Real Deep Research for AI, Robotics and Beyond
Abstract: With the rapid growth of research in AI and robotics now producing over 10,000 papers annually it has become increasingly difficult for researchers to stay up to date. Fast evolving trends, the rise of interdisciplinary work, and the need to explore domains beyond one's expertise all contribute to this challenge. To address these issues, we propose a generalizable pipeline capable of systematically analyzing any research area: identifying emerging trends, uncovering cross domain opportunities, and offering concrete starting points for new inquiry. In this work, we present Real Deep Research (RDR) a comprehensive framework applied to the domains of AI and robotics, with a particular focus on foundation models and robotics advancements. We also briefly extend our analysis to other areas of science. The main paper details the construction of the RDR pipeline, while the appendix provides extensive results across each analyzed topic. We hope this work sheds light for researchers working in the field of AI and beyond.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a tool called Real Deep Research (RDR). It helps scientists keep up with the huge number of new papers in AI and robotics. Instead of reading thousands of papers by hand, RDR automatically collects, organizes, and analyzes them to find:
- What topics are growing or fading
- How different fields connect (like AI and robotics)
- Good starting papers to read for any topic
Think of it like building a smart, always-up-to-date map of the research world.
What questions does the paper try to answer?
The authors ask simple but important questions:
- How can we quickly understand a big, fast-changing research area?
- Which topics are becoming popular, and which are slowing down?
- Where are the best opportunities to connect ideas across different fields?
- If you want to start researching something new, which papers should you read first?
How does RDR work? (Methods explained simply)
RDR follows a step-by-step process. Here’s the idea in everyday language:
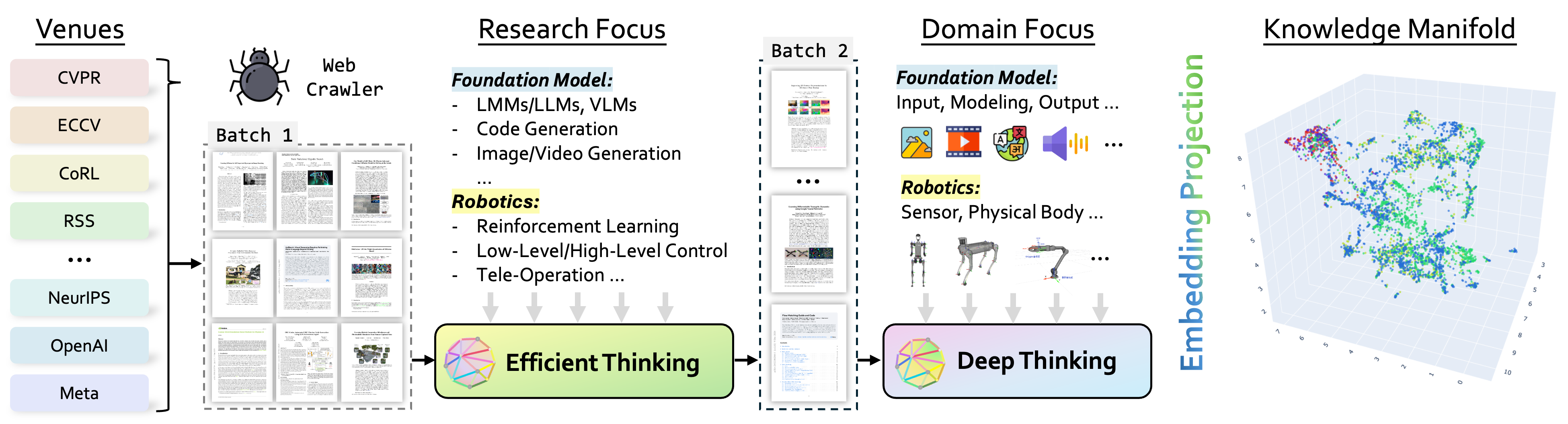
- Data preparation: It collects papers from top conferences (like CVPR, ICLR, NeurIPS, ACL, CoRL, RSS) and company research pages (like NVIDIA, Meta, OpenAI). Then it uses an AI to check if each paper is relevant to foundation models (big, general-purpose AI systems) or robotics.
- Content reasoning: Instead of reading the whole paper, RDR pulls out the most important parts using clear “perspectives.” It’s like reading with a checklist.
