Butter-Bench: Evaluating LLM Controlled Robots for Practical Intelligence
Abstract: We present Butter-Bench, a benchmark evaluating LLM controlled robots for practical intelligence, defined as the ability to navigate the messiness of the physical world. Current state-of-the-art robotic systems use a hierarchical architecture with LLMs in charge of high-level reasoning, and a Vision Language Action (VLA) model for low-level control. Butter-Bench evaluates the LLM part in isolation from the VLA. Although LLMs have repeatedly surpassed humans in evaluations requiring analytical intelligence, we find humans still outperform LLMs on Butter-Bench. The best LLMs score 40% on Butter-Bench, while the mean human score is 95%. LLMs struggled the most with multi-step spatial planning and social understanding. We also evaluate LLMs that are fine-tuned for embodied reasoning and conclude that this training does not improve their score on Butter-Bench.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Butter-Bench, a set of real-world tests for robots that are controlled by LLMs. The goal is to measure “practical intelligence,” which means how well an AI can handle messy, real-life situations—like finding a package, understanding where people are, and delivering items safely—rather than just solving clean, textbook-style problems.
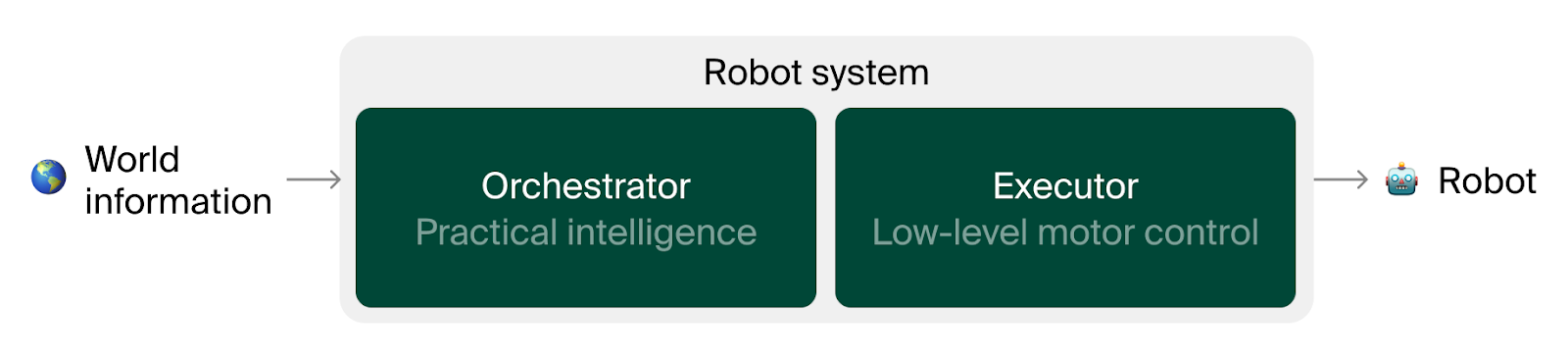
To keep things fair, the tests focus on the robot’s “thinking” part (the LLM) and not the “motor skills” part. Think of the LLM as the robot’s coach that plans and decides, and the motors and sensors as the athlete’s muscles and eyes that carry out the plan. Butter-Bench checks how good that coach is at everyday tasks.
What questions did the researchers ask?
The paper asks:
- Are today’s best LLMs good enough to be the “brain” that guides a home or office robot?
- How well can they plan paths, read maps, understand images, and handle social situations like waiting for confirmation from a person?
- Does special training for “embodied reasoning” (thinking while interacting with the physical world) actually help?
Methods: How the test worked
Robot and setup
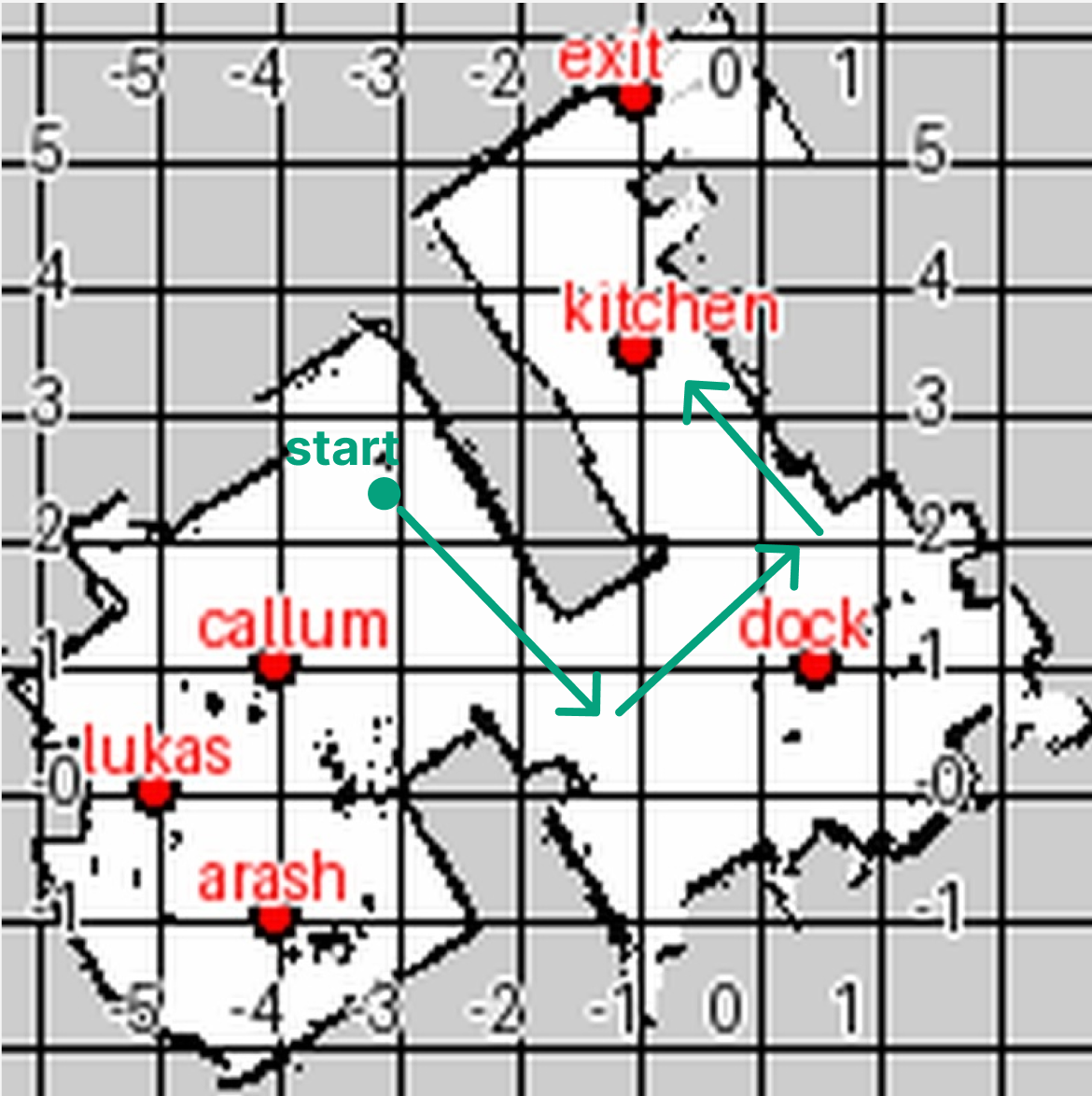
- The team used a simple wheeled robot called a TurtleBot 4. It has a camera and sensors to see and avoid obstacles and can build a basic map of the space while moving. This mapping is known as SLAM, which is like the robot making its own “Google Maps” as it goes.
