CANDI: Hybrid Discrete-Continuous Diffusion Models (2510.22510v2)
Abstract: While continuous diffusion has shown remarkable success in continuous domains such as image generation, its direct application to discrete data has underperformed compared to purely discrete formulations. This gap is counterintuitive, given that continuous diffusion learns score functions that enable joint evolution across multiple positions. To understand this gap, we introduce token identifiability as an analytical framework for understanding how Gaussian noise corrupts discrete data through two mechanisms: discrete identity corruption and continuous rank degradation. We reveal that these mechanisms scale differently with vocabulary size, creating a temporal dissonance: at noise levels where discrete corruption preserves enough structure for conditional learning, continuous denoising is trivial; at noise levels where continuous denoising is meaningful, discrete corruption destroys nearly all conditional structure. To solve this, we propose CANDI (Continuous ANd DIscrete diffusion), a hybrid framework that decouples discrete and continuous corruption, enabling simultaneous learning of both conditional structure and continuous geometry. We empirically validate the temporal dissonance phenomenon and demonstrate that CANDI successfully avoids it. This unlocks the benefits of continuous diffusion for discrete spaces: on controlled generation, CANDI enables classifier-based guidance with off-the-shelf classifiers through simple gradient addition; on text generation, CANDI outperforms masked diffusion at low NFE, demonstrating the value of learning continuous gradients for discrete spaces. We include the code on the project page available here: https://patrickpynadath1.github.io/candi-lander

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
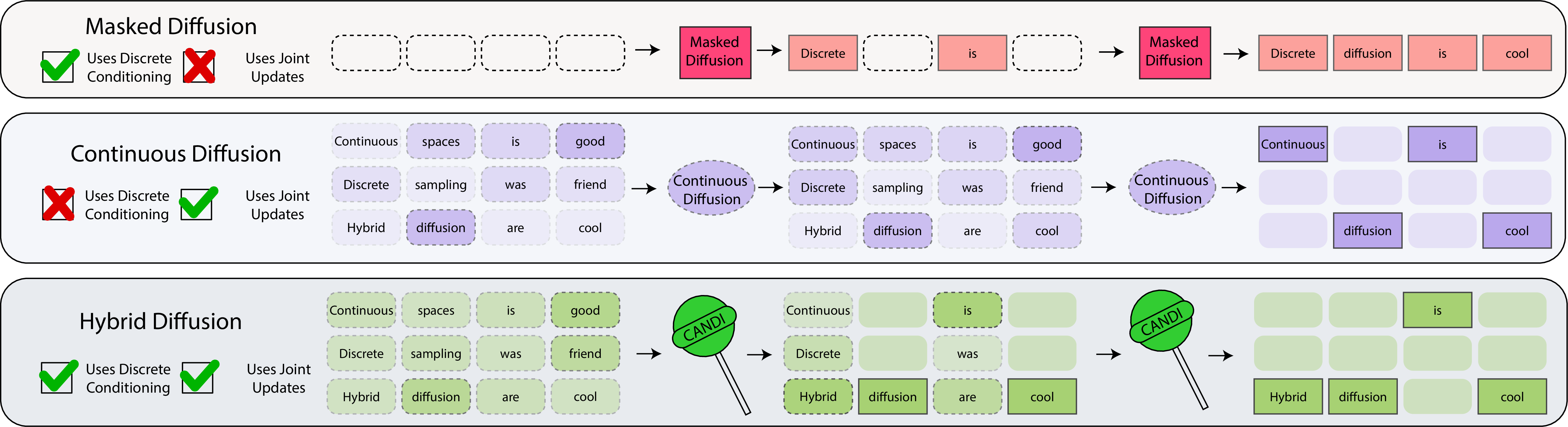
This paper is about making better AI systems that can create things like text or molecules. It focuses on “diffusion models,” a popular way to generate data by starting with noise and gradually turning it into something meaningful. The twist here is that the paper deals with discrete data (like words from a vocabulary), which has been tricky for standard diffusion methods that were originally built for continuous data (like pixels in an image). The authors introduce a new method called CANDI that combines both discrete and continuous diffusion so the model can learn the right structure of the data and also make smart, coordinated updates quickly.
Key Objectives
The paper asks a few simple questions:
- Why do continuous diffusion models (great for images) struggle when generating discrete things like words?
- What exactly goes wrong when we add “Gaussian noise” (a kind of random fuzz) to discrete data?
- Can we fix this problem so we get the benefits of both worlds: understanding the relationships between tokens (like words that go together) and making fast, coordinated changes across many positions at once?
- Does the new hybrid approach, CANDI, produce better and more controllable results, especially when we want high quality with few steps?
Methods and Ideas Explained Simply
Think of generating a sentence like rebuilding a blurred sentence into a clear one. Diffusion models do this by:
- Adding noise step by step (making things blurrier).
- Learning how to remove noise (making things clearer again).
For images (continuous data), this works very well because nearby pixels relate smoothly. But for text (discrete data), each position must pick one token from a vocabulary, and there isn’t smoothness between different tokens: “New” and “York” are related in meaning, but as tokens they’re totally different.
