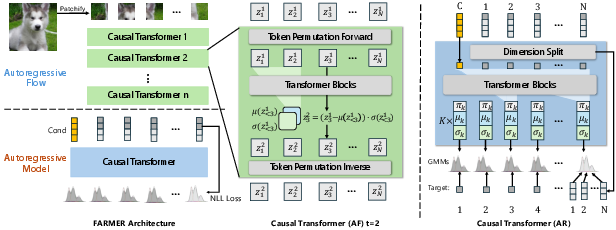
FARMER: Flow AutoRegressive Transformer over Pixels
Abstract: Directly modeling the explicit likelihood of the raw data distribution is key topic in the machine learning area, which achieves the scaling successes in LLMs by autoregressive modeling. However, continuous AR modeling over visual pixel data suffer from extremely long sequences and high-dimensional spaces. In this paper, we present FARMER, a novel end-to-end generative framework that unifies Normalizing Flows (NF) and Autoregressive (AR) models for tractable likelihood estimation and high-quality image synthesis directly from raw pixels. FARMER employs an invertible autoregressive flow to transform images into latent sequences, whose distribution is modeled implicitly by an autoregressive model. To address the redundancy and complexity in pixel-level modeling, we propose a self-supervised dimension reduction scheme that partitions NF latent channels into informative and redundant groups, enabling more effective and efficient AR modeling. Furthermore, we design a one-step distillation scheme to significantly accelerate inference speed and introduce a resampling-based classifier-free guidance algorithm to boost image generation quality. Extensive experiments demonstrate that FARMER achieves competitive performance compared to existing pixel-based generative models while providing exact likelihoods and scalable training.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “FARMER: Flow AutoRegressive Transformer over Pixels” in simple terms
Overview: What is this paper about?
This paper introduces a new way to teach computers to create realistic images from scratch. The method is called FARMER. It combines two powerful ideas:
- A reversible way to transform images into a simpler “code” (called a Normalizing Flow).
- A step-by-step way to predict data like a sentence, one piece at a time (called an Autoregressive model).
The goal is to directly model images at the pixel level (the tiny dots that make up a picture), while keeping training stable, quality high, and math exact.
What questions is the paper trying to answer?
In simple terms, the paper asks:
- How can we model images directly from pixels without compressing them first, but still keep the model efficient and high-quality?
- Can we mix “reversible” transformations (so we know exact probabilities) with “step-by-step” prediction (so we can model complex patterns)?
- How do we reduce the unnecessary parts of image data so the model focuses on what matters most?
- Can we make sampling (the process of generating a new image) faster without losing quality?
How does FARMER work? (Methods explained with analogies)
Think of image generation like creating a drawing:
- You first sketch the outline (structure).
- Then you fill in colors and textures (details).
- You follow a plan one step at a time.
- You also prefer the best choices as you go.
FARMER follows a similar plan:
- Normalizing Flow (NF): This is like a reversible recipe. You can turn an image into a “secret code” and back, perfectly. Because it’s reversible, you can measure exactly how likely the model thinks an image is (this is important for math and evaluation).
- Autoregressive (AR) Transformer: This is like writing a story one word at a time. The model predicts the next piece based on what it has already generated.
- Putting them together: The NF turns an image into a sequence of codes. The AR model then learns the pattern of these codes, step by step. This makes the pattern easier to learn than working on raw pixels directly.
- Cutting images into patches: The image is split into small tiles (patches) and arranged like a long line of tokens (like words). This lets the AR model “read” and “write” them in order.
- Self-supervised dimension reduction: Not all information in an image is equally important. FARMER automatically splits each token into:
- informative channels (the outline/structure),
- redundant channels (fine details like color and texture).
- The model learns the structure tokens one-by-one, and then learns the detail tokens all at once using the structure as context. This makes learning easier and more efficient.
- Resampling-based Classifier-Free Guidance (CFG): Guidance is like having a coach. During generation, the model proposes multiple candidates and then re-weights them to prefer those that better match a target (like a class label), without needing an extra classifier. FARMER’s “resampling” version samples smartly from both “with label” and “without label” predictions and then picks the best candidates.