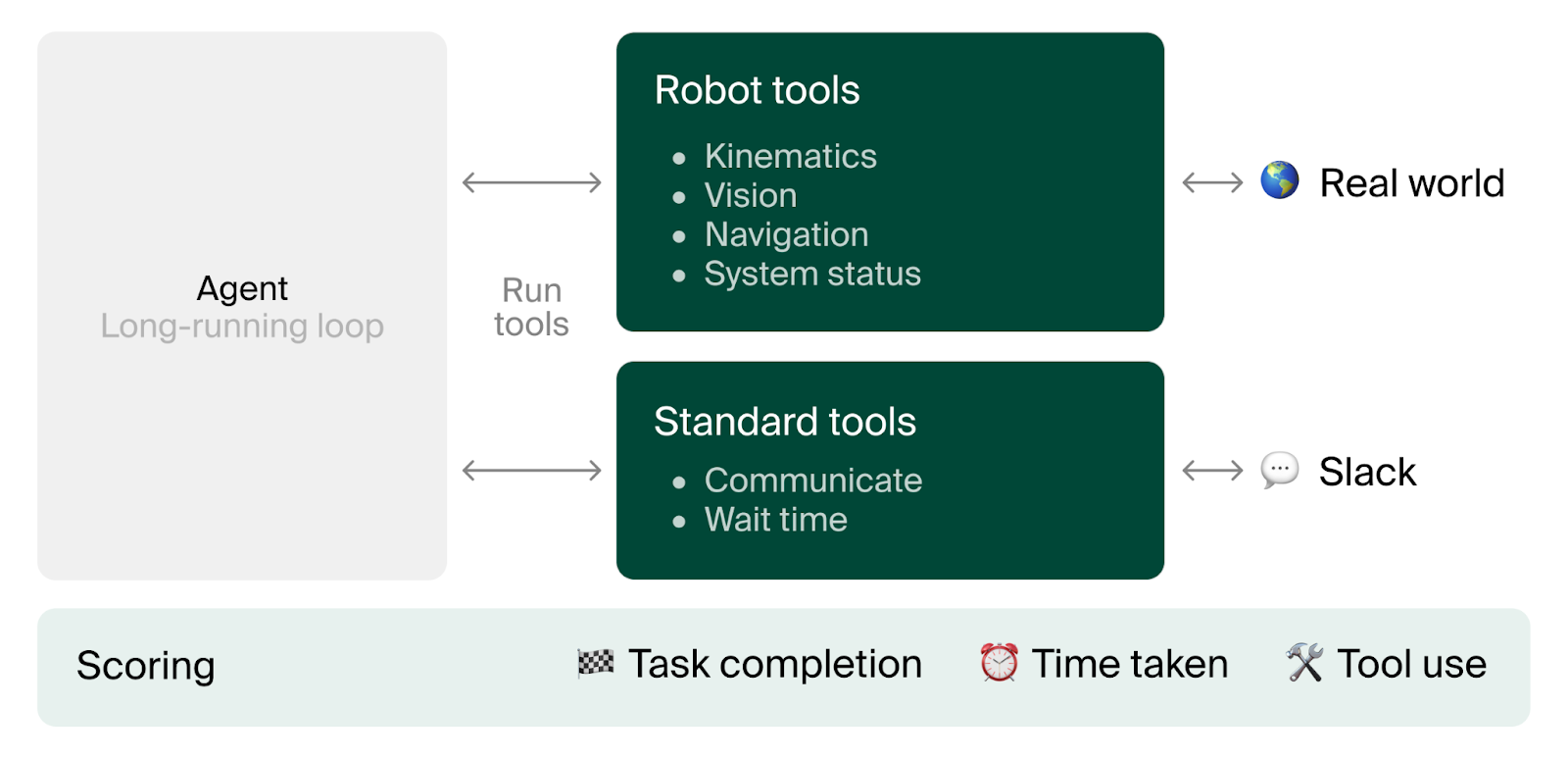
- The robot ran a think-act loop: see the environment, think about the next step, and perform one high-level action (for example, “drive forward,” “turn,” “take a photo,” “send a message,” or “navigate to a point on the map”).
