- The paper introduces a novel framework, Tripod, that integrates latent quantization, kernel density estimation for collective independence, and a normalized Hessian penalty to enhance disentanglement performance.
- The methodology stabilizes training by employing fixed grid quantization and minimizes latent interference, achieving state-of-the-art modularity and compactness on benchmark datasets.
- Quantitative and qualitative evaluations demonstrate that Tripod outperforms traditional models like β-TCVAE and QLAE, offering improved interpretability and control over latent representations.
Tripod: Three Complementary Inductive Biases for Disentangled Representation Learning
The research paper explores the potential of integrating three distinct inductive biases to enhance disentangled representation learning within neural networks. By leveraging data compression, collective independence, and minimal interference among latents, the study introduces a method—Tripod—that synergizes these biases for improved disentanglement performance. The paper explores specific modifications crucial for optimizing learning processes and eschewing subpar results from naïve combinations.
Inductive Biases and their Integration
The study focuses on leveraging three previously validated inductive biases for neural network autoencoders:
- Latent Quantization: It employs finite scalar quantization over dictionary learning for organizing data into a structured latent space (Figure 1). This method reduces codebook learning burdens, thereby stabilizing training phases.
- Collective Independence: By implementing kernel density estimation (KDE) for latent multi-information estimation, the approach enhances independence among latents by reinforcing distribution invariance despite scale disparities among dimensions (Figure 2).
- Minimal Latent Interference: This research adjusts the Hessian penalty to avoid degeneracies in disentangled model frameworks. The modifications ensure each latent minimally affects the functional influence of others, thereby promoting optimal data generation dynamics (Figure 3).
These integrated biases comprise the Tripod model, which aims to balance and optimize the inductive influences—latent pre-specification, autoencoder structure, and data generation mapping—delivering superior results in disentanglement benchmarks.
Technical Contributions
Several technical adaptations are pivotal to the proposed method:
- Finite Scalar Latent Quantization (FSLQ): FSLQ eliminates the need for adaptive codebooks by quantizing latent values over a fixed grid (Equation 6). This simplification mitigates early-stage instabilities during the model's training phase.
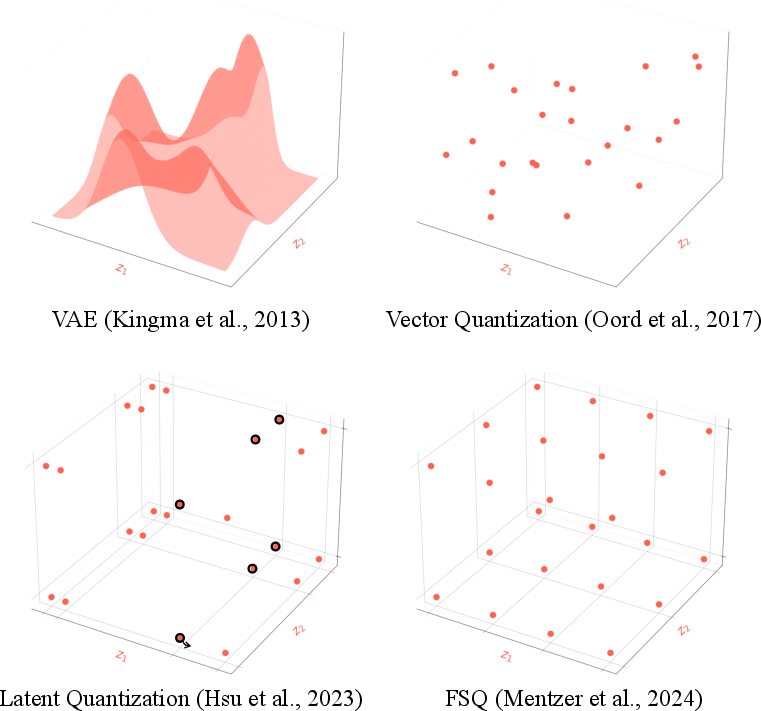
Figure 1: The evolution of discrete latent space structure in autoencoders. We use finite scalar quantization (bottom right) instead of latent quantization (bottom left) so that the codebook values need not be learned.
- Kernel-Based Latent Multiinformation: Kernel density estimation ensures latent independence-oriented regularization is effective for deterministic encoders, facilitating gradient-based optimizations (Equation 8).