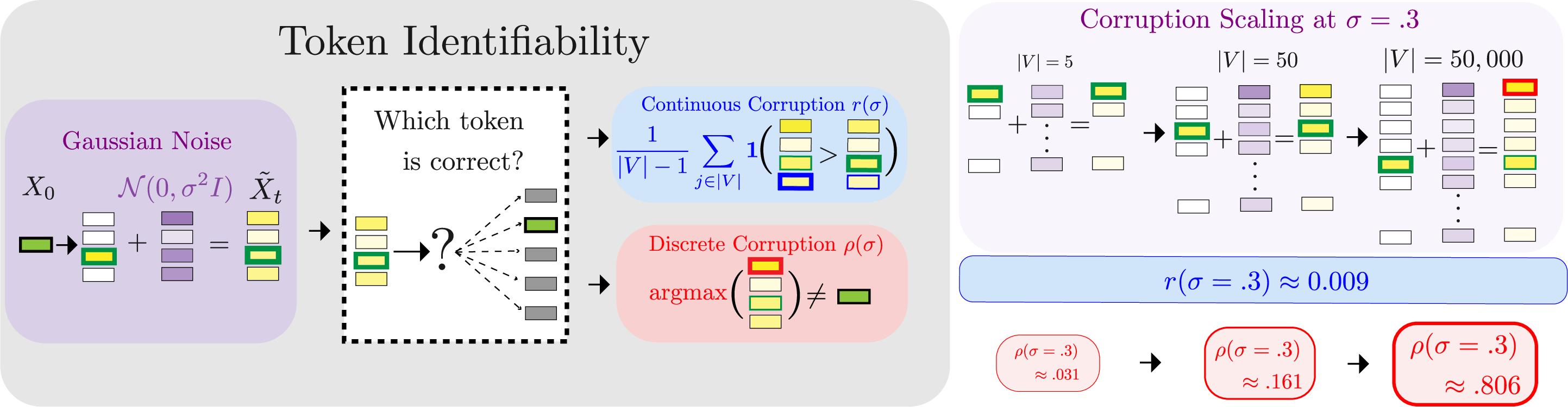
The authors introduce a simple lens to understand what noise does to discrete data: token identifiability—how easy it is to tell which token is the right one after noise is added. They break it into two parts:
- Discrete identity corruption: Does noise make the wrong token look like the best choice? Think of choosing the tallest bar on a chart; corruption is when the tallest bar is no longer the correct one.
- Continuous rank degradation: Even if the correct token is still the tallest, how much closer did other wrong tokens get? Think of a race: if the leader is still first but others closed the gap, the signal is weaker.
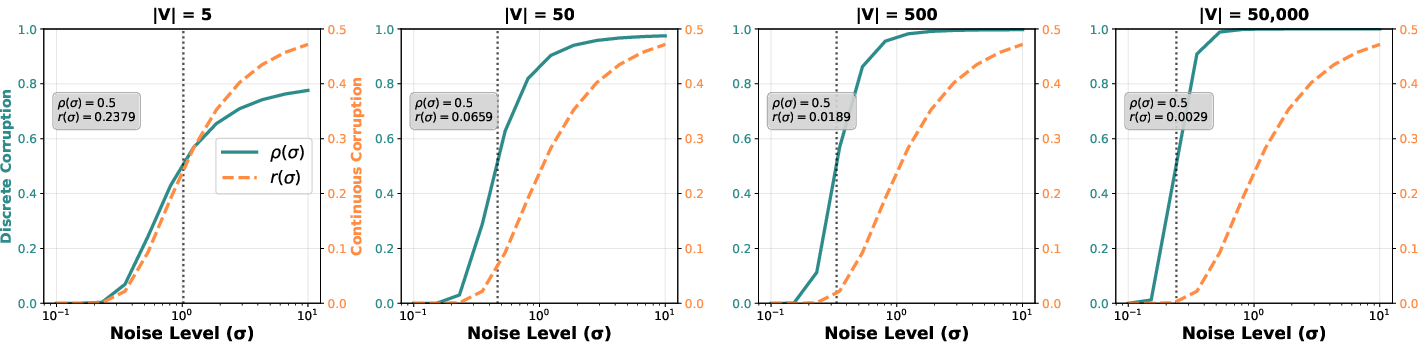
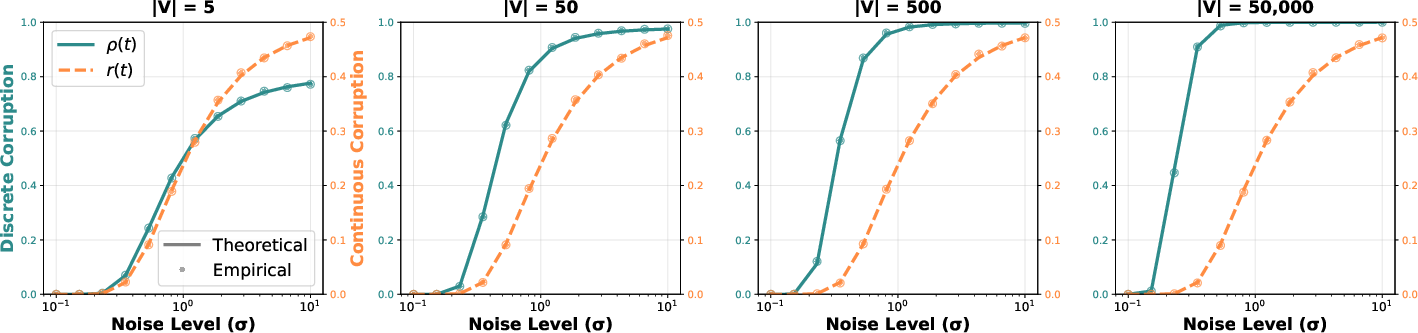
These two change at different speeds as the vocabulary gets bigger:
- Discrete identity corruption gets much worse with large vocabularies (many possible tokens). That means the model quickly loses reliable anchors—clean tokens it can condition on to learn relationships (like “New” often followed by “York”).