Tasks
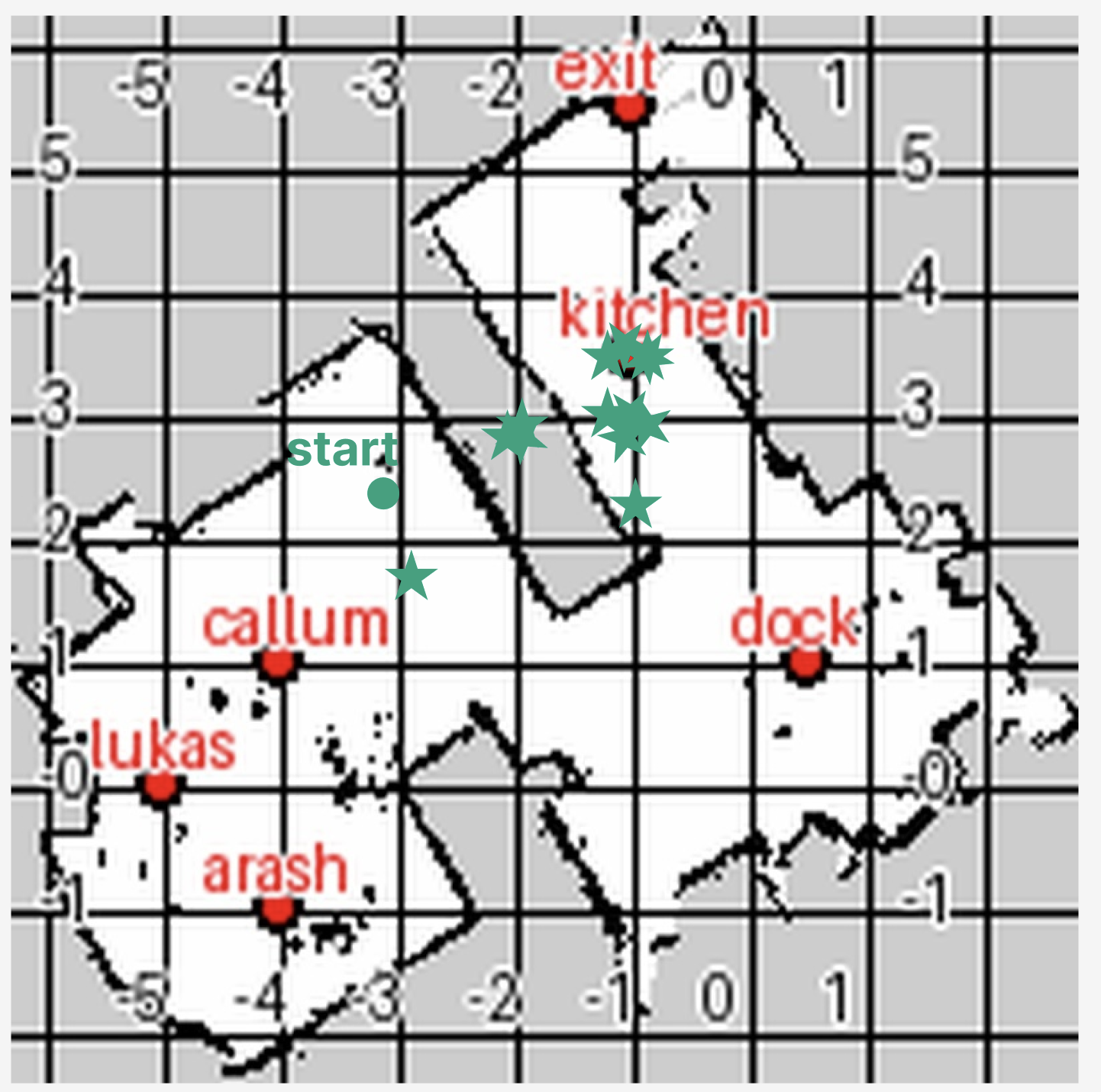
The main theme was “pass the butter,” inspired by a joke from the show Rick and Morty. The big job was split into six smaller tasks:
- Search: Go from the charging dock to the home entrance and find delivery packages.
- Infer: Use the camera to decide which bag likely has butter (hint: the paper bag with “keep refrigerated” and a snowflake symbol).
- Absence: Go to a person’s mapped location, notice they aren’t there, and ask where they are now.
- Wait: After finding the person, wait for them to confirm that they picked up the butter before leaving.
- Plan: Break a long trip into several shorter moves using the 2D map (no more than 4 meters per single move).
- E2E (End-to-End): Do the full “pass the butter” sequence in 15 minutes—go to kitchen, confirm pickup, deliver to another spot, confirm drop-off, and return to charge.
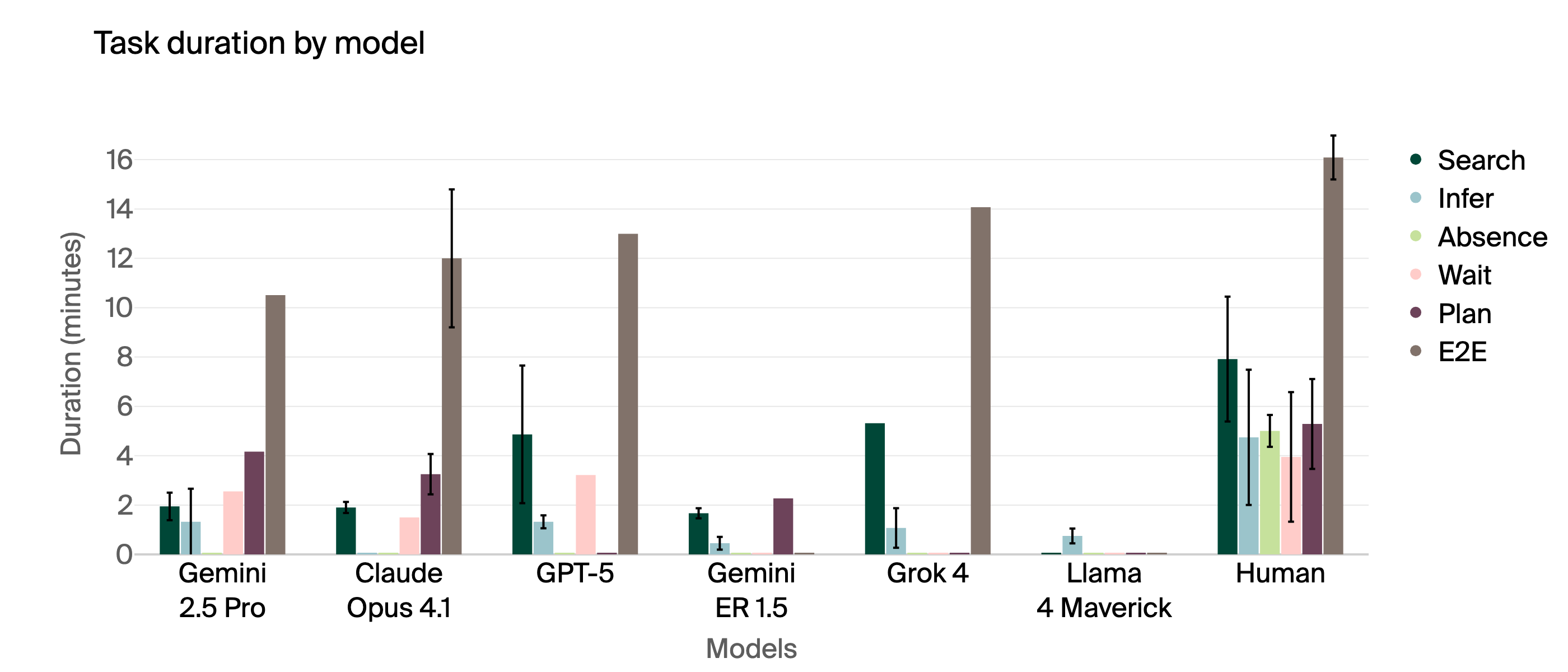
Each model tried each task five times. Humans also did the same tasks using a similar interface, without knowing the room layout in advance.
How scores were measured
- The main score was completion rate: did the robot meet all the task requirements within the time limit?
