- The paper introduces a novel decentralized control framework for robotic swarms inspired by ant walling, using FSM for structured interactions.
- It integrates a deep reinforcement learning component with FSM logic to dynamically reduce mixing by up to 50% and improve convergence speed.
- Simulations demonstrate that the RL-enhanced controller adapts quickly to diverse configurations, achieving superior separation and coverage efficiency.
Ant-inspired Walling Strategies for Scalable Swarm Separation: Reinforcement Learning Approaches Based on Finite State Machines
Introduction
The paper introduces novel decentralized controllers for heterogeneous robotic swarms inspired by the spatial segregation behavior observed in army ants. These controllers are designed to maintain spatial separation in robotic swarms through emergent structures, permitting concurrent execution of tasks without interference. The first approach utilizes a finite-state machine (FSM) based controller, which showcases rigid and stable wall formations triggered by local encounters. The second approach integrates FSM states with a Deep Q-Network (DQN), allowing for adaptive formation of demilitarized zones. The DQN-enhanced controller improves adaptability, achieving a reduction in mixing by 40-50% along with faster convergence.

Figure 1: Illustration of example ``dissipative infrastructures'' that enforce self-organized separation in collectives similar to army ant behavior.
Robot Controllers
Finite State Machine (FSM) Controller
The FSM controller is designed to reproduce ant walling behaviors using a structured state approach. It comprises a deterministic finite state machine defined by various states including Walling, Moving, and Avoid Non-Nestmate. Transitions between states are triggered by encounters of robots with other robots, either Nestmates or Non-Nestmates, as well as by a set walling timer.
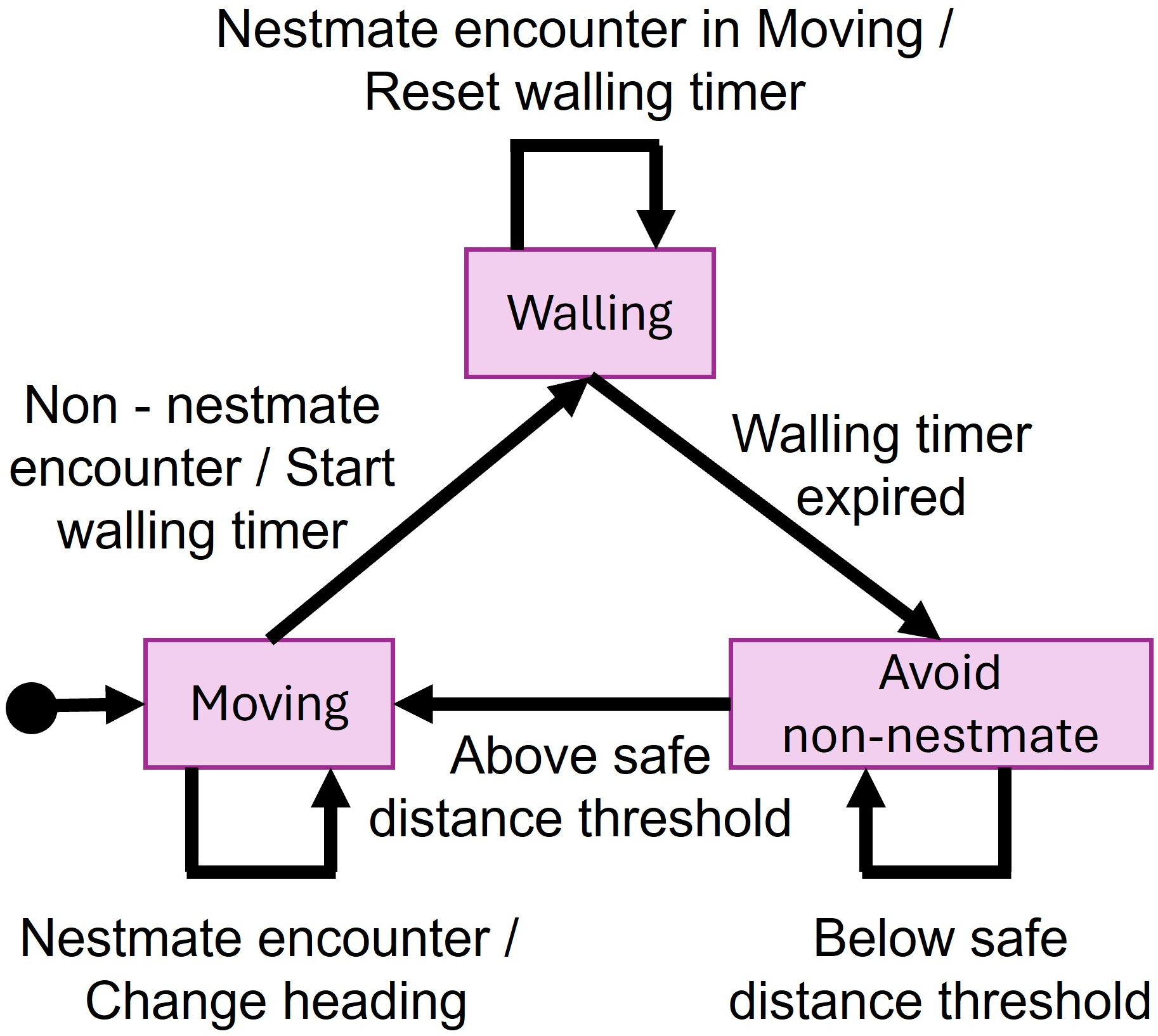
Figure 2: Finite state machine (FSM)-based robot controller.
