- The paper introduces ReCode, a novel RAG framework that integrates algorithm-aware retrieval with dual-view encoding to enhance automated code repair.
- Empirical results on RACodeBench demonstrate improved test pass rates and strict accuracy across various LLMs, outperforming traditional methods.
- The framework significantly reduces inference calls while maintaining robust in-distribution and out-of-distribution performance, ensuring scalable real-world deployment.
Fine-Grained Retrieval-Augmented Generation for Code Repair: The ReCode Framework
Introduction
The ReCode framework introduces a retrieval-augmented generation (RAG) paradigm for automated code repair, addressing the limitations of both training-intensive and inference-heavy approaches. By leveraging algorithm-aware retrieval and dual-view encoding, ReCode enhances the contextual relevance and precision of in-context exemplars, enabling efficient and accurate code repair without additional model fine-tuning. The framework is supported by RACodeBench, a benchmark constructed from real-world buggy code submissions, facilitating rigorous evaluation of repair methods under authentic conditions.
Limitations of Traditional Retrieval-Augmented Methods
Conventional RAG methods in code repair typically employ unified code-text embeddings, which fail to capture the structural and semantic intricacies of source code. This monolithic representation leads to suboptimal retrieval quality, as it inadequately models the fine-grained error semantics and structural variations inherent in programming languages. Empirical results demonstrate that replacing unified encoding with dual encoding—separately modeling textual and code modalities—yields consistent improvements in test pass rates across multiple LLMs.
The ReCode Framework
ReCode advances retrieval-augmented code repair through two principal innovations:
- Algorithm-Aware Retrieval: The framework first predicts the algorithmic categories relevant to the buggy code using LLM-based multi-label classification. This narrows the retrieval search space to algorithm-specific sub-knowledge bases, ensuring that retrieved exemplars are structurally and semantically aligned with the target problem.
- Dual-View Encoding: Textual descriptions and code snippets are independently encoded using specialized encoders (bge-m3 for text, OASIS-code-1.3B for code). The resulting representations are fused to form a discriminative vector, preserving modality-specific features and enabling fine-grained semantic matching.
The overall process is depicted in the following schematic:
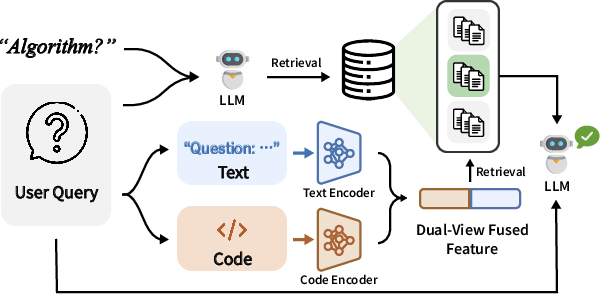
Figure 1: Overview of the ReCode method, illustrating algorithm type prediction, dual encoding, parallel semantic retrieval, and collaborative exemplar integration for in-context code repair.
Given a user query, ReCode decomposes the input, encodes each modality, predicts algorithmic labels, retrieves relevant exemplars from hierarchical knowledge bases, and constructs a semantically aligned in-context example set to guide the LLM in generating repairs.

Figure 2: Example workflow of ReCode, showing algorithm type determination, dual-view retrieval, and exemplar-based prompting for code repair.
Construction of RACodeBench and Knowledge Bases
RACodeBench is curated from Codeforces user submissions, comprising paired buggy and fixed code, annotated error types, and code-level diffs. The benchmark is stratified across algorithmic domains and difficulty levels, with rigorous partitioning to prevent data contamination between evaluation and retrieval sets. The knowledge base is hierarchically organized by algorithmic tags, enabling precise retrieval of error-specific exemplars.
Experimental Results
On RACodeBench, ReCode consistently outperforms best-of-N and self-repair baselines across all tested LLMs. For instance, with GPT-4o-mini and N=8 inference calls, ReCode achieves a test pass rate of 41.06% and strict accuracy of 30.41%, surpassing all baselines. The performance gain is amplified with larger models and is particularly pronounced for general-purpose LLMs lacking explicit code adaptation.
Out-of-Distribution Generalization
ReCode demonstrates robust generalization on six competitive programming datasets, consistently outperforming baselines in both test pass rate and strict accuracy metrics.