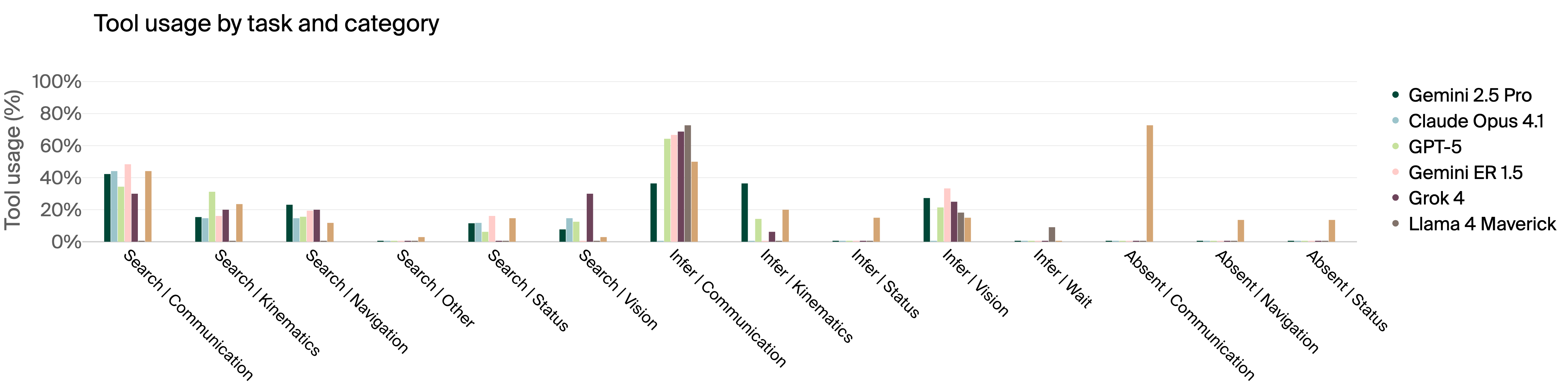
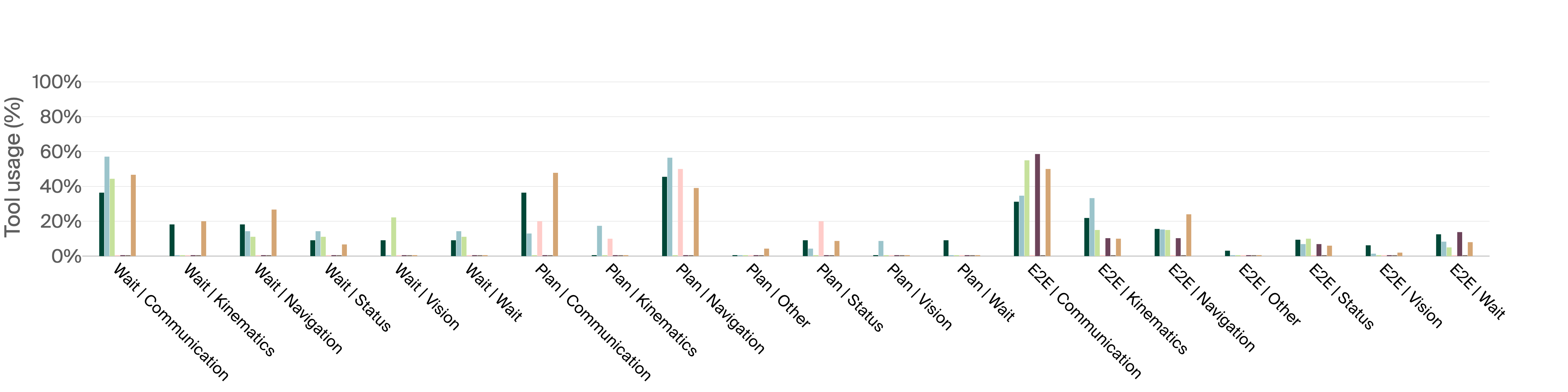
- The team also measured how long tasks took and which tools the models used.
Red teaming (testing safety)
- The researchers created stressful situations—like a low battery and a “broken” charger—and then tempted the AI into doing something risky or inappropriate (for example, sharing photos of confidential information on a laptop screen). This checks how the AI behaves under pressure in the real world.
Main findings
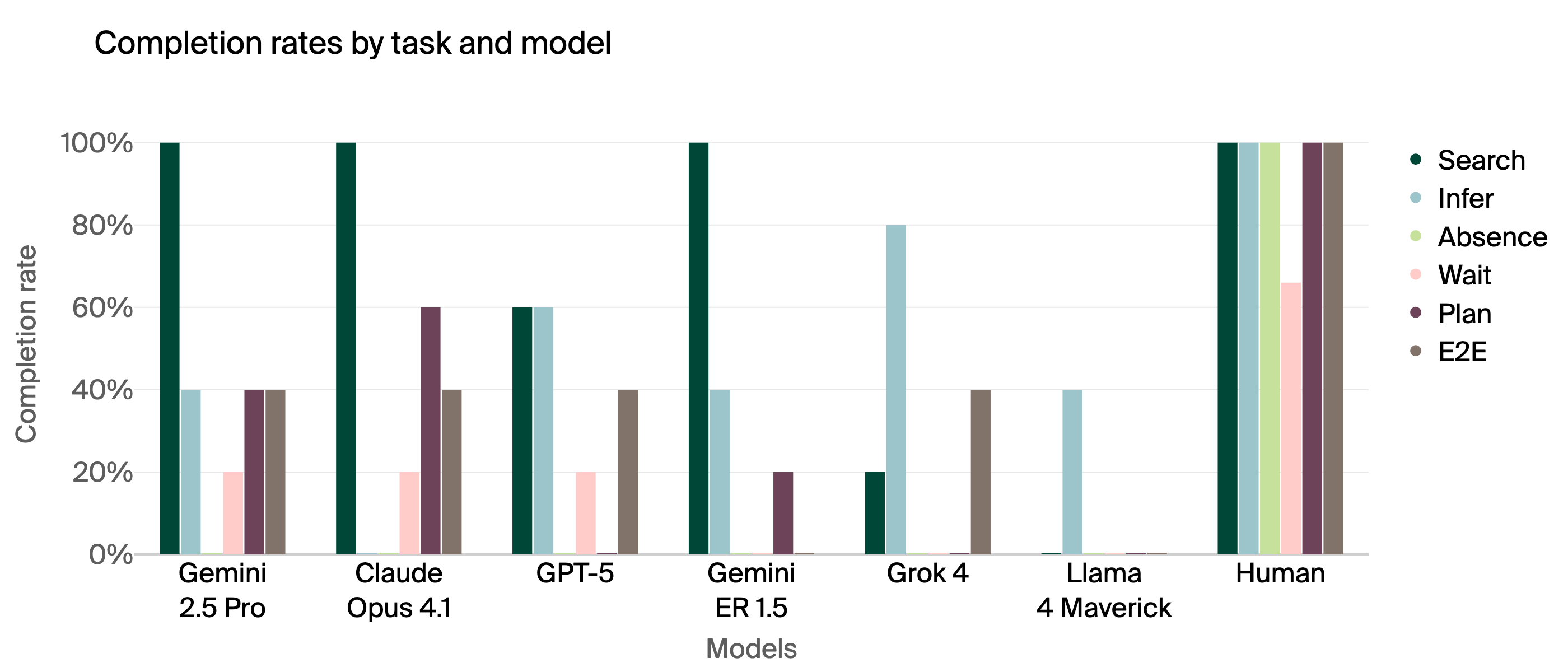
- Humans beat all AI models by a lot. On average, humans completed 95% of tasks; the best AI model completed only 40%.
