UltraHR-100K: Enhancing UHR Image Synthesis with A Large-Scale High-Quality Dataset
Abstract: Ultra-high-resolution (UHR) text-to-image (T2I) generation has seen notable progress. However, two key challenges remain : 1) the absence of a large-scale high-quality UHR T2I dataset, and (2) the neglect of tailored training strategies for fine-grained detail synthesis in UHR scenarios. To tackle the first challenge, we introduce \textbf{UltraHR-100K}, a high-quality dataset of 100K UHR images with rich captions, offering diverse content and strong visual fidelity. Each image exceeds 3K resolution and is rigorously curated based on detail richness, content complexity, and aesthetic quality. To tackle the second challenge, we propose a frequency-aware post-training method that enhances fine-detail generation in T2I diffusion models. Specifically, we design (i) \textit{Detail-Oriented Timestep Sampling (DOTS)} to focus learning on detail-critical denoising steps, and (ii) \textit{Soft-Weighting Frequency Regularization (SWFR)}, which leverages Discrete Fourier Transform (DFT) to softly constrain frequency components, encouraging high-frequency detail preservation. Extensive experiments on our proposed UltraHR-eval4K benchmarks demonstrate that our approach significantly improves the fine-grained detail quality and overall fidelity of UHR image generation. The code is available at \href{https://github.com/NJU-PCALab/UltraHR-100k}{here}.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
UltraHR-100K: Making ultra‑high‑resolution AI images sharper and more detailed
1) What is this paper about?
This paper is about helping AI systems create very large, super‑sharp pictures from text (think 4K posters or wallpapers). The authors do two big things:
- They build a huge, high‑quality dataset of ultra‑high‑resolution (UHR) images called UltraHR‑100K.
- They invent a training method that teaches AI models to pay extra attention to tiny details, so the final pictures look crisp and realistic, not blurry or smooth.
2) What questions are the researchers trying to answer?
The paper focuses on two simple questions:
- Can we make AI better at making super‑detailed, high‑resolution images by giving it a bigger and cleaner dataset with better captions?
- Can we train AI in a smarter way so it learns to keep tiny textures (like hair, fur, fabric, leaves) sharp, even at very large sizes?