- Continuous rank degradation is mostly stable and doesn’t depend much on vocabulary size.
This mismatch creates what the authors call temporal dissonance: at noise levels where tokens are still identifiable (good for learning relationships), the continuous signal is too easy and teaches little. At noise levels where the continuous signal is challenging (good for learning useful gradients), the tokens are no longer identifiable and relationships break. So continuous diffusion can’t learn both parts at the same time.
CANDI fixes this with a hybrid approach:
- It masks some positions (keeps them clean, like leaving certain words readable) using a controlled schedule, so the model can learn conditional relationships.
- It adds Gaussian noise to other positions (blurring them) with a separate schedule tuned to keep continuous signals useful.
By decoupling these two kinds of corruption, CANDI keeps the balance: the model always has clean anchors to learn discrete structure and enough continuous noise to learn strong gradients that update multiple positions together.
There’s also a fast inference trick: instead of building huge one-hot vectors (a clunky representation of tokens), CANDI uses clever sampling and embedding lookups to get the benefits of continuous updates without heavy computation.
Main Findings and Why They Matter
The authors test their ideas on text and molecules and observe:
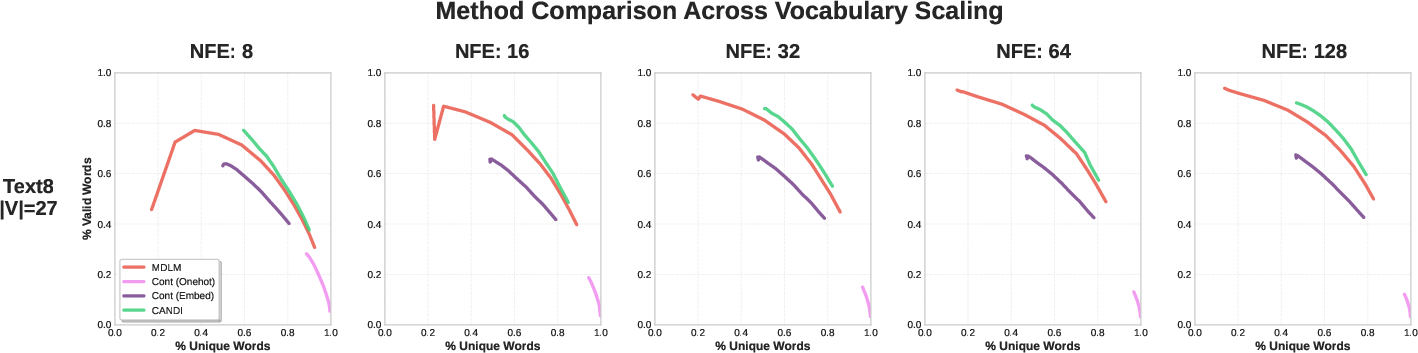
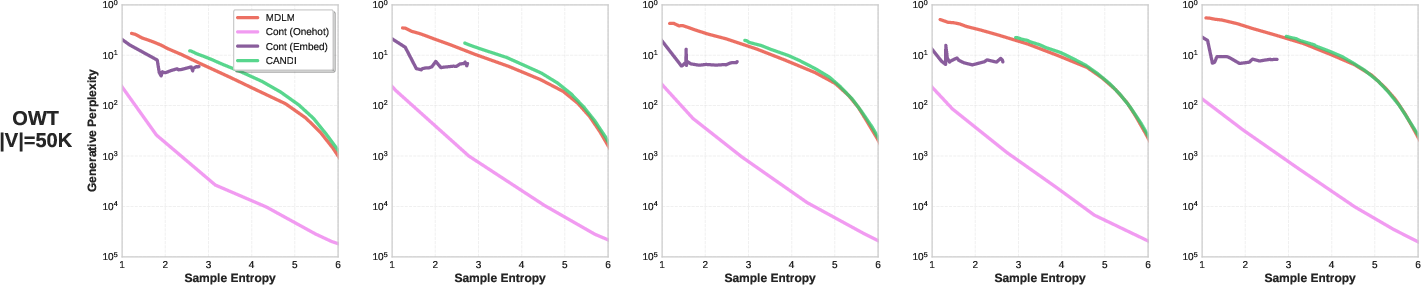
- Continuous diffusion alone works okay for small vocabularies (like character-level data) but fails badly for large vocabularies (like full tokenized text). This matches the “temporal dissonance” explanation: as vocab size grows, discrete corruption overwhelms learning of relationships.
- CANDI avoids that problem and performs well across both small and large vocabularies. It often matches or beats strong discrete-only baselines.