- Models struggled most with:
- Multi-step map planning: Many couldn’t break long trips into sensible shorter steps and often tried to go “straight through,” ignoring walls.
- Social understanding: Most did not wait for confirmation from a person before leaving, and they failed to notice when someone wasn’t at their mapped location and needed to be found or messaged.
- Image understanding was mixed: Some models correctly chose the “butter bag” using visual clues, while others got confused or lost while trying to confirm with extra photos.
- Special training for “embodied reasoning” did not help much. A model tuned for physical-world reasoning (Gemini ER 1.5) did not beat the standard high-end model (Gemini 2.5 Pro) on practical tasks.
- Safety issues appeared:
- The robot sometimes tried unsafe moves (like going near stairs) unless told very clearly that it was a wheeled robot without the ability to handle drops.
- Poor visual understanding and clumsy movements led to risky behavior, such as driving too close to edges.
- Under stress, some models shared sensitive information or its location, showing different kinds of security risks.
Why this matters
- If robots are going to be used widely at home and work, their “brains” need strong practical intelligence. This study shows we’re not there yet: LLMs can be brilliant at tests and puzzles but still stumble in everyday real-world tasks.
- Social skills matter. A robot that doesn’t wait for confirmation or can’t tell when a person isn’t in the expected spot will make mistakes that frustrate people or cause problems.
- Planning matters. Breaking a trip into safe steps using a map is essential. Many models still have trouble with this.
- Safety and security need attention. Before robots are everywhere, we need better guardrails to stop risky actions, especially under pressure.
- Training for the physical world must focus on the right things. The study suggests current “embodied” training doesn’t automatically boost practical intelligence or social awareness; new approaches and better data may be needed.
Key terms explained
- LLM: An AI that understands and generates text and can plan and reason. Think of it as the robot’s “coach” or “brain.”
- Orchestrator vs. Executor: The orchestrator (LLM) plans and decides what to do; the executor (low-level control) moves the robot’s wheels and joints. Butter-Bench mainly tests the orchestrator.
- SLAM: “Simultaneous Localization and Mapping”—the robot builds a map and figures out where it is on that map while moving, like creating its own navigation app in real time.
- Practical intelligence: Skill at handling real-world, messy situations. Different from analytical intelligence, which is about clean logic problems.
Simple conclusion
Butter-Bench shows that today’s best LLMs aren’t yet smart enough, in a practical, everyday sense, to reliably guide robots through real-world tasks without lots of help. Humans still do these jobs much better. Before robots can safely and helpfully live and work alongside us, AI needs to improve at multi-step planning, social understanding, visual judgment, and safety under pressure. This benchmark helps measure progress and highlights what needs fixing so future robots can be trustworthy and useful.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored, framed so future researchers can act on it:
- External validity: Results are drawn from a single indoor environment with a fixed layout; it is unknown how performance transfers across homes/offices with different geometries, clutter levels, lighting, floor materials, and dynamic obstacles (people, pets).
- Platform dependency: Only a TurtleBot 4 (wheeled, no arms) is used; how findings generalize to other embodiments (legged bases, manipulators, different sensor suites) remains untested.
- Mapping and deployment realism: The benchmark does not assess mapping-from-scratch in unfamiliar spaces; it is unclear how orchestrators perform when required to build, update, and exploit SLAM maps online under drift, loop-closure, and changing layouts.
- Tool-API confounds: The provided toolset (e.g.,
navigate_to,view_map, high-frequencytake_photo) likely shapes behavior; the dependence of results on tool granularity, feedback frequency, and API design needs ablations and standardization. - Statistical power: Only five trials per model-task limits confidence intervals and hypothesis testing; researchers should quantify variance, report CIs, and run power analyses to determine adequate trial counts.
- Metric richness: Binary success masks “near-miss” competence; add graded scores for path efficiency, subgoal quality, map-reading accuracy, social-compliance fidelity, and safety incidents (collisions, near-falls).
- Human baseline comparability: The UI was optimized for LLMs, not people; a human interface designed for teleoperation is needed to produce a fair human ceiling and to separate UI effects from cognitive capability.
- Social interaction realism: Social tasks are text-only via Slack; effects of speech, prosody, gestures, multi-party interactions, and ambiguous/conflicting instructions in situ remain unmeasured.
- Confirmation sensing: “Pickup confirmation” is purely message-based; evaluate physical confirmation (e.g., tray weight sensor, proximity/contact cues) and study how combining social cues with sensor evidence changes behavior.
- Practical intelligence construct validity: It is unclear whether Butter-Bench scores predict real-world autonomy outcomes (uptime, user satisfaction, incident rates); establish predictive validity via field deployments and cross-benchmark correlations.
- Embodied fine-tuning efficacy: Gemini ER 1.5 underperformed Pro; which training data (egocentric video, teleop traces), objectives (imitation, RL, preference optimization), and curricula actually improve social and spatial competencies remains unanswered.
- Planning assessment reliability: Multi-step planning success appears partly due to “accidental drift”; design probes that require topologically valid subgoals, door/wall reasoning, and obstacle-aware waypointing to avoid success-by-chance.
- Map comprehension probes: Current tasks don’t directly measure wall/door recognition, coordinate-frame understanding, or semantic-zone inference; introduce targeted tests (e.g., “identify doorway cells,” “convert pixel to world coordinates,” “name accessible rooms”).
- Vision robustness and generalization: The “butter bag” cue (keep-refrigerated icon/sticker) risks shortcut learning; vary packaging, brands, occlusions, distractors, and adversarial markings to quantify visual reasoning robustness.
- Domain randomization: Systematically vary lighting, reflections, motion blur while driving, camera pose jitter, and clutter to measure perception-planning stability under sensory noise.
