- The paper presents ReCoDe, a novel approach that fuses MARL with constraint-based optimization to learn adaptive, situation-specific constraints for coordination.
- It employs Graph Neural Networks to aggregate local information, dynamically adjusting parameters like uncertainty radius for precise trajectory tracking.
- Experimental results across navigation and consensus tasks demonstrate that ReCoDe outperforms handcrafted controllers and standard MARL in reward and efficiency, even under real-world conditions.
ReCoDe: Reinforcement Learning-based Dynamic Constraint Design for Multi-Agent Coordination
Introduction to the Paper
This essay analyzes the research presented in "ReCoDe: Reinforcement Learning-based Dynamic Constraint Design for Multi-Agent Coordination," highlighting the innovative approach of merging optimization-based controllers with multi-agent reinforcement learning (MARL). The paper addresses the limitations of handcrafted constraints in complex multi-agent settings and proposes ReCoDe, a decentralized hybrid framework aimed at improving coordination among autonomous agents.
Methodology: Integration of MARL and Optimization
ReCoDe integrates the reliability of constraint-based optimization with the adaptability of MARL by learning dynamic, situation-dependent constraints through local communication. It augments existing expert controllers by introducing context-specific constraints that enhance multi-agent coordination without sacrificing safety guarantees.
An overview of ReCoDe is depicted with figures that illustrate the method's operational structure, showcasing its integration with Graph Neural Networks (GNNs) for local information aggregation and decision-making.
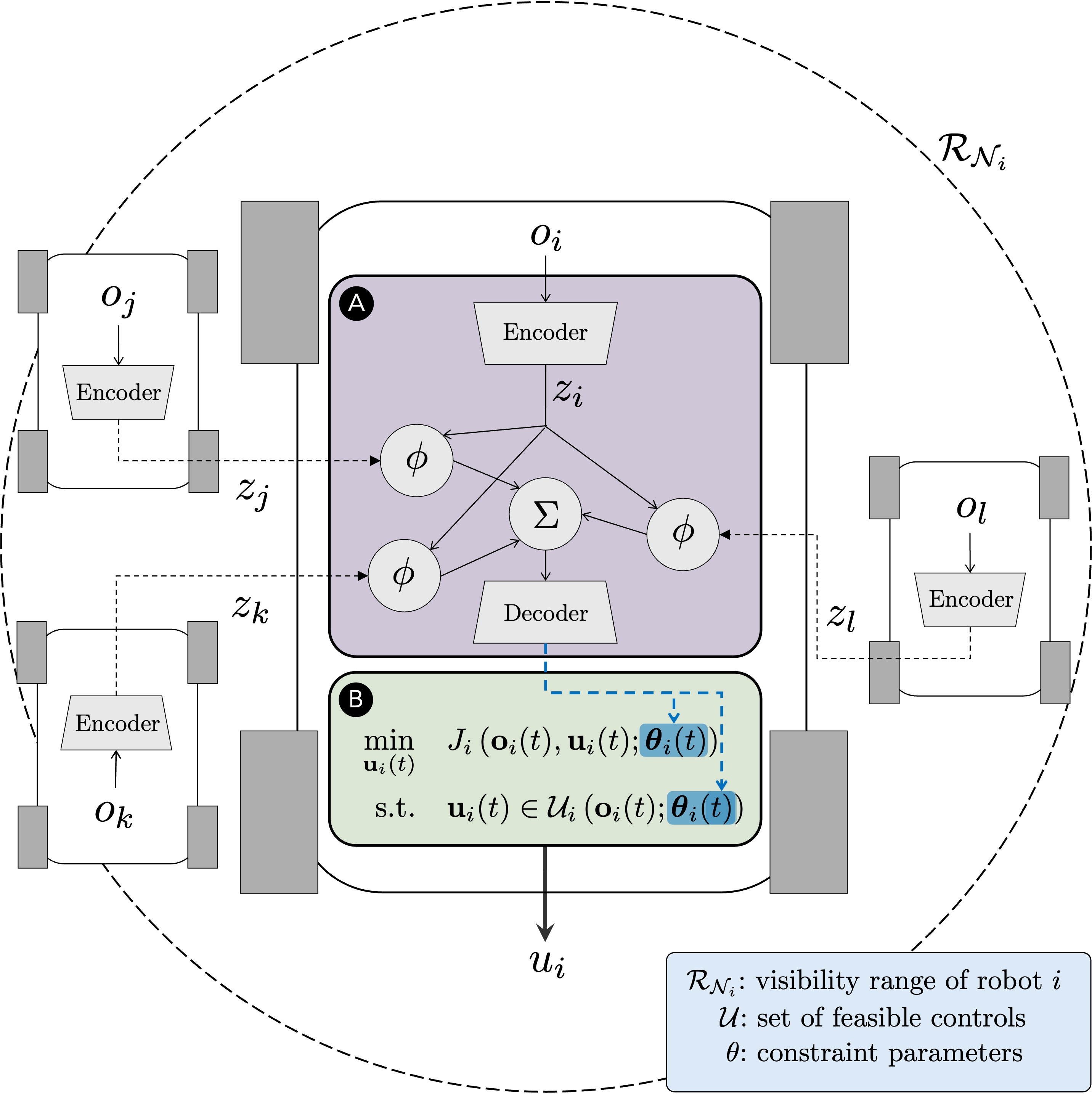

Figure 1: An overview of the proposed ReCoDe method, emphasizing the GNN-based policy to aggregate observations and generate dynamic constraints.
Experimental Design and Results
The paper tests ReCoDe across various navigation and consensus tasks, such as Narrow Corridor, Connectivity, Waypoint Navigation, and Sensor Coverage scenarios. These experiments are designed to highlight coordination challenges where safe regions are scarce or coordination is needed to prevent deadlocks.
ReCoDe's results demonstrate superior performance compared to both handcrafted controllers and general MARL approaches, with significant increases in reward and efficiency in sample usage.
