Continuously Augmented Discrete Diffusion model for Categorical Generative Modeling
Abstract: Standard discrete diffusion models treat all unobserved states identically by mapping them to an absorbing [MASK] token. This creates an 'information void' where semantic information that could be inferred from unmasked tokens is lost between denoising steps. We introduce Continuously Augmented Discrete Diffusion (CADD), a framework that augments the discrete state space with a paired diffusion in a continuous latent space. This yields graded, gradually corrupted states in which masked tokens are represented by noisy yet informative latent vectors rather than collapsed 'information voids'. At each reverse step, CADD may leverage the continuous latent as a semantic hint to guide discrete denoising. The design is clean and compatible with existing discrete diffusion training. At sampling time, the strength and choice of estimator for the continuous latent vector enables a controlled trade-off between mode-coverage (generating diverse outputs) and mode-seeking (generating contextually precise outputs) behaviors. Empirically, we demonstrate CADD improves generative quality over mask-based diffusion across text generation, image synthesis, and code modeling, with consistent gains on both qualitative and quantitative metrics against strong discrete baselines.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to make AI systems that generate things made of “choices,” like words in a sentence, pixels in a small image, or code tokens in a program. The method is called CADD, short for Continuously Augmented Discrete Diffusion. It mixes two popular ideas—masking and adding noise—so the model keeps useful hints even when parts of the data are hidden. This helps the AI create results that are both accurate and varied.
What questions are they trying to answer?
The authors focus on simple, practical questions:
- Can we avoid throwing away all information when we “mask” (hide) a token during training?
- Can we keep soft hints about what a hidden token might be, instead of using a single empty “[MASK]” symbol?
- Can we combine the strengths of two kinds of models—discrete (works with tokens) and continuous (works with vectors)—to make better text, images, and code?
- Can we do this without making training much harder or slower?
How does their method work?
To make this easy to understand, imagine a crossword puzzle:
- In a standard masked model, when a square is blank, it’s completely blank—no hints. The model must guess the letter from scratch.
- In a continuous model, you don’t use letters directly; you draw in pencil in a big, fuzzy space and only decide on a letter at the very end. That can be too vague.
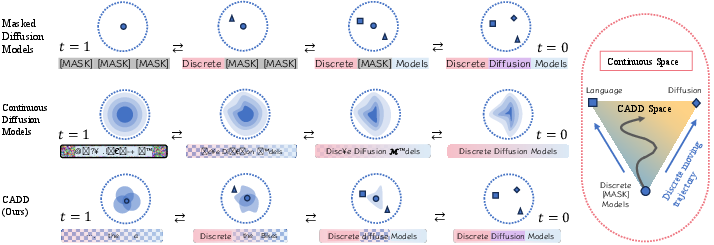
- CADD does both: if a square is blank, the model keeps a faint pencil sketch underneath—the “continuous hint”—that gently suggests what the letter could be. As time goes on, the sketch slowly fades, but it never becomes a total void. This makes it easier to fill in blanks correctly and consistently with the rest of the puzzle.
The problem with two popular approaches
- Masked diffusion (discrete): Hides tokens by replacing them with a single [MASK] symbol. This creates an “information void”—the model gets no clues about what the token used to be.
- Continuous diffusion: Adds blur-like noise to continuous vectors. This keeps “how close” something is to the right answer, but it can be too fuzzy and hard to turn into exact tokens at each step.
The new idea: CADD
CADD keeps the token-based process but adds a partner continuous vector at each position:
- When a token is visible (not masked), everything stays normal.
- When a token gets masked, instead of becoming a featureless [MASK], it also gets a continuous vector that carries a soft, noisy hint about what it might be.
- Over time, that hint gets noisier (like gradually blurring an image), but it still carries useful information—far better than a blank hole.
This paired setup gives you:
- Precision from the token side (staying on valid choices).
- Flexibility from the continuous side (smooth hints between likely choices).
It also gives you a dial between:
- Mode-seeking (be very specific and on-target).
- Mode-covering (explore diverse, valid alternatives).
