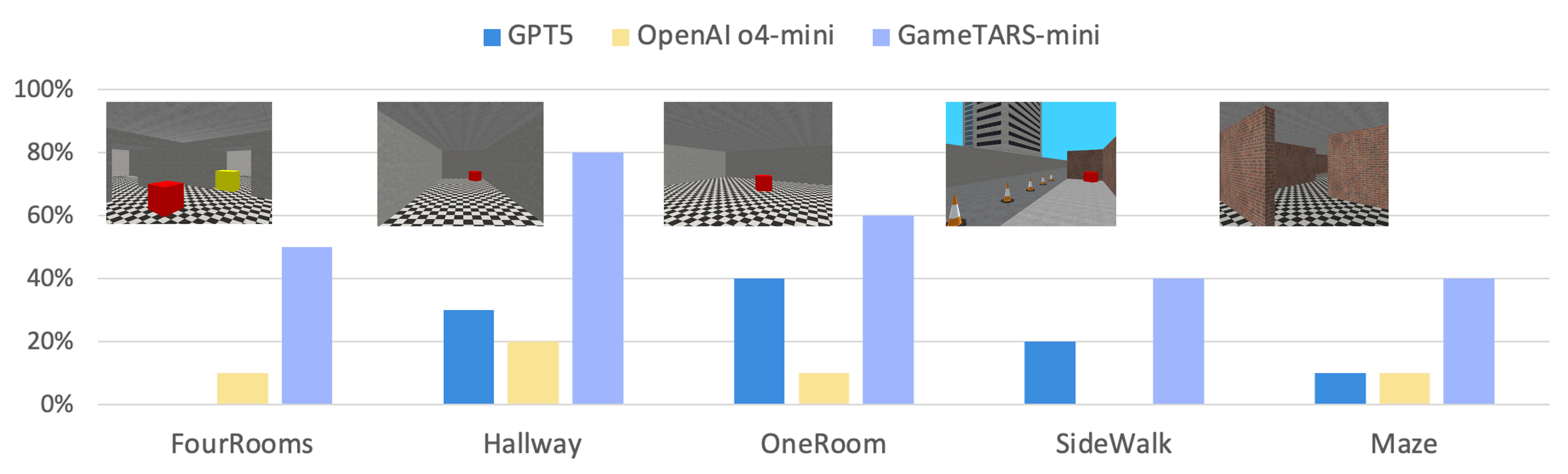
- In FPS benchmarks (like Vizdoom), even the smaller Game-TARS version outperformed well-known general models such as GPT-5, Gemini-2.5-Pro, and Claude-4-Sonnet.
- Scaling tests showed that using the unified keyboard–mouse action space keeps improving results as you add more cross-game and multimodal data.
Why this is important:
- It proves you don’t need custom, game-specific actions to get strong performance. A simple, universal action setup—plus lots of diverse training—can create a powerful, flexible agent.
- The agent can learn to use any GUI or game like a human, making it easier to transfer skills across many digital environments.
Implications and Potential Impact
- A general computer-use agent: Because Game-TARS acts with mouse and keyboard and is trained on more than just games (like coding and research tasks), it can grow into a versatile “digital assistant” that understands screens, follows instructions, and adapts to new software.
- Better training recipes for future agents: Sparse thinking, decaying loss, multimodal prompts, and two-tier memory are practical techniques others can reuse to build smarter, more efficient agents.
- Path toward more general AI: The success of simple actions plus large-scale, mixed data suggests a scalable way to move from specialized bots to general problem-solving agents that can learn, plan, and act across many domains.
In short, Game-TARS shows that using human-like controls, thinking at the right times, and training on massive varied data can create an agent that not only plays games well but also learns to be a capable general computer user.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These are framed to be actionable for future research.
Action space and control modeling
- Clarify action timing semantics: how are keyPress events parameterized for press/hold duration, repeated taps, key-down vs key-up, and double-clicks/drag operations (mouse button down–move–up sequences) in the unified device-level action space.
- Extend beyond keyboard–mouse: how to generalize the primitive action space to touchscreens, gamepads/joysticks, VR controllers, multi-touch gestures, haptics, and pen input while preserving scalability and training efficiency.
- Cursor dependence in alignment: the causal alignment method relies on visible cursor tracking; many FPS and 3D engines hide or lock the cursor—how are keyboard-only actions and cursor-invisible regimes aligned and validated.