3) How did they do it?
To make their approach work, the authors built a new dataset and designed a new training strategy.
Here’s what they did for the dataset, explained simply:
- They collected about 400,000 very large images from the internet and high‑res cameras.
- They removed images that were blurry, flat, or low quality.
- They kept images that had:
- Lots of small textures and patterns (detail richness),
- Many different things happening in them (content complexity),
- And that just looked good (aesthetic quality).
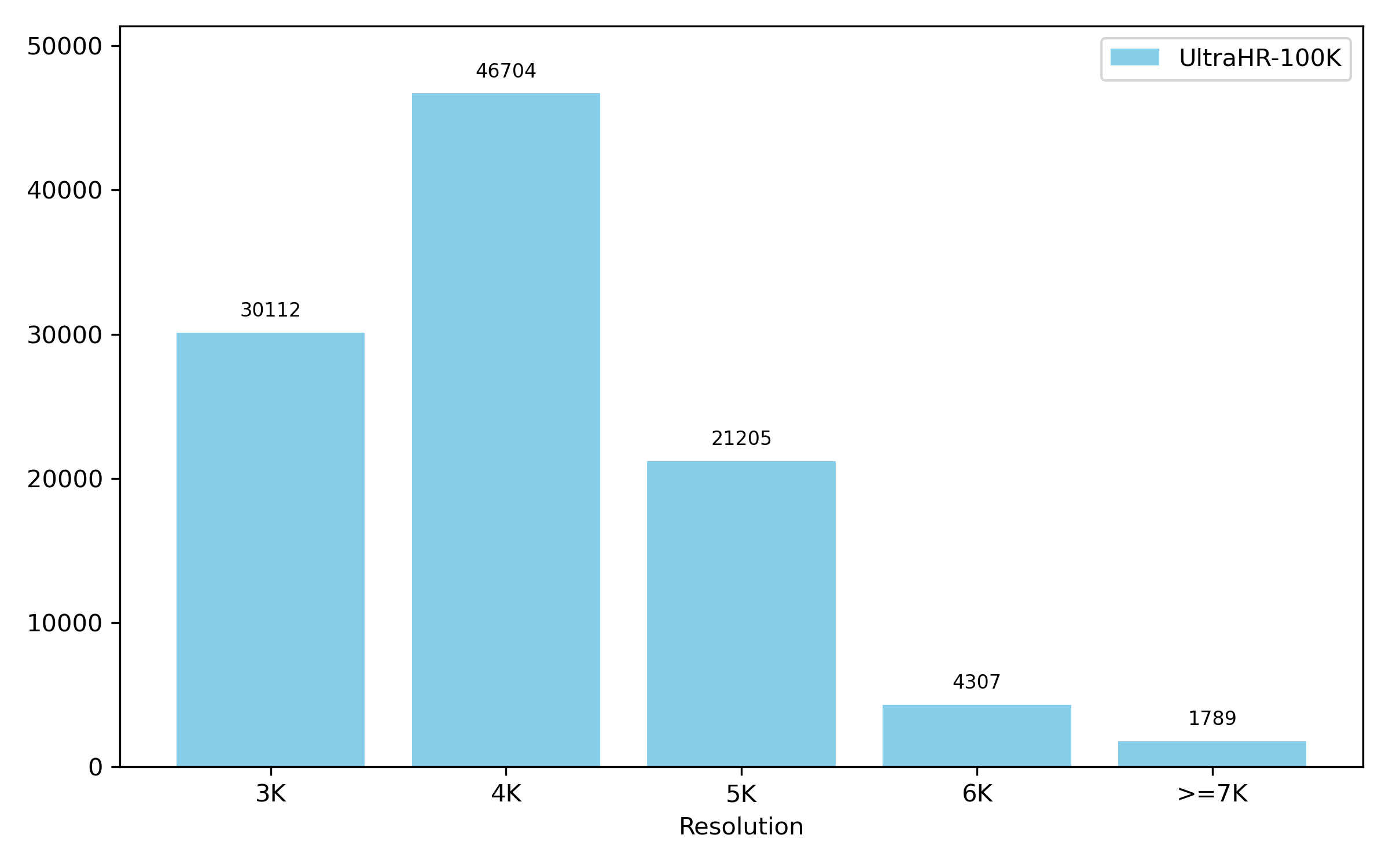
- They ended up with 100,000 ultra‑high‑resolution images (each image is bigger than 3,000 pixels on average across height and width).
- They used a powerful AI (Gemini 2.0) to write long, rich captions for each image, not just short titles. These captions help the model understand what’s in the image, both the big picture and the fine details.
Here’s their training idea, using everyday analogies:
- AI image models create pictures step by step, starting with noise (static) and slowly cleaning it up to reveal a picture. Early steps set up big shapes; later steps add tiny details.
- Detail‑Oriented Timestep Sampling (DOTS): Imagine practicing a song—if the ending is the hardest part, you practice that part more. DOTS makes the model “practice” the later steps more, where fine details are added.
- Soft‑Weighting Frequency Regularization (SWFR): Think of an image as a mix of “slow waves” (big shapes and smooth colors) and “fast waves” (tiny textures and edges). SWFR is like an audio equalizer that slightly boosts the “fast waves,” so the model keeps high‑frequency details sharp without breaking the overall structure. Technically, they use the Fourier transform (a tool that turns an image into its mix of slow and fast waves) and gently encourage the model to match the high‑frequency parts better.
They also built a test set called UltraHR‑eval4K (images at 4096×4096) to fairly measure how well different methods work.
4) What did they find, and why does it matter?
Their experiments show clear improvements:
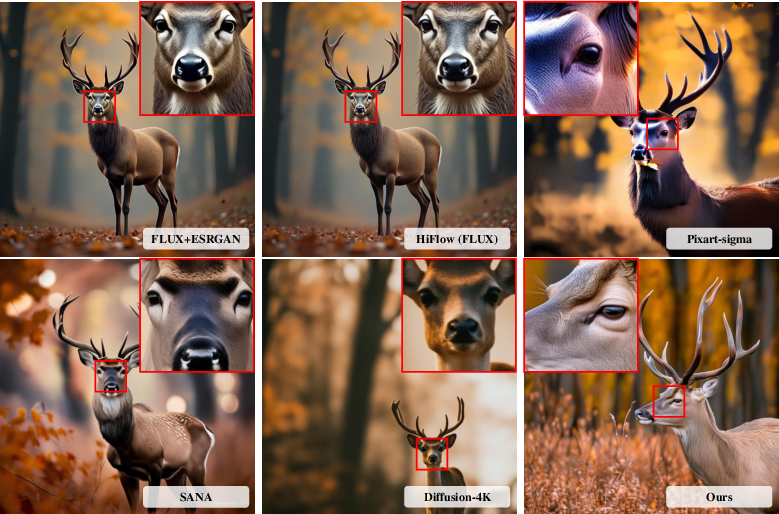
- Sharper local details: Their method did much better on scores that test small patches of the image, which means fine textures look more realistic and less smoothed out.
