ReCode: Unify Plan and Action for Universal Granularity Control
Abstract: Real-world tasks require decisions at varying granularities, and humans excel at this by leveraging a unified cognitive representation where planning is fundamentally understood as a high-level form of action. However, current LLM-based agents lack this crucial capability to operate fluidly across decision granularities. This limitation stems from existing paradigms that enforce a rigid separation between high-level planning and low-level action, which impairs dynamic adaptability and limits generalization. We propose ReCode (Recursive Code Generation), a novel paradigm that addresses this limitation by unifying planning and action within a single code representation. In this representation, ReCode treats high-level plans as abstract placeholder functions, which the agent then recursively decomposes into finer-grained sub-functions until reaching primitive actions. This recursive approach dissolves the rigid boundary between plan and action, enabling the agent to dynamically control its decision granularity. Furthermore, the recursive structure inherently generates rich, multi-granularity training data, enabling models to learn hierarchical decision-making processes. Extensive experiments show ReCode significantly surpasses advanced baselines in inference performance and demonstrates exceptional data efficiency in training, validating our core insight that unifying planning and action through recursive code generation is a powerful and effective approach to achieving universal granularity control. The code is available at https://github.com/FoundationAgents/ReCode.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “ReCode: Unify Plan and Action for Universal Granularity Control”
1) What is this paper about?
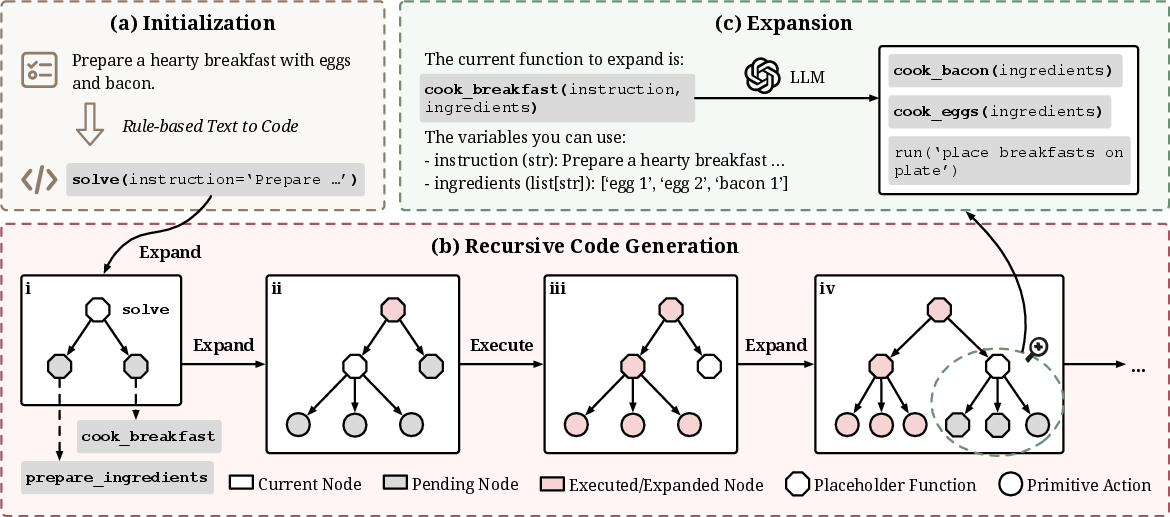
This paper introduces ReCode, a new way to make AI agents (smart programs powered by LLMs) think and act more like humans. Humans can plan at big-picture levels (“make breakfast”) and then switch smoothly to small, detailed actions (“crack an egg”). ReCode lets AI do the same thing by treating plans and actions as the same kind of thing: pieces of code. Big plans are written as “placeholder” functions that get broken down step by step into smaller sub-plans and finally into simple actions the agent can execute.
2) What questions does the paper try to answer?
The paper focuses on three simple questions:
- Can AI agents make decisions at different levels of detail, switching smoothly between big-picture plans and tiny, step-by-step actions?
- If we represent both plans and actions as code, can the agent handle complex tasks better?
- Does this approach help the agent learn faster and use less data and money while still getting better results?
3) How does ReCode work? (With everyday analogies)
Think of ReCode like writing a recipe as code:
- A high-level plan (like “prepare_breakfast()”) is a placeholder function — basically a “to-do” step that isn’t fully written yet.