You can control this by how you use the continuous hints when you pick tokens (e.g., “hard” pick the top option for precision, or “soft” average for variety) and by resampling those hints during generation.
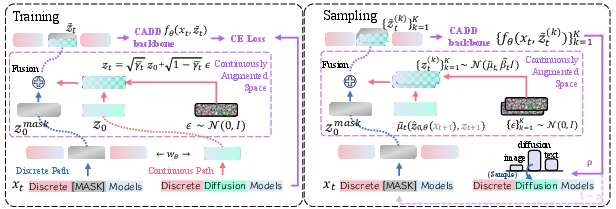
Training and generating with CADD
- Training (in plain terms):
- Take real data (text, image pixels, or code tokens).
- Randomly mask some positions.
- For masked positions, create continuous hints by adding controlled noise to the original token’s embedding (vector form).
- Feed the mix (tokens + hints) to the model and train it to predict the correct tokens at the masked spots using a standard cross-entropy loss (the usual classification loss).
- No special architecture needed; it’s similar in size and speed to existing masked diffusion models.
- Generating (sampling):
- Start with everything masked and random continuous hints.
- At each step, for each masked position, decide either:
- Unmask it now (choose a token using the model’s prediction, guided by the hint), or
- Keep it masked a bit longer and gently update the hint (add a little more controlled noise).
- Repeat until all positions are filled or you reach the final step.
- For more diversity, you can draw multiple hint samples; for sharper outputs, use the “hard” top choice.
What did they find?
Across text, images, and code, CADD consistently outperforms strong token-only baselines:
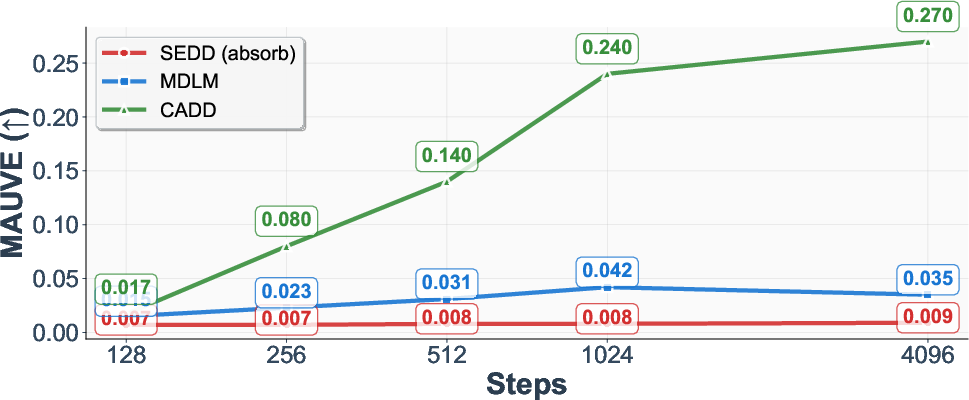
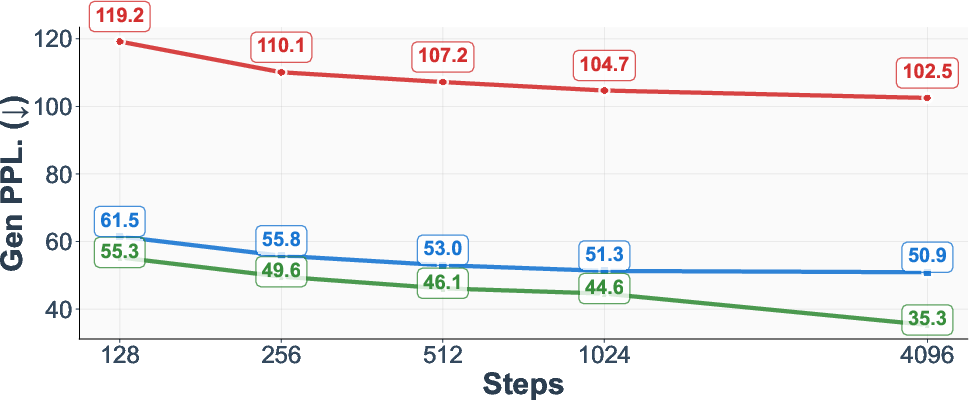
- Text generation (OpenWebText):
- Better quality across many sampling step counts.