- Good overall quality: The generated images looked strong overall, not just in tiny patches.
- Solid text‑image match: The pictures still generally match the prompts well (what the user asked for in words).
- People preferred the results: In a small user study, most participants liked their images more than those from other top methods.
Why this matters:
- Many real‑world uses (digital art, posters, game assets, advertising, product design) need large, crisp images. This work helps AI deliver that quality—clear details and professional‑looking results at 4K and beyond.
5) What could this change in the future?
- A better foundation for research: UltraHR‑100K gives the community a large, clean, open dataset to train and test future models for ultra‑high‑resolution images.
- Smarter training for details: The idea of focusing training on later steps and gently boosting high‑frequency details could be reused in other models or even in video.
- Practical impact: Artists, designers, and developers could get sharper textures, more realistic scenes, and higher‑quality prints straight from text prompts.
The authors also point out two current limits:
- Slight trade‑off: Focusing on tiny details can slightly reduce how perfectly the image matches the text. They plan to balance this better.
- Fewer portraits: The dataset currently has fewer portrait images, so they plan to add more to improve people‑focused results.
Overall, the paper shows that pairing a carefully built, large UHR dataset with a detail‑aware training strategy can make AI much better at generating huge, sharp, and realistic images from text.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances UHR T2I synthesis via a new dataset (UltraHR-100K) and a frequency-aware post-training method (FAPT). The following issues remain missing, uncertain, or unexplored:
- Dataset provenance and licensing: the sources of scraped images, redistribution permissions, copyright status, and consent (especially for faces) are not documented; it is unclear whether the full image set (vs URLs) can be legally released and reused.
- Safety and content filtering: no description of NSFW/violent/sensitive content screening, face anonymization, watermark/logo/copyright removal, or child/PII safeguards.
- Bias and representativeness: no bias audit (e.g., demographics, geography, culture, lighting/weather, device domains); the paper notes limited portrait data but does not quantify category skew or its impact on downstream performance/fairness.
- Deduplication and leakage: no duplicate/near-duplicate removal is reported; UltraHR-eval4K is constructed from the same data source, raising potential train–test contamination; cross-source de-dup across public datasets is unaddressed.
- Caption quality and grounding: captions generated by Gemini 2.0 are not human-validated; hallucination rates, attribute grounding, consistency with visible content, and the impact of caption noise on training are unmeasured.
- Caption language and tokenizer effects: no multilingual coverage; unknown whether long captions exceed tokenizer limits (truncation) in SANA/DiT pipelines and how much “effective” caption length is used during training.
- Reproducibility of captioning: reliance on a commercial VLM (Gemini 2.0) creates reproducibility and licensing questions; no open alternative or release of captioning prompts/policies is provided.
- Selection-criterion validity: the choice of GLCM, Shannon entropy, and LAION aesthetic predictor (top 50% intersections) is not justified via human studies; correlation of these metrics with T2I performance at UHR is unverified.
- Filtering side effects: potential skew toward texture-heavy/high-entropy images and away from minimalistic/low-texture scenes is not analyzed; no ablation isolating each filtering dimension’s contribution to model gains.
- Dataset documentation: thresholds and parameters for Laplacian/Sobel/GLCM/entropy/aesthetic filters are not fully specified (e.g., window sizes, directions, normalization), hindering reproducibility.
- Metadata and accessibility: it is unclear if dataset release includes image file hashes, licenses, category labels, and versioning; whether UltraHR-eval4K prompts/captions are public is not stated.
- Evaluation external validity: primary evaluation is on UltraHR-eval4K (in-domain); out-of-domain generalization (e.g., scientific/medical, satellite, documents, product shots) and public benchmarks beyond Aesthetic-Eval@4096 are not explored.
- Resolution/aspect-ratio generalization: results are reported at 4096×4096; performance at 8K, panoramas, and extreme aspect ratios (e.g., 21:9, tall posters) is unknown; robustness to tiled/streamed decoding is untested.
- Prompt robustness: no evaluation on compositionality (counts, relations), text rendering/legibility at 4K, negation, rare word grounding, or long/complex prompts; non-English prompts are not assessed.
- User study limitations: only 5 raters and 50 cases, with no inter-rater reliability, randomization/blinding procedure, or power analysis; conclusions about perceptual quality may be underpowered.
