Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation
Abstract: Recent studies have demonstrated the importance of high-quality visual representations in image generation and have highlighted the limitations of generative models in image understanding. As a generative paradigm originally designed for natural language, autoregressive models face similar challenges. In this work, we present the first systematic investigation into the mechanisms of applying the next-token prediction paradigm to the visual domain. We identify three key properties that hinder the learning of high-level visual semantics: local and conditional dependence, inter-step semantic inconsistency, and spatial invariance deficiency. We show that these issues can be effectively addressed by introducing self-supervised objectives during training, leading to a novel training framework, Self-guided Training for AutoRegressive models (ST-AR). Without relying on pre-trained representation models, ST-AR significantly enhances the image understanding ability of autoregressive models and leads to improved generation quality. Specifically, ST-AR brings approximately 42% FID improvement for LlamaGen-L and 49% FID improvement for LlamaGen-XL, while maintaining the same sampling strategy.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation”
Overview
This paper is about teaching computers to make better pictures. The authors focus on a popular kind of model called an autoregressive model, which normally writes text word by word. Here, it “draws” an image piece by piece, like placing tiles in a mosaic. Their main idea is simple: before a model tries to generate (draw) images, it should first learn to understand them better. They create a training method called ST-AR (Self-guided Training for AutoRegressive models) to help these models understand images more deeply, so the pictures they produce look more realistic and make more sense.
What questions did the paper ask?
The paper tries to answer three questions:
- Why do autoregressive image models sometimes make mistakes or create blurry or odd-looking images?
- How can we train these models so they understand the big picture of an image, not just tiny local details?
- Can we do this without using extra, pre-trained “helper” models?
To do that, they first show three problems that hold these models back:
- The model mostly looks at nearby pieces and the initial condition (like a class label), instead of the whole image. This is like writing a story by only checking the last sentence you wrote, not the entire plot.
- The meaning (semantics) the model learns can drift as it generates the image step by step, causing inconsistencies later on.
- The image “tokens” (like image words) can change a lot if the image is slightly cropped or moved, so the model sees the same object as totally different tokens and gets confused.
How did they approach it?
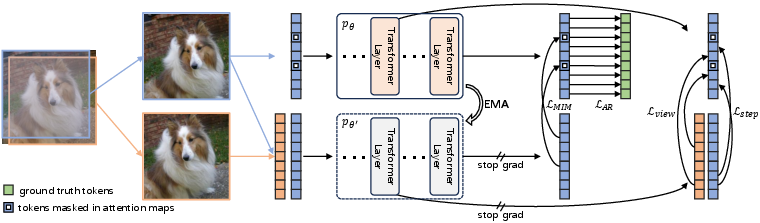
They design ST-AR, which adds self-supervised learning tricks during training to help the model understand images better. Think of self-supervised learning as learning by solving puzzles you make yourself, rather than using answer sheets.
Here are the key parts, explained with everyday analogies:
- Masked attention (like a scavenger hunt with some clues hidden): The model normally pays attention to nearby pieces. ST-AR randomly hides some of those attention connections during training so the model is forced to look farther away and use more global context. This is similar to covering parts of a map so you must use broader landmarks, not just nearby streets.
- Contrastive learning across steps (keeping your story’s theme consistent as you write): As the model generates the image step by step, ST-AR teaches it to keep the meaning consistent. It does this by making features from different steps of the same image more similar, and features from different images more different.
- Contrastive learning across views (recognizing the same object from different angles): The same image is slightly changed (like different crops or views). ST-AR tells the model to treat those as the same thing, so it won’t get fooled when an object shifts a little.
They also use a “teacher–student” setup: the teacher is a slower, more stable copy of the model that guides the student. The student tries to match the teacher’s understanding. The teacher’s weights are updated by averaging the student over time (EMA), so the teacher acts like a steady coach.
To check understanding, they use:
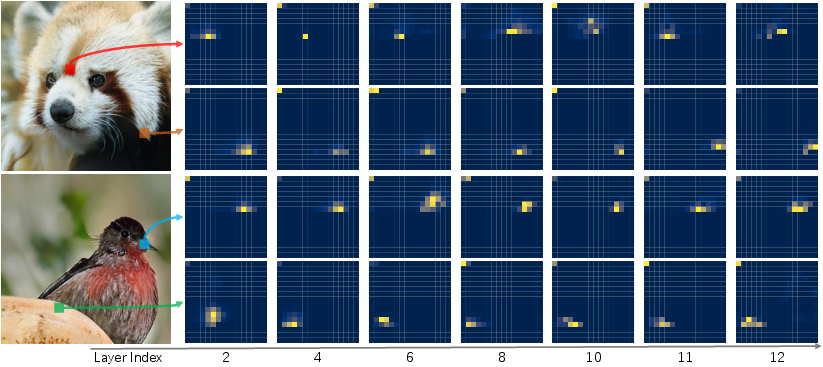
- Attention maps: show what parts of the image the model looks at.