- One-step distillation for speed: Normally, reversing the NF is slow because it rebuilds tokens one-by-one. Distillation teaches a “student” model to do in one step what the “teacher” does in many steps—like learning a shortcut. This makes generating images much faster with similar quality.
What did they find, and why does it matter?
Here are the main results in everyday terms:
- Better quality than similar methods that also combine flows and autoregression: FARMER beats JetFormer (a strong baseline) on image quality metrics.
- Competitive with top pixel-based generators: It performs well compared to modern diffusion and autoregressive image models.
- Exact probabilities: Unlike many popular models, FARMER can calculate the exact likelihood of images. That’s useful for science, evaluation, and future research.
- Much faster sampling after distillation: The slow part (reversing the flow) becomes about 22 times faster, and overall image generation is around 4 times faster, while keeping quality similar.
- Smarter use of image information: Splitting channels into structure vs. details (and modeling them differently) improves both quality and efficiency without throwing information away.
- Better guided sampling: The new resampling-based guidance makes generated images sharper and more faithful to the target class.
Why it matters: Combining reversibility (for exact math and stable training) with step-by-step prediction (for expressive modeling) is a big deal. It offers a new path to high-quality, controllable, and efficient pixel-level image generation.
What’s the impact? Why should we care?
- For researchers: FARMER shows how to unify two families of models (flows and autoregressive transformers) into a single, scalable system with exact likelihoods. That opens doors for more principled training and evaluation.
- For applications: Faster, higher-quality pixel-level generation can help in art creation, data augmentation, simulation, and tools that need precise control over images.
- For the future: The idea of separating “structure” from “details” in a self-supervised way could be used in other areas, like video, audio, or multimodal models. The distillation and resampling techniques are general and could speed up other generative systems too.
In short: FARMER is like a careful artist with a perfect undo button—first laying down the structure, then filling in details, choosing the best next strokes, and learning a shortcut to finish the painting much faster, all while keeping the math exact.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it.
- Exact likelihood evaluation is not reported: no bits-per-dimension (BPD), negative log-likelihood (NLL), or calibration metrics are provided, despite the method’s claimed “exact likelihoods.” Quantify and compare likelihoods against NF baselines (e.g., Glow, RealNVP) and latent AR models.
- Impact of one-step distillation on likelihood tractability is unclear: distilling the AF reverse into a single-step student forward path likely breaks exact invertibility and may invalidate Jacobian-based likelihood computation. Determine whether the distilled model preserves a tractable change-of-variables formulation and measure the post-distillation NLL gap.
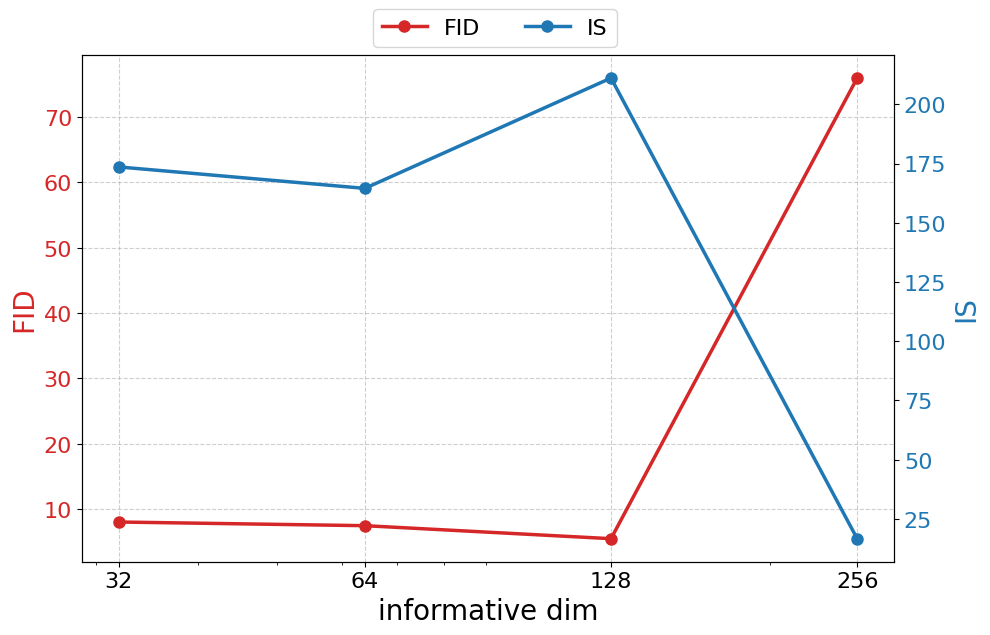
- “Self-supervised dimension reduction” lacks a principled channel partition mechanism: the split into informative vs redundant channels and their dimensions (e.g., dI=128, dR=640) are hand-chosen. Develop and evaluate criteria or learning objectives (e.g., mutual information, sparsity/orthogonality constraints) that automatically discover and adapt the partition.