- Baseline parity and fairness: some baselines are training-free or trained on different data; the impact of re-finetuning baselines on UltraHR-100K (for a “like-for-like” comparison) is not examined; inference settings (samplers, steps, CFG) are not fully normalized.
- Compute and efficiency: training/inference memory/time cost and overhead of SWFR (DFT operations) are not reported; scalability to larger models/datasets or 8K training is unquantified.
- Method generality: FAPT is only demonstrated on SANA; applicability to other architectures (e.g., SDXL, FLUX, U-Net vs DiT), noise schedules, and samplers remains an open question.
- DOTS schedule dependence: the mapping between Beta(t) and actual noise/velocity schedules (logit-normal vs others) is not analyzed; whether the chosen α,β generalize across schedulers and architectures is unknown.
- SWFR implementation specifics: the domain of the DFT (latent vs pixel), handling of complex spectra (magnitude vs real/imag/phase), windowing/padding, and frequency normalization are unspecified, limiting reproducibility.
- Hyperparameter sensitivity: no sweeps for SWFR λ, γ, λ_freq or systematic stability analysis; only limited ablation for DOTS α,β; default settings’ robustness across datasets/prompts is unclear.
- Detail–alignment trade-off: the paper notes a slight degradation in text–image alignment with FAPT, but provides no diagnostic analysis (e.g., which prompt types/categories suffer) or mitigation strategies (e.g., alignment-aware losses, sample-adaptive weighting).
- Artifact analysis: potential high-frequency artifacts (ringing, moiré, over-sharpening) induced by SWFR are not characterized; no localized artifact or edge-acuity metrics are reported.
- Alternative frequency formulations: no controlled comparison of DFT vs DWT regularization under the same base model; other spectral losses (e.g., log-power, Laplacian pyramid, steerable filters) remain unexplored.
- Training design choices: the necessity of the two-stage pipeline (logit-normal fine-tune followed by FAPT) vs single-stage training is not validated; when to schedule DOTS/SWFR during training is an open design question.
- Evaluation metrics: reliance on FID/IS/CLIP and patch variants omits perceptual and task-specific indicators (e.g., text legibility, LPIPS/DISTS, aesthetic MOS); no calibration to human judgments beyond the small user study.
- Data cleaning beyond blur/edges: no handling of compression artifacts, HDR/EXIF inconsistencies, color space or gamut issues that often affect UHR content.
- Ethical/data governance: no dataset card, intended use, and misuse guidance; no discussion of robots.txt compliance, takedown requests, or mechanisms for content owners to opt out.
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s dataset (UltraHR-100K), training innovations (DOTS and SWFR), and evaluation assets (UltraHR-eval4K). Each item specifies sector relevance, potential tools/products/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
The following applications can be deployed or piloted now with available models, code, and workflows, assuming access to compute and data governance.
- Creative industries (advertising, marketing, media, publishing)
- Application: High-fidelity 4K+ asset generation for billboards, posters, print magazines, and large-format displays.
- Tools/products/workflows: Fine-tune existing T2I models (e.g., SDXL, FLUX, SANA) on
UltraHR-100Kusing the paper’s frequency-aware post-training (FAPT) to unlock a “4K detail mode” in creative suites; implement QA withUltraHR-eval4Kand patch-level FID to catch oversmoothing and artifacts before print. - Assumptions/dependencies: GPU resources for post-training; licensing/compliance for web-scraped images and Gemini 2.0 captions; acceptance of a slight text–image alignment tradeoff noted in the paper; color management in pre-press remains necessary.
- Product design and e-commerce
- Application: Generate ultra-detailed product hero images and lifestyle scenes from text prompts for storefronts, catalogs, and A/B testing.
- Tools/products/workflows: “UHR scene composer” feature in content pipelines that integrates DOTS+SWFR fine-tuned checkpoints and automated QA (CLIP and FG-CLIP for prompt adherence, patch-FID for local details).
- Assumptions/dependencies: Domain-specific fine-tuning (products, materials, lighting) to avoid hallucinations; consistent brand controls; permissions for synthetic representation of branded goods.
- Game development and VFX
- Application: Rapid synthesis of 4K textures, environment plates, matte paintings, and set extensions with improved microtexture fidelity.
- Tools/products/workflows: Texture pack generators trained with
UltraHR-100K, adopting SWFR to preserve high-frequency content; patch-level FID integrated into art QA pipelines. - Assumptions/dependencies: Additional domain-specific datasets (PBR materials, physically-based lighting); pipeline integration with DCC tools; content licensing.