- Continuous control calibration: quantitatively characterize convergence speed and stability of the proposed in-context calibration (random (dx,dy) scaling and long-horizon histories) under extreme mouse sensitivities, DPI differences, acceleration/smoothing, and high-FOV/4K displays.
- Action magnitude limits: justify and ablate the cap of |dx|,|dy| ≤ 180 and its effect on tasks that require large, rapid camera turns (e.g., FPS flicks), multi-monitor setups, or ultra-wide resolutions.
Data collection, quality, and causal alignment
- Keyboard alignment without visual anchors: propose and evaluate methods to causally align keyPress events that have delayed or non-visual effects (e.g., toggles, mode switches) where cursor motion is uninformative.
- Multi-action bundling per frame: merging all inputs between frames into a single action may cause aliasing—quantify information loss vs. higher frequency framing, and its impact on learning fine motor sequences.
- ASR and thought-noise robustness: measure how ASR transcription errors and LLM “refinement” noise affect policy quality; provide ablations with different WER levels and editing strategies.
- Think-aloud behavioral bias: assess whether verbalization alters gameplay (e.g., slower actions, more no-ops). Provide controlled comparisons against silent-play trajectories.
- Causal confusion diagnostics: empirically validate that the proposed visual-anchor alignment prevents inverse dynamics leakage across diverse games (not only cursor-heavy ones); add failure analyses when alignment is imperfect.
- Dataset documentation and provenance: specify licenses, privacy protections, and any filtering/redaction applied to think-aloud recordings; disclose potential overlaps with evaluation environments to rule out contamination.
Training objectives and algorithms
- Decaying loss hyperparameters: ablate decay factor γ, sequence-length effects, and per-domain tuning to quantify stability vs. performance trade-offs; compare with alternative imbalance remedies (e.g., focal loss, hard-example mining).
- Inverse-dynamics auxiliary loss: quantify downstream gains across tasks and report failure modes (e.g., shortcut learning, hindsight bias) relative to pure forward-policy training.
- Sparse-thinking selection criterion: the reasoning step locator depends on the model’s own action errors, which can be circular—compare with oracle/human-labeled “hard” steps and alternative uncertainty-based selectors.
- Rejection fine-tuning efficiency: report acceptance rates, compute cost, and policy improvements as a function of candidate samples; compare to reward-model/RLAIF or direct preference optimization that jointly optimizes thought–action chains.
- Unified vs. staged curricula: although a single-stage blend worked best here, provide controlled curricula studies that vary the order/ratio of pure action, offline CoT, think-aloud, and multimodal data.
Memory and long-horizon reasoning
- Thought-only long-term memory: evaluate fidelity and drift when evicting visual tokens and keeping only compressed thoughts—how often do stale or hallucinated summaries misguide actions over 1k–5k steps.
- Retrieval and editing: explore mechanisms for updating, verifying, or retracting incorrect long-term thought summaries; compare with external memory/RAG or learned episodic controllers.
- Ultra-long context limits: provide scaling curves and latency/memory overheads at 64k–128k tokens; quantify how much of the context the model actually attends to and benefits from.
Generalization and evaluation
- Standardized, reproducible benchmarking: release the exact task lists, seeds, initial states, keybindings, and evaluation harnesses for Minecraft (MCU/MineDojo), VizDoom, MiniWorld, and web games to enable fair comparisons.
- Statistical rigor of claims: report sample sizes, confidence intervals, and significance testing for human and model baselines; detail human participant expertise, training time, and instructions.
- Cross-domain transfer disentanglement: isolate the contributions of game data vs. GUI/code/MCP trajectories via controlled ablations to quantify how each source improves which capability.
- Robustness to domain shift: test non-English UIs, alternate skins/themes, unusual aspect ratios, color/lighting changes, and accessibility modes; evaluate brittleness to UI perturbations and adversarial distractors.
- Unseen control schemes: quantify performance under remapped keys and novel action semantics beyond those seen in post-training augmentation; measure zero-shot adaptation speed without re-prompting.
Systems performance and efficiency
- Real-time constraints: report end-to-end latency, frame rate, and token costs under different Sparse-Thinking policies in fast-paced FPS and web tasks; characterize the Pareto frontier of reasoning depth vs. control latency.