- The assumption of a single shared GMM for all redundant tokens may be too restrictive: modeling all zR tokens with one global distribution could underfit fine-grained channel correlations. Test alternative parameterizations (e.g., per-token low-rank covariances, mixture of shared experts, hierarchical modeling) for zR.
- Diagonal covariance in GMM heads limits intra-token dependencies: tokens are high-dimensional (up to 768), yet covariances are diagonal. Assess full, block-diagonal, or low-rank covariances and measure gains vs computational cost.
- Limited analysis of guidance method: the resampling-based CFG lacks theoretical guarantees (bias/consistency, variance, convergence) and stability analyses (e.g., behavior when p_u(z) is small, large guidance scales w). Provide formal analysis and empirical sweeps of w, candidate counts s/s′, and robustness across classes and resolutions.
- CFG computational overhead and latency are not quantified: resampling from s+s′ candidates per token (and N replicas for redundant tokens) can be expensive. Measure guidance overhead, optimize candidate counts, and explore adaptive candidate allocation.
- Patch size and resolution scaling are underexplored: experiments are limited to ImageNet-256 with patch sizes 8/16. Investigate performance, speed, and memory scaling to 512/1024 resolutions and smaller/larger patches (including the trade-off between sequence length N and per-token dimensionality).
- Generalization beyond class labels is not demonstrated: despite claims about better multi-modal compatibility, no text-to-image or multi-condition experiments (e.g., CLIP embeddings, captions) are provided. Evaluate FARMER on multimodal conditioning and compare against diffusion/AR baselines.
- Underdeveloped analysis of long-range dependencies: the method reduces per-token dimensionality but keeps sequence length roughly unchanged (N→N+1). Quantify whether FARMER effectively mitigates long-range dependency brittleness relative to pixel AR baselines (e.g., attention distance, perplexity of AR heads).
- Impact of dequantization noise schedule is not studied: Gaussian noise annealed from 0.1 to 0.005 is used, but its effect on likelihood and sample quality is not ablated. Evaluate different noise schedules, magnitudes, and their interaction with AF/AR training stability.
- Permutation strategy is fixed and unexamined: reversing token order per AF block is adopted without comparing learned, random, or structured permutations. Test alternative or learnable permutations and their effects on expressivity, likelihood, and speed.