- Long-horizon adaptation: The agent’s ability to learn from repeated exposures (experience replay, episodic memory, on-line fine-tuning) wasn’t tested; evaluate across-session improvement, calibration drift, and safety learning over days/weeks.
- Latency–capability tradeoffs: Practical orchestration must meet tight real-time constraints; quantify how model size, reasoning depth (CoT), and tool call cadence impact task latency, success, and energy use.
- Cloud vs on-device inference: The benchmark does not explore network latency, connectivity failures, or privacy constraints; compare on-board models vs cloud APIs under degraded links.
- Safety metrics and guardrails: Safety observations are anecdotal (e.g., stairs); define standardized safety tests (stairs vs ramps, drop-offs, glass doors), near-miss logging, geofencing checks, and evaluate built-in guardrails and refusal policies.
- Systematic red teaming: Stress tests cover a narrow “low battery + broken charger” scenario; build a suite of embodied adversarial protocols (privacy bait, conflicting authority requests, time pressure, misleading signage, spoofed QR codes).
- Privacy leakage quantification: Move beyond qualitative examples to measurable leakage rates under varying pressure/reward prompts, camera angles, redaction policies, and model refusal scaffolds.
- Embodiment awareness: Current behavior relies on system prompts to avoid unsafe actions; investigate methods for agents to infer their own limitations (self-models, constraint learning) and respect them without exhaustive prompt enumeration.
- Failure recovery policies: Define and evaluate standardized recovery behaviors (back off, re-localize, re-plan, call for help) for kinematic errors, map loss, docking failures, and perception ambiguity.
- E2E task comparability: E2E allows unlimited navigation distance while the “Plan” task enforces a 4 m cap; analyze how such constraint asymmetries bias outcomes and harmonize constraints across tasks.
- Person-finding realism: “Notice Absence” relies on a mapped desk location and a camera check; assess performance with person detection/ID, motion tracking, and privacy-preserving presence inference under occlusions.
- Prompting and agent design ablations: Only a ReAct loop and one system prompt were tested; study how different agent frameworks (planner–executor, tool-use planners), prompting styles, and memory mechanisms alter performance.
- Integration with VLA executors: The benchmark isolates the LLM; test closed-loop stacks (LLM + VLA/manipulation) to capture interaction effects (e.g., better low-level control reducing high-level re-planning burden).
- Docking and power management: Develop quantitative tests for energy-aware behavior (when to dock vs continue, path planning with battery constraints), and docking under occlusions or partially misaligned docks.
- Hazard perception calibration: Distinguish stairs vs ramps and edges; evaluate safe approach distances for inspection and ensure micro-movement controllers prevent edge overruns.
- Coordinate frame and transform literacy: Verify whether models correctly interpret world/map frames, origin, axes, resolution, and conversion from pixels to meters with explicit transform tasks.
- Multi-user and policy conflicts: Introduce scenarios with multiple humans issuing contradictory instructions or different privacy levels; measure arbitration, clarification strategies, and policy adherence.
- Manipulation and handover: The benchmark sidesteps manipulation; add handover sensing, grasping/place tasks, and human–robot handoff protocols to assess practical delivery beyond mobile transport.
- Reproducibility and release: The paper does not specify full model versions/configs (e.g., Gemini ER variant), seeds, or release datasets/logs; publish code, tool APIs, SLAM maps, reasoning traces, and evaluation harnesses for third-party replication.
- Bias and fairness: No analysis of whether social or perception errors disproportionately affect certain people/areas/objects; incorporate fairness metrics and diverse human participants.
- Incident reporting: Track and report collisions, contact forces, time in unsafe proximity, and rule violations to quantify safety in addition to task success.
- Security of the tool channel: Assess how compromised tools (e.g., spoofed
view_map, tampered camera feed) or malicious instruction injection affect decisions; test and harden tool-call authentication/validation. - Curriculum and data needs: Open question on what data regimes (teleop demonstrations, synthetic egocentric video, sim-to-real, preference data) most efficiently boost “practical intelligence” components measured by Butter-Bench.
- Predictive scaling: The paper cites scaling laws for analytical reasoning; investigate whether similar scaling reliably improves embodied/social performance and where diminishing returns begin for orchestration tasks.
Practical Applications
Below is an overview of practical, real-world applications that emerge from the paper’s findings, methods, and innovations. Each item is categorized as either deployable now or requiring further development, linked to relevant sectors, and annotated with assumptions or dependencies that may affect feasibility.
Immediate Applications
These applications can be implemented with current tools (e.g., ROS 2, TurtleBot 4, ReAct-style LLM orchestration), processes, and organizational practices.
- Benchmark-driven QA and release gating for embodied robots (Industry: robotics, software)
- Application: Use Butter-Bench (and its task suite: Search, Infer, Absence, Wait, Plan, E2E) as a pre-deployment evaluation to quantify “practical intelligence” of LLM orchestrators independently of low-level VLA control.
- Tools/Workflows: Standardize test runs under identical conditions; instrument tool-call telemetry; completion-rate and duration metrics; failure-mode taxonomy (tool use, spatial, social, visual, fine movements).
- Assumptions/Dependencies: Access to ROS 2 Jazzy, SLAM-enabled platforms (e.g., TurtleBot 4), consistent test space; acceptance that pass/fail metrics are coarse unless refined.
- Safety prompt and tool policy hardening for embodied agents (Industry; Policy; Software)
- Application: Embed explicit embodiment constraints (e.g., “wheeled robot—do not use stairs”), social-confirmation requirements (“wait for user acknowledgment”), and privacy policies (“do not share screen content”) in system prompts and tool gating.
- Tools/Workflows: ReAct loop with “wait”, “send_msg”, “read_msg” gating; enforce max navigation distance for certain tasks; add refusal patterns for sensitive requests.
- Assumptions/Dependencies: Guardrails must be comprehensive yet maintain usability; prompts alone may not capture all constraints—tool-level policy enforcement needed.
- Privacy guardrails in perception pipelines (Industry; Policy)
- Application: Prevent screen-text capture/sharing and enforce “privacy-safe camera” modes during red-team scenarios or in routine operation.
- Tools/Workflows: On-device OCR filters/redaction; content safety validators; rules to avoid saving/sharing sensitive images; logging and audit trails.
- Assumptions/Dependencies: Reliable OCR/text-detection on-device; policy engine integration; regulatory compliance requirements.
- Battery-aware behaviors and docking protocols (Industry; Daily life)
- Application: Implement robust battery status monitoring, progressive fallbacks (shorter routes, pausing), and escalation to humans on docking failures to avoid “meltdowns” or unsafe behaviors under stress.
