- The paper introduces a systematic taxonomy classifying AI4Research into five key areas: scientific comprehension, academic survey, discovery, writing, and peer review.
- The paper details advanced AI methodologies such as automated text and data comprehension, semantic literature retrieval, and hypothesis generation to accelerate research workflows.
- The paper highlights promising future directions including interdisciplinary models, ethics in AI, and multimodal integration to enhance the impact of AI-driven research.
AI4Research: A Comprehensive Survey
This paper presents a survey of AI for Research (AI4Research), motivated by the recent advancements in AI, particularly in LLMs. It addresses the absence of a comprehensive survey in this field, which the authors argue hinders understanding and impedes further development. The survey provides a systematic taxonomy to classify mainstream tasks in AI4Research, identifies key research gaps, and highlights promising future directions, focusing on the rigor and scalability of automated experiments, as well as societal impact. Furthermore, the paper compiles a wealth of resources, including relevant multidisciplinary applications, data corpora, and tools.
Systematic Taxonomy of AI4Research
The authors introduce a systematic taxonomy (Figure 1) categorizing AI4Research into five key areas:
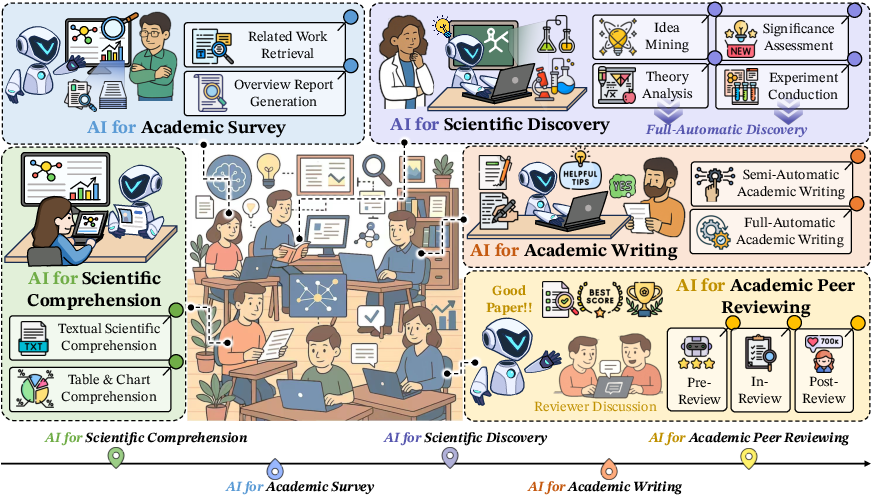
Figure 1: The mainstream processes and categories of AI4Research, which can be divided into five key areas: (1) AI for Scientific Comprehension, (2) AI for Academic Survey, (3) AI for Scientific Discovery, (4) AI for Academic Writing, and (5) AI for Academic Peer Review. Each of these areas contributes to improving the effectiveness and efficiency of AI-integrated research and publication.
- AI for Scientific Comprehension: Focuses on AI systems' ability to extract relevant information from scientific literature.
- AI for Academic Surveys: Involves AI techniques for systematically reviewing and summarizing scientific literature.
- AI for Scientific Discovery: Employs AI to generate hypotheses, theories, or models based on existing scientific knowledge.
- AI for Academic Writing: Provides AI tools to support researchers in drafting, editing, and formatting manuscripts.
- AI for Academic Reviewing: Assists in evaluating and providing feedback on scientific manuscripts.
This categorization provides a structured overview of how AI can augment and, in some cases, automate various stages of the research process. This framework is essential for understanding the current landscape and identifying opportunities for future research.
AI for Scientific Comprehension
This section elaborates on the role of AI in scientific comprehension, categorized into Textual Scientific Comprehension and Table & Chart Scientific Comprehension (Figure 2).