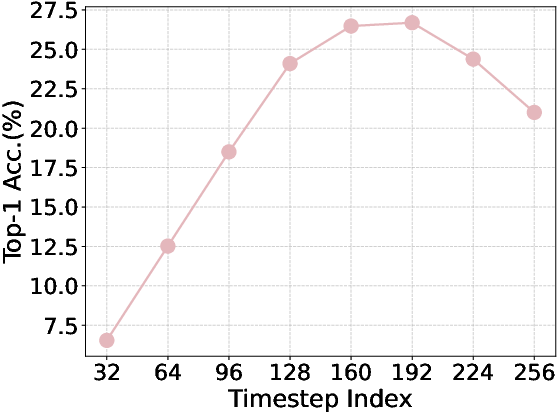
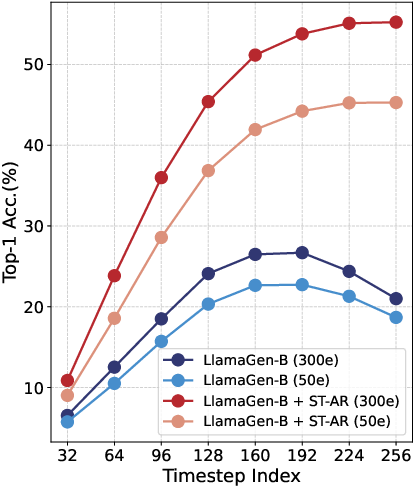
- Linear probing: freeze the model’s features and train a simple classifier on top to see how much meaningful information the model has learned.
- Image quality metrics like FID (lower is better) and Inception Score (higher is better), which measure realism and diversity of generated images.
What did they find?
- Better understanding: The model’s features became much more informative (big jump in linear probing accuracy). Attention maps expanded beyond just nearby pieces and showed clear, meaningful focus on important regions.
- More consistent semantics: The model kept a stable sense of what the image meant across many generation steps, instead of losing track later on.
- Stronger image quality: On ImageNet (a standard dataset), their method improved the main image quality score (FID) a lot—by about 42% for a large model (LlamaGen-L) and about 49% for an extra-large model (LlamaGen-XL). In some cases, a smaller model trained with ST-AR matched or beat a much larger baseline trained longer.
- No special sampling tricks needed: They kept the usual autoregressive “generate the next token” process at test time. All the extra smarts come from better training, not a complicated new generation procedure.
- No external helper models required: Unlike some other methods that borrow features from separate pre-trained encoders, ST-AR learns everything by itself.
Why does this matter?
If a model understands images better, it draws better images. That’s useful for many applications, from art and design to data augmentation and vision–language systems. Because autoregressive models are already great at language, improving their visual understanding helps move toward unified models that can handle text and images together smoothly.
Big picture impact and limitations
- Impact: ST-AR shows that adding simple self-supervised tasks during training can make image generation both sharper and more coherent. It also keeps the door open for combining image and language generation in one framework.
- Limitations: Training costs go up because of the extra objectives and the teacher–student setup. Also, as image generation gets better, there are responsible-use concerns around deepfakes and misuse. The authors note these risks.
In short, the paper’s message is: teach autoregressive image models to understand before they draw, and they will draw much better.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following points summarize what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research:
- Dataset and task generality: The study is limited to class-conditional ImageNet at 256×256 resolution. It does not evaluate ST-AR on other datasets (e.g., COCO, LAION, CIFAR, LSUN), higher resolutions (≥512×512), or out-of-domain distributions, nor on text-conditional or unconditional generation settings.
- Multimodal applicability: While motivated by unification across modalities, ST-AR is only validated for image AR. It is unclear how the approach transfers to multimodal AR (joint image–text generation), audio, or video token sequences, and whether contrastive objectives across modalities would remain effective.
- Tokenizer dependence and invariance: ST-AR is evaluated with a fixed VQ-GAN tokenizer. The sensitivity of gains to different tokenizers (e.g., VQ-VAE, residual VQ, RVQ with multi-codebooks, learned tokenizer resolutions) is not studied. It remains open whether jointly training a tokenizer with explicit invariance constraints (e.g., rotation/scale robustness) would further reduce inter-view inconsistencies or obviate parts of ST-AR.