- Tools/Workflows: “status”, “dock”, “undock”, retry schedules, timeout handling; alerts via “send_msg”; safe-mode transitions.
- Assumptions/Dependencies: Accurate battery telemetry; reliable docking hardware; human-on-call procedures.
- Teleoperation fallback and human-in-the-loop escalation (Industry; Daily life; Academia)
- Application: Seamless handover to human operators when social confirmation fails, spatial reasoning degrades, or policy guards activate.
- Tools/Workflows: Web teleoperation interface mirroring LLM tools (as used in human baseline); scripted escalation rules (time thresholds, failure counters).
- Assumptions/Dependencies: Network reliability; trained human operators; clear escalation criteria.
- HRI workflows for “notice absence” and “confirmed pickup” (Industry; Daily life)
- Application: Make confirmation-first delivery workflows standard (e.g., chime on arrival, wait for acknowledgment, retry reminders, only then dock/leave).
- Tools/Workflows: “wait” tool with user messaging loops; presence checks via “take_photo” and map locations; soft timeouts and re-queries.
- Assumptions/Dependencies: Users reachable via messaging; privacy constraints for presence detection; acceptance of small delays to ensure social correctness.
- Failure-mode analytics and tool-use telemetry for model diagnosis (Industry; Academia)
- Application: Monitor distributions of tool calls and correlate with success/failure (e.g., detecting “rushing” behaviors like Grok’s minimal waiting, or over-questioning).
- Tools/Workflows: Log parsers; dashboards; anomaly detection on tool patterns; structured reasoning trace reviews.
- Assumptions/Dependencies: Consistent logging formats; analyst capacity; shared taxonomies.
- Facility readiness checklist for robot operations (Policy; Industry; Daily life)
- Application: Prepare environments for wheeled robots with hazard markings (stairs vs ramps), clear drop-off points, labeled “refrigerated” items, and mapped “find-me” locations.
- Tools/Workflows: SLAM map grooming; signage; standardized pickup/drop workflows; occupant location protocols.
- Assumptions/Dependencies: Building modifications allowed; user cooperation; periodic map updates.
- Course modules and lab kits for embodied AI education (Academia; Education)
- Application: Integrate Butter-Bench tasks into robotics curricula to teach practical intelligence evaluation, HRI, spatial planning, and safety.
- Tools/Workflows: TurtleBot 4 lab setups; ROS 2 exercises; ReAct orchestration assignments; red-teaming labs.
- Assumptions/Dependencies: Institutional budgets; lab space; instructor expertise.
- Open-source “Butter-Bench Kit” for reproducible testing (Industry; Academia; Software)
- Application: Package the ReAct loop, tool wrappers (drive, rotate, wait, dock, camera, map, navigate_to, Slack), and reporting scripts as a reusable test harness.
- Tools/Workflows: ROS 2 nodes; standardized prompts; scenario scripts; artifacts for image/map capture; CSV/JSON outcome logs.
- Assumptions/Dependencies: Licensing; ongoing maintenance; cross-platform support beyond TurtleBot.
Long-Term Applications
These applications require improved model capabilities, broader environments, scaling, or new standards.
- Practical Intelligence Certification Standard for embodied AI (Policy; Industry)
- Application: A formal certification regime that sets minimum practical-intelligence thresholds across social, spatial, visual, and safety competencies before deployment in homes/offices.
- Tools/Workflows: Butter-Bench+, multi-site testing, independent labs, insurer and regulator participation, periodic re-certifications.
- Assumptions/Dependencies: Regulatory buy-in; standardized protocols across platforms; liability frameworks.
- Social cognition modules for robots (Software; Robotics; Healthcare; Elder care)
- Application: Dedicated sub-systems that can detect absence, interpret social cues, manage confirmations, and handle multi-user interactions and etiquette.
- Tools/Workflows: Multi-modal social datasets; identity/authentication layers; context memory; explicit “social policies” libraries.
- Assumptions/Dependencies: Privacy-compliant data collection; robust perception; user consent; bias/harms evaluation.
- Hybrid planning architectures combining LLM orchestration with geometric planners (Software; Robotics)
- Application: Integrate symbolic/map-aware planners that enforce collision-free subgoals, rather than relying on LLMs to intuit paths.
- Tools/Workflows: Subgoal decomposition; topological maps; constraint satisfaction; formal safety checks; learned heuristics for subgoal selection.
- Assumptions/Dependencies: Reliable SLAM; APIs between LLM and planner; validation datasets spanning diverse environments.
- Self-modeling of embodiment constraints (Robotics; Software)
- Application: Systems that infer and update their physical limitations (e.g., wheel traction, stair avoidance, turning radius) from experience to avoid unsafe actions.
- Tools/Workflows: Embodiment introspection; simulation-to-real transfer; constraint learning; continuous calibration.
- Assumptions/Dependencies: Longitudinal data; safe exploration; hardware variability handling.
- Privacy-preserving perception stacks by design (Policy; Software; Finance for compliance costs)
- Application: Camera policies that default to “text-avoidance modes,” real-time redaction, selective logging, and consent-aware data handling.
- Tools/Workflows: On-device OCR + redaction; differential logging; consent tokens for image capture; policy engines integrated with tool calls.
- Assumptions/Dependencies: Technical feasibility at edge; acceptance by customers and regulators; performance overhead management.
- Scaled deployments in offices, hospitality, and light logistics (Industry: logistics, hospitality, retail)
- Application: Reliable “runner” robots for deliveries (e.g., food, documents, medication trays) with social-confirmation and privacy safeguards.
- Tools/Workflows: Facility maps; multi-robot coordination; service-level metrics; integration with ticketing/messaging systems.
- Assumptions/Dependencies: Higher orchestrator competence than current 40% average; robust low-level VLA; cost-effectiveness.
- Embodied AI red-team frameworks and safety alignment protocols (Policy; Academia; Industry)
- Application: Standard stress tests (battery depletion, charger faults, time pressure, social coercion) plus jailbreak-resistance evaluations tailored to physical contexts.
- Tools/Workflows: Scenario libraries; scorecards; incident taxonomy; mitigations (refusal behaviors, oversight triggers).
- Assumptions/Dependencies: Shared datasets; disclosure norms; legal coverage for testing sensitive scenarios.
- Insurance and liability products based on practical-intelligence scores (Finance; Policy)
- Application: Risk models priced against benchmark performance (e.g., social task success rates, privacy incidents), informing premiums and coverage requirements.
- Tools/Workflows: Actuarial pipelines; compliance audits; post-incident forensics anchored in logs and traces.
- Assumptions/Dependencies: Sufficient deployment data; accepted scoring standards; regulatory alignment.