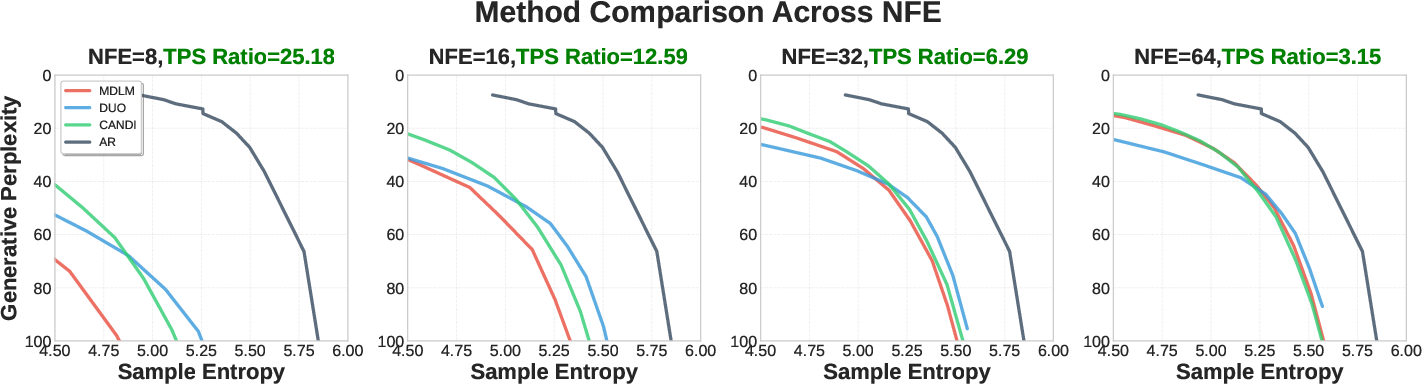
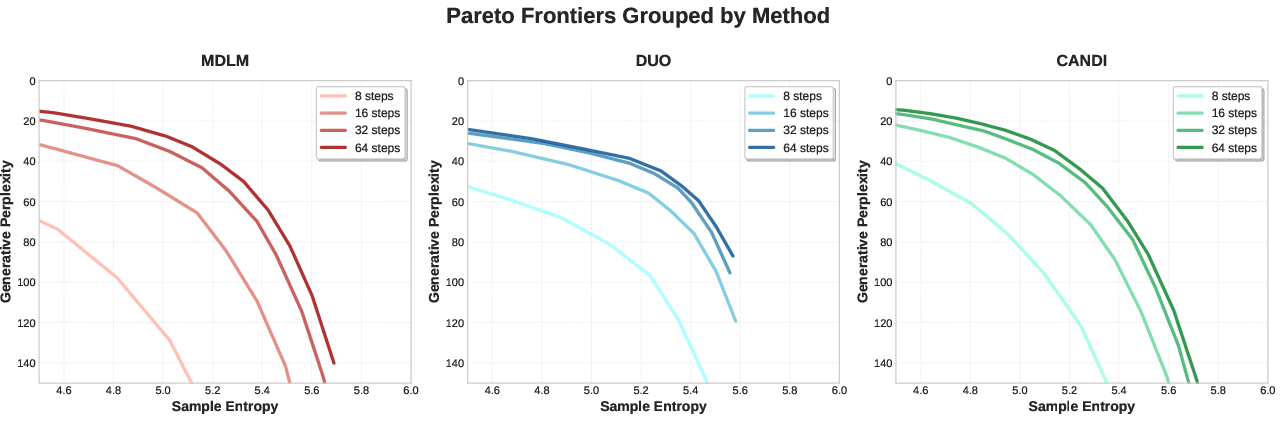
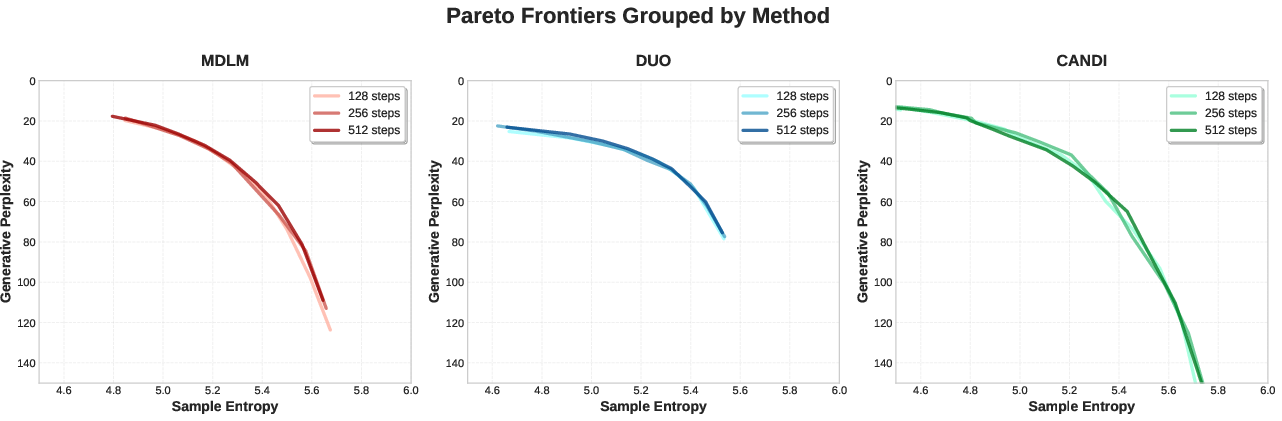
- At low NFE (number of function evaluations—think “few steps”), CANDI is especially strong. Because it learns continuous gradients, it can update many positions in a coordinated way, producing higher-quality text with fewer steps.