- Model size vs. data scaling: provide parameter/data scaling laws across Dense vs. MoE variants, controlling for data mixture, to separate architecture gains from data effects.
- Inference memory footprint: quantify VRAM/CPU/RAM needs for 32k–128k contexts with visual tokens; evaluate truncation strategies and their performance impact.
Safety, ethics, and deployment
- System-level safety: define sandboxing, permissioning, and rollback for OS/web control to prevent harmful or irreversible actions; evaluate on red-team scenarios (e.g., deleting files, changing system settings).
- Content and behavior alignment: assess whether reasoning traces encourage risky or deceptive behaviors; consider private thought redaction and on-device safety filters for action emission.
- Data privacy and compliance: detail consent, anonymization, and retention policies for think-aloud recordings; evaluate re-identification risk and sensitive information leakage in training/inference.
- Security robustness: test resilience to prompt injection through on-screen text, phishing-like UI elements, or malicious web content; incorporate defenses and report efficacy.
Open research directions
- Unified multimodal IO: design a principled, extensible low-level action space that covers keyboard, mouse, touch, controllers, and voice while retaining time alignment and learnability.
- Online adaptation and RL: investigate on-policy fine-tuning (e.g., RL, DPO/RLAIF) in the unified action space to improve credit assignment for long-horizon goals beyond imitation learning.
- Causal representation learning: develop methods that explicitly model action–state causality under partial observability and delayed effects to reduce reliance on heuristic alignment and auxiliary losses.
- Multi-agent and collaborative settings: evaluate coordination, communication, and competition in multi-player games, including learning social conventions and teamwork via the unified action space.
Practical Applications
Immediate Applications
Based on the paper’s unified human-native action space, sparse ReAct training, decaying-loss optimization, multimodal prompting, rejection fine-tuned “Sparse Thinking,” and tiered memory, the following applications can be deployed with current technology and typical enterprise/game tooling.
- Generalist playtesting and QA automation (Sector: Gaming, Software QA)
- What it does: Drives any PC game or simulator via keyboard/mouse to run regression suites, reproduce crashes, validate tutorials, and measure task success rates without per-game API wrappers.
- Why it works: Unified action space + causal realignment (visual-anchored cursor tracking) enables robust, time-aligned action replay; decaying-loss training improves sensitivity to decisive transitions.
- Tools/products/workflows: “AgentPlaytest” runner, scenario recorder/replayer, flaky-test triage using summary memory, GPU-enabled test farm.
- Assumptions/dependencies: Respect game ToS/anti-cheat policies; screen capture and input-injection permissions; test seeds for reproducibility; latency budgets for fast games.
- End-to-end GUI test automation and RPA 2.0 (Sector: Software/Enterprise IT)
- What it does: Automates workflows across legacy desktop apps and web apps without DOM/XPath reliance; resilient to UI changes and custom keymaps.
- Why it works: Automatic Action Space Augmentation prevents overfitting to global key habits; multimodal prompts (short clips) anchor action semantics; inverse-dynamics head sharpens causal understanding.
- Tools/products/workflows: Unified Input Agent SDK, policy-guarded “agent executor” with human-approval steps, visual-anchor alignment library, runbooks as multimodal prompts.
- Assumptions/dependencies: OS-level screen read + input control; secure sandboxing; audit logs of actions/reasons; accessibility mode or VDI for regulated domains.
- Customer support co-pilot with safe remote actions (Sector: SaaS/IT support)
- What it does: Under human-in-the-loop approval, executes multi-step fixes on user desktops; narrates “think-aloud” rationale; provides replays for audits.
- Why it works: Sparse Thinking reduces unnecessary deliberation; tiered memory provides concise summaries for handoffs/escalations.
- Tools/products/workflows: Supervisor console, action rate-limiter and rollback, summary-memory-based incident timelines.
- Assumptions/dependencies: Explicit user consent; PII-safe screen handling; strong RBAC and session isolation; enterprise compliance review.
- Gameplay tutoring, coaching, and assist modes (Sector: Education, Gaming/eSports)
- What it does: Offers on-screen hints, or executes exemplar sequences while explaining reasoning in natural language.
- Why it works: Think-aloud datasets + rejection fine-tuning align thoughts with effective actions; multimodal prompts let coaches share exemplar clips.
- Tools/products/workflows: Overlay “coach” plugin, session recording, skill progression analytics.
- Assumptions/dependencies: Game developer support; ToS compliance; low-latency inference for action-heavy titles.
