Compress to Impress: Efficient LLM Adaptation Using a Single Gradient Step on 100 Samples
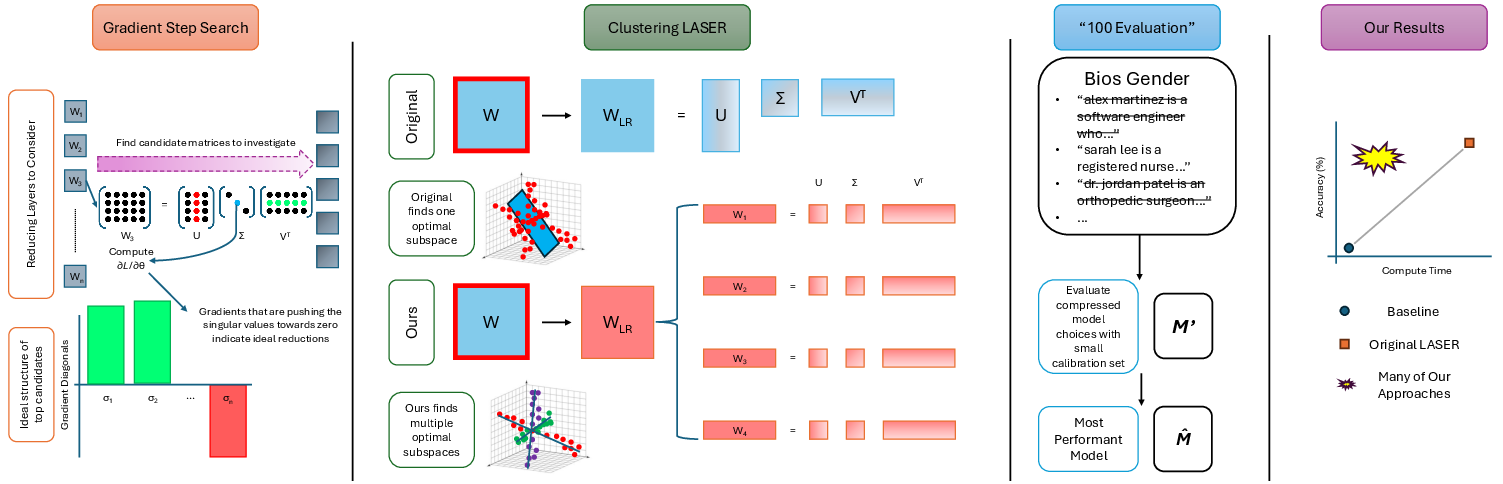
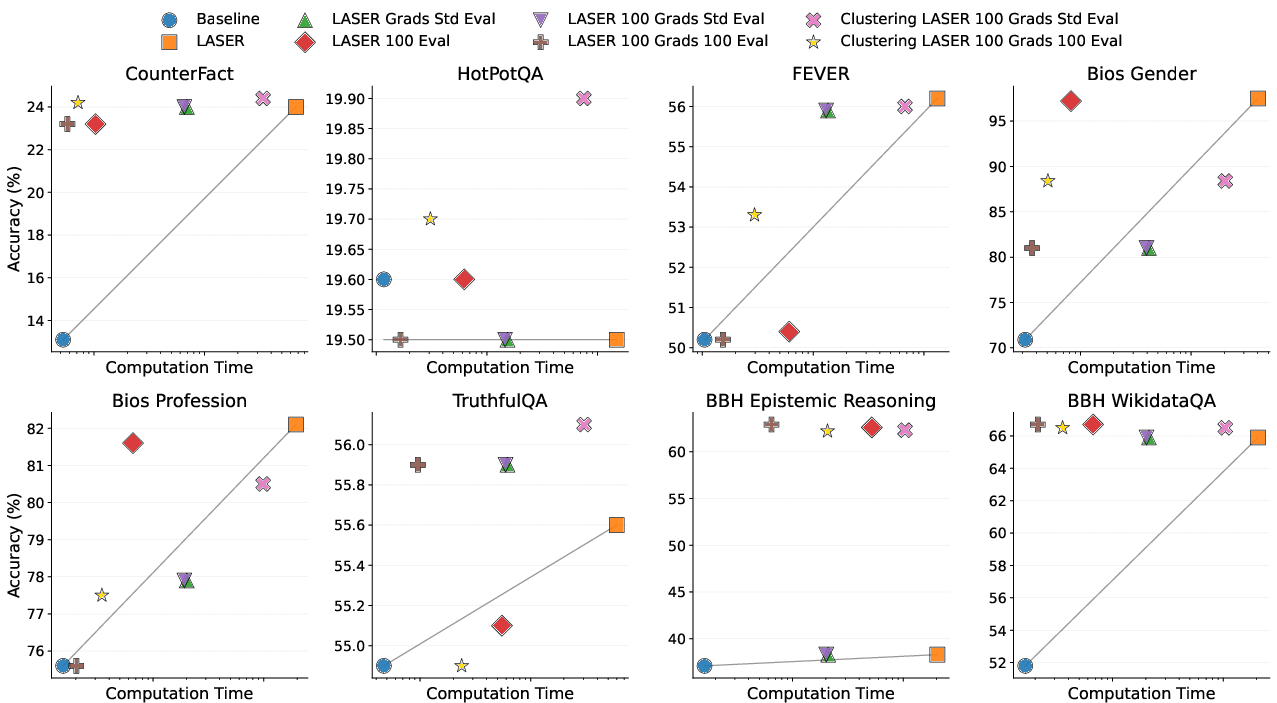
Abstract: Recently, Sharma et al. suggested a method called Layer-SElective-Rank reduction (LASER) which demonstrated that pruning high-order components of carefully chosen LLM's weight matrices can boost downstream accuracy -- without any gradient-based fine-tuning. Yet LASER's exhaustive, per-matrix search (each requiring full-dataset forward passes) makes it impractical for rapid deployment. We demonstrate that this overhead can be removed and find that: (i) Only a small, carefully chosen subset of matrices needs to be inspected -- eliminating the layer-by-layer sweep, (ii) The gradient of each matrix's singular values pinpoints which matrices merit reduction, (iii) Increasing the factorization search space by allowing matrices rows to cluster around multiple subspaces and then decomposing each cluster separately further reduces overfitting on the original training data and further lifts accuracy by up to 24.6 percentage points, and finally, (iv) we discover that evaluating on just 100 samples rather than the full training data -- both for computing the indicative gradients and for measuring the final accuracy -- suffices to further reduce the search time; we explain that as adaptation to downstream tasks is dominated by prompting style, not dataset size. As a result, we show that combining these findings yields a fast and robust adaptation algorithm for downstream tasks. Overall, with a single gradient step on 100 examples and a quick scan of the top candidate layers and factorization techniques, we can adapt LLMs to new datasets -- entirely without fine-tuning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.