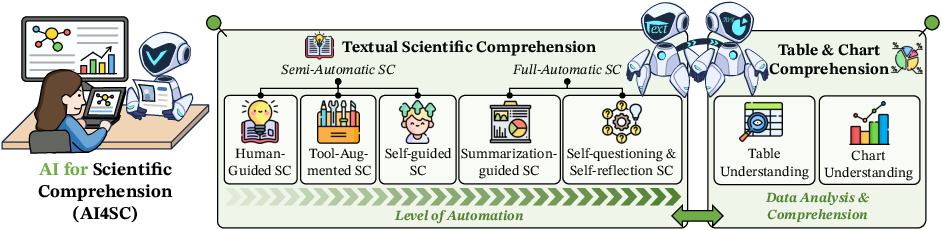
Figure 2: The primary paradigms of AI for Scientific Comprehension. These include: (1) Textual Scientific Comprehension, which is further categorized into Semi-Automatic and Fully-Automatic Scientific Comprehension; and (2) Table {additional_guidance} Chart Scientific Comprehension, encompassing Table and Chart Understanding.
Textual Scientific Comprehension is further divided into Semi-Automatic and Fully-Automatic approaches, addressing the nuances of AI-assisted versus autonomous understanding of scientific texts.
AI for Academic Survey
The authors discuss AI-driven approaches to academic surveys, focusing on two primary stages: Related Work Retrieval and Overview Report Generation (Figure 3).
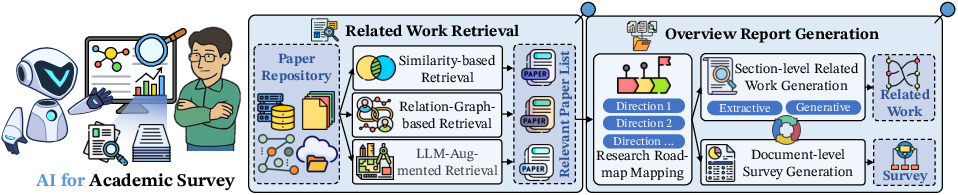
Figure 3: The two primary stages in AI-driven academic surveys: Related Work Retrieval and Overview Report Generation. Related Work Retrieval is further subdivided into Semantic-Guided Retrieval, Graph-Guided Retrieval, and LLM-Augmented Retrieval. Overview Report Generation encompasses Research Roadmap Mapping, Section-level Related Work Generation, and Document-level Survey Generation.
Related Work Retrieval is categorized into Semantic-Guided, Graph-Guided, and LLM-Augmented techniques, reflecting the evolution of methods used to identify relevant literature. Overview Report Generation includes Research Roadmap Mapping, Section-level Related Work Generation, and Document-level Survey Generation, outlining the steps involved in synthesizing a comprehensive overview.
AI for Scientific Discovery
This section explores the use of AI in generating and validating novel scientific hypotheses, emphasizing the augmentation of human capabilities in scientific exploration (Figure 4).
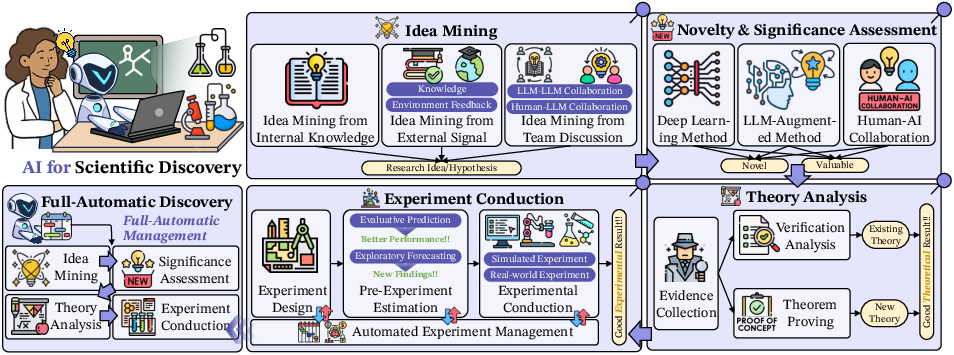
Figure 4: The AI-augmented pipeline for scientific discovery, encompassing Idea Mining, Novelty {additional_guidance} Significance Assessment, Theory Analysis, and Experiment Conduction. Full-Automatic Discovery integrates these elements into a cohesive, end-to-end process, supporting scientific exploration and innovation.