Upon encountering a Non-Nestmate, the FSM transitions the robot into a Walling state, enforcing stationary behavior and activating a walling timer. The system resumes movement upon timer expiration or adequate separation from Non-Nestmates, ensuring the separation of robot subgroups.
Reinforcement Learning (RL) Controller
The RL controller leverages a hybrid framework combining FSM with deep reinforcement learning for enhanced decision-making and adaptability. By integrating sensor inputs such as UWB distance measurements and AoA data, the architecture efficiently processes variable-sized input through an attention mechanism to dynamically adapt navigation actions.
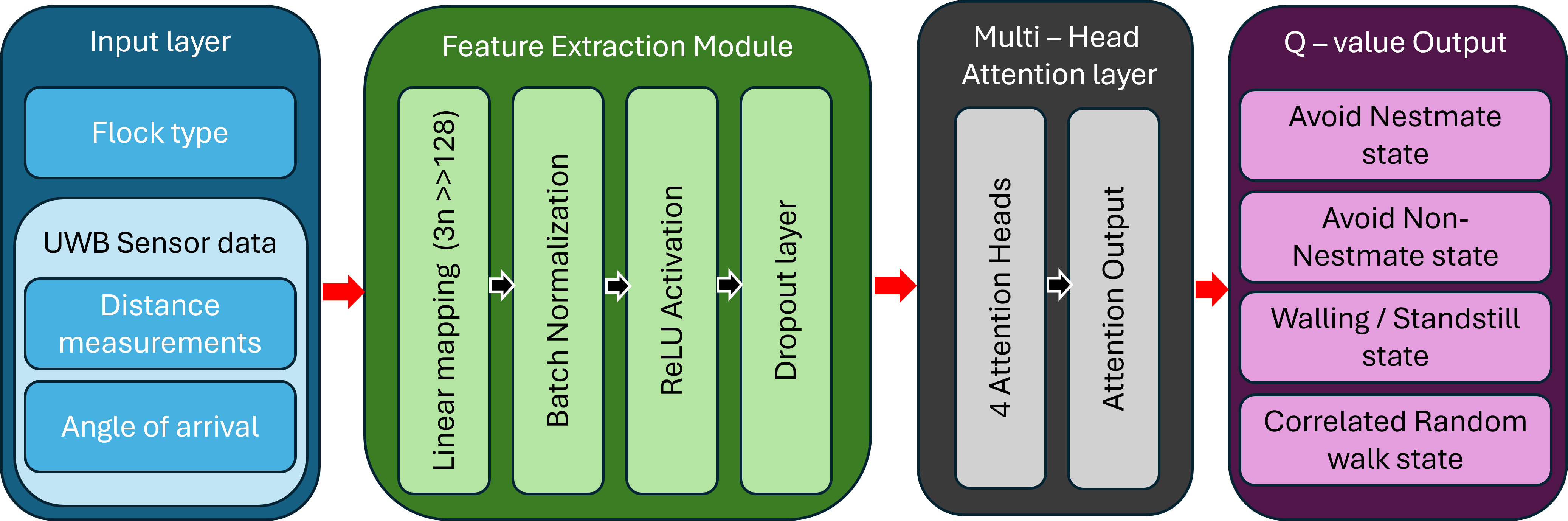
Figure 3: RL-based navigation system architecture facilitating swarm coordination and spatial separation.
During training, the RL controller employs CTDE paradigms to learn optimal behavioral switching and positioning strategies, balancing exploration and stability while penalizing excessive proximity, ensuring efficient swarm separation and coverage.
Simulation Environment and Results
Simulation Environment
The simulations conducted in a custom environment enabled analysis of the controllers' effectiveness in real-world scenarios. Models were developed to test separation efficiency, coverage, and mixing ratios across various initial spatial configurations. Additive noise was incorporated to simulate sensor uncertainty, enabling evaluations of robustness.