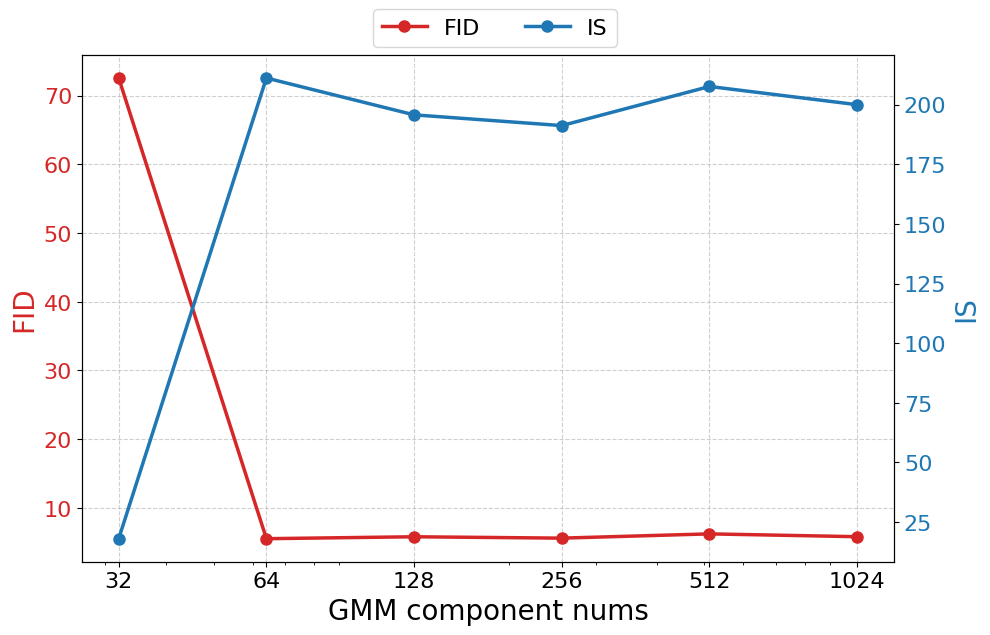
- Choice of GMM mixture components is not principled: K is set differently for zI and zR (e.g., 64 vs 200), with limited ablation. Establish criteria for selecting K (e.g., via MDL, held-out NLL) and study the compute–quality trade-off.
- Training compute, throughput, and memory footprint are unreported: models up to 1.9B parameters are trained for 320 epochs, but FLOPs, GPU hours, batch sizes, and tokens/sec are missing. Provide detailed efficiency benchmarks and scaling laws.
- Speed claims exclude CFG and AR sampling costs in detail: AF reverse is accelerated 22×, but overall end-to-end sampling latency (including AR, GMM sampling, CFG resampling) under different settings is not fully characterized. Report comprehensive latency breakdowns.
- Empirical equivalence of AF+AR to deeper AF at K=1 is not validated: the paper claims formal equivalence (appendix) but lacks empirical tests showing matched likelihoods and samples for K=1 across architectures.
- Information preservation claim is not substantiated: “without information loss” is asserted for the dimension reduction scheme, yet no reconstruction experiments or information-theoretic measures (e.g., mutual information between zI/zR and x) verify this. Design diagnostics to quantify information allocation and leakage.
- Robustness and failure modes are not analyzed: no per-class or OOD performance, diversity/precision trade-offs, sensitivity to hyperparameters, or qualitative failure cases are reported. Provide error analyses and robustness metrics.
- Comparative evaluation omits likelihood-centric NF baselines and pixel AR models on the same settings: some baselines differ in resolution, tokenization, or conditioning. Run matched comparisons (same resolution/conditioning/evaluation protocol) to isolate architectural effects.
- The interaction between the AF Jacobian term and AR log-likelihood is underexplored: training involves balancing log-det and AR likelihood, but no analysis of their relative magnitudes, gradients, or potential instability is provided. Study loss weighting, curriculum strategies, and gradient diagnostics.
- Token-level modeling granularity is fixed: all informative tokens are modeled individually, while redundant channels are modeled jointly. Explore intermediate granularities (e.g., grouping tokens by spatial locality or semantics) to trade off complexity and fidelity.
- No human evaluation or perceptual studies: FID/IS/precision–recall are reported, but human judgments and perceptual metrics (e.g., LPIPS) are missing, especially given claims about fine-grained detail preservation.
- Reproducibility artifacts are absent: code, training recipes, and exact preprocessing/augmentation details (beyond noise schedule and patchify) are not provided. Release artifacts and report seed sensitivity and variance across runs.
Practical Applications
Immediate Applications
Below are actionable applications that could be deployed or prototyped now using the paper’s methods and findings, with sector links, potential tools/workflows, and feasibility notes.
- High-fidelity class-conditional image generation for creative production — sectors: media, advertising, gaming, e-commerce
- What: Use FARMER’s pixel-space generator to produce photorealistic assets with fine detail preservation (e.g., textures, product shots, background variations).
- Tools/products/workflows: A “FARMER Sampler” plugin for design suites (e.g., Photoshop, Blender), with resampling-based classifier-free guidance (CFG) for controllability; presets for class labels; a “structure vs. detail” knob built on informative/redundant channel splitting.