- The AI then expands that function into smaller steps (like “get_ingredients()” and “cook_meal()”).
- It keeps breaking those down until it reaches the simplest actions (like
run('open refrigerator')orrun('turn on stove')) that it can actually do right away.
This process is called “recursive code generation.” “Recursive” means the agent repeats the same idea (break it down!) on smaller and smaller pieces until it’s simple enough to act. It builds a decision tree as it goes: big plan at the top, medium steps in the middle, tiny actions at the bottom.
Technical terms explained simply:
- Granularity: How detailed a decision is. Coarse = big-picture plan; fine = tiny step.
- Placeholder function: A plan step that says “we need to do this” but doesn’t spell out the details yet.
- Primitive actions: The smallest actions the agent can do right away (like clicking a button).
- Policy model: The AI brain that decides what code to write next.
- Environment: The world the agent acts in (like a house, a lab, or a website).
4) What did they find, and why does it matter?
The researchers tested ReCode in three simulated worlds:
- ALFWorld: a virtual home with household tasks (like “put the alarm clock in the dresser”).
- WebShop: an online store where the agent shops based on your requirements.
- ScienceWorld: a virtual lab where the agent runs experiments.
Here’s what stood out:
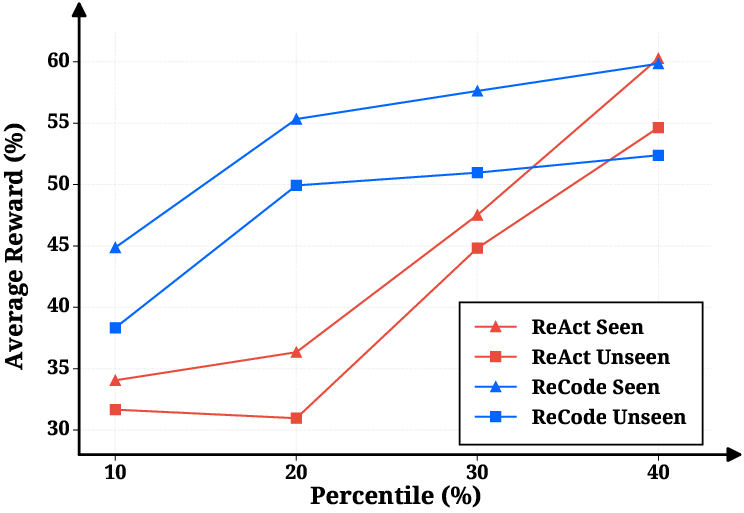
- Better performance: ReCode beat other popular methods (like ReAct, CodeAct, and planning tools) across different tasks and models. For example, in ALFWorld, ReCode did especially well, including on “unseen” tasks it hadn’t trained on.
- Lower cost: ReCode was much cheaper to run (fewer API calls and tokens), because it uses smarter, more organized thinking instead of long, chatty back-and-forth steps.
- More data-efficient: When training the agent, ReCode needed fewer examples to learn good behavior. Its “plan-as-code” structure gives richer training signals, because the data naturally includes the whole thinking process (big plan → sub-plan → actions), not just a flat list of steps.
- Right amount of detail: The team found there’s a “sweet spot” for how deep the recursion should go. Too shallow and the agent can’t plan well; too deep and it gets lost in tiny details. A moderate depth worked best.
These results matter because they show a clear path to making AI agents both smarter and more practical: they can think strategically, act efficiently, and learn quickly.
5) What’s the bigger impact?
If AI can treat planning and acting as the same kind of code, it can:
- Handle complex, real-world tasks more reliably (like multi-step shopping, lab procedures, or home automation).
- Adapt to new situations by choosing the right level of detail — zooming out to plan or zooming in to act.
- Train faster and cheaper, making it more accessible for everyday applications.
There are still limits: ReCode depends on how good the underlying LLM is and how well it follows the code format. Future work could improve training, add rewards for efficient plans, and make error handling even more robust.
In short, ReCode shows a promising way to build smarter, more adaptable AI agents by unifying “what to do” and “how to do it” into one simple idea: code that plans and acts, step by step.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps that remain unresolved and can guide future research:
- Formal grounding: No theoretical connection to hierarchical RL (e.g., options/semi-MDPs) or proof of optimality, convergence, or sample complexity for recursive code generation.
- Granularity control metrics: “Universal granularity control” is asserted but not quantified; no metrics track chosen abstraction levels, branching factors, or depth distributions, nor analyses linking these to success.