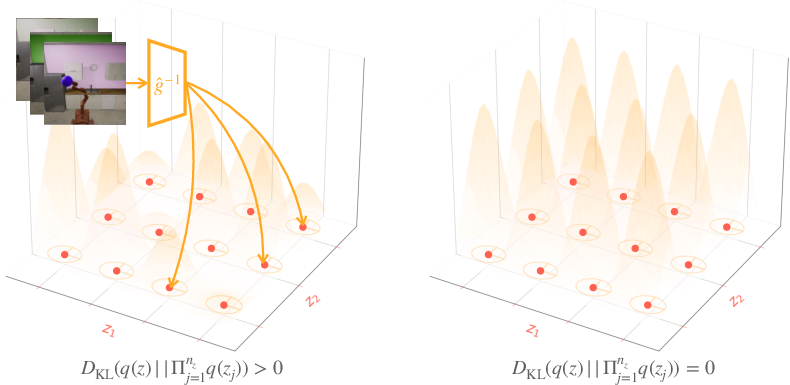
Figure 2: Kernel density estimation facilitates regularizing deterministic quantized latents from having nonzero multiinformation (left) towards collective independence (right).
- Normalized Hessian Penalty (NHP): This version normalizes mixed derivatives in data-generating mappings, quelling degeneracies by adhering to scale-invariance among inputs and outputs, bolstering disentanglement efficacy (Figure 3).
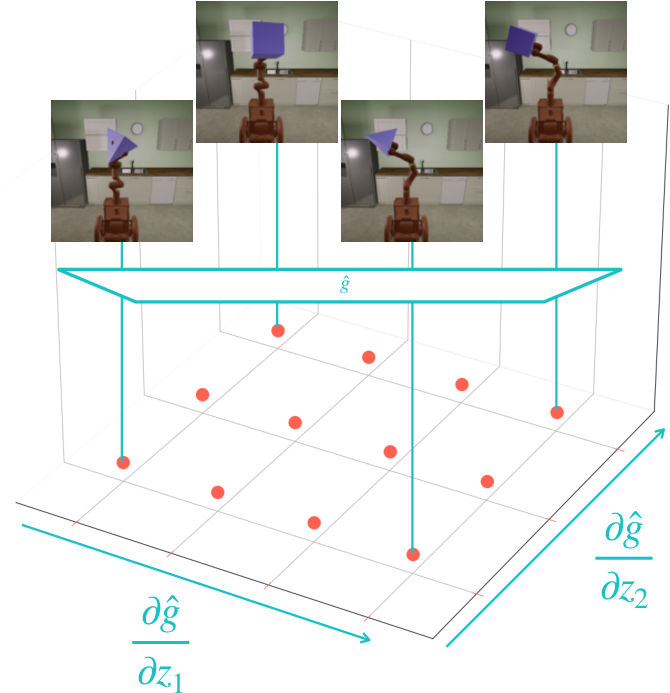
Figure 3: The Hessian penalty is supposed to specify a preference for decoders in which change along one latent minimally affects how another latent influences data generation.
Together, these innovations address optimization challenges inherent in multi-objective deep learning scenarios and foster impressive disentanglement capabilities in various benchmark settings such as Shapes3D, MPI3D, Falcor3D, and Isaac3D.
Quantitative and Qualitative Evaluation
The model sets new state-of-the-art performance on four benchmark datasets designed to reflect true data-generating processes conducive to disentanglement (Table 1). The supervised evaluation with InfoMEC and DCI metrics demonstrates significant gains over traditional models like β-TCVAE and QLAE, especially in modularity and compactness measures.
Additionally, qualitative studies (Figure 4) illustrate consistent and interpretable latent manipulation effects, reinforcing the quantitative metrics.


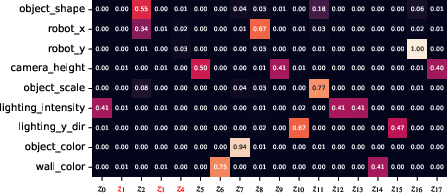
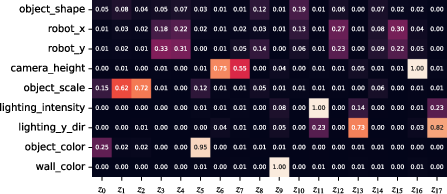
Figure 4: Decoded latent interventions and normalized mutual information heatmaps for Tripod and naive Tripod on Isaac3D.
Conclusion
The integration of multiple inductive biases in the Tripod model forms a robust framework for disentangled representation learning, harmonizing distinct yet synergistic influences to overcome inherent deep learning challenges. While computational demands rise due to the complexity of combined biases—particularly from the NHP component—Tripod showcases remarkable advancements in representation modularity, compactness, and explicitness. The study's findings amplify the understanding of disentanglement mechanics and chart a course for future improvements in handling high-dimensional, unlabeled data challenges across various domains.