- Measured with MAUVE (higher is better) and generative perplexity (lower is better), CADD improves as you give it more steps, even when other methods plateau or get worse.
- Image generation (CIFAR-10 and ImageNet 32×32):
- Lower FID (better realism) and higher Inception Score than comparable discrete methods at the same compute budget.
- On CIFAR-10 (with the same number of steps), CADD achieves top-tier scores among the compared methods.
- Code generation (HumanEval, MBPP, BigCodeBench):
- CADD is the strongest diffusion-based code model reported here, beating previous diffusion baselines on most metrics.
- It’s also competitive with strong autoregressive code models.
- It works both when trained from scratch and when used to fine-tune an existing diffusion code model.
Why this matters: CADD proves that keeping soft, continuous hints for masked tokens helps the model make better choices—more accurate and more coherent—without sacrificing diversity.
Why does it matter?
- Better balance of creativity and control: CADD can generate outputs that are both varied and contextually precise, and you can tune the balance easily.
- Simple to adopt: It uses the same kind of backbone as popular masked diffusion models and the same standard training loss for tokens, so it’s easy to plug in and fine-tune existing models.
- Broad impact: The idea isn’t limited to words—it helps across text, images, and code, and likely other categorical data too.
In short, CADD fills in the “information void” left by plain masking with helpful, smooth hints. That small change leads to clearer, more faithful, and more flexible generation across different kinds of data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that are missing, uncertain, or left unexplored by the paper:
- Objective mismatch and ELBO tightness
- The main training objective drops the continuous-space MSE term and optimizes only cross-entropy over masked positions. The impact of this simplification on likelihood, ELBO tightness, and convergence guarantees is not analyzed or quantified.
- No comparison is provided between training with the exact KL/MSE term vs. the simplified CE-only loss on downstream quality, likelihood (e.g., bits-per-token), or calibration.
- Schedule design and sensitivity
- How to jointly choose and tune the discrete mask schedule αt and continuous schedule γt is not explored; sensitivity of performance to these schedules (and their relative SNR decay rates) is unreported.
- It remains unclear whether learned/adaptive schedules (e.g., data- or token-dependent) outperform fixed schedules, or whether schedules should depend on token frequency, position, or entropy.
- Fusion mechanism between discrete and continuous states
- The model fuses discrete and continuous inputs by simple addition. Alternatives (concatenation, gating/FiLM, attention-based conditioning, learned scaling/normalization) are not investigated, and it is unknown whether they yield better stability or accuracy.
- No analysis on how embedding norm/anisotropy interacts with additive fusion; learned scaling of the continuous hint could mitigate interference but is untested.
- Geometry and noise model in the continuous space
- The continuous diffusion uses isotropic Gaussian noise in embedding space; the suitability of this assumption for anisotropic token-embedding geometry is not validated. Token-specific or learned covariances remain unexplored.
- The latent dimensionality is tied to the token embedding dimension by default; there is no study on whether different latent sizes or projection heads improve performance.
- Posterior estimation and use of multiple continuous samples
- The method proposes averaging over K samples from the continuous latent but evaluates almost exclusively with K=1. The trade-off between sample diversity, precision, and computational cost as K increases is not characterized.
- The estimator of E[pθ(·|xt, zt)] is a simple Monte Carlo average; variance-reduction, importance weighting, or deterministic quadrature alternatives are not explored.
- Mode coverage vs. mode seeking controls
- The paper claims controllable trade-offs via “hard” vs. “soft” ẑ0 choices and via K, but does not provide systematic Pareto curves or diversity–precision analyses (e.g., Self-BLEU/diversity scores for text, CLIP diversity for images).