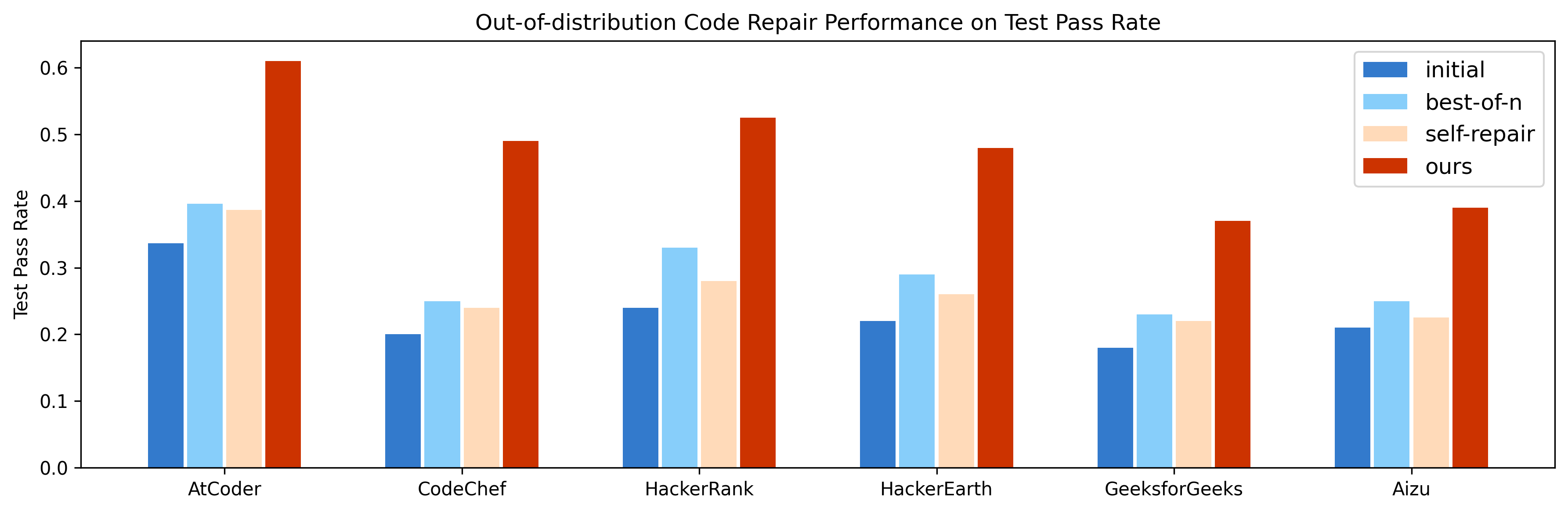
Figure 3: Test pass rates on out-of-distribution code repair, showing ReCode's superior generalization across multiple datasets.
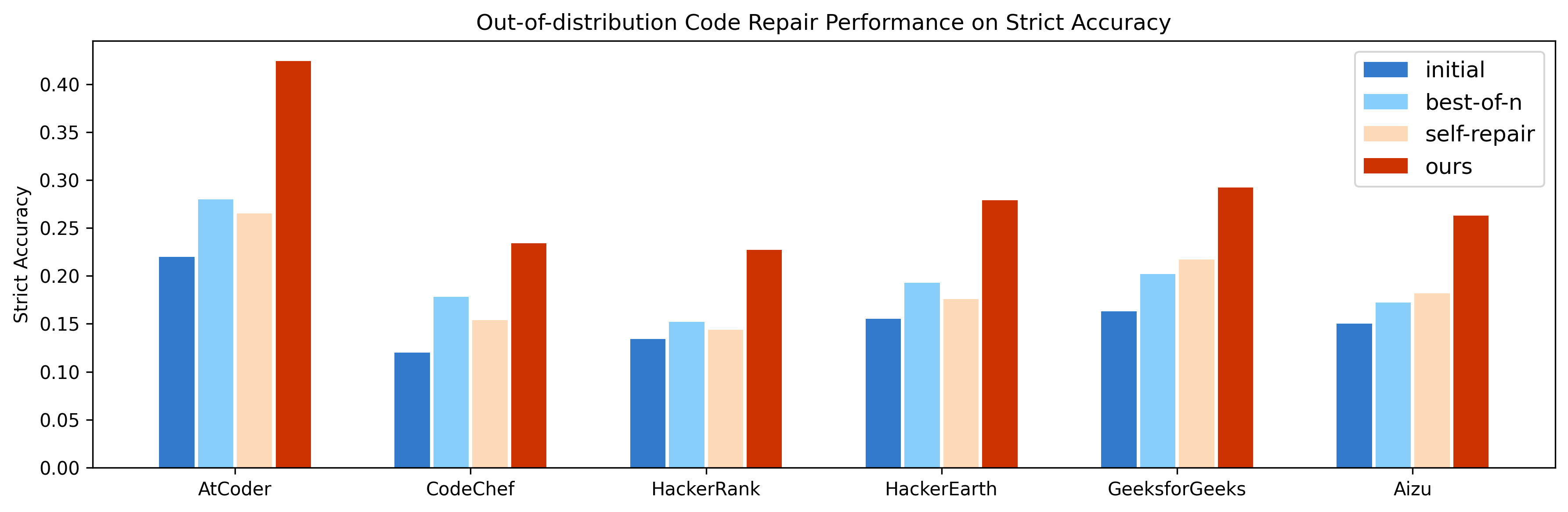
Figure 4: Strict accuracy on out-of-distribution code repair, highlighting ReCode's ability to generate fully correct solutions.