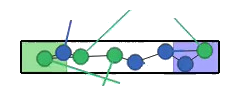
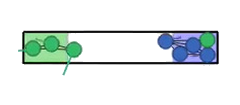
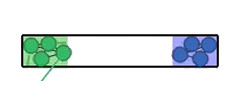
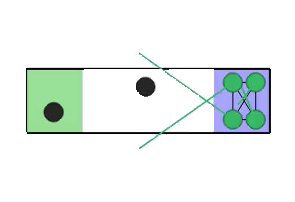
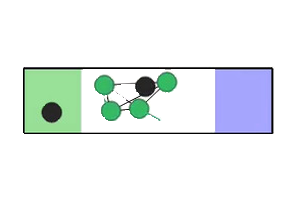
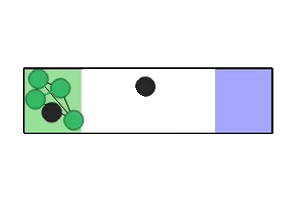
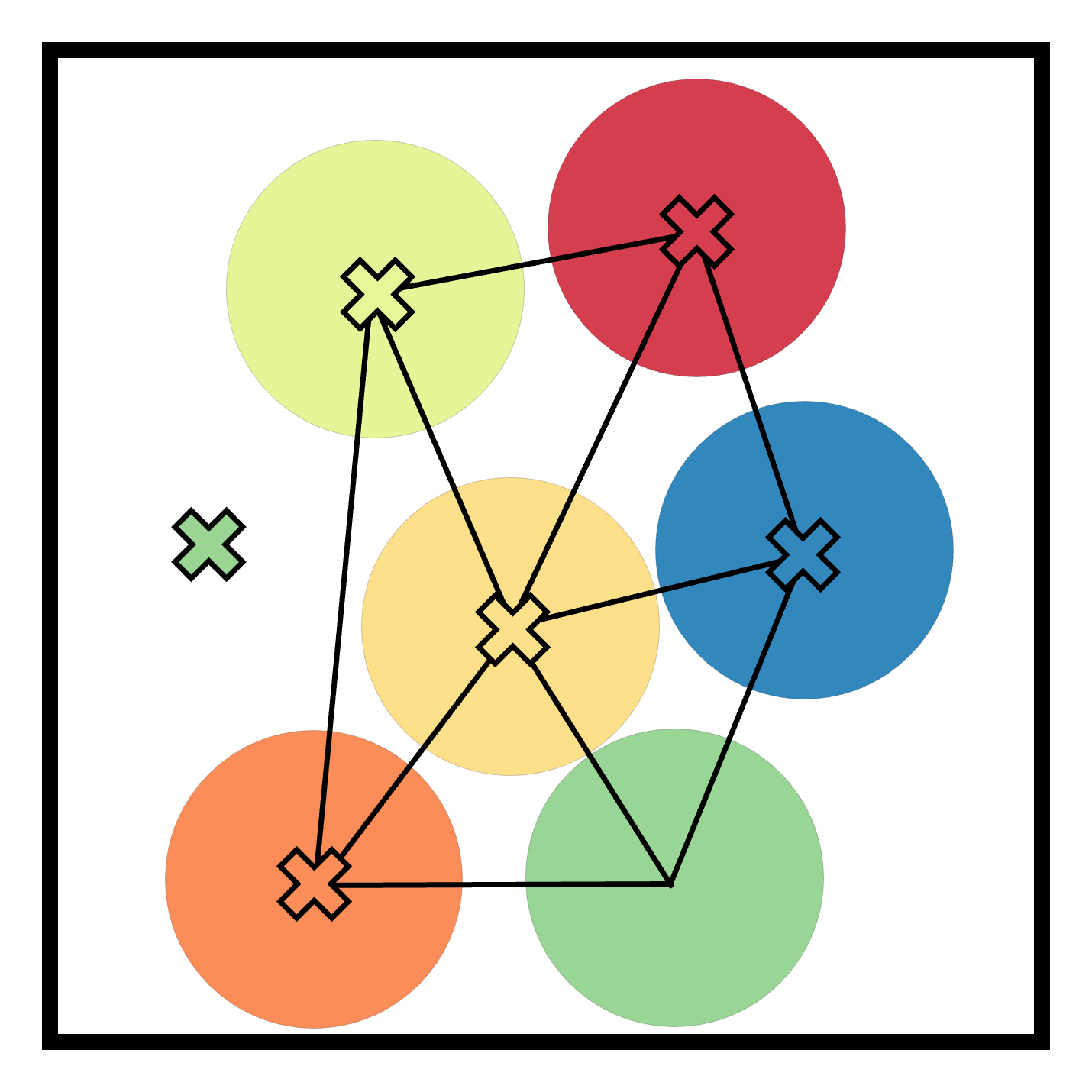
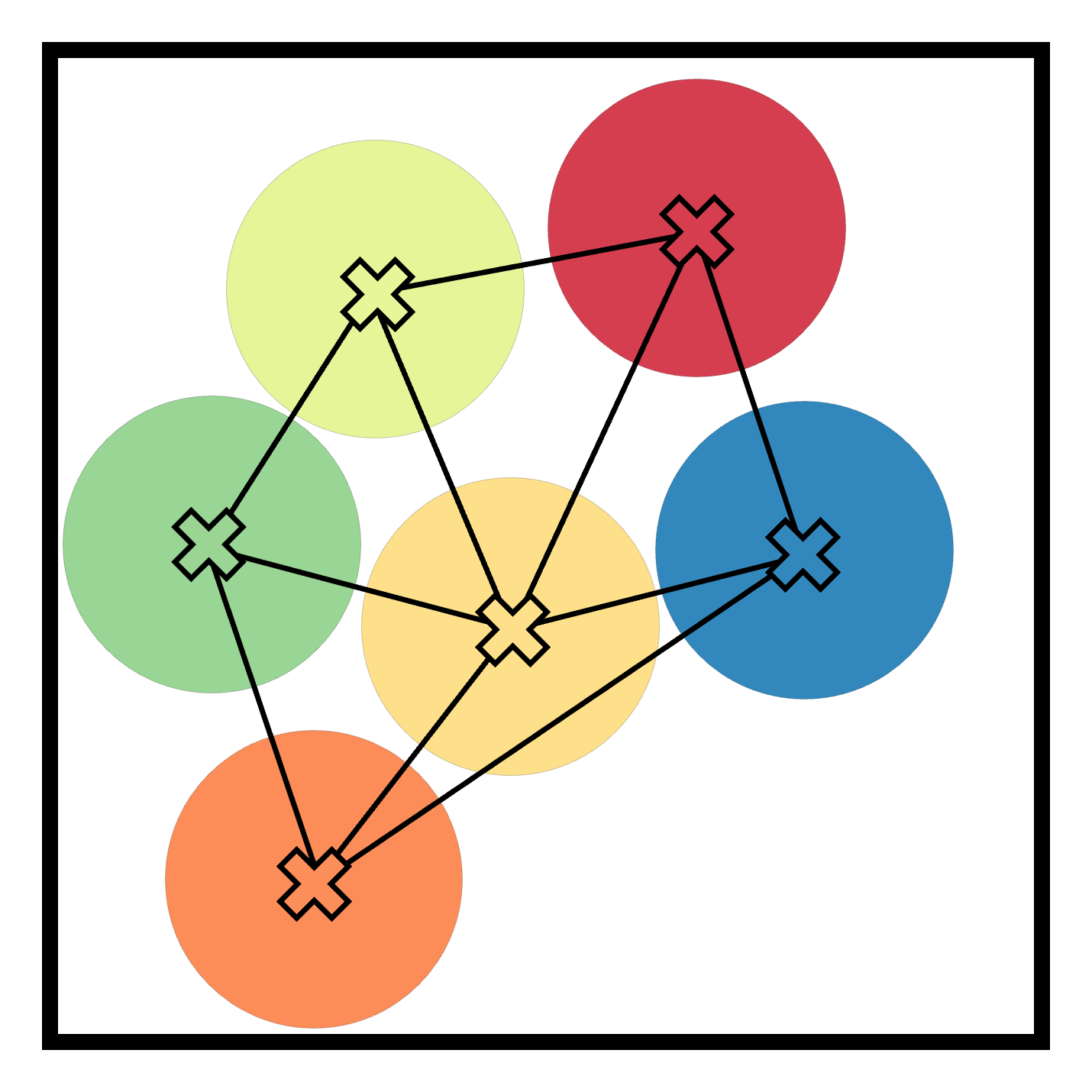
Figure 2: Experimental scenarios and results, illustrating initial conditions and scenarios requiring coordination, where ReCoDe demonstrates enhanced performance.
Further analysis probes ReCoDe's ability to adjust its constraint parameters, such as the uncertainty radius, based on environmental contexts. This dynamic adjustment helps strike a balance between learned policies and expert objectives, mitigating uncertainty and improving performance.
Analysis of the Learning Mechanism
The paper applies theoretical propositions to validate ReCoDe's adaptability and optimization balance. Proposition \ref{thm:trajectory_tracking} shows that ReCoDe can achieve precise trajectory tracking by appropriately adjusting constraint parameters. Meanwhile, Proposition \ref{thm:uncertaintyestimate} indicates the advantages of mixing learned policies with expert control, resulting in improved agent performance when opening the uncertainty radius.
Key figures confirm empirical learning adaptations, such as narrowing the uncertainty radius during high interaction states and widening it when paths are clear, synchronizing with the paper's theoretical analysis.
Real-World Deployment
ReCoDe is evaluated on physical robots in a narrow corridor environment, reinforcing the method's robustness in real-world settings. The robot demonstration corroborates ReCoDe's efficacy in resolving deadlocks through adaptive constraint learning, even amidst sensor noise and communication delays.
Conclusion
ReCoDe presents a competent solution for multi-agent coordination challenges by merging MARL with traditional constraint-based optimization. Its ability to dynamically adjust constraints demonstrates an effective hybrid approach, offering enhanced coordination capabilities while retaining safety assurances. Future work may explore ReCoDe’s application in non-navigation domains and scalability to larger systems, potentially broadening its implementation scope within the field of autonomous agent coordination.