- Guidance-like mechanisms (classifier/classifier-free in the continuous hint) to steer mode seeking/coverage are not investigated.
- Unmasking policy and adaptivity
- The flip/keep decision is driven by a fixed schedule-derived probability; learning an adaptive policy conditioned on content uncertainty, confidence, or entropy (potentially improving error correction) is not explored.
- Remasking or edit operations (known to improve discrete diffusion) are not integrated with CADD’s continuous hints; the interplay remains an open design question.
- Training–sampling mismatch and stability
- During training, zt at masked positions is formed from clean embeddings of x0 (then noised), while at sampling zt starts from Gaussian noise; the effect of this mismatch on stability, calibration, and early-step predictions is not analyzed.
- No robustness analysis to embedding-table initialization/quality (random vs. pretrained), embedding normalization, or tokenizer granularity (bytes vs. BPE vs. wordpiece).
- Likelihood and calibration evaluation
- Beyond MAUVE/gen-perplexity and FID/IS, there is no report of likelihood-based metrics (bits-per-token for text/code, NLL bounds) or calibration metrics (ECE/Brier), which would clarify probabilistic faithfulness of the model.
- Scaling and memory/compute footprint
- While parameter count is unchanged, the memory/runtime overhead of maintaining and updating the continuous latents (especially for long sequences or large K) is not measured across tasks or model sizes.
- Inference-time scaling is shown on OWT, but broader throughput/latency comparisons (e.g., vs. AR or MDMs) under fixed wall-clock or FLOP budgets, and for K>1, are absent.
- Scope of empirical evaluation
- Text experiments are limited to unconditional OWT; conditional/natural language tasks (prompted generation, summarization, translation) and human preference evaluations are not included.
- Image experiments focus on low-resolution (32×32). Applicability to higher-resolution, latent-tokenized image models (e.g., VQ or semantic tokens), and multimodal settings is untested.
- Code results cover pass@1 on select benchmarks; pass@k, robustness to long-context coding, and real-time latency comparisons against AR baselines are not provided.
- Error analysis and failure modes
- No qualitative or quantitative error analysis shows where CADD helps/hurts compared to MDMs (e.g., contradiction resolution, long-range coherence, error propagation, recovery from early mistakes).
- It is unclear whether continuous hints reduce common discrete diffusion failure modes (premature token commitment, inconsistent spans) or introduce new ones (overreliance on noisy zt).
- Integration with advanced discrete diffusion techniques
- CADD is not combined with recent improvements (remasking, shortlisting/bit/simplex representations, edit operations, informed correctors). Synergies or conflicts with these techniques remain open.
- Theoretical characterization
- Beyond factorization results, there is no theoretical characterization of how continuous hints change posterior contraction, information flow, or sample complexity vs. MDMs/CDMs.
- Formal analysis of the proposed mode coverage/precision balancing (e.g., bounds or diagnostics connecting γt/αt, K, and entropy of pθ) is missing.
- Safety and controllability
- The paper does not address how to steer or constrain the continuous hints for safe or controlled generation (e.g., toxicity filters, constrained decoding, adherence to constraints), nor whether the continuous path can be exploited for controllable edits.
- Generalization and domain shift
- Robustness of the continuous hints under domain shift (e.g., out-of-distribution prompts, rare tokens, low-resource domains) is untested; how the continuous latents behave for very rare or unseen tokens is unclear.
- Tokenization and vocabulary size effects
- Sensitivity to vocabulary size and type (byte-level vs. BPE vs. word-level) on both performance and efficiency is not explored; large-vocabulary regimes may stress the discrete path and the continuous hint differently.
- Practical guidance
- There is no prescriptive guidance for practitioners on choosing αt/γt, K, hard vs. soft ẑ0, or fusion strategies by task and budget, nor heuristics for diagnosing when CADD provides the most benefit.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now by leveraging CADD’s core contributions: continuous augmentation of masked diffusion, improved sampling trade-offs (mode-seeking vs. mode-covering), and parameter-efficient fine-tuning on existing masked diffusion models.