- Adaptive halting: Recursion depth is a fixed hyperparameter with limited ablation (one environment); no learned stopping criterion or task-adaptive depth controller.
- Search strategy: Only depth-first expansion is explored; no comparison to best-first, beam search, MCTS, or backtracking over alternative decompositions.
- Error handling and verification: Recovery relies on a simple self-correction loop using tracebacks; no static analysis, grammar constraints, type checking, unit tests, or formal verification before execution.
- Code safety and sandboxing: Executing LLM-generated Python is a security risk; the paper does not specify sandboxing, resource limits, allowed subsets of Python, or defenses against malicious/infinite code.
- Representation design: It is unclear which language features (loops, conditionals, imports, external calls) are permitted; the trade-off between Python vs. a safer typed DSL with constrained APIs is not explored.
- Context management limitations: The model only sees current variables, not execution history; no ablation on including selective history/memory; risk of information loss and state staleness is unquantified.
- Scaling of the variable namespace: No analysis of how variable serialization scales with long horizons (context length growth, retrieval errors) or strategies for compression, scoping, or memory pruning.
- Partial observability: No explicit belief-state tracking or learned world models; robustness to stochasticity and hidden-state uncertainty is not evaluated.
- Generalization scope: Evaluations are limited to three text-based simulators; no results on real browsers, real robotics, multimodal (vision/audio) tasks, or noisy real-world environments.
- Tool/action schema portability: The approach assumes a “run(...)” interface; there is no study of automatic tool discovery, grounding to unfamiliar APIs, or resilience to schema changes.
- Reusability of subroutines: Placeholder functions are not persisted as libraries; no mechanism to learn, cache, and reuse subroutines across tasks, or to standardize naming and signatures.
- Search-efficiency vs. performance: While token costs are reported, wall-clock latency, CPU/GPU overhead, interpreter execution time, and memory usage of recursion/execution are not measured.
- Data efficiency confounds: Training comparisons are not controlled for equal token budgets/steps; differing pair counts and token totals (and top-40% filtering) may confound claims of data efficiency.
- Teacher-dependence: Trajectories come from a single teacher (DeepSeek-V3.1); sensitivity to teacher quality/diversity, mixing multiple teachers, and the effect of reward thresholds are not studied.
- Baseline parity: Planner baselines and advanced training methods are not re-implemented under identical setups; missing comparisons to strong hierarchical/planning agents (e.g., options, ToT/MCTS with code).
- Robustness to adversarial inputs: No evaluation against prompt injection, malicious observations, or adversarial environment outputs that could corrupt code or variables.
- Failure mode analysis: No systematic taxonomy/quantification of failure causes (format drift, recursion loops, dead ends, variable mismanagement) or targeted mitigations.
- Long-horizon limits: Depth>10 and very long-horizon tasks are not tested; behavior under extreme decomposition (tree blow-up, compounding errors) is unknown.
- Halting and success detection: Termination is defined by “only primitive actions” in a block and environment reward; mechanisms for goal satisfaction checks or fail-safe fallback strategies are absent.
- Learning objectives: No auxiliary losses to encourage efficient decompositions (e.g., minimizing expansions/steps), or regularizers for compositionality and abstraction consistency.
- Cross-domain transfer: No study of training on one environment and testing on another, or mixing domains to test compositional and structural generalization.
- Multi-agent extensions: The paradigm’s applicability to collaborative planning, task allocation, and conflict resolution across agents is unexplored.
- Few-shot and prompt sensitivity: Performance depends on few-shot formatting; there is no robustness analysis to prompt style/length or code-style variance.
- Program structure quality: No structural metrics (e.g., cyclomatic complexity, modularity, reuse) to verify that generated code is genuinely hierarchical rather than linearized scripts.
- Safety and ethical considerations: Executing generated code raises safety risks; policies for auditing, permissioning, and human-in-the-loop oversight are not discussed.
Practical Applications
Immediate Applications
The following applications can be deployed now by mapping ReCode’s unified “plan-as-code” and recursive expansion to existing APIs, RPA tools, browsers, IDEs, and cloud services. Each item notes sector, proposed tool/product/workflow, and key dependencies.