- Assumptions/dependencies: Requires large-scale training (B-scale Transformers) and domain-specific datasets for target styles; GPUs for inference; licensing of model weights.
- Structure/detail-separated image editing — sectors: creative software, photography, AR/VR
- What: Selective editing of content: apply edits to coarse structure (informative channels) vs fine details/color (redundant channels) without retraining.
- Tools/products/workflows: A “channel group editor” UI with sliders; batch workflows to recolor or re-detail assets while keeping layout and shapes intact.
- Assumptions/dependencies: Channel partition quality depends on training; mapping latent channel groups to intuitive controls needs empirical tuning.
- Likelihood-based visual anomaly scoring for QA — sectors: manufacturing, logistics, retail operations
- What: Use exact per-image likelihoods as a principled anomaly score to flag defects or atypical frames in visual inspection pipelines.
- Tools/products/workflows: A “FARMER Score” service (REST API) that ingests frames and returns log-likelihood, enabling thresholding and alerts; one-step-distilled AF for near-real-time scoring.
- Assumptions/dependencies: Must train on in-distribution imagery for the specific production line; thresholds require calibration; device-specific lighting/pose variability must be represented in training data.
- Dataset curation and out-of-distribution (OOD) screening for vision ML — sectors: academia, ML platform providers, MLOps
- What: Rank or filter images by tractable likelihood to remove corrupted, duplicated, or unusual samples; prioritize representative data.
- Tools/products/workflows: A curation pipeline that computes per-sample NLL, tags outliers, and integrates with data versioning tools (e.g., DVC); reports with likelihood histograms across classes.
- Assumptions/dependencies: Model must be trained on the dataset or a close proxy; likelihoods reflect the model’s learned distribution, not an absolute notion of “quality.”
- Sampling quality and speed upgrades for existing AR/NF image models — sectors: software/AI infrastructure, research labs
- What: Drop-in adoption of resampling-based CFG to improve sample quality and one-step distillation to accelerate flow-based reverse passes.
- Tools/products/workflows: Open-source sampling modules with cfg_resample() and AF_distill_one_step(); CI benchmarks tracking FID/IS and latency.
- Assumptions/dependencies: Requires access to unconditional/conditional heads; distillation needs a frozen teacher and additional epochs; speed gains depend on hardware and sequence length.
- Synthetic data generation for perception training with likelihood filtering — sectors: robotics, autonomous driving, industrial vision
- What: Generate class-specific synthetic images and use likelihood gating to remove implausible samples before training detectors/classifiers.
- Tools/products/workflows: A synthetic data factory: farm samples per class, compute likelihood percentile, retain top X%; integrate with labeling tools and data augmentation pipelines.
- Assumptions/dependencies: Domain shift remains a challenge; farmed samples should be validated with downstream task metrics; CFG scales and class embeddings must be tuned per domain.
- Benchmarking and pedagogy in generative modeling — sectors: academia, education
- What: Use exact likelihood reporting alongside FID/IS to teach and evaluate pixel-space models; demonstrate NF+AR training curves and Jacobian log-det contributions.
- Tools/products/workflows: Classroom notebooks showing end-to-end training on a small dataset, visualization of informative vs redundant channels, and sampling with/without CFG resampling.
- Assumptions/dependencies: Requires simplified/downsized configurations for classroom hardware; careful choice of patch sizes and mixture components to keep runtimes manageable.
- Fine-grained reconstruction pipelines — sectors: cultural heritage digitization, archival imaging
- What: Exploit invertible flows to reconstruct and enhance images while preserving minute details (e.g., textures, inscriptions).
- Tools/products/workflows: Restoration workflows that encode artifacts into latents, adjust redundant channels for subtle color/contrast corrections, and decode back losslessly.
- Assumptions/dependencies: Trained on relevant photographic styles; ethical guidelines for restoration fidelity; high-resolution inputs may need patch-size and memory tuning.
Long-Term Applications
The following applications likely require further research, scaling, domain adaptation, or standardization before broad deployment.