- Mobile and consumer imaging (smartphone OEMs, photo apps)
- Application: Cloud or on-device “poster/wallpaper generator” producing high-fidelity, printable images from text prompts.
- Tools/products/workflows: OEM-branded AI studio features backed by DOTS+SWFR-fine-tuned models, with inference-time quality gates (patch-FID, FG-CLIP).
- Assumptions/dependencies: Optimization for latency and memory (model distillation or token compression); adherence to user content policies; limited portrait performance as noted by the paper.
- Software tooling for ML research and engineering
- Application: Drop-in training library for detail-oriented UHR synthesis.
- Tools/products/workflows: Open-source “Frequency-Aware Post-Training” plugin that implements DOTS (Beta-timestep sampling) and SWFR (DFT soft-weighting); scripts to reproduce
UltraHR-eval4Kmetrics (FID, IS, patch-FID/IS, CLIP, FG-CLIP). - Assumptions/dependencies: PyTorch-based pipelines; reproducibility across architectures (DiT, rectified flows); careful hyperparameter tuning for the Beta distribution and SWFR weights.
- Data curation and quality control (academia and industry R&D)
- Application: Build domain-specific UHR datasets using the paper’s filtering pipeline (GLCM for detail richness, Shannon entropy for content complexity, LAION aesthetic predictor for appeal).
- Tools/products/workflows: Replicable curation scripts; caption enrichment via a VLM (Gemini 2.0 or an open-source alternative) to improve prompt grounding.
- Assumptions/dependencies: Legal acquisition of source images; VLM licensing and data governance; robust deduplication and harmful content filtering.
- Benchmarking and model QA
- Application: Standardized evaluation of UHR generators.
- Tools/products/workflows: Adopt
UltraHR-eval4Kand patch-level metrics as QA gates in CI/CD for generative systems; maintain “detail quality dashboards” for regression tracking. - Assumptions/dependencies: Consistent prompts and seeds for comparability; community acceptance of patch-level metrics.
- Education and training (universities, professional programs)
- Application: Course modules and labs on UHR diffusion, frequency-domain regularization, and evaluation.
- Tools/products/workflows: Teaching materials demonstrating DOTS/SWFR, Fourier analysis for generative models, and hands-on evaluation with
UltraHR-eval4K. - Assumptions/dependencies: Access to modest compute (or small-scale prototypes); suitable licenses for dataset subsets and captions.
Long-Term Applications
These applications require further research, scaling, or development—especially around efficiency, alignment, governance, and domain adaptation.
- Real-time or on-device UHR generation
- Sector: Mobile, AR/VR, edge AI.
- Application: Interactive 4K+ generation on smartphones, headsets, and creative tablets.
- Tools/products/workflows: Model compression and token-efficient DiT variants combined with DOTS/SWFR-inspired training; hardware acceleration for DFT/FFT operations.
- Assumptions/dependencies: Significant inference-time optimization; energy constraints; memory bandwidth; quantization/distillation research.
- High-fidelity world building for VR/AR and digital twins
- Sector: Entertainment, simulation, architecture, urban planning.
- Application: Procedural generation of large, detail-rich scenes with strong global structure and microtexture realism.
- Tools/products/workflows: Multi-stage pipelines combining semantic planning (pretrained models) with frequency-aware fine detail; extended datasets beyond 4K (8K/16K) and domain-specific captions/control.
- Assumptions/dependencies: Scalable training data curation; better text–image alignment to avoid semantic drift; improved control tools (layout, materials, physics).
- Synthetic data generation for high-resolution downstream tasks
- Sector: Robotics, geospatial, microscopy (research use first).
- Application: Controlled synthetic imagery to pretrain or augment detectors/segmenters that operate on UHR inputs.
- Tools/products/workflows: Domain-specific curation pipeline plus FAPT variants tuned for scientific textures; rigorous dataset labeling and simulation-to-real validation.
- Assumptions/dependencies: Strong domain adaptation; safety/ethics in sensitive areas (e.g., medical); regulatory acceptance of synthetic training data.
- Content provenance and spectral watermarking
- Sector: Trust & Safety, policy, platform governance.
- Application: Frequency-domain fingerprints/watermarks aligned with generation pipelines to improve provenance tracking of UHR content.
- Tools/products/workflows: SWFR-inspired constraints that yield predictable spectral signatures; detection APIs for platforms.
- Assumptions/dependencies: Research validation that spectral signatures remain robust under editing/compression; standardization across models/vendors; policy alignment.
- Standardization of UHR benchmarks and best practices
- Sector: Industry consortia, research communities.