Results Analysis
The SM controller exhibited stable wall formations, ensuring separation but resulting in rigidity and slower convergence in dynamic environments. The RL controller, however, showcased adaptive behaviors, efficiently disentangling swarms and optimizing coverage while reducing mixing ratios significantly.
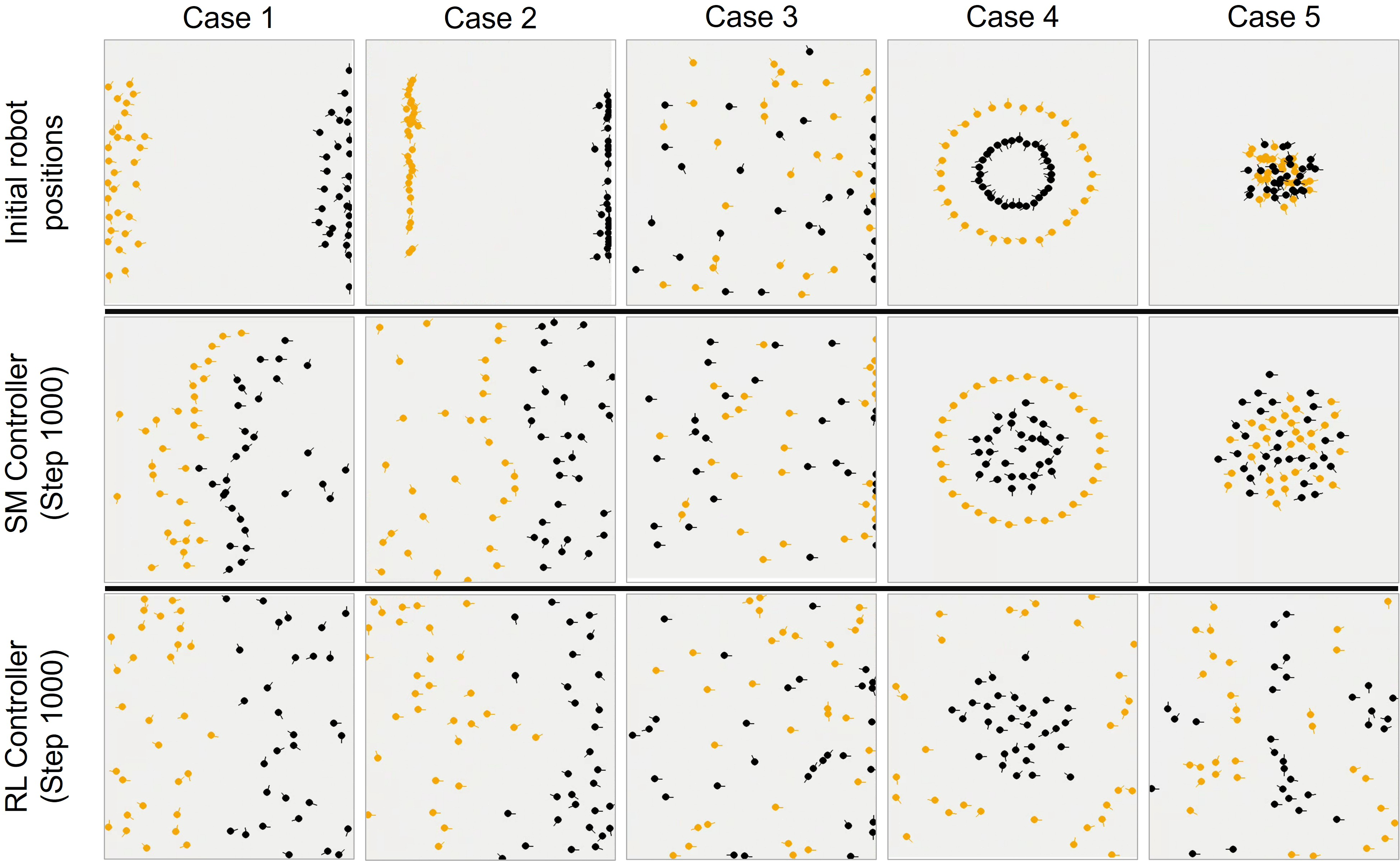
Figure 4: Initial and final robot positions under varying conditions indicating the dynamic adaptability and coverage efficiency of controllers.
The figures demonstrate that the RL controller adapts quickly across differing initial configurations, achieving faster separation and broader coverage compared to the FSM approach. The addition of walling timers further improved proportional coverage distribution.