Impact of Example Selection
Ablation studies confirm that relevance-driven exemplar selection is critical. Random sampling yields marginal improvements, while algorithmically aligned retrieval enables rapid convergence to high performance under limited inference budgets.
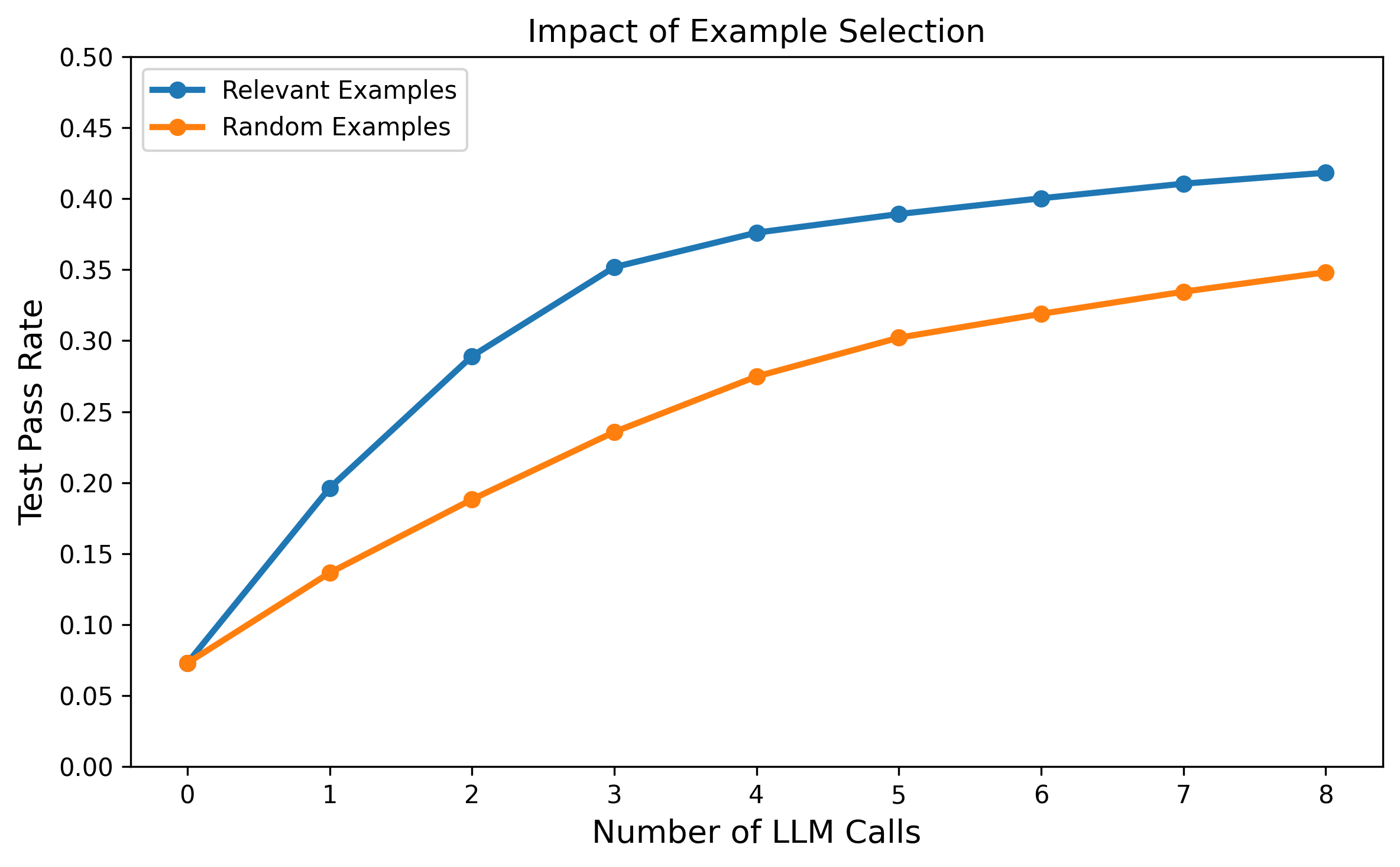
Figure 5: Example selection impact, demonstrating the advantage of relevant exemplars under constrained LLM call budgets.
