- The paper presents two advanced variants, MHRoPE and MRoPE-I, that significantly enhance positional representation in vision-language tasks.
- It provides a formal derivation of the attention score’s upper bound, offering insights into long-range decay properties inherent in self-attention mechanisms.
- The study demonstrates that MRoPE-I delivers stable extrapolation performance at extended context lengths, making it practical for video and scalable vision-language applications.
Revisiting Multimodal Positional Encoding in Vision-LLMs
Introduction
The paper "Revisiting Multimodal Positional Encoding in Vision-LLMs" investigates improvements and trade-offs related to multimodal positional encoding techniques within vision-LLMs. Positional encoding is vital for modeling sequential data efficiently, accommodating tasks that span modalities like vision and language. The research focuses on two variants: Multimodal High-RoPE (MHRoPE) and Multimodal RoPE-Interleaved (MRoPE-I), evaluating their efficacy in various settings and highlighting specific advantages of each approach.
Positional Encoding Techniques
The study proposes two positional encoding methods, MHRoPE and MRoPE-I, with particular emphasis on MRoPE-I due to its simplicity and slight performance gains. MHRoPE involves partitioning at the head-level, impacting the integration within the self-attention mechanism, while MRoPE-I adopts a more streamlined approach with an interleaved design. This design choice aids compatibility with extrapolation algorithms like NTK-aware and YaRN, facilitating a more efficient extension of context length without compromising performance integrity.
Derivation and Analysis
The paper includes a formal derivation of the upper bound of the attention score in the context of RoPE. The expression for bounding involves the content and position-dependent terms, leading to insights about the long-range decay property of the attention mechanism. These theoretical underpinnings offer a robust foundation for understanding the behavior of the proposed positional encoding methods under varying conditions.
Video Extrapolation and Long-Context Understanding
An evaluation on long-context video understanding highlights the performance differences between various positional encoding methods at increased context lengths: 32K, 64K, 128K, and 256K (Figure 1). The authors report a sharp decline in performance specifically with Vanilla RoPE, attributed to rapidly growing positional IDs. Conversely, MRoPE-I and MHRoPE exhibit more stable extrapolation capabilities, which are essential for tasks exceeding typical context limitations encountered in practical applications.
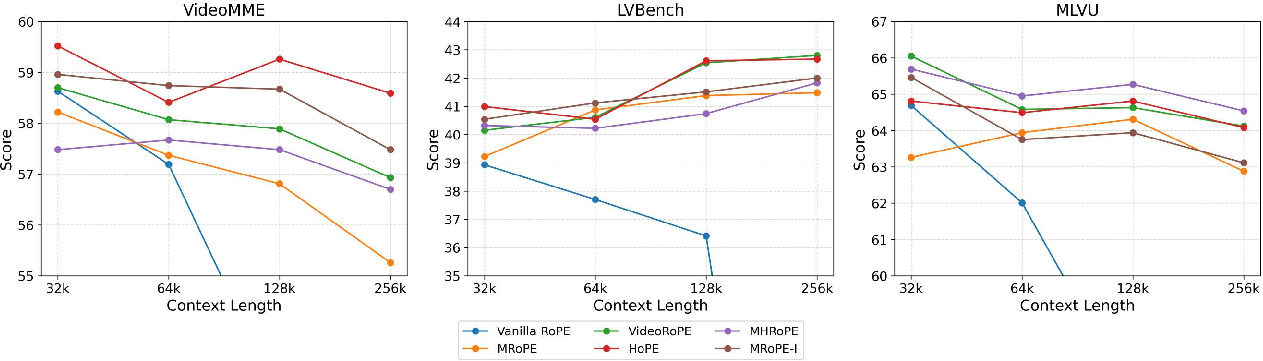
Figure 1: Video extrapolation performance. Models are trained with a context length of 32k (256 frames) and extrapolated to 64k (512 frames), 128k (1024 frames), and 256k (2048 frames).
Practical Implications and Future Work
The paper emphasizes the significance of choosing between MHRoPE and MRoPE-I based on the trade-offs of computational complexity and extrapolation capability. The MRoPE-I method, recommended for its ease of implementation and consistent performance, is well-suited for scenarios requiring efficient handling of expansive positional contexts. The authors foresee the potential for further scaling and adaptation in more complex environments, especially where the number of positional axes could meaningfully increase.
The research also explores detailed ablation studies examining various configurations of the position encoding strategies across image, video, and grounding tasks. These analyses reiterate MRoPE-I's balanced performance and shed light on optimization avenues, such as allocation ratios and temporal strides, which substantially influence the model's adaptability and accuracy.
Conclusion
The paper provides a meticulous exploration of multimodal positional encoding strategies, meticulously iterating on design and performance considerations. With promising empirical results, MRoPE-I offers a compelling configuration of positional encoding for vision-LLMs across diverse task landscapes. Future directions are likely to focus on scalability and integration within more intricate systems, promising advancements in the effectiveness of cross-modal processing tasks.