- Higher-quality text generation for content workflows
- Sector: software, media, marketing, education
- What: Generate more coherent and context-faithful copy (blog posts, product descriptions, summaries, lesson outlines) with controlled diversity for brainstorming vs. precise rewriting.
- Tools/workflows: Upgrade existing masked diffusion LMs (e.g., MDLM) via CADD fine-tuning; expose a “diversity–precision” knob via hard vs. soft z-hat and the number of continuous latent samples K; set larger T at inference when latency allows, as CADD scales favorably with steps.
- Assumptions/dependencies: Access to pretrained MDM checkpoints and tokenizer; moderate compute; content safety filters.
- Code assistants with better first-try solutions and fallback diversity
- Sector: software engineering, developer tools
- What: Higher pass@1 and more robust alternatives in IDE assistants, code completion, bug fixing, and refactoring, particularly on challenging tasks (e.g., BigCodeBench-Hard).
- Tools/workflows: Integrate CADD into existing diffusion code LMs (e.g., DiffuCoder) via fine-tuning (same parameter count); at inference, sample multiple continuous latents (K>1) for safe exploration of candidate implementations; surface a coverage–precision toggle to users.
- Assumptions/dependencies: High-quality code datasets; policy-compliant licensing; security filters (e.g., for secrets, unsafe APIs).
- Low-resolution image generation with improved fidelity under the same budget
- Sector: graphics, gaming, UX, embedded
- What: Generate icons, sprites, thumbnails, and concept studies with better FID/IS at fixed NFE budgets.
- Tools/workflows: Replace MDM backbones in existing 32×32 pipelines with CADD; provide user-level control over diversity by switching z-hat mode (hard/soft) and K; use higher T when latency allows to further improve quality.
- Assumptions/dependencies: Current results demonstrated at 32×32; scaling to high-resolution typically requires discrete tokenizers (e.g., VQ/VAE) and engineering.
- Data augmentation for downstream ML tasks
- Sector: ML engineering, robotics (discrete plans), NLP/CV model training
- What: Generate semantically consistent yet diverse synthetic text/code/images to improve robustness and coverage in training classifiers, retrievers, or policy learners.
- Tools/workflows: Use CADD’s multi-sample latent draws to expand each masked context into multiple valid variants; keep “soft” z-hat for broader coverage; apply filtering and reweighting to maintain label integrity.
- Assumptions/dependencies: Validation loops to avoid label drift; compute for on-the-fly augmentation.
- Retrieval- and context-anchored text completion with fewer off-topic drifts
- Sector: search, customer support, productivity
- What: Reduce “information void” when spans are masked by conditioning denoising on continuous hints; improves alignment to retrieved snippets/FAQs/specs.
- Tools/workflows: Map retrieval embeddings to the model’s embedding space and feed them as the continuous latent for masked positions; unmask with CADD while keeping discrete context fixed.
- Assumptions/dependencies: Alignment between retrieval and token embedding spaces; guardrails for source attribution.
- Interactive writing tools with “precision vs. variety” toggles
- Sector: consumer productivity, education
- What: Writers switch between precise rewrites (mode-seeking) and varied suggestions (mode-covering) for the same prompt/paragraph.
- Tools/workflows: Expose z-hat choice (hard for precision, soft for variety), K (number of latent candidates), and T (quality vs. latency) in UI.
- Assumptions/dependencies: Lightweight inference for real-time UX; on-device feasibility depends on model size and hardware.
- Efficient upgrade path for existing masked diffusion stacks
- Sector: platform providers, ML infrastructure
- What: Retrofit current MDM models (text, code, image) to CADD without increasing parameter count or substantial training complexity.
- Tools/workflows: Add a continuous head and fused embedding input (disc + cont), train with standard cross-entropy; retain discrete schedules; deploy inference-time knobs without architectural changes.
- Assumptions/dependencies: Access to training pipeline; continuous noise schedule tuning; evaluation to calibrate trade-offs.
