- The paper introduces a one-shot compression strategy using low-rank feature distillation to reduce model complexity.
- It leverages SVD initialization and a local distillation loss to maintain up to 99% performance and improve inference speed by 20%.
- The method is model-independent and validated across various architectures, offering practical benefits over resource-intensive alternatives.
LLMs Compression via Low-Rank Feature Distillation
Introduction
The paper addresses the challenge of compressing LLMs without the typically high computational cost and performance degradation. Current methods involve steps like structured pruning followed by extensive pretraining, which are resource-intensive. The introduced method focuses on a one-shot compression strategy that utilizes low-rank feature distillation to maintain model performance with reduced memory and computational requirements.
Proposed Method
The proposed methodology involves a three-step process:
- Layer Selection and SVD Initialization: The method begins by selecting layers for compression to achieve a target compression ratio. This is done using Singular Value Decomposition (SVD) to initialize low-rank weights, which offers an optimal low-rank approximation.
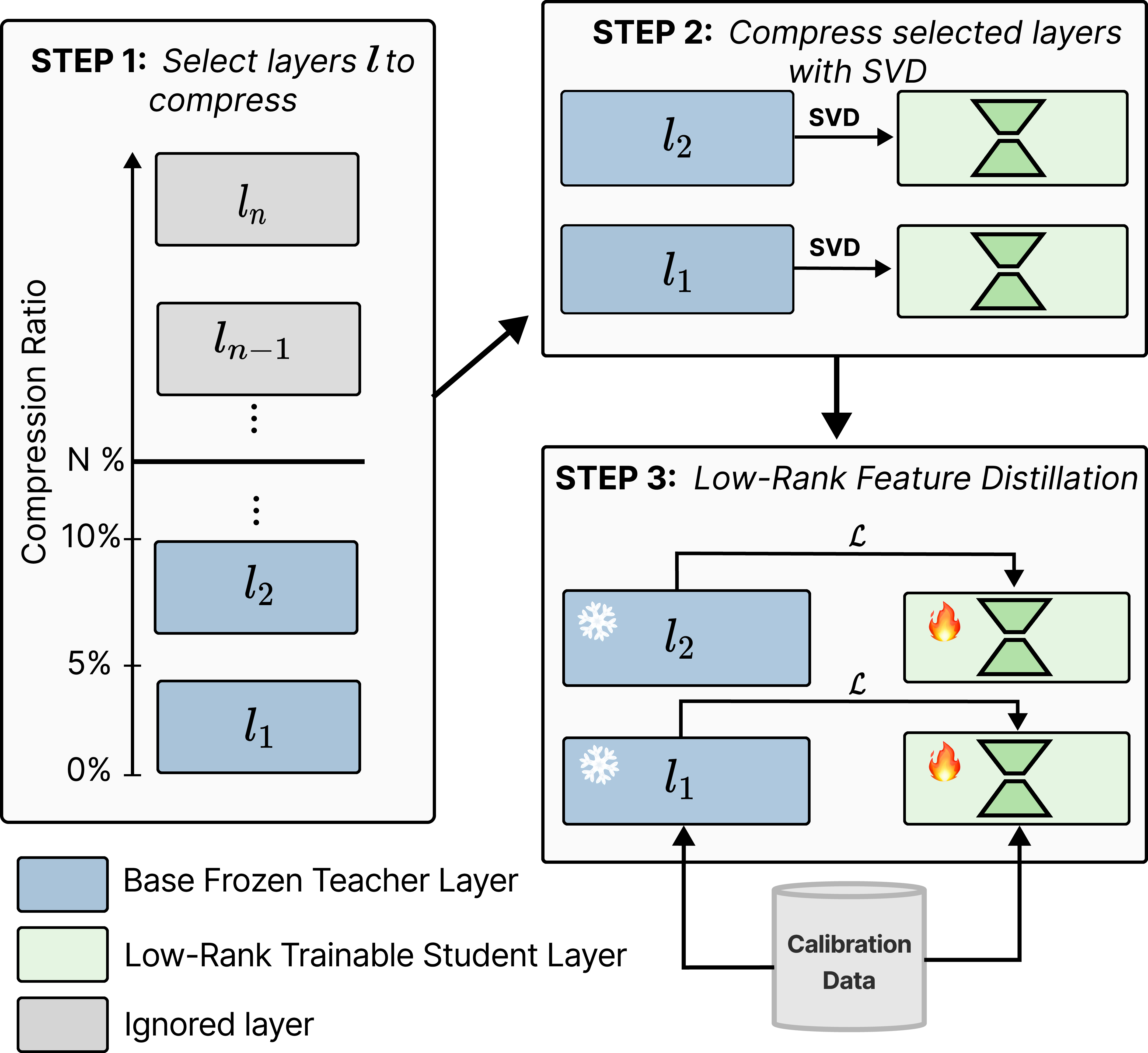
Figure 1: Our compression approach: STEP 1 selects layers to compress for a target compression ratio (e.g., N\%) using various strategies.