- Bold: Web automation and RPA copilots
- Sector: Software, E-commerce, Back-office Operations
- What: Agents that automate multi-step web tasks (search → filter → compare → purchase; form-filling; logistics tracking) by decomposing high-level intents into Playwright/Selenium actions, adapting granularity on-the-fly when pages are complex or dynamic.
- Tools/products/workflows: “ReCode Browser Agent” integrating Playwright/Selenium; UiPath/Automation Anywhere activity wrappers; Zapier/Make connectors using placeholder functions for SOPs.
- Assumptions/dependencies: Stable selectors or robust locator strategies; anti-bot policies; authenticated API/session handling; curated primitive action library; model adherence to code format; depth limits tuned to site complexity.
- Bold: E-commerce shopping assistants
- Sector: Retail, Consumer Apps
- What: Personal shopping copilots that plan at high level (budget, specs) then refine into product search, comparison, and checkout actions—mirroring WebShop gains and significantly lowering token/call costs.
- Tools/products/workflows: Browser extensions; embedded assistant in marketplaces; “compare-and-buy” mobile app.
- Assumptions/dependencies: Merchant APIs or scrape policies; payment tokens and security compliance; price/availability volatility handling.
- Bold: IDE and DevOps orchestration agents
- Sector: Software Engineering, DevOps
- What: GitHub/GitLab agents that take an issue and recursively expand into sub-tasks (tests, scripts, config changes), executing safe primitives (run tests, update CI config) and pausing for human approval on risky steps.
- Tools/products/workflows: VS Code/JetBrains plugin (“expand placeholder function”); CI/CD bots for staged rollouts; test generation and repair as primitive actions.
- Assumptions/dependencies: Fine-grained permissions, sandboxed execution, strong audit logs; reliable unit/integration test signals; org policy hooks for approvals.
- Bold: Business process digitization from SOPs
- Sector: Enterprise Operations, Compliance
- What: Convert SOPs into placeholder functions that the agent refines into executable steps (e.g., onboarding, expense approvals) with dynamic granularity (batch vs case-by-case).
- Tools/products/workflows: BPMN-to-ReCode converters; ServiceNow/Workday connectors; hierarchical trace logs for audits.
- Assumptions/dependencies: Clear API coverage of target systems; change management; role-based access; human-in-the-loop gates for exceptions.
- Bold: Scientific computing and data pipeline copilots
- Sector: Academia, R&D, MLOps
- What: Orchestrate analysis pipelines (data fetch → preprocess → train → evaluate) using placeholder functions for stages and primitive actions for job submission, artifact tracking, and reproducibility.
- Tools/products/workflows: Jupyter “expand plan” magic; Airflow/Prefect/Dagster integration; MLflow/W&B logging of hierarchical traces.
- Assumptions/dependencies: HPC/cluster schedulers; reliable metadata capture; isolation and cost controls for long runs.
- Bold: Educational stepwise tutors and graders
- Sector: Education, EdTech
- What: Tutors that show multi-granularity solution plans (outline → sub-steps → final steps), and graders that align rubric items with plan nodes for transparent feedback.
- Tools/products/workflows: LMS plugins that render plan trees; “show next level of detail” UI control; automatic hint generation.
- Assumptions/dependencies: Domain ground truth or exemplars; format adherence; safe content filters.
- Bold: Agent training data generation with hierarchical supervision
- Sector: AI/ML Tooling
- What: Use ReCode to generate compact, multi-granularity SFT datasets, improving data efficiency and lowering labeling costs (as evidenced by 3–4× fewer pairs achieving higher scores).
- Tools/products/workflows: “ReCode Data Engine” that harvests decision trees; DPO/RLAIF pipelines that leverage plan/action levels; curriculum sampling by recursion depth.
- Assumptions/dependencies: Access to a strong teacher model; trajectory filtering criteria; reproducible environment APIs.
- Bold: Cost-efficient inference for existing agentic apps
- Sector: Cross-industry
- What: Replace step-by-step ReAct loops with ReCode’s recursive decomposition to cut token/API spend (≈79–84% reported) while improving outcomes.
- Tools/products/workflows: Drop-in policy wrapper; auto-depth controller; per-task cost guardrails.
- Assumptions/dependencies: Comparable few-shot exemplars; monitoring for over-/under-decomposition.
- Bold: Smart home orchestration
- Sector: Consumer IoT
- What: “Do evening routine” expands into device-specific primitives (lights, HVAC, locks, media), with adjustable detail when devices require calibration or context.