- Safer controlled generation via latent-side guidance
- Sector: trust & safety, policy compliance
- What: Steer away from restricted content or toward policy-compliant phrasing by resampling/weighting continuous latents at masked positions before unmasking.
- Tools/workflows: Couple CADD with lightweight safety scorers that rank latent candidates; reject/replace problematic latent hints before unmasking.
- Assumptions/dependencies: Reliable safety signals; monitoring for false positives/negatives.
- On-device or edge deployment with no parameter overhead
- Sector: mobile, IoT, privacy-first apps
- What: Improve quality of discrete diffusion models on-device (e.g., text assist, small-image generation) without increasing model size.
- Tools/workflows: Keep same backbone as MDM; optimize fusion and sampling kernels; adjust T and K to meet latency/energy budgets.
- Assumptions/dependencies: Hardware acceleration for DiT-like backbones; careful schedule tuning for real-time performance.
Long-Term Applications
These uses are plausible but need further research, scaling, or productization—e.g., moving beyond 32×32 images, extending to audio, or integrating tightly with enterprise systems and policies.
- High-resolution image and video generation with discrete token pipelines
- Sector: media, design, entertainment
- What: Combine CADD with discrete image/video tokenizers (e.g., VQ-VAE, tokenizer-based codecs) to mitigate “information voids” during masking and improve sample quality at high resolution and long sequences.
- Tools/workflows: CADD on token sequences; inference-time scaling (large T), multi-sample K to maintain coverage without mode collapse; editing workflows via targeted masking.
- Assumptions/dependencies: Robust tokenizers; memory/latency management; distributed inference.
- Audio, speech, and music generation over codec tokens
- Sector: communications, creative tools
- What: Model discrete audio tokens (e.g., EnCodec) with CADD to preserve semantic hints in masked spans, improving prosody consistency and timbre continuity.
- Tools/workflows: Extend CADD schedules to audio token streams with long-range structure; provide coverage–precision controls for style exploration vs. faithful cloning.
- Assumptions/dependencies: High-quality audio tokenizers; evaluation protocols for intelligibility and naturalness.
- Multimodal generative foundation models with better cross-modal grounding
- Sector: assistants, enterprise workflows, accessibility
- What: Use CADD to bridge masked discrete tokens across modalities (text, image, code) while continuous latents carry semantic hints, improving alignment and reducing off-mode errors.
- Tools/workflows: Joint discrete schedules per modality; shared or aligned continuous latent spaces; selective unmasking strategies per channel.
- Assumptions/dependencies: Stable multimodal tokenizers; training at scale; careful cross-modal calibration.
- Structured planning and reasoning over discrete action spaces in RL
- Sector: robotics, logistics, operations
- What: Retain “soft semantic hints” in masked action sequences (skills/tactics) to improve plan refinement and reduce error cascades during unmasking.
- Tools/workflows: Treat action tokens as discrete with CADD latents; sample multiple latents (K) for contingency plans; select via value/policy scores.
- Assumptions/dependencies: Reliable evaluators for plan selection; sim-to-real transfer.
- Program synthesis with verifiability and alternative search
- Sector: software, formal methods, verification
- What: Use CADD’s multi-sample latents to propose diverse yet semantically plausible programs, then filter via tests/specs/provers; maintain precision by switching to hard z-hat once a candidate passes checks.
- Tools/workflows: Tight CI-style loops: propose → test → shrink search via unmasking; cache latent candidates for incremental edits.
- Assumptions/dependencies: High-coverage specs/tests; compute for propose–verify cycles.
- Fine-grained controllable editing for documents, UI layouts, and code diffs
- Sector: productivity, design systems, developer tools
- What: Mask targeted spans and use continuous hints for graded edits (style, tone, complexity) without losing local semantics.
- Tools/workflows: Expose tunable schedules for how quickly masked spans “forget” context; allow user to set K and choose among alternatives; integrate with version control for diffs.
- Assumptions/dependencies: Reliable span selection and constraint handling; UX for presenting alternatives.