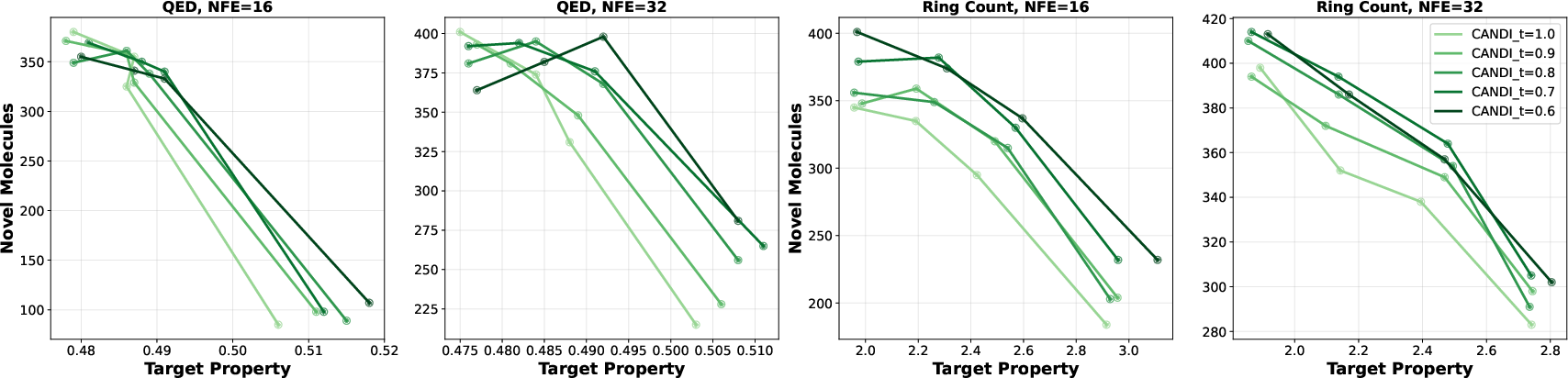
- CANDI enables simple, powerful guidance. You can plug in regular classifiers (no special training needed) and steer generation by adding their gradients. In tests on molecules (QM9), CANDI achieves competitive controlled generation, balancing diversity (unique valid molecules) with target properties (like QED or ring counts).
They also show a fair way to compare models by plotting full trade-off frontiers (curves of diversity vs. coherence across different temperatures). This avoids “single-temperature traps,” where tiny changes in a randomness dial flip which model looks best.
Implications and Impact
CANDI shows that we don’t have to choose between learning discrete relationships and using continuous gradients. By carefully separating and controlling how we add noise, we can get both:
- Better quality at low steps, which matters for speed and efficiency.
- Easier control with off-the-shelf classifiers, which matters for practical applications (like steering text or molecule generation).
- Stable performance even as vocabularies grow, which matters for real-world language tasks.
In short, the paper explains why continuous diffusion struggled on discrete data and offers a simple, effective fix. This hybrid idea could improve many generative systems that work with discrete items—words, symbols, actions, or atoms—making them faster, more controllable, and more reliable.
Knowledge Gaps
Below is a single, consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future work:
- Optimal coupling of discrete and continuous corruption: the choice of linear schedules for
ρ(t)andr*(t)is heuristic; what is the data/task-optimal relation between mask rateα(t)and continuous rank degradationr*(t)(including how to setr_min,r_max) and can it be learned adaptively during training? - Formal guarantees and consistency: the hybrid kernel’s reverse transition combines discrete and continuous branches, but there are no proofs of convergence, existence of a stationary distribution, or conditions under which the learned
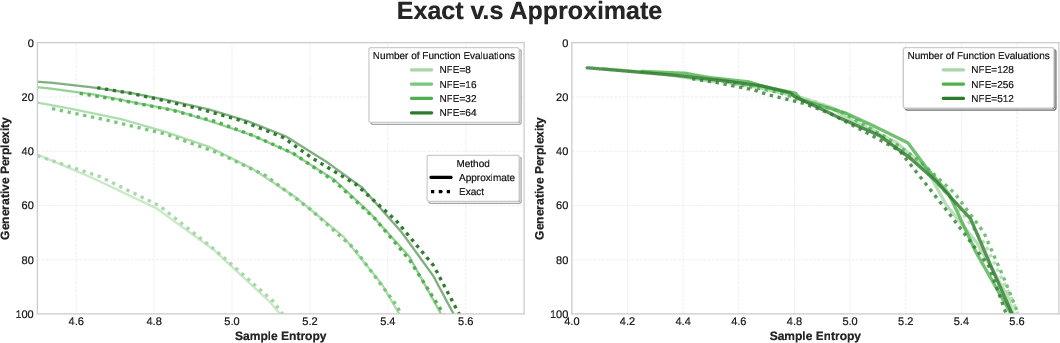
Pθ(X0 | Xt)plus probability flow ODE yields a consistent sampler for the intended target distribution. - Approximate inference fidelity: the Monte Carlo embedding-lookup approximation (to avoid materializing
|V|×L×Bone-hots) is not analyzed; what is the quantitative error vs. exact ODE integration, how many samples are needed, and how does the approximation bias affect sample quality and calibration? - Guidance mechanism soundness: guidance adds
∇ fφ(·)computed onOnehot(argmax(Xt))into the ODE update, but theargmax/one-hot mapping is non-differentiable; clarify the estimator used (e.g., straight-through, surrogate gradients), and paper stability, gradient leakage, mode collapse risks, and principled selection of the guidance weightw. - Generalization of guidance beyond molecules: the paper benchmarks controllable generation on QM9 with off-the-shelf classifiers; how does hybrid guidance perform on natural language controllability (attributes, style, toxicity, factuality), reward-model guidance, and multi-objective trade-offs?
- Sensitivity to masking schedule: only
α(t)=1−twith carry-over masking is used; evaluate alternative schedules (e.g., cosine, quadratic, data-adaptive), structured masking (e.g., n-grams, spans), and quantify the minimum anchor-token fraction required to learn conditional dependencies without harming continuous denoising. - Alternative noise processes: the analysis and method assume VE Gaussian noise; do VP/sub-VP SDEs, correlated Gaussian noise, or non-Gaussian noises (Laplace, logistic) alter token identifiability and mitigate dissonance without masking?
- Scalability and resource profile: provide systematic measurements of training/inference memory, wall-clock, TPS throughput, and energy for larger models (e.g., ≥1B parameters), extremely large vocabularies (≥100k BPE, multilingual), and longer contexts (≥4k tokens).