- Tools/products/workflows: Home Assistant/OpenHAB adapters; room/scene variable namespaces; error recovery via self-correction loop.
- Assumptions/dependencies: Reliable device APIs; state observability; safety constraints for actuators.
- Bold: Customer support and CRM task triage
- Sector: Customer Experience, Sales Ops
- What: From “resolve refund request” to sub-plans (verify purchase → check policy → issue credit), executing CRM primitives and escalating when uncertain.
- Tools/products/workflows: Salesforce/Zendesk connectors; knowledge base retrieval as an action; compliance audit via hierarchical trace.
- Assumptions/dependencies: Policy sources; identity/permissions; clear escalation paths.
Long-Term Applications
These require further research, integration, safety validation, or scale-up (e.g., grounding to perception/actuation, regulatory compliance, robust verification).
- Bold: General-purpose embodied robotics with adjustable autonomy
- Sector: Robotics, Manufacturing, Warehousing
- What: Robots that decompose tasks (e.g., “assemble kit,” “pick-pack-ship”) into reusable skills and context-aware micro-actions, switching granularity based on uncertainty or sensor feedback.
- Tools/products/workflows: Skill libraries as primitive functions; vision-language-action grounding; sim-to-real adaptation; mixed-initiative UI for human override.
- Assumptions/dependencies: Robust perception; latency-sensitive control; safety certs; fail-safe recovery; standardized robot APIs.
- Bold: Clinical workflow orchestration and care pathways
- Sector: Healthcare
- What: Agents that expand clinical pathways (triage → diagnostics → orders → discharge planning) with fine-grained EHR actions; adjustable detail for complex comorbidities.
- Tools/products/workflows: Epic/Cerner SMART-on-FHIR integrations; CDS hooks at plan nodes; plan trace for auditability.
- Assumptions/dependencies: HIPAA/GDPR compliance; clinical oversight; bias/fairness testing; formal verification of safety constraints.
- Bold: Autonomous lab platforms (wet/dry)
- Sector: Pharma, Materials, Bioengineering
- What: Hierarchical planning of experimental protocols, lab equipment control, and iterative optimization (design → execute → measure → refine).
- Tools/products/workflows: Lab automation APIs (Opentrons, Hamilton); LIMS/ELN integration; Bayesian optimization as callable sub-plans.
- Assumptions/dependencies: High-fidelity device control; contamination/safety SOPs; validated protocol libraries.
- Bold: Grid and industrial control planning
- Sector: Energy, Utilities, Process Industries
- What: Multi-level contingency planning and dispatch (forecast → schedule → curtail → restore) with real-time refinement under disturbances.
- Tools/products/workflows: SCADA/EMS adapters; digital twin as planning sandbox; safety interlocks at primitive actions.
- Assumptions/dependencies: Deterministic control envelopes; certification and red-team testing; cyber-physical security.
- Bold: Financial operations and compliance copilot
- Sector: Finance
- What: From “rebalance portfolio” to concrete trade orders and post-trade checks; from “KYC review” to granular document verification and risk scoring.
- Tools/products/workflows: OMS/EMS APIs; rules engines at plan nodes; immutable plan/action logs for regulators.
- Assumptions/dependencies: Market microstructure risks; adversarial manipulation; strong guardrails and approvals.
- Bold: Emergency response and policy implementation
- Sector: Public Sector, Emergency Management
- What: High-level response strategies (wildfire, flood, outbreak) decomposed into logistics, communications, and resource allocation actions; dynamic replanning as data streams in.
- Tools/products/workflows: Integration with 911/CAD, ICS structures; geospatial data ingestion; cross-agency plan sharing.
- Assumptions/dependencies: Data reliability; authority and governance; tested escalation protocols.
- Bold: Enterprise-wide multi-agent project management
- Sector: Cross-industry
- What: Portfolio-level plans recursively assigned to departmental agents that further decompose into executable tasks, coordinating dependencies and budgets.
- Tools/products/workflows: PM tools (Jira, Asana) orchestration; dependency graph as decision tree; budget/time constraints as plan predicates.
- Assumptions/dependencies: Robust scheduling under uncertainty; access control; alignment with human incentives.
- Bold: Verified agent safety toolchain
- Sector: AI Safety, Tooling
- What: Static/dynamic analysis of generated code plans; conformance checking for primitives; depth and scope policies; formal verification for critical steps.