- Accessibility: voice-to-action desktop control (Sector: Accessibility/Consumer)
- What it does: Maps speech intents to keyboard/mouse actions; adapts to app-specific bindings and sensitivities.
- Why it works: The paper’s think-aloud pipeline and continuous-action calibration handle variable sensitivities and user-specific bindings.
- Tools/products/workflows: On-device ASR, per-app calibration with brief demos, user profiles stored in long-term summary memory.
- Assumptions/dependencies: High-quality on-device ASR to preserve privacy; safe-guardrails to avoid destructive actions.
- Procedural tutorial and how-to content generation (Sector: Education/Content)
- What it does: Automatically performs tasks on software/games and renders stepwise videos and text guides.
- Why it works: Tiered memory yields concise long-range summaries; ReAct traces explain rationale.
- Tools/products/workflows: “TutorialGenerator” pipeline that records actions + auto-narrates with sparse thoughts; localization pass.
- Assumptions/dependencies: Copyright/licensing for UI assets; human QA for accuracy.
- Constrained-browser research agent (Sector: Research, Media, Knowledge work)
- What it does: Performs browsing, form-filling, and summarization in a sandboxed browser; outputs sources and rationale.
- Why it works: Cross-domain agentic post-training (GUI/MCP/code) and unified input control generalize to web tasks.
- Tools/products/workflows: Kiosk browser sandbox, rate-limited fetch, citation enforcement.
- Assumptions/dependencies: Compliance with site robots/terms; provenance tracking; content licensing.
- Agent benchmarking and reproducible evaluation (Sector: Academia/Benchmarks)
- What it does: Provides standardized eval suites spanning Minecraft, VizDoom, MiniWorld, and web games to study generalization and action reasoning.
- Why it works: The paper’s unseen-environment evaluation protocol and action-observation causal alignment reduce confounds.
- Tools/products/workflows: Open benchmark harness, alignment utilities (visual anchor), sparse ReAct conversion tools.
- Assumptions/dependencies: Dataset licenses; documented seeds/configs; compute availability.
- Anti-cheat and bot-behavior detection R&D (Sector: Gaming/Policy)
- What it does: Generates realistic bot traces to train detectors that distinguish human vs agent inputs.
- Why it works: Human-native action primitives produce lifelike timing distributions for training adversarial detectors.
- Tools/products/workflows: Synthetic-bot corpus generator; feature extraction on micro-motor signatures (e.g., jitter, burstiness).
- Assumptions/dependencies: Coordination with publishers; ethical use policies.
- Data-collection and alignment toolkit (Sector: Data/Tooling, Academia)
- What it does: Deploys the paper’s think-aloud pipeline (ASR→LLM refine), cursor-anchored alignment, and sparse ReAct synthesis to build high-quality trajectories.
- Why it works: Fixes timestamp drift and causal confusion; enforces sparsity where reasoning is actually needed.
- Tools/products/workflows: “Sparse ReAct DataKit,” alignment metrics, quality filters via rejection fine-tuning.
- Assumptions/dependencies: IRB/consent for audio; storage of synchronized video+inputs; multilingual ASR support.
Long-Term Applications
These opportunities need further research, engineering, scaling, policy agreements, or ecosystem support before broad deployment.
- Universal general computer-use agent for enterprise workflows (Sector: Enterprise IT, Finance, Healthcare admin)
- Vision: An autonomous agent that navigates heterogeneous desktop/web stacks, executes multi-app workflows, and self-calibrates to environment changes.
- Enablers from the paper: Unified input space, multimodal ICL, long-horizon memory, action-space augmentation to avoid keybinding brittleness.
- Dependencies: Robustness and recovery in non-deterministic UIs; governance (approvals, guardrails, auditability); regulatory adherence (SOX, HIPAA).
- Cross-OS, cross-device assistant (desktop + mobile) (Sector: Consumer/OS)
- Vision: Extend unified action space to touch/gestures/haptics for iOS/Android and mixed-reality.
- Enablers: The taxonomy already sketches mobile actions; same Sparse ReAct and calibration concepts apply.
- Dependencies: OS vendor APIs; background execution permissions; secure input injection; privacy-by-design.
- Agent-driven NPCs and dynamic game content (Sector: Gaming)
- Vision: Non-scripted NPCs that plan, remember, and act with human-like variability; emergent quests and coaching that adapts to player styles.