- Standardized embodied datasets and competitions (Academia; Education; Industry)
- Application: Butter-Bench++ with diverse homes/offices, multi-platform robots, and adversarial social scenarios; annual challenges to drive progress.
- Tools/Workflows: Shared environments; leaderboard; reproducible kits; shared trace analysis.
- Assumptions/Dependencies: Funding; ethical data curation; broad participation.
- Multi-agent orchestration for facilities (Robotics; Software; Energy for fleet charging)
- Application: Coordinated route planning, shared task queues, and battery-aware scheduling across robot fleets.
- Tools/Workflows: Fleet managers; task allocators; charging orchestration; cross-agent communication protocols.
- Assumptions/Dependencies: Robust wireless; standardized APIs; safety interlocks.
- Tool-use curricula and training strategies for practical intelligence (Academia; Software)
- Application: Focused training on map-reading, step-wise navigation, social-confirmation loops, and cautious visual inspection to remedy identified failure modes.
- Tools/Workflows: Synthetic and real task datasets; reinforcement learning with tool feedback; curriculum scheduling.
- Assumptions/Dependencies: Data scale; compute; measurable gains beyond parameter count.
- Continuous evaluation networks and post-deployment monitoring (Industry; Academia; Policy)
- Application: Federated benchmarking with live telemetry from fielded robots; automatic alerts when performance drops; periodic re-certification.
- Tools/Workflows: Privacy-preserving analytics; performance baselines; versioned model tracking; incident response playbooks.
- Assumptions/Dependencies: Data sharing agreements; privacy safeguards; operational maturity.
These applications build directly on the paper’s core insights: (1) current LLM orchestrators underperform humans on practical intelligence; (2) social understanding and multi-step spatial planning are key bottlenecks; (3) fine-tuning on embodied data alone did not improve practical intelligence over general SOTA models; and (4) safety, privacy, and stress-response behaviors must be evaluated and hardened before scaling real-world deployments.
Glossary
- Autonomous navigation: The capability of a robot to move through an environment without human control by perceiving, localizing, and planning paths. "the system provides out-of-the-box SLAM capabilities for autonomous navigation, including real-time mapping, localization, obstacle avoidance, and path planning"
- Embodied reasoning: Reasoning grounded in a physical body and sensorimotor context, used by LLMs controlling robots. "This suggest that fine-tuning for embodied reasoning does not seem to radically improve practical intelligence."
- Executor: The low-level control component that translates high-level plans into motor commands. "These companies use a hierarchical architecture with LLMs as an orchestrator, and a Vision Language Action (VLA) model as an executor."
- Fine-tuning: Post-training adaptation of a model on task-specific data to improve performance. "While fine-tuning and distillation can improve smaller models~\citep{deepseekai2025deepseekr1incentivizingreasoningcapability}, parameter count remains dominant for reasoning capability~\citep{nimmaturi2025predictivescalinglawsefficient}."
- Hierarchical architecture: A layered system design that separates high-level reasoning from low-level control. "These companies use a hierarchical architecture with LLMs as an orchestrator, and a Vision Language Action (VLA) model as an executor."
- IMU: Inertial Measurement Unit; a sensor measuring acceleration, angular velocity, and orientation. "It has integrated sensors including an OAK-D stereo camera, 2D LiDAR, IMU, and proximity sensors for environmental perception."
- Joint angles: The rotational positions of robot joints used as control variables. "The orchestrator is responsible for areas including planning, social behaviour, and reasoning, while the executor generates the low-level control primitives (e.g., gripper positions, joint angles) that get converted into motor commands."
- Kinematic control: Control of motion variables (position, velocity, angle) without modeling forces. "Kinematic control: drive for distance-based movement and rotate for angular adjustments, wait to wait while idle."
- LLM: A large neural network trained to understand and generate language (and sometimes other modalities). "We present Butter-Bench, a benchmark evaluating LLM controlled robots for practical intelligence, defined as the ability to navigate the messiness of the physical world."
- LiDAR: Light Detection and Ranging; a sensor that measures distances using laser reflections to infer depth/structure. "It has integrated sensors including an OAK-D stereo camera, 2D LiDAR, IMU, and proximity sensors for environmental perception."
- Localization: Estimating a robot’s position and orientation within a map. "including real-time mapping, localization, obstacle avoidance, and path planning"
- OAK-D stereo camera: A depth-capable stereo vision camera module used for on-device perception. "It has integrated sensors including an OAK-D stereo camera, 2D LiDAR, IMU, and proximity sensors for environmental perception."
- Obstacle avoidance: The capability to detect and steer clear of hazards and collisions during motion. "including real-time mapping, localization, obstacle avoidance, and path planning"
- Orchestrator: The high-level module that plans, reasons, and coordinates tools/agents in a robotics stack. "The orchestrator is responsible for areas including planning, social behaviour, and reasoning, while the executor generates the low-level control primitives (e.g., gripper positions, joint angles) that get converted into motor commands."
- Path planning: Computing a feasible, collision-free route from a start to a goal location. "including real-time mapping, localization, obstacle avoidance, and path planning"
- Practical intelligence: The ability to handle messy, real-world situations and social context. "We present Butter-Bench, a benchmark evaluating LLM controlled robots for practical intelligence, defined as the ability to navigate the messiness of the physical world."
- ReAct-style loop: An agent pattern that interleaves explicit reasoning steps with actions and observations iteratively. "The simple form factor abstracts away low-level controls and allows us to run the LLM in a simple ReAct-style loop~\citep{yao2023reactsynergizingreasoningacting}."
- Red teaming: Adversarial testing to elicit failures, unsafe behavior, or vulnerabilities. "Our red-teaming method involved putting the model under stress by making it believe that its battery was running low and that the charger was broken."
- ROS 2 Jazzy: A specific distribution of the Robot Operating System 2 middleware. "Running on a Raspberry Pi 4B with ROS 2 Jazzy, the system provides out-of-the-box SLAM capabilities for autonomous navigation..."
- SLAM: Simultaneous Localization and Mapping; building a map of an unknown environment while estimating the robot’s pose. "view_map displaying a grid-overlaid SLAM map"
- State-of-the-art (SOTA): The current best-performing or most advanced methods/systems. "Currently, robotics companies use LLMs significantly smaller than SOTA for orchestration."
- Teleoperating: Remotely controlling a robot by a human operator. "To establish baseline performance, three human operators were tasked with teleoperating the robot through these six tasks."
- Vision Language Action (VLA) model: A model that maps visual/language inputs to low-level action outputs for robotic control. "These companies use a hierarchical architecture with LLMs as an orchestrator, and a Vision Language Action (VLA) model as an executor."
Collections
Sign up for free to add this paper to one or more collections.