Inference Cost Analysis
ReCode achieves comparable or superior repair accuracy with significantly reduced inference cost. For example, on AtCoder, ReCode requires only 4 LLM calls to reach a 35% test pass rate, compared to 11 and 15 calls for best-of-N and self-repair, respectively.
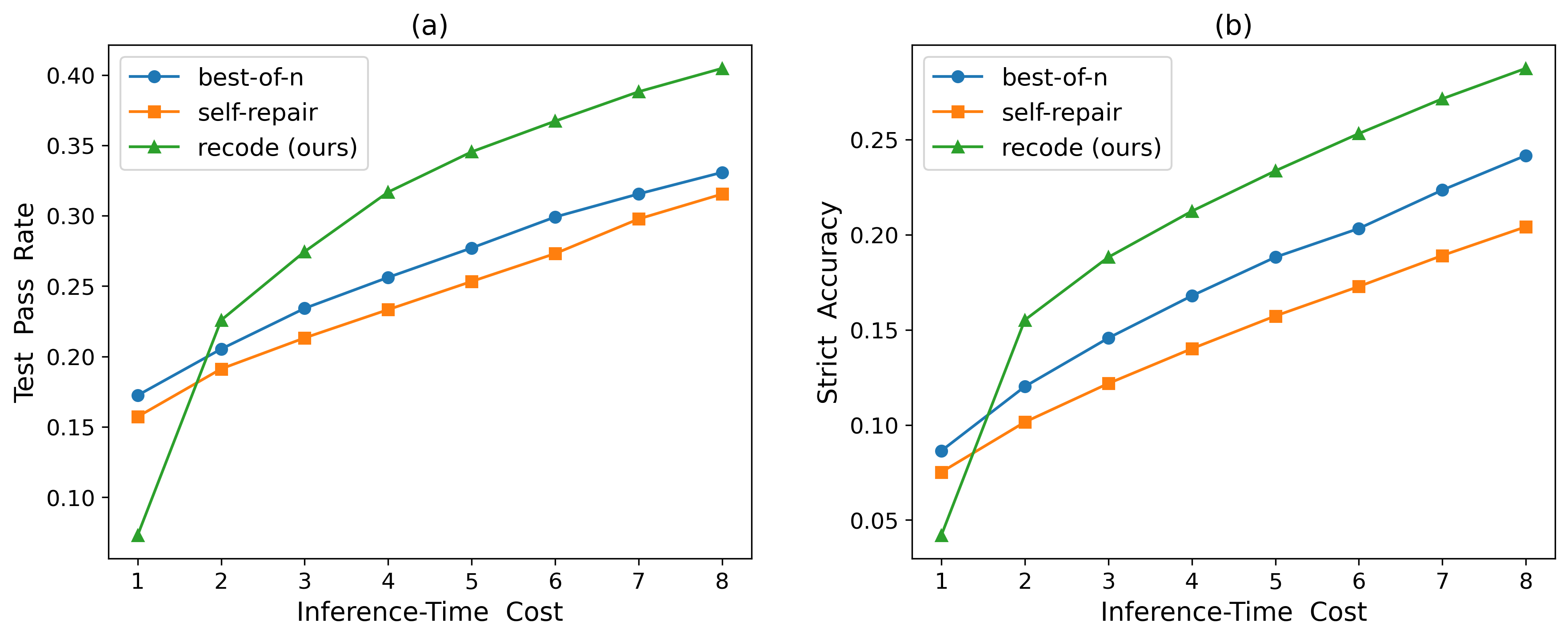
Figure 6: Comparative analysis of repair performance and inference efficiency under in-distribution settings.