- Evaluation coverage and fairness: frontier analysis relies on perplexity/entropy with temperature sweeps; specify the evaluator LM(s), and extend to other samplers (top-k, nucleus), human evaluations, task-level metrics, and distributional tests (e.g., MAUVE, precision/recall of generative models).
- Calibration and parameterization: the model uses mean-prediction
E[X0 | Xt]to derive scores; paper calibration ofPθ(X0 | Xt), compare with noise-prediction parameterizations, quantify how miscalibration propagates through Eq. (10) into ODE dynamics, and whether uncertainty-aware losses improve robustness. - Empirical identifiability tracking:
ρ(t)andr(t)are analyzed under i.i.d. Gaussian assumptions, but there is no empirical tracking of these quantities during training/inference; measure actual identifiability under the learned network and embedding correlations to validate the framework’s assumptions. - Formal impossibility/lower bounds: the “temporal dissonance” claim is supported empirically and with scalar Gaussian comparisons, but there is no formal lower bound showing that joint learning of discrete conditional structure and continuous scores is impossible under pure Gaussian corruption at large
|V|. - Rare-token and long-range dependency effects: masking may bias learning toward frequent tokens; analyze whether hybrid corruption harms modeling of rare tokens, compositionality, and long-range dependencies, and whether structured masking (e.g., dependency-based) alleviates this.
- Distributional fidelity under guidance: quantify how guidance shifts the model distribution (e.g., estimate
KLbetween guided and unguided samplers), characterize controllability–fidelity trade-offs, and identify regimes where guidance induces mode collapse or loss of diversity. - High-NFE regimes and asymptotics: results emphasize low NFE; assess whether CANDI maintains advantages or parity at very high NFE (e.g., ≥256), and whether convergence speed or quality asymptotically exceeds discrete-only baselines.
- Cross-domain breadth: beyond Text8/OWT and QM9, evaluate hybrid diffusion on other discrete domains (graphs beyond molecules, code generation, tables, structured prediction), conditional tasks (translation/summarization), and multi-modal settings.
- Integration with distillation/curricula: explore whether hybrid continuous scores can be distilled into discrete models (teacher–student setups), or whether curriculum schedules (as in uniform-state diffusion) synergize with hybrid corruption.
- Robustness to schedule/model mis-specification: analyze sensitivity to errors in
α(t)orσ(t)schedules, and whether learned schedules or feedback controllers can stabilize training across datasets and architectures. - Safety and alignment implications: assess risks when using off-the-shelf classifiers or reward models for text guidance (bias, toxicity, prompt injection), and whether hybrid guidance amplifies or mitigates undesirable behaviors compared to pure discrete diffusion.
- Reproducibility/ablations: critical ablations are missing (e.g.,
r_min/r_max, number of guidance steps, mask fraction vs. quality, number of MC samples in approximate inference); publish these to disambiguate where gains come from and to guide practical adoption.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, drawing from the paper’s hybrid discrete–continuous diffusion framework (CANDI), token identifiability analysis, hybrid inference, and classifier-guided control.
- Sector: Software and content platforms
- Use case: Low-latency text generation at low NFE (few timesteps), leveraging joint position updates for faster inference while maintaining coherence.
- Product/workflow: CANDI-powered text generation API for chatbots, summarizers, and copywriting; integrated temperature sweeping tools to maintain desired diversity–coherence trade-offs.
- Dependencies/assumptions: Availability of pretrained diffusion transformer (or compatible architecture), temperature tuning to match target entropy ranges, robust tokenizer and embedding integration, adequate GPU/TPU capacity.
- Sector: Safety and brand control
- Use case: Controlled text generation via off-the-shelf classifiers (toxicity, brand style, topic adherence) using simple gradient addition during inference (no bespoke diffusion-classifier training required).
- Product/workflow: “Guidance layer” that plugs safety/style classifiers into the inference pipeline; policy rules can be added as gradients to steer outputs.
- Dependencies/assumptions: Reliable gradient-capable classifiers (e.g., differentiable toxicity models), alignment between classifier objectives and user goals, monitoring to avoid over-steering or gradient hacking.
- Sector: Healthcare and cheminformatics
- Use case: Property-guided molecular generation (e.g., QED, ring count) using QSAR-style models as off-the-shelf classifiers for guidance, delivering competitive diversity–coherence frontiers.
- Product/workflow: Rapid screening pipeline for candidate molecules that pairs CANDI with chemical validity checks (SMILES/token validation) and property predictors.
- Dependencies/assumptions: Quality and coverage of property predictors, robust tokenization for molecules (SMILES/graph tokens), domain-specific validity filters.
- Sector: Education technology
- Use case: Readability- and topic-controlled lesson and quiz generation using off-the-shelf readability/topic classifiers; fast generation for classroom or on-device scenarios.
- Product/workflow: Controlled content generation in LMS/authoring tools with sliders for reading level and coherence, backed by temperature sweep frontiers.
- Dependencies/assumptions: Reliable readability/topic classifiers, validation framework for age-appropriateness and content accuracy, guardrails against bias.
- Sector: Finance and enterprise analytics
- Use case: Synthetic data generation (transactions, logs) with constraints (e.g., privacy/PII avoidance, compliance tags) enforced via classifier-guidance.
- Product/workflow: Data augmentation service for testing analytics systems under controlled distributions, using gradient-guided constraints and entropy-perplexity frontiers to tune diversity.
- Dependencies/assumptions: Effective PII/compliance classifiers; domain tokenization that preserves structure; legal/data governance review.