The AI-augmented pipeline encompasses Idea Mining, Novelty & Significance Assessment, Theory Analysis, and Experiment Conduction. A key aspect is Full-Automatic Discovery, where AI integrates these elements into a cohesive, end-to-end process.
AI for Academic Writing
The survey addresses AI's role in academic writing, dividing it into Semi-Automatic and Full-Automatic approaches (Figure 5).
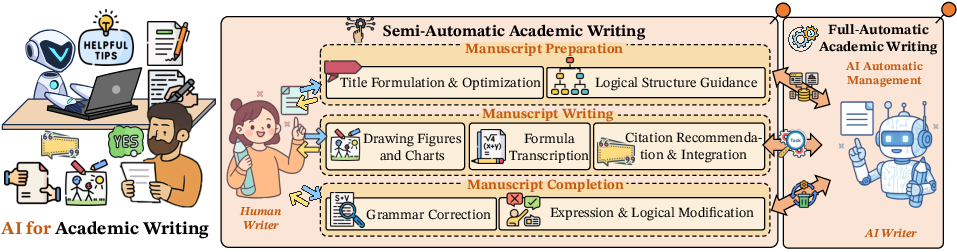
Figure 5: The main paradigms of AI for Academic Writing. It can be divided into two main categories: Semi-Automatic Academic Writing and Full-Automatic Academic Writing. Specifically, Semi-Automatic Academic Writing encompasses Manuscript Preparation, Manuscript Writing, and Manuscript Completion.
Semi-Automatic Academic Writing includes Manuscript Preparation, Manuscript Writing, and Manuscript Completion, highlighting AI's supportive role in enhancing writing quality. Full-Automatic Academic Writing explores the potential for AI to generate complete manuscripts autonomously.
AI for Academic Peer Review
The authors detail how AI can enhance academic peer review, dividing the process into Pre-Review, In-Review, and Post-Review stages (Figure 6).
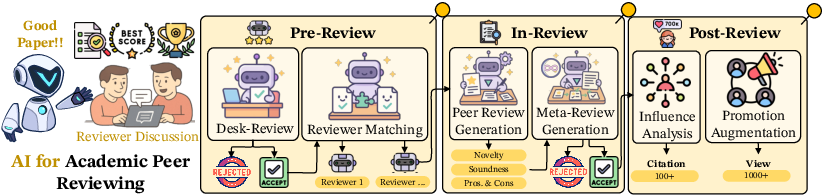
Figure 6: The primary process pipelines in AI for Academic Peer Review, encompassing three key stages: (1) Pre-Review, including Desk-Review and Reviewer Matching to ensure higher quality and more efficient evaluations; (2) In-Review, comprising Peer Review and Meta-Review, aimed at providing comprehensive scholar feedback and evaluation; and (3) Post-Review, featuring Influence Analysis and Promotion Augmentation, designed to assess the impact of the review process and improve the dissemination of scholarly work.
Pre-Review includes Desk-Review and Reviewer Matching, while In-Review comprises Peer Review and Meta-Review, focusing on providing comprehensive scholar feedback. Post-Review features Influence Analysis and Promotion Augmentation, designed to assess the review process's impact and improve scholarly work dissemination.
Multidisciplinary Applications of AI4Research
The survey highlights the broad applicability of AI in various scientific disciplines (Figure 7).