- Fairness and coverage auditing in generative systems
- Sector: policy, compliance, research
- What: Use the mode-coverage knob (soft z-hat, larger K) to probe whether the model can represent diverse dialects, styles, or demographic contexts; identify collapses that MDMs may hide due to absorbing masks.
- Tools/workflows: Audit pipelines that sweep K/T and measure representation quality across subgroups; report stability of outputs vs. diversity.
- Assumptions/dependencies: Suitable fairness metrics; curated evaluation datasets; governance frameworks.
- Knowledge distillation and training efficiency research
- Sector: academia, ML infrastructure
- What: Distill large AR models into CADD-based discrete diffusers that preserve coverage while enabling precision via continuous hints; explore inference-time scaling laws in masked diffusion with augmentation.
- Tools/workflows: Paired training losses (cross-entropy + optional MSE on continuous posterior); experiments on schedules and remasking strategies; open-source CADD layers for common backbones.
- Assumptions/dependencies: Teacher access; compute for distillation; standardized benchmarks.
Notes on Assumptions and Dependencies (cross-cutting)
- Scaling evidence: The paper demonstrates improvements on text (OWT), code (HumanEval/MBPP/BigCodeBench), and low-res images (CIFAR-10, ImageNet-32). For high-resolution vision and long-form audio, additional engineering and tokenization are required.
- Knobs and trade-offs: The hard vs. soft z-hat choice and the number of latent samples K directly implement the diversity–precision control; higher T generally improves CADD more than mask-only baselines but increases latency.
- Compatibility: CADD reuses MDM backbones (same parameter count); training remains simple (cross-entropy on masked positions), enabling efficient fine-tuning.
- Safety and governance: As with any generative model, outputs require alignment, filtering, and auditing; CADD’s latent-side sampling can assist but does not replace policy controls.
Glossary
- Absorbing [MASK] token: An absorbing state used in discrete diffusion that collapses all corrupted tokens into a single symbol, erasing token-specific information. "Standard discrete diffusion models treat all unobserved states identically by mapping them to an absorbing [MASK] token."
- Annealing (attention mechanism): Gradually changing the attention mask during training or adaptation, typically from causal to bidirectional. "adapting a pretrained autoregressive LLM (e.g., Qwen2.5-coder) into a discrete diffusion model by annealing its attention mechanism from causal to bidirectional"
- Autoregressive (AR) model: A model that generates each token conditioned only on previous tokens in sequence. "achieving performance on par with AR models."
- Bidirectional attention: Attention that can attend to both left and right context, not restricted to past tokens. "from causal to bidirectional"
- CADD (Continuously Augmented Discrete Diffusion): A method that augments discrete diffusion with a paired continuous latent process to retain and use semantic hints during denoising. "We introduce Continuously Augmented Discrete Diffusion (CADD), a framework that augments the discrete state space with a paired diffusion in a continuous latent space."
- Causal attention: Attention restricted to only previous positions (past context) in a sequence. "from causal to bidirectional"
- Categorical distribution: A discrete distribution over a finite set, used to model token probabilities. "p_\theta(\hat{}0\mid _t,_t)=\mathrm{Categorical}\big(\mathrm{logits}=f\theta(_t,_t)\big)"
- Continuous diffusion models (CDMs): Diffusion models that corrupt and denoise data in continuous space (typically with Gaussian noise). "Continuous Diffusion Models (CDMs) for categorical data maps tokens into a continuous space"
- Continuous latent space: A continuous vector space paired with tokens that retains graded semantic information during masking. "a paired diffusion in a continuous latent space."
- Continuous-time masked diffusion models: A formulation of discrete diffusion where masking evolves in continuous time. "the model was unified and simplified to continuous-time masked diffusion models"
- Cross-entropy (token-level): A loss measuring the discrepancy between predicted token distributions and true tokens. "yielding clear training signals via token-level cross-entropy."