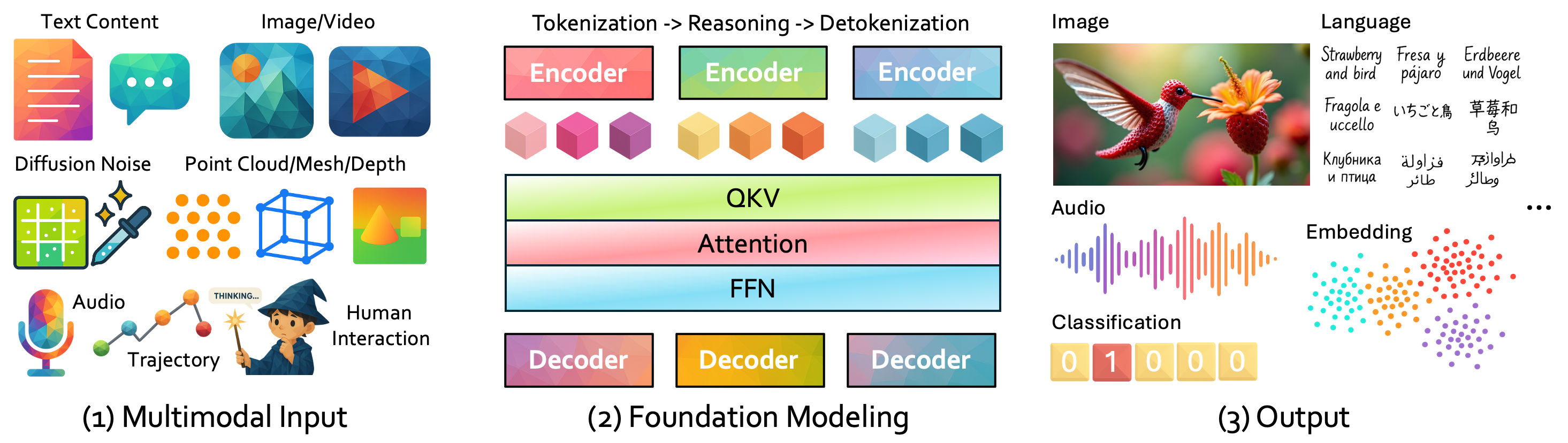
- Input: What data goes in (images, text, audio, etc.)
- Modeling: How the AI is built to understand and reason
- Output: What the AI produces (answers, actions, labels)
- Objective: What the AI is taught to do (its training goal)
- Recipe: How it’s trained (steps, settings, tricks)
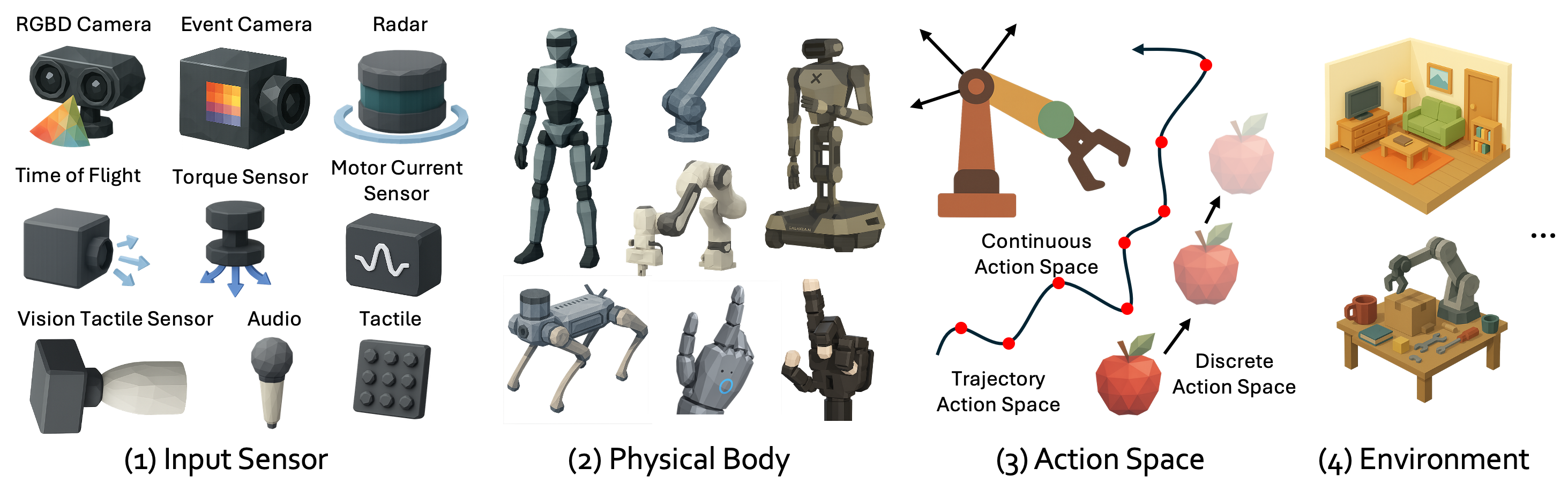
For robotics, it looks at: - Sensor: How the robot senses the world (cameras, touch, LiDAR) - Body: The robot’s physical parts (arms, legs, grippers) - Joint output: How its joints move when it acts - Action space: What actions it can choose (from simple motor commands to high-level tasks like “grasp”) - Environment: Where it operates (home, lab, outdoors)
- Content projection: RDR turns the paper text into “embeddings.” Imagine each paper becomes a point on a huge map where nearby points are about similar topics. This makes it easier to find patterns and groups.