- Enablers: Sparse Thinking for cost-effective deliberation; tiered memory for persistent world context.
- Dependencies: Deterministic simulations or server-authoritative checks; fairness and toxicity controls; server compute budgets.
- Simulation-based training and assessment in safety-critical fields (Sector: Healthcare, Aviation, Defense)
- Vision: Adaptive simulators with an agent that mentors, evaluates, and perturbs scenarios to target specific competencies.
- Enablers: Multimodal prompting for skill exemplars; inverse dynamics for causal feedback; summary memory for longitudinal assessment.
- Dependencies: Domain-validated curricula; explainability; formal verification and regulatory approval.
- Teleoperation learning and sim-to-real transfer for robots (Sector: Robotics/Automation)
- Vision: Use the paper’s training tricks (decaying loss on repeats, sparse ReAct, memory) to learn from human teleop traces and scale to real-world autonomy.
- Enablers: Causal alignment methods; dynamic calibration of continuous controls; rejection fine-tuned reasoning-action chains.
- Dependencies: Mapping from human inputs to robot control spaces; safety cases; latency and bandwidth constraints; robust perception.
- Formalized safety, audit, and certification frameworks for generalist agents (Sector: Policy/Standards)
- Vision: Standardized evals for instruction adherence, action-space compliance, rate limits, and failure containment; disclosure norms for human-native automation.
- Enablers: The paper’s instruction-following protocols and action-space augmentation create measurable compliance targets.
- Dependencies: Multi-stakeholder governance, legal guidance on device-level automation, provenance logging standards.
- Personal universal desktop agent with privacy-preserving long-term memory (Sector: Consumer productivity)
- Vision: A persistent assistant that learns preferences, manages files/apps, and executes complex tasks with interpretable rationales.
- Enablers: Two-tier memory to compress long histories; sparse thoughts for efficient, reviewable summaries.
- Dependencies: On-device or encrypted vector memory; user control and red-teaming; energy-efficient inference.
- Adaptive e-learning labs and assessments across disciplines (Sector: Education)
- Vision: Agents that demonstrate, grade, and adapt tasks in virtual labs (STEM, creative tools), using multimodal exemplars and causal feedback.
- Enablers: Multimodal prompts and inverse dynamics; long-horizon ICL.
- Dependencies: Curriculum alignment, content IP, fairness and accessibility audits.
- No-code “teach by demonstration with think-aloud” agent programming (Sector: Developer tools/Low-code)
- Vision: Users record a few demonstrations with narration; the agent generalizes workflows and exposes parameterized automations.
- Enablers: Think-aloud collection + rejection fine-tuning to bind reasoning to effective actions; action-space augmentation to avoid overfitting.
- Dependencies: UX for recording/calibration; drift detection; safe sandboxing; versioning and rollback.
- Cost-aware, dynamically “Sparse Thinking” serving for agent platforms (Sector: AI Infrastructure)
- Vision: Production serving stacks that adaptively gate reasoning tokens at decision points to balance accuracy and cost/latency.
- Enablers: The paper’s Sparse Thinking and timestamp targeting (S_r) for where to think more deeply.
- Dependencies: Runtime controllers, token budgets, SLAs; reliable detectors for high-entropy steps; model introspection APIs.
Notes on common assumptions and risks across applications:
- Access and permissions: Many use cases require OS-level screen capture and input injection, which must be consented, secured, and auditable.
- Compliance and ToS: Game automation and web interaction must align with platform policies; enterprise use needs regulatory controls.
- Privacy: Think-aloud and screen data can contain sensitive content; on-device processing and data minimization are advisable.
- Robustness: Heterogeneous hardware, displays, latency, and app-specific key bindings require calibration loops and fallback strategies.
- Cost and performance: FPS-like settings need low-latency inference; Sparse Thinking and memory compression mitigate but do not eliminate compute costs.
- Safety: Guardrails against irreversible actions (deletions, purchases), human-in-the-loop approvals, and rate limiting are essential for trust and adoption.