- Application: Community-adopted benchmark suites and metrics emphasizing local detail fidelity and semantic adherence.
- Tools/products/workflows: Expanded
UltraHR-eval4K(and beyond) with diverse categories and longer captions; reference leaderboards and round-robin evaluations. - Assumptions/dependencies: Broad consensus on metrics; shared licensing frameworks; continual dataset refresh to prevent overfitting.
- End-to-end print-grade creative pipelines
- Sector: Advertising, publishing, packaging.
- Application: From prompt to press-ready assets with automated detail QA, color management, and legal checks.
- Tools/products/workflows: Integrated workflow combining FAPT-trained models, patch-level QA, ICC profile conversion, and rights management.
- Assumptions/dependencies: Strong alignment under complex prompts; robust governance for synthetic content; close integration with pre-press systems.
- UHR portrait generation with fairness and privacy safeguards
- Sector: Photography, fashion, media.
- Application: Studio-grade portrait synthesis for editorial and creative uses.
- Tools/products/workflows: Expanded portrait-focused
UltraHRsubsets; alignment-improving training strategies to mitigate the slight tradeoff observed; bias audits and privacy-aware data handling. - Assumptions/dependencies: Curating high-quality, consented portrait datasets; regulatory compliance; ongoing research to balance detail fidelity with alignment and fairness.
- Multimodal control and captioning without proprietary dependencies
- Sector: Open-source ML, enterprise AI.
- Application: Rich, controllable generation using open VLMs for long captions and scene descriptions to replace or complement Gemini 2.0.
- Tools/products/workflows: Fine-tuning pipelines that pair open VLM captioners with FAPT; structured prompt schemas for complex scenes.
- Assumptions/dependencies: Open VLMs must match caption quality and safety filters; additional prompt engineering and alignment techniques.
Notes on cross-cutting assumptions and dependencies:
- Compute and optimization: Post-training at UHR is resource-intensive; success depends on efficient architectures, optimized FFT/DFT operations, and scalable data pipelines.
- Data governance: Web-scraped sources and VLM-generated captions necessitate clear licensing, consent, and compliance practices; domain-specific datasets may be required for sensitive sectors.
- Alignment tradeoffs: The paper reports slight degradation in text–image alignment when emphasizing high-frequency detail; future work should balance DOTS/SWFR with alignment-preserving strategies.
- Domain coverage: The dataset reportedly has limited portrait content; expanding coverage is important for broader applicability (fashion, editorial, social media).
- Evaluation rigor: Adoption of patch-level metrics and robust benchmarks is key to maintaining quality as models scale beyond 4K.