- Embedding analysis: It groups similar papers together (“clustering”) and asks an AI to summarize each group with a few keyword phrases. Then it creates a structured survey of the field based on these clusters, shows trends over time, draws a “knowledge graph” of cross-field connections, and lets you search for the most relevant high-impact papers for any topic.
In short: RDR collects → understands → maps → groups → summarizes → shows trends → finds great papers.
What did they find, and why does it matter?
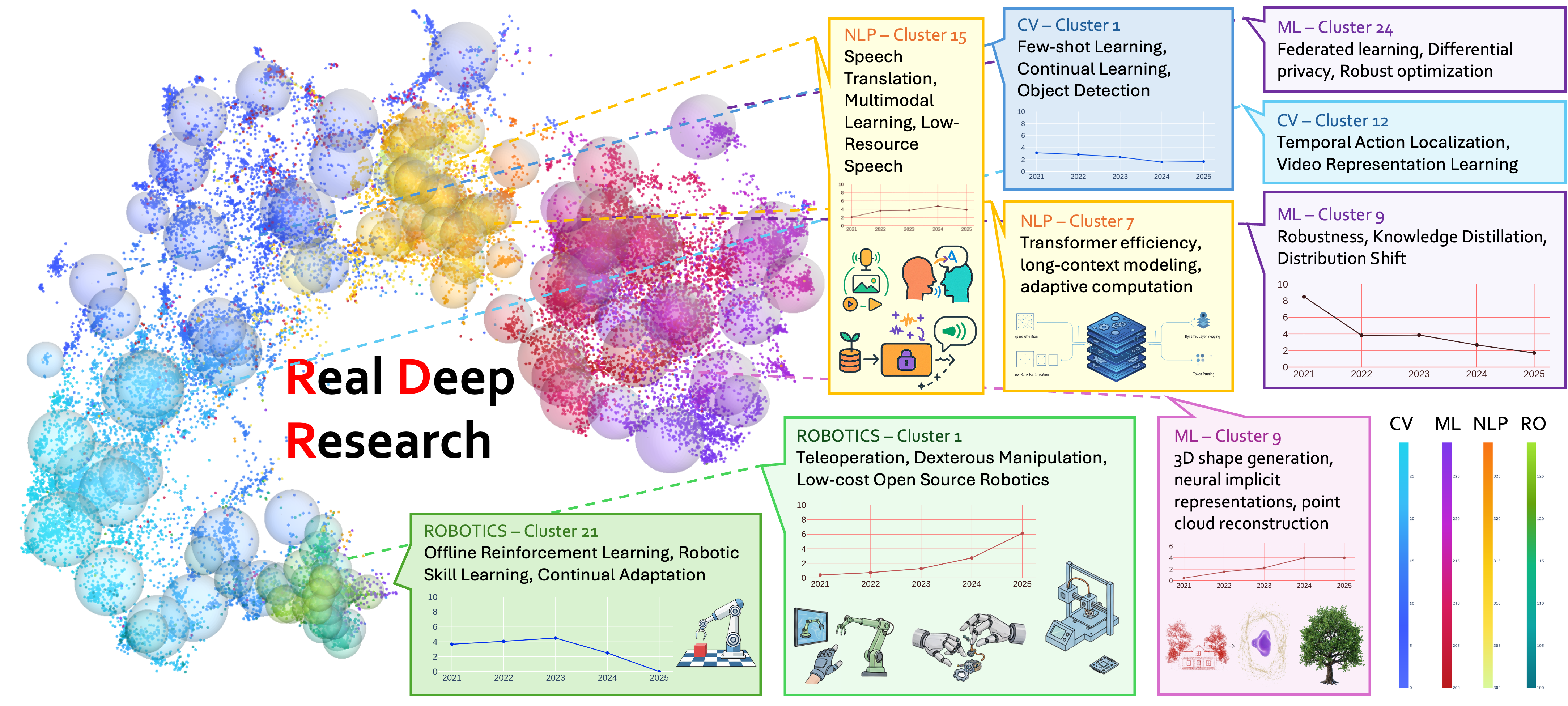
- RDR builds useful maps of research topics: It can automatically create surveys, track trends, and show how areas like computer vision, NLP, machine learning, and robotics connect.