- Local Distillation Loss: A joint loss function combines teacher and student activations, which accelerates convergence and enhances performance. It significantly reduces memory requirements by using local gradient updates only, tailored for achieving high efficiency.
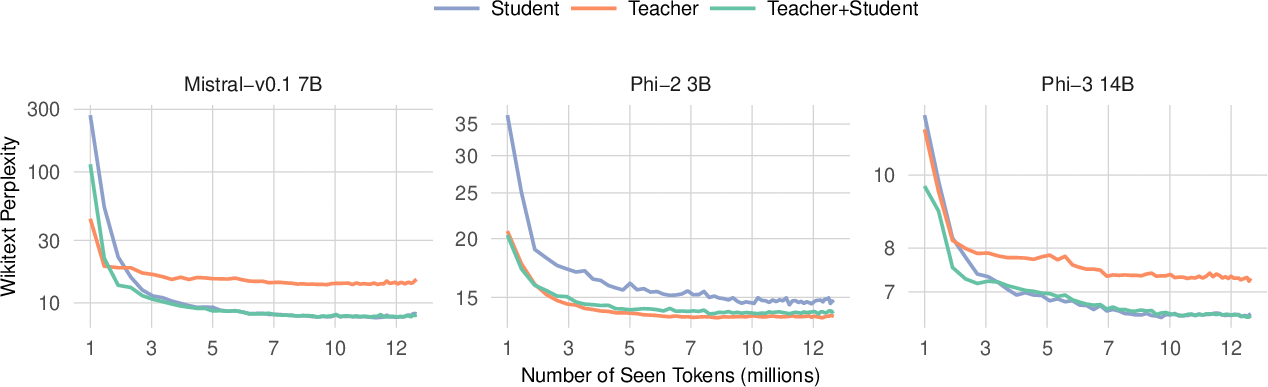
Figure 2: The joint loss converges generally better. Convergence of the three losses illustrated in Figure~\ref{fig:distillaton}.
- Layer-Wise Implementation: The compression is model-independent and layer-wise, hence applicable to both linear and non-linear layers, which allows it to be generalized across various model architectures, including non-Transformer models like Mamba.
Experimental Results
The paper provides comprehensive results demonstrating the efficiency of the method:
- Compression Efficiency: Mixtral-8x7B and Phi-2 3B were compressed significantly while retaining over 95% performance. The Mamba-3B architecture, when compressed, maintained 99% of its performance.
(Table 1 & Table 2 illustrations in the original paper context)
- Inference Speed and Memory Gain: The compression improves inference speed by up to 20% and achieves significant memory reduction. For instance, compressing the Mixtral model enabled fitting a model on a single A100 GPU that was previously not feasible.
- Comparison with Existing Methods: The paper’s method stands out against current methods like SparseGPT and Wanda by being less computationally intensive and independent of specialized GPU kernels.
Implementation Details
The implementation involves core PyTorch components and simple plug-in configurations for applying the proposed compression method across models. The core algorithm functions using local optimization, and its minimal GPU memory usage makes it suitable for large-scale deployments.

Figure 3: An example of PyTorch implementation of our approach with the Teacher loss.
Limitations and Future Work
The current trade-offs in complexity versus the generalizability of the compression present a balance between speed and applicability. Future work is envisaged to explore complementing the technique with quantization and additional pretraining stages, potentially enhancing practical deployments further.
Conclusion
This low-rank feature distillation approach presents a valuable method for efficiently compressing LLMs with minimal loss in performance. The technique's adaptability across various architectures and its efficient resource usage make it a strong candidate for real-world applications requiring optimized computational efficiency.