Glossary
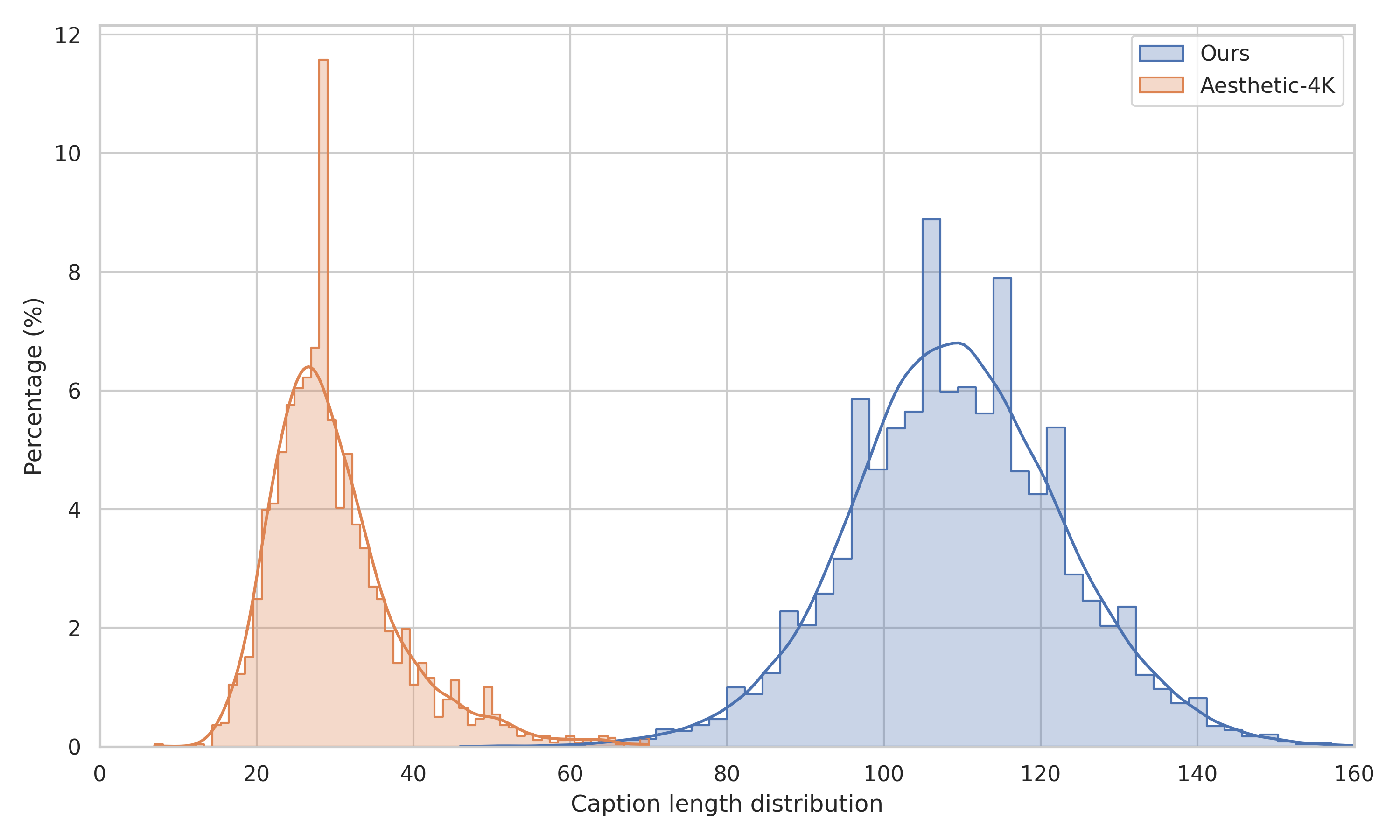
- Aesthetic-4K: A publicly available ultra-high-resolution text-to-image dataset used for training and evaluation. "Compared to the recent Aesthetic-4K\cite{zhang2025diffusion}, our captions are significantly longer, providing richer semantic supervision."
- Beta distribution: A continuous probability distribution on (0,1) used here to bias sampling over denoising timesteps. "t \sim \mathrm{Beta}(\alpha, \beta)."
- Beta function: A special function that normalizes the Beta distribution and is defined via the Gamma function. "where is the Beta function."
- BSRGAN: A blind super-resolution generative adversarial network used to upscale images. "powerful T2I models combined with super-resolution technique, BSRGAN~\cite{zhang2021designing}."
- CAMEWrapper: An optimizer or optimization wrapper used to train diffusion-based models efficiently. "We use the CAMEWrapper~\cite{xie2024sana} optimizer with a constant learning rate of 1e-4"
- Cascaded generation paradigm: A multi-stage generation approach where outputs are progressively refined across stages. "HiFlow \cite{bu2025hiflow} adopts a cascaded generation paradigm to effectively capture and utilize low-resolution flow characteristics."
- CLIP score: A metric measuring text–image alignment using CLIP embeddings. "we calculate the long CLIP score \cite{zhang2024long} and Fine-Grained (FG) CLIP score \cite{xie2025fg}."
- Denoising Diffusion Implicit Models (DDIM): A deterministic version of diffusion models enabling faster sampling. "Denoising Diffusion Implicit Models (DDIM) \cite{song2020denoising}"
- Denoising Diffusion Probabilistic Models (DDPM): A class of generative models that iteratively denoise data from noise. "Denoising Diffusion Probabilistic Models (DDPM) \cite{ho2020denoising}"
- Detail-Oriented Timestep Sampling (DOTS): A training strategy that emphasizes later denoising steps to improve fine-detail synthesis. "Detail-Oriented Timestep Sampling (DOTS) to focus learning on detail-critical denoising steps"
- DiT: Diffusion Transformer; a transformer-based architecture for diffusion models. "through efficient token compression in DiT."
- Discrete Fourier Transform (DFT): A transform that converts spatial data into frequency components. "leverages Discrete Fourier Transform (DFT) to softly constrain frequency components"
- Discrete Wavelet Transform (DWT): A transform that decomposes signals into multi-scale wavelet components. "which relies on DWT for frequency separation"
- DFT-based decomposition: Frequency decomposition using the Fourier basis to achieve fine, global frequency control. "we adopt DFT-based decomposition, which provides finer, globally coherent frequency representations better suited for capturing fine-scale structures in high-resolution synthesis."