- Clear trends in robotics: Topics like teleoperation (controlling robots remotely), dexterous manipulation (fine, human-like hand control), and low-cost open-source robotics are rising. Older styles of reinforcement learning (a training method) seem to be slowing down.
- Better than other tools: In tests with expert researchers, RDR’s surveys and analyses were rated higher than those from popular commercial AI tools. Its topic grouping and embeddings (the “map points”) also performed very well compared to other methods.
- Practical retrieval: If you search for a topic like “dexterous manipulation,” RDR returns focused, high-impact papers from top venues—great starting points for a new project.
Why this matters: Scientists and students can avoid getting lost in thousands of papers. RDR points them to what’s hot, what’s connected, and where to begin.
What’s the impact?
- Faster learning: Newcomers (and busy experts) can quickly understand a field without reading everything.
- Smarter planning: Teams can choose projects in growing areas and find gaps where new ideas are needed.
- More collaboration: The cross-domain maps make it easier to spot connections between fields (like combining LLMs with robot control).
- Beyond AI and robotics: The same pipeline can be used to analyze other scientific areas in the future.
Bottom line: RDR is like a smart research compass. It helps you find your way, choose promising directions, and get started with the best possible papers—without getting overwhelmed.
Knowledge Gaps
Below is a single, consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions that future researchers could address.
- Quantify and report the accuracy of the Area Filtering step (e.g., precision/recall, F1) against a human-labeled benchmark to validate LLM-based inclusion/exclusion of papers.
- Release full prompt templates, LLM model versions, temperature/decoding settings, and any post-processing rules to enable reproducibility of perspective extraction and clustering.
- Provide an explicit, formal method for determining the number of clusters k (e.g., silhouette score, BIC/AIC, stability analyses) and assess sensitivity of results to k.
- Evaluate topic label generation robustness by comparing LLM-produced cluster keywords against human-curated labels (topic coherence, intruder tests, inter-annotator agreement).
- Formalize trend analysis: define the metric of “momentum,” the time windowing, smoothing/normalization, and statistical significance tests for trend changes and comparisons across topics.
- Move from descriptive trends to predictive modeling: test forecasting methods (e.g., temporal embeddings, Hawkes processes, diffusion of innovations) and validate out-of-sample predictive accuracy.
- Specify how the Cross-Domain Topology Graph is constructed (edge definition, similarity thresholds, graph sparsification, community detection), and assess its stability across parameter choices.
- Benchmark retrieval quality with standard IR metrics (MAP, nDCG@k, Recall@k) across diverse queries, and compare against baselines like Semantic Scholar, Google Scholar, and domain search engines.
- Assess generalizability beyond AI/robotics by applying the pipeline at scale to at least one natural or formal science domain, with complete end-to-end evaluation and domain-expert review.
- Address venue and time-range biases: quantify coverage gaps (e.g., arXiv-only works, journals, workshops, non-top-tier venues) and measure how inclusion/exclusion alters trend conclusions.
- Include non-English and multilingual literature; evaluate how language affects embedding quality, clustering, and retrieval in international research ecosystems.