Glossary
- AGI: A goal of building agents with general-purpose competence across diverse tasks and environments. "AGI"
- ASR (Automatic Speech Recognition): Technology that transcribes spoken audio into text. "we use an ASR model~\citep{radford2023robust} to transcribe the audio into text"
- ASR-LLM pipeline: A processing pipeline that combines speech recognition with a LLM to clean and structure recorded thoughts. "refines sparse-thinking through the ASR-LLM pipeline"
- Autoregressive: A modeling approach that predicts the next output (e.g., action) conditioned on the entire prior sequence. "a autoregressive, parameterized policy, "
- Causal alignment: Ensuring the temporal and causal consistency between observations and actions across modalities. "Causal Alignment via Visual Anchors"
- Causal confusion: A failure mode in imitation learning where models learn spurious correlations and misattribute causality. "leads to the causal confusion in imitation learning~\citep{de2019causal}"
- Chain-of-thought: Explicit, step-by-step reasoning sequences used to guide model decisions. "offline chain-of-thought synthesis~\citep{wei2022chainofthought}"
- Continual pre-training: Ongoing large-scale pre-training that incorporates diverse and evolving data streams over time. "continual pre-training phase"
- Decaying loss function: A loss reweighting scheme that reduces the contribution of repeated actions, focusing learning on meaningful transitions. "Continual Pre-training with Decaying Loss Function"
- History-aware loss re-weighting: Adjusting per-step loss weights based on action repetition to mitigate dominance of low-entropy samples. "we introduce a history-aware loss re-weighting scheme"
- Human-Native Interaction paradigm: Grounding the action space directly in keyboard and mouse inputs to maximize universality across environments. "We term this the Human-Native Interaction paradigm."
- In-Context Learning (ICL): The ability of a model to adapt its behavior by leveraging examples and interaction history provided in its context. "We define this ability as the agent's In-Context Learning (ICL)~\citep{jiang2022vima,dong2022survey}"
- Inverse Dynamics Model (IDM): A model that infers actions from observed state changes rather than deciding from current state alone. "degenerate into an Inverse Dynamics Model (IDM)~\citep{vpt}"
- Inverse-Dynamics Prediction: Predicting the action that caused a transition given current and next observations. "we introduce Inverse-Dynamics Prediction as an auxiliary training task."
- LLM: A high-capacity neural model trained on text to perform tasks like reasoning, rewriting, and instruction following. "which is then refined using a LLM to remove noise and enhance logical consistency."
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert subnetworks to improve efficiency and capacity. "a Mixture-of-Experts (MoE) LLM with 2.5B active parameters."
- Multimodal prompting mechanism: Providing visual (e.g., video) examples alongside text prompts to demonstrate action-effect pairs. "we introduce a multimodal prompting mechanism."
- No-op: An explicit action indicating no operation is performed during a timestep. "Think, LongThinking, and No-Op"
- Non-Markovian: Trajectories where the optimal decision depends on long-range history, not just the current state. "non-Markovian agent trajectories"
- ReAct paradigm: A framework that interleaves reasoning (thought) and action steps for better decision-making. "Following the ReAct paradigm~\citep{yao2022react}"
- Rejection Fine-Tuning (RFT): Fine-tuning with rejection sampling to keep only reasoning that yields correct actions. "We adopted a Rejection Fine-Tuning (RFT) approach"
- Rejection Sampling: Generating candidate thoughts and accepting only those whose resulting actions match ground truth. "through Rejection Sampling."
- Sparse Thinking: Producing reasoning only at crucial decision points to balance performance and cost. "Sparse Thinking via Reinforcement Fine-Tuning"
- Think-aloud protocol: Collecting reasoning by having annotators verbalize thoughts during task execution. "we adopt a think-aloud protocol"
- Timestamp aligner: A tool to synchronize action and observation streams by correcting timing discrepancies. "uses a timestamp aligner to synthesize the final (Instruction, Observation, Thinking, Action) datasets."
- Ultra-Long Context Training: Training on sequences with very large context windows to learn long-range dependencies. "Ultra-Long Context Training"
- Visual anchors: Stable visual features (e.g., cursor) used to realign actions with the correct observation frames. "a realignment method based on visual anchors"
- Visual grounding model: A model that locates and tracks specific objects or features within image frames. "employ a visual grounding model~\citep{wang2025ui} to precisely track its pixel position in each frame."
- Vision-LLM (VLM): A model jointly trained to understand and reason over visual and textual inputs. "general VLMs"
- Visual Question Answering (VQA): A task requiring models to answer questions about visual content. "visual question answering (VQA)"
Collections
Sign up for free to add this paper to one or more collections.