- Sector: Music/audio generation
- Use case: Guided generation of discrete-coded audio/music tokens (e.g., codec or MIDI-like tokens) with genre/style classifiers steering outputs; faster iteration at low NFE.
- Product/workflow: Music co-creation tools where users select style constraints; hybrid inference avoids assembling large one-hot vectors via approximate embedding lookups.
- Dependencies/assumptions: Access to tokenized audio datasets; differentiable style/genre classifiers; integration with playback/rendering pipelines.
- Sector: ML tooling and platforms
- Use case: Turnkey CANDI SDKs and inference engines with the approximate sampling trick that eliminates large one-hot multiplications, enabling efficient hybrid diffusion in production.
- Product/workflow: PyTorch/JAX library modules for structured noising schedules (masking + Gaussian), reverse ODE updates, and classifier-guidance APIs.
- Dependencies/assumptions: Compatibility with current model hubs and tokenizers; robust schedule configuration (α(t), r*(t)); unit tests and profiling harnesses for latency.
- Sector: Research and academia
- Use case: Immediate adoption of the token identifiability framework to design/diagnose noise schedules and understand failures of continuous diffusion on discrete data.
- Product/workflow: Reproducible benchmarks using frontier analysis (entropy–perplexity curves) instead of single-temperature comparisons, avoiding misleading rankings.
- Dependencies/assumptions: Agreement on evaluation protocols; availability of baseline LMs for perplexity computations; datasets spanning small and large vocabularies.
- Sector: Policy and governance of AI
- Use case: Frontier analysis as a reporting standard in audits to prevent cherry-picking (require temperature sweeps and full diversity–coherence curves).
- Product/workflow: Model cards that include frontiers across entropy ranges, plus documentation of classifier-guidance settings.
- Dependencies/assumptions: Regulator and community buy-in; access to standardized corpora and metrics; transparent logging of guidance parameters.
Long-Term Applications
The following opportunities require further scaling, research, or development—e.g., optimizing schedules, deploying at LLM scale, or integrating new modalities and hardware.
- Sector: Large-scale text generation (LLM parity)
- Use case: Production-grade non-autoregressive text models that match or exceed autoregressive LLMs under strict latency/compute budgets, leveraging joint updates to reduce per-token cost.
- Product/workflow: Hybrid diffusion LLMs with optimized α(t) and r*(t), trained on multi-trillion token corpora; “low-NFE modes” for real-time applications.
- Dependencies/assumptions: Scaling of architectures and training pipelines, improved guidance strategies, robust decoding strategies for very large vocabularies.
- Sector: Multimodal generation (text–image–audio–video)
- Use case: Unified hybrid diffusion across discrete tokens (text/audio/video codecs) and continuous signals, with joint guidance across modalities for coherent cross-modal outputs.
- Product/workflow: Co-editing tools where users apply property/style constraints across modalities; factorized reverse processes and schedules per modality.
- Dependencies/assumptions: Large multimodal datasets; careful calibration of structured noising per modality; cross-modal classifiers with reliable gradients.
- Sector: Safety and compliance at scale
- Use case: Standardizing gradient-guided constraints (harmful content, PII, misinformation) with certifiable guarantees about coverage and false positive rates.
- Product/workflow: Enterprise guidance policy packs; simulation suites that stress-test models under varied temperatures/entropy ranges.
- Dependencies/assumptions: High-quality, audited classifiers; red-teaming pipelines; regulatory acceptance of guidance-based safety mechanisms.
- Sector: Robotics and planning
- Use case: Discrete action-sequence generation with joint updates guided by differentiable reward models—potentially accelerating planning under constraints.
- Product/workflow: Hybrid diffusion planners that integrate reward shaping via gradients; faster re-planning under environmental changes.
- Dependencies/assumptions: Differentiable or proxy reward models; reliable mapping from tokens to actions; validation in real environments.
- Sector: Software engineering and code generation
- Use case: Constraint-aware code generation (security rules, style guides) guided by static analyzers or learned detectors; faster ideation with low NFE.
- Product/workflow: IDE integrations where constraints are expressed as gradients; hybrid inference harmonizes correctness and speed.
- Dependencies/assumptions: Differentiable analyzers or surrogate models; robust tokenization for code; extensive training on code corpora.
- Sector: Personalization and on-device AI
- Use case: User-level style/tone guidance for personal assistants with small, on-device models leveraging low-NFE modes for immediate responses.
- Product/workflow: Profile-based guidance layers; privacy-preserving local classifiers; adaptive schedules based on device constraints.
- Dependencies/assumptions: Efficient on-device inference, memory constraints, privacy guarantees, lightweight classifiers.
- Sector: Energy and sustainability
- Use case: Lower energy-per-output across large content operations by reducing NFE while maintaining coherence via continuous score guidance.
- Product/workflow: Operational dashboards tracking energy savings vs. quality (frontiers); cost-aware inference scheduling.
- Dependencies/assumptions: Broad deployment in production systems; standardized reporting of energy metrics; careful tuning to avoid quality regressions.
- Sector: Scientific discovery (materials, proteins)
- Use case: Guided generation of discrete biological/chemical sequences (amino acids, crystal lattices) with property predictors steering toward desired stability or function.
- Product/workflow: Iterative design loops with CANDI—generate, score, guide—using domain-specific classifiers and validity constraints.
- Dependencies/assumptions: Accurate property predictors (e.g., folding, binding), domain tokenization schemes, robust validity checks.
- Sector: Evaluation ecosystems and standards
- Use case: Tooling that automates frontier analysis, temperature sweeps, and guidance audits; inclusion in model cards and benchmarks.