- Detail PDF parsing and content extraction: how figures, tables, math, and supplementary materials are handled; measure the impact of multimodal content on perspective accuracy.
- Incorporate multimodal embeddings (images, tables, diagrams) and ablate their contribution versus text-only embeddings on clustering coherence and retrieval performance.
- Perform embedding model ablations (e.g., NV-Embed-v2 vs open-source alternatives) and quantify effects on clustering stability, topic coherence, and retrieval metrics.
- Report computational cost, latency, and scaling characteristics (per 10k/100k papers): end-to-end profiling, memory footprints, incremental update strategies, and streaming ingestion.
- Implement and evaluate continuous update mechanisms (concept drift detection, model re-indexing cadence, incremental clustering) to maintain up-to-date analyses.
- Quantify LLM hallucination and extraction errors in perspective mapping with a labeled test set; introduce confidence scoring and human-in-the-loop verification where needed.
- Expand the user study: increase sample size, diversify expert panels across subdomains, pre-register evaluation protocols, and measure inter-rater reliability to reduce evaluator bias.
- Clarify baseline models and naming (e.g., “GPT5,” “GPT5-Thinking”) to ensure they correspond to accessible, documented systems; otherwise, replace with verifiable baselines.
- Validate claims about topic trajectories (e.g., “RL declining”) by triangulating multiple signals (publication volume, citation velocity, funding trends) and performing causal analyses.
- Audit citation-based “impact” signals for recency and field normalization (e.g., citations per year, field/venue normalization) to reduce bias toward older or larger subfields.
- Provide rigorous de-duplication and metadata hygiene (author disambiguation, venue normalization, versioning of preprints) and quantify their effects on clustering/trends.
- Align perspective taxonomies with established ontologies (e.g., ACM CCS, robotics taxonomies); resolve symbol inconsistencies (e.g., Physical Body noted as B vs P) and test inter-annotator agreement.
- Examine ethical and fairness issues: quantify domain/region/gender/institutional biases in retrieval and clustering; propose mitigation strategies and audit procedures.
- Release code, data artifacts (embeddings, cluster assignments, prompts), and complete reproducibility instructions; include versioned snapshots to support longitudinal comparisons.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that organizations and individuals can implement today using the paper’s Real Deep Research (RDR) pipeline and insights.
- Research intelligence dashboards for R&D teams
- Sectors: software, robotics, semiconductors, autonomy
- What: Automated ingestion of conference/company papers, area filtering via prompts, perspective tagging (e.g., Foundation Model: Input/Modeling/Output; Robotics: Sensor/Body/Action), embedding-based clustering, trend heatmaps, and semantic reading lists
- Emergent tools/workflows: RDR dashboard; weekly auto-updated “living surveys”; topic momentum tracker; targeted paper retrieval
- Assumptions/dependencies: Reliable web crawling and PDF parsing; access to LLM/LMM APIs (e.g., o3, Doubao) and embedding models (e.g., NV-Embed-v2); human-in-the-loop for QA; coverage limited to selected venues
- Living surveys and onboarding kits for academic labs and courses
- Sectors: academia, education
- What: Perspective-informed, always-up-to-date surveys for foundation models and robotics; curated syllabi and starter reading packs for new students and researchers
- Emergent tools/workflows: Course syllabus generators; lab onboarding bundles; perspective-specific primers (e.g., FM Input/Modeling)
- Assumptions/dependencies: Domain prompts quality; periodic refresh; institutional repository integration
- Funding/portfolio prioritization radar for agencies and investors
- Sectors: public funding bodies, venture capital, corporate strategy
- What: Trend analysis to spotlight rising areas (e.g., teleoperation, dexterous manipulation, open-source robotics) and de-emphasize saturated ones (e.g., traditional RL)
- Emergent tools/workflows: Grant call topic selection; portfolio rebalancing; horizon-scanning reports
- Assumptions/dependencies: Representative literature coverage; avoidance of venue/discipline bias; expert oversight to interpret momentum correctly
- Dynamic topic maps and navigation for conferences and publishers
- Sectors: scientific publishing, events