- Learned generative codecs (lossless/lossy) with entropy coding — sectors: software, telecom, cloud storage
- What: Use exact likelihoods for bits-back or arithmetic coding, enabling learned compression with invertible decompression; optionally exploit channel partitioning for layered coding (structure vs detail).
- Tools/products/workflows: A “FARMER Codec” with encoder (AF forward) and decoder (AF reverse), entropy coder over AR-modeled latents, and optional quality knobs via CFG.
- Assumptions/dependencies: Needs format standardization, real-time speeds on edge devices, rigorous rate–distortion evaluation; present models preserve dimensionality and will need additional design for strong compression ratios.
- Medical imaging anomaly detection and triage — sectors: healthcare
- What: Train FARMER on modality-specific scans (e.g., X-ray, CT) to provide calibrated anomaly likelihoods and preserve fine details for clinical review.
- Tools/products/workflows: Clinical decision support that surfaces low-likelihood scans to radiologists; explainability via channel-group saliency (structure vs detail).
- Assumptions/dependencies: Regulatory compliance (e.g., FDA/CE); extensive domain validation; robust handling of site-specific variations; strict data governance and bias assessment.
- On-device real-time enhancement (“generative cameras”) — sectors: mobile, consumer electronics
- What: Apply one-step-distilled AF and lightweight AR heads to denoise or enhance frames on smartphones/AR devices with detail preservation.
- Tools/products/workflows: Mobile SDKs with fast AF reverse path and CFG controls optimized for battery and latency; interactive sliders for “sharpness” (redundant channels) vs “composition” (informative channels).
- Assumptions/dependencies: Further model compression/distillation; energy constraints; user privacy; adaptation to sensor-specific noise characteristics.
- Multimodal extensions: video, audio, and cross-modal conditioning — sectors: entertainment, social media, education
- What: Extend NF+AR to temporal sequences (video) and continuous audio signals, leveraging causal flows and AR distributions for tractable likelihoods and controllable generation.
- Tools/products/workflows: Video generators with likelihood-based quality gating, audio-visual dubbing with synchronized flow transformers, and CFG resampling for conditional guidance (e.g., text prompts).
- Assumptions/dependencies: Sequence lengths and compute scale explode for video/audio; memory-efficient architectures and training curricula are needed; new evaluation metrics and stabilization strategies.
- Robust OOD detection and content provenance — sectors: policy, platform trust & safety
- What: Use explicit likelihood and channel-group analyses to flag atypical content, assist provenance pipelines, and augment deepfake detection workflows.
- Tools/products/workflows: A “Provenance Assistant” that scores images against a reference distribution, signals structural vs detail mismatches, and integrates with watermarking tools.
- Assumptions/dependencies: Likelihood scores can be gamed if attackers target model biases; must be combined with cryptographic provenance (C2PA) and human review; cross-domain retraining needed.
- Industrial robotics and manufacturing: closed-loop anomaly detection — sectors: robotics, Industry 4.0
- What: Deploy NF+AR systems on visual inspection lines for continuous monitoring, with likelihood-based thresholds adapting in real time to distribution drift.
- Tools/products/workflows: Edge inference appliances with AF distillation; dashboards showing likelihood bands per station; automatic retraining triggers when drift is detected.
- Assumptions/dependencies: Latency and throughput requirements; robust domain adaptation; integration with PLCs and MES; safety certification.
- Scientific imaging and remote sensing analytics — sectors: earth observation, materials science, astronomy
- What: Model complex continuous pixel distributions (e.g., satellite imagery, microscopy) to improve denoising, super-resolution, and anomaly discovery with exact likelihood scoring.
- Tools/products/workflows: Research platforms combining NF+AR pipelines with likelihood maps over large imagery; channel-group exploration for interpretable structure vs detail signals.
- Assumptions/dependencies: Scale to massive images (tiling strategies, memory constraints); domain-specific validation; careful handling of physical measurement noise.
- Finance and document forensics — sectors: finance, govtech
- What: Likelihood-based screening of document images (receipts, IDs) to detect tampering or unusual visual patterns.
- Tools/products/workflows: Back-office services scoring uploads, alerting on low-likelihood patterns; optional channel-level analysis to localize suspected edits.
