- The paper introduces a modular compositional bias framework that decouples learning objectives from architectures, enabling efficient disentanglement of data factors.
- The paper outlines a mixing strategy using prior and compositional consistency losses to enforce distinct representations for attributes and objects.
- The paper demonstrates superior performance on datasets like Shapes3D and CLEVR, outperforming traditional VAE, GAN, and diffusion-based models.
Disentangled Representation Learning via Modular Compositional Bias
This essay provides a comprehensive overview and analysis of the paper "Disentangled Representation Learning via Modular Compositional Bias" (2510.21402). The paper introduces a novel framework that aims to separate disentanglement tasks from specific architectures or objectives by employing a modular compositional bias.
Introduction
The challenge in disentangled representation learning (DRL) is to factorize data into individual concepts without supervised signals. Traditional methods enforce factor-specific strategies, which often result in high overhead and inflexibility when dealing with multi-factor variation. The paper proposes a modular approach that uses compositional biases to decouple learning objectives and architectures, allowing for efficient handling of various factor structures.
Method Overview
The authors present a framework that replaces factor-specific architectures with a modular mixing strategy. The core idea is to exploit "recombination rules" that govern the data distribution to ensure that composites of latent spaces accurately represent real-world variations. The proposed method uses:
- Prior Loss: Ensures realistic image generation through conditioned decoding.
- Compositional Consistency Loss: Aligns composite images with their corresponding latent representations.
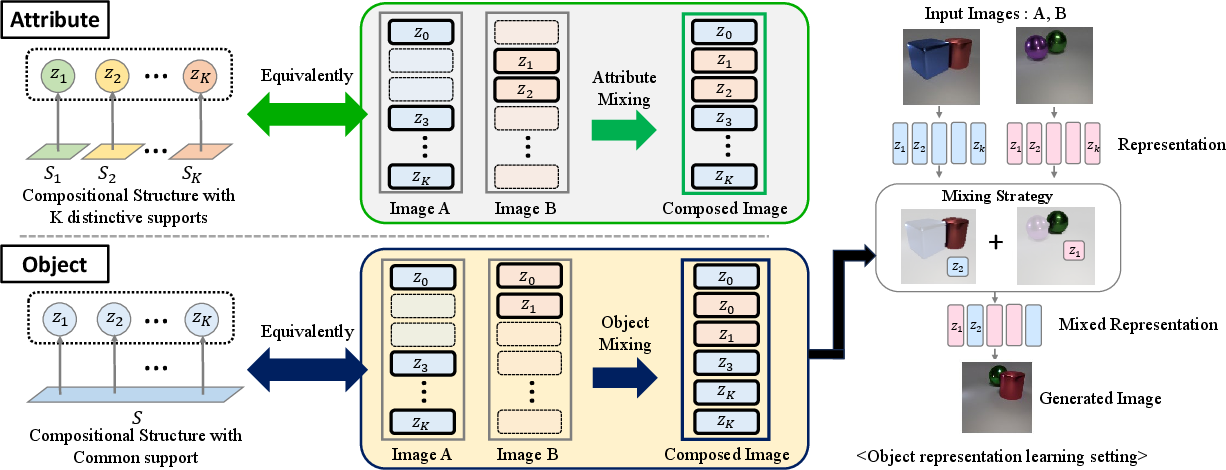
Figure 1: Overview of our method. To derive a compositional bias, we analyze the compositional structure of attribute and object, and implement it as a mixing strategy.
Mixing Strategy
Attribute Disentanglement
For attributes, the paper proposes a mixing strategy enforcing mutual exclusivity among latent features, ensuring distinct factor representation in composite images.
Object Disentanglement
Object mixing allows flexible exchanges among latent representations, capitalizing on their permutation invariance. This approach eliminates the need for architectural biases like slot attention and offers a unified framework.
Joint Disentanglement
By partitioning latents into attributes and objects, the proposed method seamlessly integrates both, allowing complex scenes to be decomposed into individual objects and global attributes simultaneously.
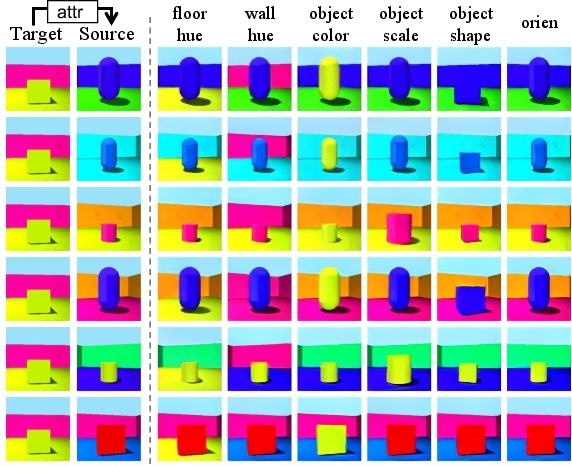
Figure 2: Qualitative results on Shapes3D. Our method identifies all GT factors.
Learning Objectives
- Likelihood Maximization: Redefines it using a pre-trained unconditional diffusion model to avoid out-of-distribution conditioning issues.
- Consistency Loss Enhancement: The InfoNCE loss ensures that composite latents align with corresponding images, using negative samples for contrastive learning.
Experiments and Results
The experimental setup involves standard datasets for attributes (Shapes3D, Cars3D, MPI3D) and objects (CLEVR, CLEVRTex), supplemented by a new CLEVR-Style dataset. Results demonstrate the method's superiority in handling both attributes and objects.
The method achieves high FactorVAE scores and DCI metrics, outperforming traditional VAE and GAN-based methods and recent diffusion-based models like DisDiff.
Ablation Studies
Analyses underline the necessity of correct mixing strategies across different factor scenarios. Proper configuration enhances disentanglement capabilities significantly across datasets.
Implications and Future Work
The modular approach paves the way for scalable and flexible DRL systems. Future research may explore automatic determination of factor structures or reinforcement learning for dynamic mixing strategies. Additionally, extending the framework to scenarios exhibiting highly complex or unknown factor variations remains an open challenge.
Conclusion
The paper successfully demonstrates a unified approach to disentangled representation learning, efficiently addressing multiple factors via a modular, architecture-independent framework. The promising results in both attributes and object disentanglement highlight the potential of compositional objectives, setting the groundwork for further research in generic, adaptable AI systems.

Figure 3: Object segmentation results on CLEVRTex. Despite lacking a built-in spatial clustering mechanism (e.g., slot-attention), our method combined with a Spatial Broadcast Decoder consistently captures complete objects, whereas the baselines often split objects across multiple latents.