- What: Clustered topic maps to help attendees/readers navigate sessions and proceedings; keyword overlays; cross-session linkage
- Emergent tools/workflows: Conference explorer; “follow a topic” alerts; proceedings navigator
- Assumptions/dependencies: Timely metadata; permissions; stable clustering across updates
- Cross-domain collaboration finder
- Sectors: academia, corporate research, consortia
- What: Knowledge graph surfaces central cross-domain nodes (e.g., language-conditioned manipulation, VLA models) to match teams across CV/NLP/ML/Robotics
- Emergent tools/workflows: Collaboration matchmaking; seed workshops; shared grant proposals
- Assumptions/dependencies: Graph reliability; institutional willingness; minimal data silos
- Semantic literature retrieval for targeted project scoping
- Sectors: software, robotics, academia
- What: Embedding-based search to retrieve high-impact, query-aligned papers (e.g., “dexterous manipulation generated data in 3D simulation and evaluated in real world”)
- Emergent tools/workflows: Project scoping queries; citation shortlist generators; venue-aware filters
- Assumptions/dependencies: High-quality embeddings; effective query formulation; periodic index refresh
- Competitive intelligence for product roadmapping
- Sectors: robotics, autonomy, AI platforms
- What: Monitor competitor labs’ directions and community shifts; translate trend signals into product features (e.g., teleoperation toolkits; open-source robotics support)
- Emergent tools/workflows: Product radar; quarterly tech briefings; roadmap adjustments
- Assumptions/dependencies: Balanced corpus beyond academia; legal/IP review; avoid overfitting to hype cycles
- Reviewer assignment and program committee support
- Sectors: publishing, conferences
- What: Use clusters and keywords to match papers with appropriate reviewers; identify conflicts via author/topic proximity
- Emergent tools/workflows: Reviewer recommender; conflict-of-interest detector
- Assumptions/dependencies: Accurate author disambiguation; privacy/compliance; stable topic taxonomies
- Library and research services enhancement
- Sectors: university libraries, corporate knowledge management
- What: Subject guides and discovery portals powered by RDR embeddings and perspectives; personalized reading lists for staff/students
- Emergent tools/workflows: Library discovery layer; “2-hour topic primer” service
- Assumptions/dependencies: Repository integration; librarian curation; multilingual support for broader adoption
- Safety and risk monitoring in autonomous systems
- Sectors: transportation, robotics safety, compliance
- What: Identify safety-critical topic clusters (e.g., trajectory prediction, safety scenario generation) and track evidence bases for compliance/internal audits
- Emergent tools/workflows: Safety evidence dashboards; compliance checklists; incident-relevant literature packs
- Assumptions/dependencies: Coverage of safety literature; risk taxonomy alignment; human review
Long-Term Applications
Below are forward-looking applications that require further scaling, research, institutional integration, or productization before broad deployment.
- Predictive topic forecasting and early-warning systems
- Sectors: corporate strategy, public policy, meta-research
- What: Model trajectories and graph centrality to forecast emerging topics and likely inflection points, enabling proactive investment and policy moves
- Emergent tools/workflows: Forecast dashboards; scenario planning; “risk/opportunity” heatmaps
- Assumptions/dependencies: Historical baselines; robust time-series modeling; bias correction; validation against outcomes
- Autonomous research agents that close the loop from discovery to prototyping
- Sectors: software, robotics, applied AI
- What: Integrate RDR (trend/gap detection) with code-generation and sim-to-real tooling to propose experiments, generate baseline code, and plan evaluations
- Emergent tools/workflows: ResearchOps pipelines; experiment planners; agentic prototyping
- Assumptions/dependencies: Strong LLMs/LMMs for reliable reasoning; sandbox compute; safety guardrails; reproducibility infrastructure
- Cross-domain discovery pipelines in healthcare and materials
- Sectors: healthcare, pharma, materials science, energy
- What: Apply RDR to biomedical/chemical corpora to surface intersections (e.g., foundation models + medical imaging; robotics + lab automation)
- Emergent tools/workflows: Translational opportunity finders; clinical/lab workflow matchers; preclinical evidence maps
- Assumptions/dependencies: Domain adaptation of perspectives; access to specialized corpora; clinical regulatory constraints; expert validation