- Tools/products/workflows: Type-checked DSL for primitives; runtime guards; “plan linting” and test harnesses; counterfactual simulations.
- Assumptions/dependencies: Standardization of primitive interfaces; formal specs; performance overhead tolerances.
- Bold: Automatic skill library induction and reuse
- Sector: Agent Platforms
- What: Mine frequently occurring subtrees into reusable, parameterized skills; auto-select skill granularity per context; marketplace of verified skills.
- Tools/products/workflows: Skill discovery service; telemetry-based skill evolution; provenance tracking.
- Assumptions/dependencies: High-quality telemetry; IP/licensing; versioning and compatibility management.
- Bold: Human–AI mixed-initiative UIs with “granularity sliders”
- Sector: Productivity, Design, Education
- What: Interfaces where users request more/less detail at any point in the plan tree; negotiate plan structures; inspect and edit placeholders before execution.
- Tools/products/workflows: Tree visualizers; inline editing of function signatures; side-by-side simulation of alternative decompositions.
- Assumptions/dependencies: Usability research; explainability standards; secure live-edit execution contexts.
Notes on Feasibility and Deployment
- Model capability and format adherence: Success depends on LLMs reliably generating well-formed code and respecting ReCode’s placeholder/function conventions; few-shot exemplars and lightweight validators help.
- Environment grounding: Practical use requires a vetted set of primitive actions with clear side effects, robust error handling, and state observability.
- Depth and recursion controls: Tuning max depth (empirically optimal range observed at 6–12) and implementing self-correction loops are important to avoid over-/under-decomposition.
- Safety, governance, and audit: Hierarchical traces offer strong auditability; add approval gates, policy checks, and formal verification for sensitive domains.
- Cost and performance: ReCode can cut token/API costs substantially; monitor for regressions where tasks need very deep decomposition or high stochasticity.
- Tooling gaps: Beneficial additions include a plan linter, depth controller, primitive registry with contracts, sandboxed executors, and standardized logging of decision trees.
Glossary
- ADaPT: A planning method that decomposes tasks on demand, using a sub-executor to carry out subtasks. "and ADaPT~\citep{prasad2024adapt}, which decomposes tasks on-demand using ReAct as the sub-task executor."
- AdaPlanner: A planner that pre-writes executable action sequences and iteratively revises them based on feedback. "AdaPlanner~\citep{sun2023adaplanner}, which pre-writes action sequences in Python and iteratively modifies them based on environmental feedback;"
- ALFWorld: A text-based embodied household environment for task-oriented agent evaluation. "ALFWorld~\citep{shridhar2021alfworld} provides an embodied household environment where agents navigate and manipulate objects to complete daily tasks."
- CodeAct: A code-based agent paradigm that expands the action space to Python code for more expressive actions. "CodeAct~\citep{wang2024executable}, extending ReAct's action space from natural language to Python code."
- decision granularity: The level of abstraction at which decisions are made, ranging from high-level plans to low-level actions. "enabling the agent to dynamically control its decision granularity."
- Direct Preference Optimization: A training approach that optimizes models directly from preference data rather than explicit rewards. "ETO~\citep{song2024trial}, which learns from expert trajectories via Direct Preference Optimization~\citep{rafailov2023direct};"
- few-shot prompts: Prompts containing a small number of examples to guide model behavior in inference. "We adapt few-shot prompts from prior work, making minimal modifications to fit each method's format while keeping the number of examples consistent."
- hierarchical planning: Planning that organizes tasks across multiple abstraction levels with sub-goals and decompositions. "To address this, more sophisticated methods emerged, such as hierarchical planning frameworks~\citep{paranjape2023art,sun2024pearl} and dynamic re-planning methods~\citep{sun2023adaplanner,prasad2024adapt}, which continuously modify their plans based on environmental feedback."
- LLM-based agents: Autonomous agents powered by LLMs to reason and act in environments. "Achieving this adaptive intelligence is a primary goal for LLM-based agents~\citep{liu2025advances}, yet current frameworks fall short because they operate at fixed granularities."
- observation space: The set of all possible observations an agent can receive from the environment. "where is the state space, is the primitive action space, is the observation space, is the transition function, and is the reward function."
- Partially Observable Markov Decision Process: A decision process where the agent cannot fully observe the true state and must act under uncertainty. "All three environments are partially observable Markov decision processes where agents cannot fully infer the environment state from observations alone."