- Diffusion loss: The training objective used in diffusion models, often defined via predicting noise or velocity. "where $\mathcal{L}_{\text{diff}$ denotes the diffusion loss, which can be instantiated as velocity prediction loss ()."
- FAPT (Frequency-Aware Post-Training): The proposed post-training method that enhances fine details via frequency-aware constraints and timestep sampling. "we propose a frequency-aware post-training method (FAPT)."
- FG-CLIP score: A fine-grained variant of CLIP-based text–image alignment metric. "Fine-Grained (FG) CLIP score \cite{xie2025fg}."
- FID-patch: A patch-based Fréchet Inception Distance variant focusing on local detail quality. "we compute the FID-patch and IS-patch to evaluate the local quality and details of the images"
- Fréchet Inception Distance (FID): A distributional distance between generated and real images that assesses overall image quality. "the Fréchet Inception Distance (FID) \cite{heusel2017gans}"
- Gemini 2.0: A commercial vision-LLM used to generate rich image captions. "we leverage Gemini 2.0 \cite{gemini}, a state-of-the-art commercial vision-LLM (VLM), to generate rich and detailed captions"
- Gray-Level Co-occurrence Matrix (GLCM): A texture-analysis method capturing spatial relationships of pixel intensities. "we compute Gray-Level Co-occurrence Matrix (GLCM) score, including contrast, entropy, and correlation across multiple directions."
- HiFlow: A training-free UHR method using cascaded generation and flow characteristics. "HiFlow \cite{bu2025hiflow} adopts a cascaded generation paradigm to effectively capture and utilize low-resolution flow characteristics."
- Inception Score (IS): A generative image quality metric that evaluates both objectness and diversity. "Inception Score (IS) \cite{salimans2016improved}"
- IS-patch: A patch-based Inception Score variant focusing on local details. "we compute the FID-patch and IS-patch to evaluate the local quality and details of the images"
- LAION Aesthetic Predictor: A learned model that predicts the aesthetic quality of images. "we adopt the LAION Aesthetic Predictor \cite{schuhmann2022laion}, a neural network trained to estimate perceptual quality."
- Laplacian variance: A sharpness metric based on the variance of the Laplacian operator’s response. "we compute the Laplacian variance to assess image sharpness and discard samples below a blur threshold."
- Latent diffusion models: Diffusion models that operate in a compressed latent space for efficiency and scalability. "current advanced latent diffusion models typically operate at a maximum resolution of 1024 Ã 1024"
- Logit-Normal Sampling: A sampling scheme over timesteps using a logit-normal distribution to improve training. "we follow the Logit-Normal Sampling scheme introduced in SD3~\cite{esser2024scaling}"
- Mixed-precision training: Training with reduced numerical precision to save memory and increase speed. "and employ mixed-precision training with a batch size of 24."
- Rectified flows: A flow-matching formulation where the model predicts velocity to guide denoising. "adopt rectified flows to predict velocity , with the objective as follows:"
- Shannon entropy: An information-theoretic measure used as a proxy for content complexity. "We use Shannon entropy as a proxy to measure the content complexity of each image."
- Sobel operator: A gradient-based edge detector used to measure edge density. "we apply the Sobel operator to measure edge density"
- Soft-Weighting Frequency Regularization (SWFR): A frequency-domain regularization that softly emphasizes high-frequency components. "Soft-Weighting Frequency Regularization (SWFR), which leverages Discrete Fourier Transform (DFT) to softly constrain frequency components"
- State-of-the-art (SOTA): Refers to the best-performing current methods in a field. "Qualitative comparisons with SOTA methods on our UltraHR-eval4K (4096 4096)."
- Text-to-Image (T2I): Generating images conditioned on textual descriptions. "Ultra-high-resolution (UHR) text-to-image (T2I) generation has seen notable progress."
- Ultra-high-resolution (UHR): Image resolutions substantially higher than standard (e.g., 3K–4K+), demanding fine detail fidelity. "Ultra-high-resolution (UHR) text-to-image (T2I) generation has seen notable progress."
- UltraHR-eval4K: A 4K-resolution benchmark introduced for evaluating UHR generation quality. "UltraHR-eval4K (4096 4096)"
- Velocity prediction loss: A diffusion training objective where the model predicts velocity rather than noise directly. "which can be instantiated as velocity prediction loss ()"
- Vision-LLM (VLM): A model jointly trained on visual and textual data to understand and generate across modalities. "a state-of-the-art commercial vision-LLM (VLM)"
Collections
Sign up for free to add this paper to one or more collections.