- Funding allocation simulation and policy design
- Sectors: government, philanthropic foundations
- What: Use topic momentum and cross-domain centrality to simulate different funding strategies and expected ecosystem impact
- Emergent tools/workflows: Grant portfolio simulators; policy impact models; fairness/equity metrics
- Assumptions/dependencies: Causal model calibration; longitudinal data; stakeholder input; transparency standards
- Global research equity and inclusion analytics
- Sectors: policy, international development, academia
- What: Map under-connected nodes/regions to identify overlooked research communities and support equitable capacity-building
- Emergent tools/workflows: Equity dashboards; multilingual ingestion pipelines; targeted funding recommendations
- Assumptions/dependencies: Non-English coverage; institution/geography metadata; ethical data use; community engagement
- Standards and benchmarking via perspective frameworks
- Sectors: robotics, AI evaluation, consortia
- What: Use action-space and foundation-model perspective taxonomies to propose community standards and create benchmark suites
- Emergent tools/workflows: Taxonomy working groups; benchmark creation platforms; longitudinal evaluation tracks
- Assumptions/dependencies: Community buy-in; neutral governance; continual maintenance
- Real-time conference copilots and personalized routing
- Sectors: events, publishing
- What: On-device or cloud copilots that guide attendees to sessions/papers matching their interests and emerging trends
- Emergent tools/workflows: Live graph navigation; “meet collaborators” suggestions; dynamic schedules
- Assumptions/dependencies: Reliable streaming updates; device privacy; venue APIs; stable UI/UX
- National/sectoral curriculum planning
- Sectors: education policy, workforce development
- What: Use RDR trend signals to plan AI/robotics curricula over 3–5 years (e.g., emphasize teleoperation, dexterous manipulation, multimodal foundation models)
- Emergent tools/workflows: Curriculum foresight tools; educator training kits; assessment alignment
- Assumptions/dependencies: Policy cycles; teacher capacity; stakeholder consultation; accessibility
- Patent landscaping fusion with scholarly embeddings
- Sectors: IP strategy, finance, venture capital
- What: Combine RDR paper embeddings with patent corpora to find white spaces and commercialization routes
- Emergent tools/workflows: Tech landscape maps; freedom-to-operate screens; investment due diligence enhancers
- Assumptions/dependencies: Patent data access; cross-corpus alignment; legal review; noise handling
- Regulatory horizon scanning for AI/robotics
- Sectors: government, compliance, safety
- What: Identify nascent risk areas (e.g., safety-critical robotics, autonomous driving simulation) and align with evolving standards
- Emergent tools/workflows: Regulatory change detectors; conformity assessment planners; standards-linking knowledge graphs
- Assumptions/dependencies: Integration with standards/regulatory feeds; expert interpretation; policy feedback loops
- SaaS productization of the RDR pipeline
- Sectors: software, research analytics
- What: Turn RDR into a multi-tenant platform offering ingestion, perspective tagging, clustering, trend analysis, knowledge graph exploration, and semantic retrieval
- Emergent tools/workflows: Admin consoles; API endpoints; custom perspective templates; enterprise SSO and governance
- Assumptions/dependencies: Scalability; data privacy/security; uptime SLAs; multi-corpus support
Notes on feasibility and dependencies across applications
- Technical dependencies: Access to robust LLM/LMM APIs and high-quality embedding models; reliable web/data ingestion pipelines; compute resources; PDF/metadata parsers.
- Methodological assumptions: Quality of domain-specific prompts and perspective taxonomies; stability and interpretability of clustering over time; human expert oversight to mitigate bias and hallucination.
- Data coverage: Current pipeline is tuned to major AI/robotics venues; broader impact requires expanding corpora (including non-English and industry technical reports) and ensuring equitable coverage.
- Governance and ethics: IP/compliance when crawling and indexing; privacy for reviewer assignment and collaboration tools; transparency in funding/policy analytics; avoidance of hype-driven misallocation.
- Maintenance: Sustained updates for models, corpora, and taxonomies; monitoring trend drift; periodic validation against real-world outcomes and expert feedback.