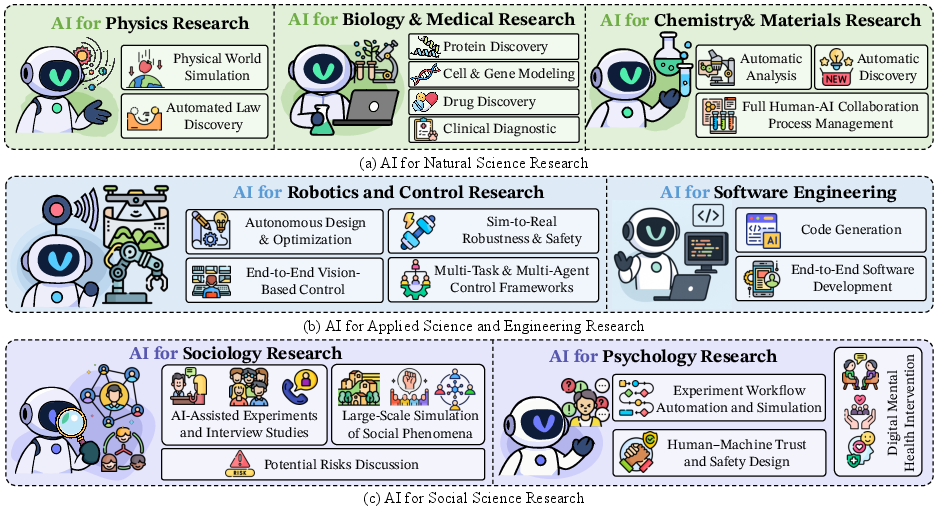
Figure 7: Multidisciplinary Applications of AI in Research. This includes three primary areas: (a) AI in Natural Sciences, covering fields such as physics, biology and medicine, and chemistry and materials science; (b) AI in Applied Sciences and Engineering, focusing on robotics and software engineering; and (c) AI in Social Sciences, encompassing disciplines such as sociology and psychology.
AI applications span Natural Sciences, Applied Sciences and Engineering, and Social Sciences, demonstrating AI4Research's versatility.
Future Directions and Frontiers
The authors identify promising future research areas for AI in academia (Figure 8).
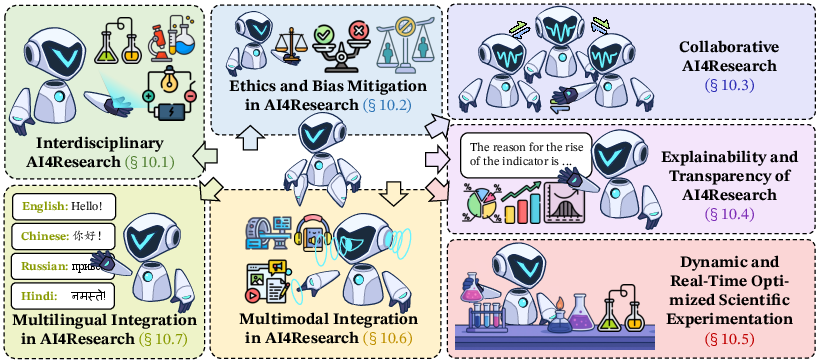
Figure 8: Frontiers and Future Directions of Artificial Intelligence in Research: This includes (1) Interdisciplinary AI models, (2) Ethics and Safety in AI4Research, (3) AI for Collaborative Research, (4) Explainability and Transparency of AI4Research, (5) Dynamic and Real-Time Optimized Scientific Experimentation, (6) Multimodal Integration in AI4Research, and (7) Multilingual Integration in AI4Research.
Key directions include Interdisciplinary AI models, Ethics and Safety in AI4Research, AI for Collaborative Research, Explainability and Transparency, Dynamic and Real-Time Optimized Scientific Experimentation, Multimodal Integration, and Multilingual Integration.
Conclusion
The paper effectively presents a comprehensive survey and unified perspective on AI4Research. By systematically categorizing the field, identifying key research gaps, and compiling relevant resources, the authors provide a valuable contribution to the research community, fostering innovative breakthroughs in AI-driven scientific exploration.