Qualitative Results
Case studies illustrate ReCode's ability to transfer algorithmic logic from retrieved exemplars, yielding semantically correct and stylistically consistent repairs.
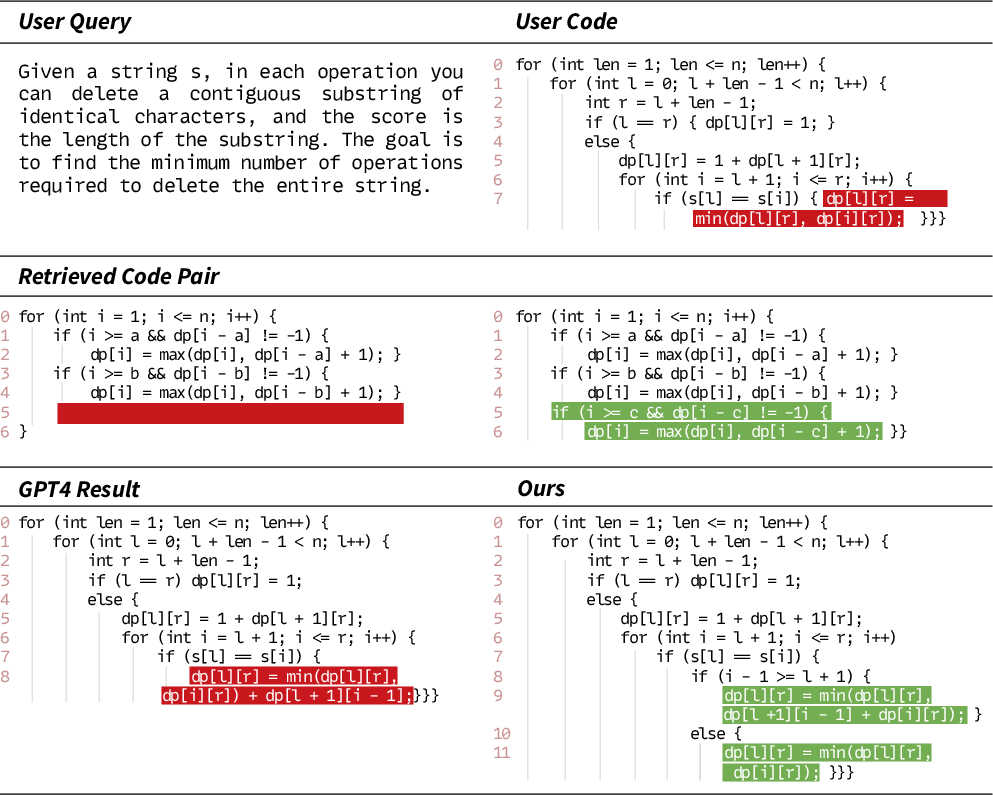
Figure 7: Qualitative results on RACodeBench, showcasing exemplar-guided code repair.
Implementation Considerations
- Retrieval Infrastructure: Efficient indexing and retrieval from hierarchical, algorithm-tagged knowledge bases are essential. Dual encoders should be pre-trained and optimized for code and text modalities.
- LLM Integration: The framework is model-agnostic and can be deployed with both open-source and closed-source LLMs. Inference-time budgets should be allocated for algorithm classification and exemplar retrieval.
- Scalability: The modular design supports scaling to large knowledge bases and diverse programming domains. Inference efficiency enables practical deployment in real-world automated code repair systems.
Implications and Future Directions
ReCode demonstrates that fine-grained, algorithm-aware retrieval substantially enhances LLM-based code repair, both in accuracy and efficiency. The framework's modularity and reliance on in-context learning obviate the need for costly retraining, facilitating rapid adaptation to novel bug patterns and domains. Future research may explore dynamic knowledge base expansion, integration with execution-based feedback, and extension to multi-language or cross-domain code repair scenarios.
Conclusion
ReCode establishes a new paradigm for retrieval-augmented code repair, leveraging dual-view encoding and algorithm-aware retrieval to deliver accurate, efficient, and generalizable repairs. The framework's empirical superiority and practical efficiency position it as a scalable solution for real-world automated code repair, with broad implications for the integration of retrieval mechanisms in LLM-driven program synthesis and debugging.