- Assumptions/dependencies: Domain-specific pretraining; strong adversarial testing; privacy constraints; alignment with regulatory audit processes.
- Synthetic data factories with active learning gates — sectors: ML platforms, enterprise AI
- What: Large-scale synthetic generation with dynamic selection based on likelihood and downstream performance feedback, improving sample efficiency.
- Tools/products/workflows: Pipelines that farm samples per class, gate by NLL and task loss, retrain models iteratively; dashboards tracking “useful synthetic” yield.
- Assumptions/dependencies: Coupling between generative and downstream models; reliable feedback signals; compute budgeting for iterative loops.
Notes on feasibility across applications:
- Compute and scaling: Current models are 1.1–1.9B parameters trained ~320 epochs on ImageNet; deployment in production or new domains will require substantial compute, careful hyperparameter tuning (patch sizes, GMM components), and distillation.
- Data dependence: Exact likelihoods reflect the learned distribution; for anomaly/OOD uses, models must be trained on representative, domain-specific data and continuously updated for drift.
- Sampling requirements: Resampling-based CFG needs both conditional and unconditional heads, plus candidate sampling budgets (s, s’); runtime trade-offs must be profiled.
- Quality vs speed: One-step distillation provides significant reverse-time speedups but needs additional training and validations to ensure quality parity.
- Safety and governance: Healthcare and policy applications require rigorous validation, explainability, bias audits, and alignment with existing regulatory frameworks and provenance standards.
Glossary
- Annealed noise levels: A training technique where the magnitude of added noise is gradually reduced according to a schedule. "we enhance this technique by employing a noise augmentation strategy with annealed noise levels."
- Autoregressive (AR) models: Sequence models that factorize the joint probability by conditioning each element on previous ones. "Autoregressive (AR) models offer strong expressivity but struggle with pixel modeling and sampling due to the long sequences required for high-resolution images."
- Autoregressive Flow (AF): A normalizing flow whose transformation of each token is conditioned on preceding tokens, enabling causal invertibility. "Concretely, we implement the NF with an Autoregressive Flow (AF) architecture, ensuring causal modeling for NF/AR within FARMER."
- Autoregressive Transformer: A Transformer configured with causal attention to model next-token conditional distributions. "Then we model its probability distribution with a large causal AR Transformer."
- Bijective: A property of a function being both injective and surjective; in flows, it preserves dimensionality and allows exact inversion. "Although an invertible AF can faithfully map the data distribution, its bijective nature preserves dimensionality."
- Categorical distribution: A discrete probability distribution over a finite set of outcomes; used here to resample candidate tokens by normalized weights. "Resample from the categorical distribution that consists of the normalized weights of all candidates, to obtain the final sample."
- Causal modeling: Structuring models so that predictions at a position depend only on previous positions; essential for AR consistency. "ensuring causal modeling for NF/AR within FARMER."
- Chain rule (of probability): Factorization of a joint distribution into conditional probabilities. "AR models directly factorize sequence likelihoods via the chain rule and lead to the scaling successes of LLMs."
- Change-of-variables formula: The principle in probability that relates densities under invertible transformations via the Jacobian determinant. "Using the change-of-variables formula, NFs can calculate the exact probability density of a data point x as:"
- Classifier-Free Guidance (CFG): A sampling technique that combines conditional and unconditional model outputs to steer samples toward desired conditions. "Classifier-Free Guidance (CFG) has become a standard technique for improving sample quality in diffusion and autoregressive models."
- Cosine decay schedule: A learning or noise scheduling strategy that reduces a quantity following a cosine curve. "where the noise level σ is annealed from 0.1 to 0.005 via a cosine decay schedule."
- Dequantize: To add noise to discrete-valued data so it becomes continuous for density modeling. "It is a common practice to add a small amount of noise to raw image I to dequantize the discrete pixel values and create a more continuous data distribution."
- Fréchet Inception Distance (FID): A metric that measures the distance between generated and real image distributions in a feature space. "Metrics include Fréchet inception distance (FID), inception score (IS), precision and recall."
- Gaussian Mixture Model (GMM): A probabilistic model that represents data as a mixture of multiple Gaussian components. "we model each conditional probability p(z_i|z_{<i}) with a Gaussian mixture model (GMM)."