- End-to-end training with the tokenizer: The paper precomputes tokens and does not explore end-to-end training where VQ-GAN or alternative tokenizers are updated jointly with ST-AR losses, nor how inter-view contrastive loss could regularize tokenizer codebook learning.
- Attention masking design space: Masking is applied randomly to attention maps with a fixed ratio. The impact of structured masks (e.g., ring/stripe/block masks, distance-biased masks), per-head/per-layer mask policies, or step-dependent mask schedules is not investigated. A quantitative measure of effective receptive field expansion (beyond visual attention maps) is missing.
- Inference-time behavior: Masking is used only during training; inference uses standard causal attention. It is unclear how training-time masking translates to inference-time global context usage, and whether certain mask policies yield more robust inference behavior across steps.
- Contrastive learning choices: The approach uses batch negatives without a temperature parameter and a SimSiam-style projector. It does not examine alternative designs (InfoNCE with temperature, memory queues like MoCo, hard negative mining, multi-layer projectors/predictors, stop-gradient variants) or their stability/performance trade-offs.
- Step-wise positive pair selection: The inter-step contrast treats any different timestep in the same view as a positive. The impact of step distance (near vs. far timesteps), adaptive weighting by step distance, or curriculum strategies for step selection (K schedule over training) is not explored.
- Loss interactions and hyperparameter sensitivity: Beyond limited ablations (mask ratio, contrastive depth, K), there is no systematic study of sensitivity to α/β weighting, projector architecture, augmentation policies, EMA decay schedules, or layerwise application of losses. Automatic loss balancing or adaptive scheduling remains an open area.
- Layerwise application: Contrastive losses are applied at a single “mid” layer. The effect of multi-layer application, layerwise loss weighting, or aligning hierarchical features (early vs. late layers) is not studied.
- Augmentation policy for inter-view contrast: The inter-view objective uses “random augmentations,” but the paper does not specify or ablate augmentation types/strengths (geometric vs. photometric, strong vs. weak), nor analyze which augmentations best enforce meaningful invariances in the discrete token space.
- Training cost quantification: The paper acknowledges increased training cost but does not quantify compute/memory overheads attributable to the teacher network, masking, and contrastive losses, nor provide scaling curves or efficiency optimizations (e.g., partial masking, layer dropping, gradient checkpointing).
- Sampling speed and latency: While inference strategy remains unchanged, the impact of ST-AR on sampling speed (e.g., due to altered attention patterns or feature distributions) and latency/throughput on large-scale models is not reported.
- Scaling beyond 775M parameters: ST-AR is shown up to LlamaGen-XL (775M) and compared against a 3.1B baseline trained without ST-AR. It remains unknown how ST-AR scales at ≥3B parameters, whether the gains persist or saturate, and how compute budget interacts with benefits.
- Classifier-free guidance (CFG) interplay: Results with CFG are reported, but the interaction of ST-AR with guidance scales, dropout ratios, calibration, and conditional fidelity is not analyzed (e.g., whether ST-AR shifts the optimal CFG settings or improves guidance robustness).
- Semantic consistency across steps: The method claims improved inter-step consistency, but does not provide quantitative measures beyond linear probing (e.g., explicit metrics for feature drift across steps, attention distance distributions) or step-wise error propagation analysis.
- Diversity and mode coverage: Precision/recall and sFID are reported, but there is no per-class analysis, human perceptual evaluation, or systematic assessment of diversity/mode collapse across classes or prompts in text-conditional settings.
- Robustness to corruptions and adversarial perturbations: The claimed invariance improvements are not tested under distribution shifts (noise, blur, compression, occlusion) or adversarial attacks in token/image space, nor is the sensitivity of the tokenizer to such perturbations addressed.
- Comparisons to representation injection baselines: ST-AR is conceptually positioned against methods that distill pre-trained representations (e.g., REPA), but there is no empirical comparison inside the AR paradigm (e.g., AR + representation distillation) to establish relative merits or combined effects.
- Theoretical justification: There is no theoretical analysis linking improved representation consistency (via ST-AR) to bounds on generation quality (e.g., FID) or formalizing how attention masking affects causal AR’s global context modeling; a principled theory could guide mask/contrast design.
- Raster-order dependence and alternative generation orders: The paper retains raster-order causal sampling. It does not examine whether ST-AR’s benefits carry over to alternative orders (e.g., coarse-to-fine scales, blockwise generation) or masked/parallel AR variants, nor if synergies exist.