Glossary
- 3-D Occupancy: A voxelized representation indicating whether 3D space cells are free or occupied, used for mapping and perception. "3-D Occupancy"
- 3-D SLAM: Simultaneous Localization and Mapping in three dimensions; building a map while estimating the agent’s pose. "3-D SLAM {paper_content} Reconstruction"
- 3D Scene Grounding: Linking natural language or symbols to objects and regions in a 3D environment. "3D Scene Grounding"
- Action Space: The set of all allowable actions a robot or agent can take, from low-level motor commands to high-level behaviors. "The action space is the set of all permissible actions a robot can select in a given context"
- Adjusted Rand Index (ARI): A clustering similarity metric adjusted for chance, measuring agreement between two partitions. "ARI()"
- BEV (Bird’s-Eye View): A top-down map-like representation of a scene commonly used in autonomous systems. "BEV / top-view mapping"
- Cross-Domain Topology Graph: A graph connecting topic clusters across multiple research domains to reveal interdisciplinary relationships. "Cross-Domain Topology Graph"
- Dexterous Manipulation: Fine-grained, coordinated robotic hand control for in-hand object manipulation. "Dexterous Manipulation"
- Embedding index: A searchable index of vector embeddings used to retrieve semantically similar documents or concepts. "query the embedding index"
- Embedding space: A high-dimensional vector space where semantically similar texts or papers lie close together. "embedding space"
- Foundation Models: Large pre-trained models (often transformer-based) that generalize across tasks and domains and can be adapted to many downstream applications. "foundation models"
- High-Dimensional Manifold: The underlying continuous structure in which embeddings reside, capturing semantic relationships. "high-dimensional manifold"
- Imitation Learning: A paradigm where models learn policies from demonstrations rather than explicit reward signals. "Imitation Learning for physical systems ..."
- Input Sensor: Hardware that measures environmental quantities and converts them to digital signals for robot perception. "Input Sensor ($\mathbf{S$)."
- Joint Output: The realized motion or configuration at a robot’s joints produced by executing control commands. "Joint Output ($\mathbf{J$)."
- Knowledge Graph: A structured representation of entities and their relationships used to organize and explore knowledge. "Knowledge Graph."
- LLMs: Large-scale neural models trained on text to perform language understanding and generation. "LLMs"
- Large Multimodal Models (LMMs): Models that process and reason over multiple modalities (e.g., text, images, audio, video). "Large Multimodal Models (LMM)"
- Latent Representation: Internal vector features learned by a model that encode abstract information about inputs. "latent representation"
- Latent Space: The abstract space of latent representations where proximity reflects semantic similarity. "latent space"
- LiDAR: Light Detection and Ranging sensor that measures distance by illuminating targets with laser light. "LiDAR"
- Linear Probe: A simple linear classifier trained on top of frozen embeddings to evaluate representation quality. "linear probe"
- Multimodal Sensor Fusion: Combining heterogeneous sensors (e.g., LiDAR, radar, cameras) for richer scene understanding. "Multimodal sensor fusion"
- NMI (Normalized Mutual Information): A normalized measure of similarity between clusterings based on mutual information. "NMI()"
- Offline Reinforcement Learning: Learning policies from fixed datasets without further environment interaction. "Offline Reinforcement Learning, Robotic Skill Learning, Continual Adaptation"
- Open-Source Robotics: Robotics platforms and tools whose designs or code are publicly available to promote accessibility and collaboration. "open-source robotics"
- Perspective Projection: Mapping extracted paper content into embeddings conditioned on predefined analytical perspectives. "perspective projection"
- Pseudo-labels: Automatically generated labels used to supervise training when ground truth labels are unavailable. "uses pseudo-labels during training"
- Pseudo-supervised: A training setup using automatically generated or weak labels rather than fully curated ground truth. "pseudo-supervised SciTopic model"
- Reinforcement Learning: Learning to act via trial-and-error feedback signals (rewards), widely used in robotics control. "Reinforcement Learning in robotic contexts"
- Semantic Reasoning: Reasoning over meaning and context (beyond lexical matching) to interpret or organize information. "semantic reasoning"
- Semantic Search: Retrieval based on meaning using embeddings rather than exact keyword matching. "semantic searches"
- Sim-to-Real Transfer: Transferring models or policies trained in simulation to real-world systems. "Sim-to-Real Transfer"
- Teleoperation: Remote control of a robot by a human operator, often used to collect demonstrations or perform complex tasks. "Teleoperation"
- Tokenization: The process of converting raw input data into discrete tokens for model consumption. "tokenization procedure"
- V2X (Vehicle-to-Everything): Communication between vehicles and external entities (infrastructure, other vehicles, devices) to enhance perception and safety. "V2X Cooperative Perception"
- Vision-Language-Action Models: Models that connect perception (vision), instruction (language), and control (action) for embodied tasks. "Vision-Language-Action Models"
Collections
Sign up for free to add this paper to one or more collections.