- plan-and-execute: A strategy that first produces a full plan and then executes it, often brittle in dynamic settings. "Early approaches often adopted a “plan-and-execute” strategy, where a complete natural language plan is generated upfront before any actions are taken~\citep{wang2023plan,yang2023intercode,kagaya2024rap,sun2024corex}."
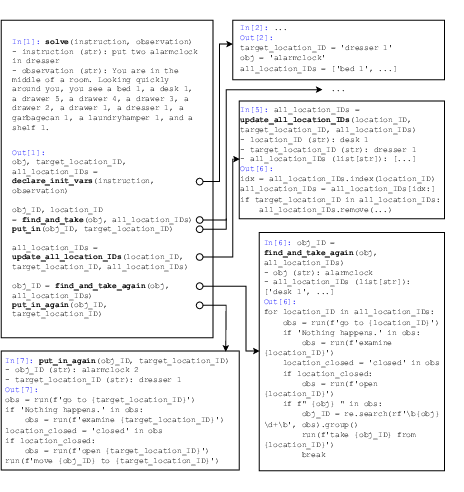
- policy model: The model that generates decisions (plans or actions) from the current context or placeholder node. "The agent's policy model then expands the current node into a child code block."
- primitive action: A low-level, directly executable operation in the environment. "When encountering a primitive action, the executor directly executes it in the environment."
- recursive code generation: A process where high-level placeholders are expanded into sub-functions until reaching executable primitives. "We introduce ReCode, an LLM-based agent paradigm with recursive code generation that achieves universal control of decision granularity."
- ReAct: A paradigm that interleaves reasoning with environment actions in a step-by-step loop. "Among these, paradigms like ReAct~\citep{yao2023react} are foundational, interleaving reasoning and primitive actions in a step-by-step loop."
- ReCode: The proposed paradigm that unifies planning and action within a single recursive code representation. "We propose ReCode (Recursive Code Generation), a novel paradigm that addresses this limitation by unifying planning and action within a single code representation."
- reward function: A mapping from state-action pairs to scalar rewards that guides behavior. " is the reward function."
- rule-based text-to-code: A heuristic conversion from task text to an initial placeholder function for code-based planning. "The task instruction is transformed into an initial placeholder function via a rule-based text-to-code method."
- ScienceWorld: A scientific laboratory environment for agents to perform experiments and instrument manipulations. "ScienceWorld~\citep{wang2022scienceworld} presents a scientific laboratory setting where agents conduct experiments and manipulate scientific instruments."
- state space: The set of all possible states of the environment. "where is the state space, is the primitive action space, is the observation space, is the transition function, and is the reward function."
- supervised fine-tuning (SFT): Training a model on labeled input-output pairs to align it with a target behavior. "we conduct supervised fine-tuning (SFT)~\citep{weifinetuned} experiments on ReCode, ReAct, and CodeAct to directly compare their learning efficiency."
- synthetic data generation: Creating artificial datasets or trajectories to improve agent training. "Much of the subsequent research has focused on optimizing this step-by-step loop, such as through synthetic data generation methods~\citep{zelikman2022star, yang2024react, wang2024learning} and novel training algorithms~\citep{song2024trial, qiao2024agent, du2024improving, lee2024rlaif, xia2025sand, xiong2025mpo, cao2025pgpo}."
- transition function: A mapping from a state and action to the next state in the environment. " is the transition function,"
- universal granularity control: The ability to flexibly operate across and unify different decision abstraction levels. "We propose ReCode, a novel agent paradigm that achieves universal granularity control by unifying plan and action within a single code representation."
- variable namespace: A shared set of named variables and their values maintained across recursive expansions and executions. "ReCode implements context management through a unified variable namespace that persists throughout task execution."
- WebShop: An online shopping environment where agents search, compare, and purchase items under constraints. "WebShop~\citep{yao2022webshop} simulates an online shopping scenario requiring agents to search, compare, and purchase products based on specific requirements."
- world models: Parameterized models that capture environment dynamics or knowledge to support planning and learning. "introducing parameterized world models for training on expert and synthetic trajectories."
- World Knowledge Model (WKM): A method that incorporates parameterized world models for agent planning and training. "WKM~\citep{qiao2024agent}, introducing parameterized world models for training on expert and synthetic trajectories."
Collections
Sign up for free to add this paper to one or more collections.