- EMA teacher reliance: The teacher is an EMA of the student. It is unknown whether external teachers (e.g., pre-trained visual transformers), multi-teacher ensembles, or alternative update schemes improve stability or performance, or if ST-AR can be made teacher-free without sacrificing gains.
- Token length and sequence structure: The approach assumes fixed token length and raster layout. The impact of varying sequence length, token grouping or reordering, and positional encoding schemes on ST-AR’s objectives is not investigated.
- Precomputed tokens vs. on-the-fly augmentations: The paper states precomputed tokens for training but also uses augmented views fed through VQ-GAN; it is unclear how token precomputation interacts with augmentation-heavy training (e.g., IO/compute trade-offs, token-cache design).
- Downstream tasks and zero-shot transfer: Improved linear probing is reported, but there is no evaluation on downstream tasks (classification, segmentation, detection) or zero-shot transfer to other datasets, leaving the general utility of learned representations unverified beyond generation.
- Safety and misuse: The societal impact note is brief. There is no concrete mitigation plan (watermarking, provenance tracking, content filters, robust conditioning) to address manipulation risks associated with improved AR generation.
Glossary
- AdamW optimizer: An adaptive gradient-based optimizer that decouples weight decay from the gradient update to improve generalization. "AdamW optimizer with "
- ADM evaluation suite: A standardized toolkit/protocol for evaluating generative models on common metrics. "we use the ADM evaluation suite and report Fréchet Inception Distance (FID)"
- Attention maps: Visualizations of attention weights indicating which tokens a transformer focuses on during prediction. "Attention maps reveal what the model relies on for predictions and whether it can capture image context."
- Autoregressive (AR): A generative modeling approach that predicts the next token conditioned on previous tokens. "autoregressive models (AR)~\cite{esser2021taming,sun2024autoregressive}"
- Bi-directional attention: An attention mechanism where tokens can attend to both past and future positions in a sequence. "employ bi-directional attention within an encoder-decoder framework"
- Causal AR methods: Autoregressive image generators that follow a strictly forward (causal) token order, analogous to LLMs. "Causal AR methods, such as VQ-GAN~\cite{esser2021taming} and LlamaGen~\cite{sun2024autoregressive}, directly adapt AR architectures for image synthesis"
- Causal attention: An attention masking scheme that allows each position to attend only to previous positions, enforcing a generation order. "The application of causal attention to images presents two critical challenges"
- Classifier-free guidance (CFG): A sampling technique that steers generative models by interpolating between conditional and unconditional predictions. "All the results are evaluated without using CFG on ImageNet."
- Conditional token: The special token at the initial step that encodes conditioning information (e.g., class or text). "the input at the initial step is the conditional token"
- Conditional vector: An embedding that represents conditioning information used for generation (e.g., class label or text). "based on the conditional vector and the preceding tokens"
- Contrastive learning: A self-supervised paradigm that learns representations by pulling positives together and pushing negatives apart. "we employ contrastive learning~\cite{chen2021empirical} to ensure the consistency of feature vectors from different time steps and views"
- Cosine distance: A similarity-based distance measure using the cosine of the angle between vectors. "defaulting to cosine distance"
- Diffusion models: Generative models that learn to reverse a gradual noising process to synthesize data. "including diffusion models~\cite{bao2023all,dhariwal2021diffusion,peebles2023scalable}"
- Effective receptive field: The region of the input that effectively influences a model’s representation or prediction. "masked image modeling (MIM) can expand the effective receptive field of image encoding models."
- EMA (Exponential Moving Average): A parameter-averaging technique that updates a teacher model as a smoothed version of the student. "weights are updated through the Exponential Moving Average (EMA) of the student model parameters ."
- Encoder-decoder framework: An architecture with separate modules for encoding inputs and decoding outputs, often enabling bidirectional context. "employ bi-directional attention within an encoder-decoder framework"
- Fréchet Inception Distance (FID): A metric comparing feature distributions of real and generated images to assess quality and diversity. "report Fréchet Inception Distance (FID)\cite{heusel2017gans} as the main evaluation metric."
- Gradient clipping: A training stabilization technique that limits the magnitude of gradients to prevent exploding updates. "gradient clipping set to $1.0$"
- iBOT-style framework: A training design inspired by iBOT that combines masked modeling with self-distillation/contrastive objectives. "forming an iBOT-style~\cite{zhou2021ibot} framework."
- Inter-step contrastive loss: A contrastive objective enforcing semantic consistency across different generation steps within the same image. "referred to as inter-step contrastive loss and inter-view contrastive loss, respectively."