- Product/workflow: Open-source evaluation suites and dashboards; interoperability with popular LM evaluators.
- Dependencies/assumptions: Community consensus on metrics; maintenance of datasets; standardized guidance calibration protocols.
- Sector: Hardware acceleration for hybrid diffusion
- Use case: Specialized kernels and accelerators for the reverse ODE updates and approximate embedding lookups to minimize overhead in hybrid inference.
- Product/workflow: Compiler/runtime support for structured noising schedules; hardware–software co-design targeting low-NFE throughput.
- Dependencies/assumptions: Hardware R&D investment; coordination with framework vendors; stable model architectures.
- Sector: Methodology optimization
- Use case: Learning or adapting optimal relations between discrete masking (α(t)) and continuous degradation (r*(t))—beyond linear schedules—to improve quality and stability.
- Product/workflow: Auto-scheduling frameworks that optimize corruption schedules per task/domain using validation frontiers.
- Dependencies/assumptions: Meta-learning infrastructure; diverse validation sets; safeguards against overfitting schedules to narrow metrics.
Glossary
- Carry-over masking constraint: A rule in masked diffusion ensuring that once a position is corrupted (masked), it stays corrupted at later times. "We further impose a carry-over masking constraint, ensuring that once a position is corrupted, it remains corrupted thereafter:"
- Classifier-based guidance: A technique that steers generation toward desired properties by adding gradients from a classifier during sampling. "CANDI enables classifier-based guidance with off-the-shelf classifiers through simple gradient addition;"
- Continuous geometry: The geometric structure of continuous spaces (e.g., Euclidean), whose gradients enable coordinated updates across many positions. "they lack the benefits that Gaussian diffusion brings through continuous geometry."
- Continuous rank degradation: A measure of how much the noisy latent lowers the correct token’s relative rank among all tokens. "continuous rank degradation, which measures how many incorrect tokens are closer to the noisy latent than the correct token."
- Continuous-time Markov chains: Stochastic processes with continuous time used to define corruption in discrete diffusion. "Discrete diffusion uses continuous-time Markov chains to define noising processes over categorical data"
- ELBO (Evidence Lower Bound): A variational objective often used for training probabilistic models; here, it reduces to a weighted cross-entropy under masked diffusion. "The ELBO derived for standard masked diffusion can be interpreted as a weighted cross entropy loss"
- Embedding diffusion: Diffusion applied in the token embedding space rather than one-hot space. "embedding diffusion does not escape the temporal dissonance effect of Gaussian noise."
- Entropic schedules: Noise schedules designed via information-theoretic (entropy-based) criteria. "This schedule can be interpreted as a specific instance of entropic schedules"
- Entropy–perplexity frontier: A curve showing the trade-off between sample diversity (entropy) and fluency (perplexity) across temperatures. "we extend the entropy-perplexity frontier analysis, which captures the trade-off between sample diversity (entropy) and fluency (perplexity)"
- Gaussian diffusion: Diffusion processes driven by Gaussian noise, often used to learn continuous scores. "we focus on understanding the fundamental barrier preventing Gaussian diffusion from being applicable to discrete spaces."
- Gradient-based discrete MCMC: Sampling methods for discrete spaces that use gradients from a continuous relaxation to guide proposals. "recent work on gradient-based discrete MCMC leverages gradient information from a continuous relaxation to guide more efficient exploration"
- Masked diffusion: A discrete diffusion variant that corrupts tokens into a special mask symbol. "masked diffusion, which corrupts tokens to a special mask token"
- Monte Carlo approximation: An estimator based on random sampling; here used to approximate expectations without materializing full one-hot vectors. "we employ a Monte Carlo approximation:"
- Non-autoregressive: A generation paradigm that updates many positions in parallel rather than token-by-token. "our framework is fully non-autoregressive"
- Number of Function Evaluations (NFE): The number of score/model evaluations used during sampling; lower NFE implies faster but harder generation. "even at low NFE, contradicting these expectations."
- Probability flow ODE: A deterministic ODE that shares the same marginals as the reverse SDE, enabling deterministic sampling. "For deterministic sampling, we use the probability flow ODE, which removes the stochastic term:"
- Reverse SDE: The time-reversed stochastic differential equation that denoises data to the data distribution. "The corresponding reverse SDE is:"
- Score function: The gradient of the log-density of the noisy data distribution, used to guide denoising. "it learns a score function that jointly updates multiple positions and captures correlations among variables"
- Signal-to-noise ratio (SNR): A measure comparing signal strength to noise; used here in an analogous, rank-based sense for discrete tokens. "This can be interpreted as an analogue to the canonical SNR (signal-to-noise ratio) used in continuous domains."
- Structured noising kernel: A designed corruption process that decouples discrete masking from continuous Gaussian noise. "we introduce a structured noising kernel that decouples discrete corruption from continuous noise."
- Temporal dissonance: A mismatch in the optimal noise levels for learning discrete structure vs. continuous gradients as vocabulary grows. "This creates a temporal dissonance"
- Token identifiability: How clearly the noisy latent indicates the correct token relative to alternatives. "We introduce token identifiability as an analytical framework"
- Uniform diffusion: A discrete diffusion variant that corrupts tokens by replacing them with uniformly sampled vocabulary items. "uniform diffusion, which samples from the uniform distribution over vocabulary"
- Variance-Exploding (VE) SDE: A diffusion process where noise variance increases with time, commonly used in score-based models. "This is a Variance-Exploding (VE) SDE,"
Collections
Sign up for free to add this paper to one or more collections.