- Generative Adversarial Network (GAN): A generative modeling framework with a generator and discriminator trained adversarially. "Popular generative paradigms such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and diffusion/score-based models do not provide tractable likelihoods—"
- Inception Score (IS): A metric that evaluates both the confidence and diversity of generated images using a pretrained classifier. "Fréchet inception distance (FID), inception score (IS), precision and recall."
- Isotropic Gaussian: A Gaussian distribution with identical variance along all dimensions (spherical covariance). "forcing a high-dimensional and highly dispersed data distribution onto a simple isotropic Gaussian can introduce discontinuities or distortions"
- Jacobian determinant: The determinant of the Jacobian matrix of a transformation; in flows, it adjusts densities after transformation. "where det ( ∂F(x)/∂x ) denotes the determinant of the Jacobian matrix of the transformation F."
- Latent sequence: The sequence of continuous representations produced by a flow from raw pixels, modeled by an AR component. "FARMER employs an invertible autoregressive flow to transform images into latent sequences, whose distribution is modeled implicitly by an autoregressive model."
- Maximum Likelihood Estimation (MLE): A method that fits model parameters by maximizing the likelihood of observed data. "To facilitate training via maximum likelihood estimation, the learning objective is commonly formulated in terms of Negative Log-Likelihood (NLL):"
- Negative Log-Likelihood (NLL): A loss function equal to the negative logarithm of the likelihood; minimizing it is equivalent to MLE. "the learning objective is commonly formulated in terms of Negative Log-Likelihood (NLL):"
- Normalizing Flow (NF): An invertible neural transformation that maps complex data distributions to simpler ones while allowing exact likelihoods. "Normalizing flows (NFs) employ invertible mappings to transform complex image distributions to a standard Gaussian, but the substantial gap between two distributions leads to degraded sampling quality."
- One-step distillation: A distillation approach that learns a single-step student path approximating a multi-step teacher, speeding up inference. "we design a one-step distillation scheme to significantly accelerate inference speed"
- Patchify: To divide an image into non-overlapping patches and reshape them into a token sequence for modeling. "Then we patchify the noised image with a downsampling factor p to obtain the patch representation I'"
- Permutation (in flows): Reordering tokens or channels within a flow block to increase expressivity while maintaining invertibility. "we follow TARFlow and apply a permutation to the token sequence"
- Precision/Recall: Complementary metrics for generative evaluation measuring sample fidelity (precision) and coverage (recall). "Fréchet inception distance (FID), inception score (IS), precision and recall."
- Probability-flow ODE: A differential equation formulation used to compute likelihoods in diffusion models via continuous-time probability flow. "diffusion/score-based models offer likelihoods only via variational bounds or costly numerical estimation by probability-flow ODE."
- Resampling-based Classifier-Free Guidance: A practical CFG variant that proposes candidates from conditional/unconditional distributions and resamples by weighted probabilities. "Finally, we present a resampling-based Classifier-Free Guidance (CFG) algorithm to boost image generation quality."
- Self-supervised dimension reduction: A learning scheme that partitions latent channels into informative and redundant groups without labels. "we propose a self-supervised dimension reduction scheme that partitions NF latent channels into informative and redundant groups"
- Standard Gaussian prior: A prior assumption that variables follow a zero-mean, unit-variance Gaussian distribution. "assigns the redundant dimensions a standard Gaussian prior"
- Token: A single element in a sequence representation (e.g., a patch vector) used for autoregressive modeling. "AutoRegressive models formulate the likelihood of a token sequence z = (z_1, z_2, \ldots, z_N) by factorizing it into a product of next-token conditional probabilities:"
- Tractable likelihoods: Likelihoods that can be computed exactly or efficiently, enabling principled training and evaluation. "Popular generative paradigms such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and diffusion/score-based models do not provide tractable likelihoods—"
- Variational Autoencoder (VAE): A latent-variable generative model trained by maximizing a variational lower bound on data likelihood. "Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and diffusion/score-based models do not provide tractable likelihoods—VAEs optimize a lower bound"
Collections
Sign up for free to add this paper to one or more collections.