- Inter-view contrastive loss: A contrastive objective enforcing representation consistency across different augmented views of the same image. "referred to as inter-step contrastive loss and inter-view contrastive loss, respectively."
- Linear probing: A representation evaluation method that trains a linear classifier on frozen features. "linear probing results on features from the layer at 8 uniformly selected steps."
- Masked AR methods: Autoregressive generators that use masked token prediction and often bidirectional attention for iterative sampling. "Masked AR methods, like MaskGiT~\cite{chang2022maskgit} and MAR~\cite{li2024mar}, employ bi-directional attention within an encoder-decoder framework"
- Masked image modeling (MIM): A self-supervised task where models reconstruct masked parts of images to learn visual context. "inspired by masked image modeling~\cite{xie2022simmim,he2022masked}"
- MaskGiT: A masked generative image transformer that performs iterative masked token prediction. "Masked AR methods, like MaskGiT~\cite{chang2022maskgit} and MAR~\cite{li2024mar}"
- MoCo-like contrastive losses: Contrastive objectives following the Momentum Contrast paradigm to stabilize and scale representation learning. "employing MoCo-like contrastive losses to align representations across different time steps and different views."
- Next-scale prediction: A strategy that predicts tokens progressively at increasing resolutions or scales. "VAR~\cite{tian2024var} proposes next-scale prediction that progressively generates tokens at increasing resolutions."
- Next-token prediction paradigm: The training/generation scheme where each token is predicted conditioned on previously generated tokens. "the mechanisms of applying the next-token prediction paradigm to the visual domain."
- Parallelized AR methods: Autoregressive generators that relax strict token-by-token causality to generate multiple tokens simultaneously. "Parallelized AR methods introduce vision-specific designs to enhance visual signal modeling capability."
- Projector: An MLP head used to map features into a space suitable for contrastive losses and to prevent collapse. "we employ a projector , which consists of several MLPs, on the student features"
- Quantized autoencoder: An autoencoder that discretizes latent representations into a codebook of tokens. "a quantized autoencoder is employed to convert to a sequence of discrete tokens"
- Quantizer: The component that maps continuous latents to discrete codebook indices. "and denote the encoder and quantizer of the quantized autoencoder."
- Raster-order next-token prediction: Generating image tokens in a left-to-right, top-to-bottom sequence akin to text ordering. "utilizing the traditional raster-order next-token prediction paradigm as LLMs."
- Self-guided Training for AutoRegressive models (ST-AR): The proposed framework that augments AR training with MIM and contrastive objectives via a teacher-student setup. "Self-guided Training for AutoRegressive models (ST-AR)"
- Self-supervised learning: Learning representations from unlabeled data using proxy tasks or instance discrimination. "leverages techniques well-explored in self-supervised learning to enhance the modeling of visual signals."
- SimSiam: A self-supervised method using a stop-gradient Siamese setup without negatives, often with a projector/predictor. "Following SimSiam\cite{chen2020simsiam}, we employ a projector "
- Spatial invariance deficiency: The lack of robustness to spatial transformations, leading to inconsistent tokenizations or features. "spatial invariance deficiency."
- Teacher network: A non-trainable network (often EMA of the student) providing stable targets for self-supervised objectives. "A non-trainable teacher network\cite{chen2020mocov2,he2019moco,caron2021emerging} is employed"
- Token grouping strategies: Techniques that partition tokens into groups to enable parallel generation steps. "PAR~\cite{wang2024par} and NPP~\cite{pang2024npp} propose token grouping strategies to generate image tokens in parallel."
- Token prediction loss: The negative log-likelihood objective for next-token prediction over sequences. "And the token prediction loss is:"
- Visual tokenizer: A module (e.g., VQ-based) that converts images into sequences of discrete tokens. "Autoregressive image generation models typically employ visual tokenizers, such as VQ-GAN~\cite{esser2021taming,lee2022autoregressive} to quantize images into discrete tokens."
- Visual tokens: Discrete codebook indices representing image patches produced by a visual tokenizer. "Visual tokens lack invariance."
- VQ-GAN: A vector-quantized generative adversarial network used to tokenize and reconstruct images from discrete codes. "VQ-GAN~\cite{esser2021taming,lee2022autoregressive}"
- Weight decay: An L2-regularization-like penalty applied to weights to improve generalization. "weight decay set to $0.05$"
- sFID: A variant of FID reported in evaluation tables as an additional image quality/diversity metric. "sFID"
Collections
Sign up for free to add this paper to one or more collections.