- Denoising objective: The training target of reconstructing clean data from noised inputs. "their continuous denoising objective can over-smooth token identities"
- Dirac delta function: A distribution representing a point mass, used to denote deterministic transitions. "( denotes the dirac function)"
- Dirichlet priors: Priors defined on probability simplices, often used to model categorical distributions. "directly on the probability simplex via Dirichlet priors"
- Discrete diffusion models: Models that define a diffusion process over discrete tokens, typically using masking/unmasking transitions. "Discrete diffusion models operate by defining a Markov chain over the discrete token space"
- Flow-matching techniques: Methods that learn generative models by matching probability flows, often on manifolds like the simplex. "Flow-matching techniques further treat the simplex as a statistical manifold"
- Fréchet Inception Distance (FID): An image-generation metric comparing statistics of generated and real data in an Inception feature space. "we report Fréchet Inception Distance (FID) and Inception Score (IS), computed with 50,000 random samples."
- Function evaluations (NFE): The number of model calls/steps used during sampling. "with 512 function evaluations (NFE)"
- Gaussian diffusion: A diffusion process that adds Gaussian noise to data in continuous space. "applies Gaussian diffusion to the representations"
- Generative perplexity: A metric that evaluates how well generated text is modeled by a reference LM (lower is better). "generative perplexity (lower is better)"
- Inception Score (IS): An image-generation metric assessing quality and diversity via a pretrained classifier. "we report Fréchet Inception Distance (FID) and Inception Score (IS)"
- Kullback–Leibler (KL) divergence: A measure of divergence between probability distributions used in variational objectives. "the KL is identically $0$"
- Latent variable: An unobserved variable capturing hidden structure; here, a continuous vector paired with each token. "augments the discrete state space with a continuous latent variable, ."
- Logits: The pre-softmax scores output by a model that parameterize categorical probabilities. "=\mathrm{Categorical}\big(\mathrm{logits}=f_\theta(_t,_t)\big)"
- Markov chain: A stochastic process where the next state depends only on the current state. "operate by defining a Markov chain over the discrete token space"
- Masked Diffusion Models (MDMs): Discrete diffusion models that progressively mask tokens and learn to unmask them. "Masked Diffusion Models (MDMs) have recently shown strong results for categorical data"
- Mode coverage: Emphasizing diversity by covering many plausible outputs (modes) of the data distribution. "mode-coverage (generating diverse outputs)"
- Mode seeking: Emphasizing precision by focusing on high-probability outputs near a mode. "mode-seeking (generating contextually precise outputs)"
- Normalizing flow: Invertible transformations used for flexible density modeling. "leveraging density models with normalizing flow"
- Over-smoothing: Loss of discrete identity due to operating solely in continuous space during denoising. "they face a different challenge known as ``over-smoothing''."
- Posterior: The distribution over previous or clean states conditioned on current observations. "the posterior can be factorized in the following form"
- Probability simplex: The set of all probability vectors (nonnegative entries that sum to one). "directly on the probability simplex via Dirichlet priors"
- Remasking: Re-introducing masks during reverse diffusion to correct earlier errors. "remasking during the reverse process"
- Rounding error: Error arising when converting continuous embeddings back to discrete tokens. "a problem known as ``rounding error''"
- Score-based methods: Generative methods that learn gradients (scores) of log densities for sampling. "enables the use of established score-based methods."
- Score distillation: Using score models to guide and sharpen samples from another generator or objective. "score-distillation approaches that sharpen samples while retaining diffusion training for coverage"
- Signal-to-Noise Ratio (SNR): A measure of signal strength relative to noise, used to weight objectives or schedules. "Example of Signal-to-Noise Ratio (SNR) change of one token in the forward of vanilla Mask Diffusion vs. CADD"
- Simplex representation: Representing discrete variables as points on the probability simplex rather than one-hot indicators. "using bits and simplex representation to enrich the binary choice of masking"
- Unconditional sampling: Generating samples without conditioning on external inputs like labels or prompts. "We follow MDM variants to unconditionally sample images"
- Variational lower bound: A tractable bound on log-likelihood optimized during variational training. "to more accurately estimate the exact variational lower bound."
Collections
Sign up for free to add this paper to one or more collections.