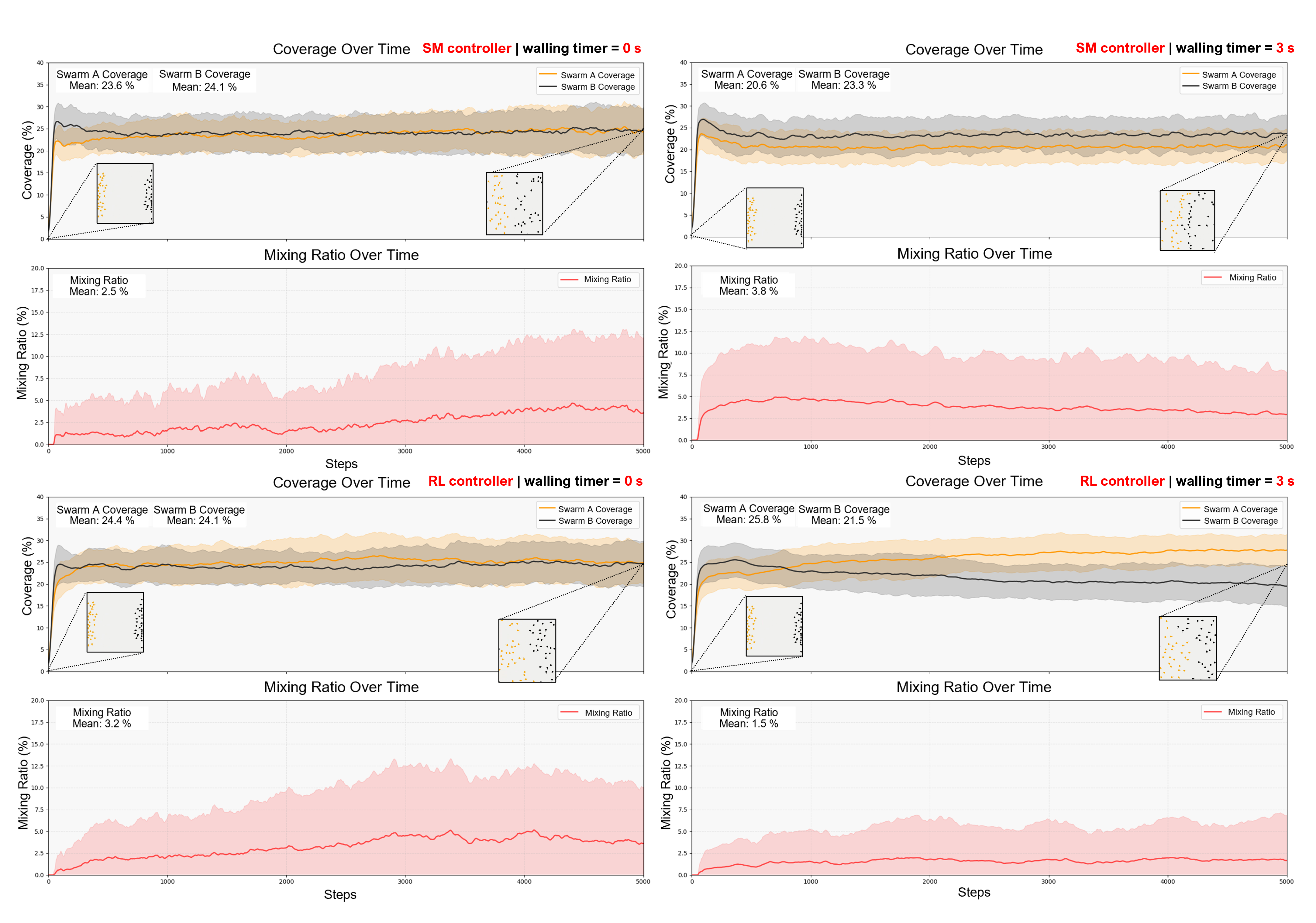
Figure 5: Case studies highlighting coverage and mixing ratios over time, showing the superior performance of the RL controller.
Conclusion
This research successfully synthesized principles from natural systems into scalable strategies for swarm robotics, achieving significant improvements in decentralized swarm coordination through reinforcement learning enhanced FSM architectures. The RL-enhanced controller presents a practical, scalable, and adaptable solution for autonomous swarm behaviors, maintaining structured interactions without the complexity of full deep RL models.
Future work aims to incorporate multi-agent communication and role differentiation among swarm robots, testing these paradigms on physical platforms to further validate and refine the approach. The combination of structured FSM logic with adaptive RL mechanisms offers new avenues for efficient decentralized control in swarm robotics, ensuring self-organized behaviors with minimal complexity.

