UltraGen: High-Resolution Video Generation with Hierarchical Attention
Abstract: Recent advances in video generation have made it possible to produce visually compelling videos, with wide-ranging applications in content creation, entertainment, and virtual reality. However, most existing diffusion transformer based video generation models are limited to low-resolution outputs (<=720P) due to the quadratic computational complexity of the attention mechanism with respect to the output width and height. This computational bottleneck makes native high-resolution video generation (1080P/2K/4K) impractical for both training and inference. To address this challenge, we present UltraGen, a novel video generation framework that enables i) efficient and ii) end-to-end native high-resolution video synthesis. Specifically, UltraGen features a hierarchical dual-branch attention architecture based on global-local attention decomposition, which decouples full attention into a local attention branch for high-fidelity regional content and a global attention branch for overall semantic consistency. We further propose a spatially compressed global modeling strategy to efficiently learn global dependencies, and a hierarchical cross-window local attention mechanism to reduce computational costs while enhancing information flow across different local windows. Extensive experiments demonstrate that UltraGen can effectively scale pre-trained low-resolution video models to 1080P and even 4K resolution for the first time, outperforming existing state-of-the-art methods and super-resolution based two-stage pipelines in both qualitative and quantitative evaluations.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
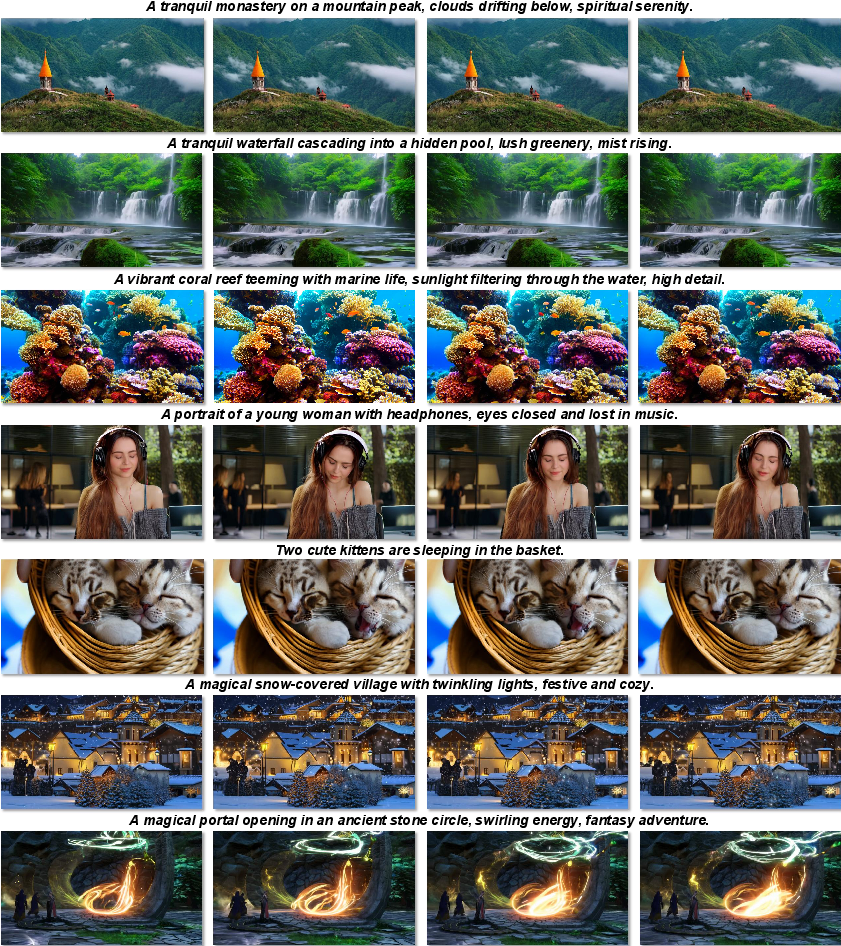
The paper introduces UltraGen, a new way to make high-quality, high-resolution videos (like 1080P and 4K) using AI. It solves a big problem: most video-generating AIs get very slow and blurry when trying to make large, sharp videos. UltraGen keeps videos clear and detailed while running much faster than popular models.
What questions did the researchers ask?
The researchers wanted to know:
- How can we generate high-resolution videos directly, instead of making a small video and just “sharpening” it later?
- Can we make video generation fast enough to be practical at 1080P or even 4K?
- How do we keep both small details (like textures) and the big picture (like overall scene layout and story) consistent over time?
How did they do it?
Think of a video as a stack of images over time—each image is made of lots of tiny patches. Traditional “attention” in AI tries to compare every patch with every other patch, which gets extremely expensive as the video gets larger. UltraGen changes how attention is used so it works much better for big videos.
Here are the key ideas, explained simply:
The problem with high resolution
- Regular transformer-based video models use “self-attention,” which compares all parts of the video with all other parts.
- If you double the height and width of a video, the number of comparisons grows by about 16 times. That’s why high-res videos are slow and often blurry.
Local attention: focusing on small areas like rooms in a building
- UltraGen chops each video frame into smaller “windows” (like dividing a picture into a grid).
- It applies attention inside each window separately. This is much cheaper and lets the model focus on fine details within each area.
Global attention: keeping the big picture consistent
- Just using local windows can cause problems—things near the edges might not match, or the overall story can feel broken.
- UltraGen adds a global branch that looks at the whole frame but at a smaller size (like shrinking the image to see the entire scene).
- It “compresses” the frame with a quick operation, applies global attention at this smaller scale, then “decompresses” it back, smoothing out the big-picture consistency.
Making windows talk to each other
- To avoid visible seams between windows, UltraGen shifts and reshapes windows across layers so neighboring areas overlap and share information. Think of it like moving the grid slightly so boundaries don’t stay fixed.
- It also uses a “hierarchical” step: attention at a middle scale (bigger than a window, smaller than the full frame), which helps track small, fast-moving objects that can cross windows.
Mixing global and local over time
- When the AI starts generating a video, it first needs to get the overall structure right; later, it polishes the details.
- UltraGen blends global and local results using a time-aware mixing factor: early steps focus more on the big picture, later steps bring out the fine details.
Reusing knowledge efficiently
- UltraGen adapts parts of the local model to handle global tasks using lightweight add-ons (similar to LoRA, which is like a small plug-in that tweaks behavior without retraining everything).
- It can take a good low-resolution model and upgrade it to high resolution without starting from scratch.
What did they find and why it’s important?
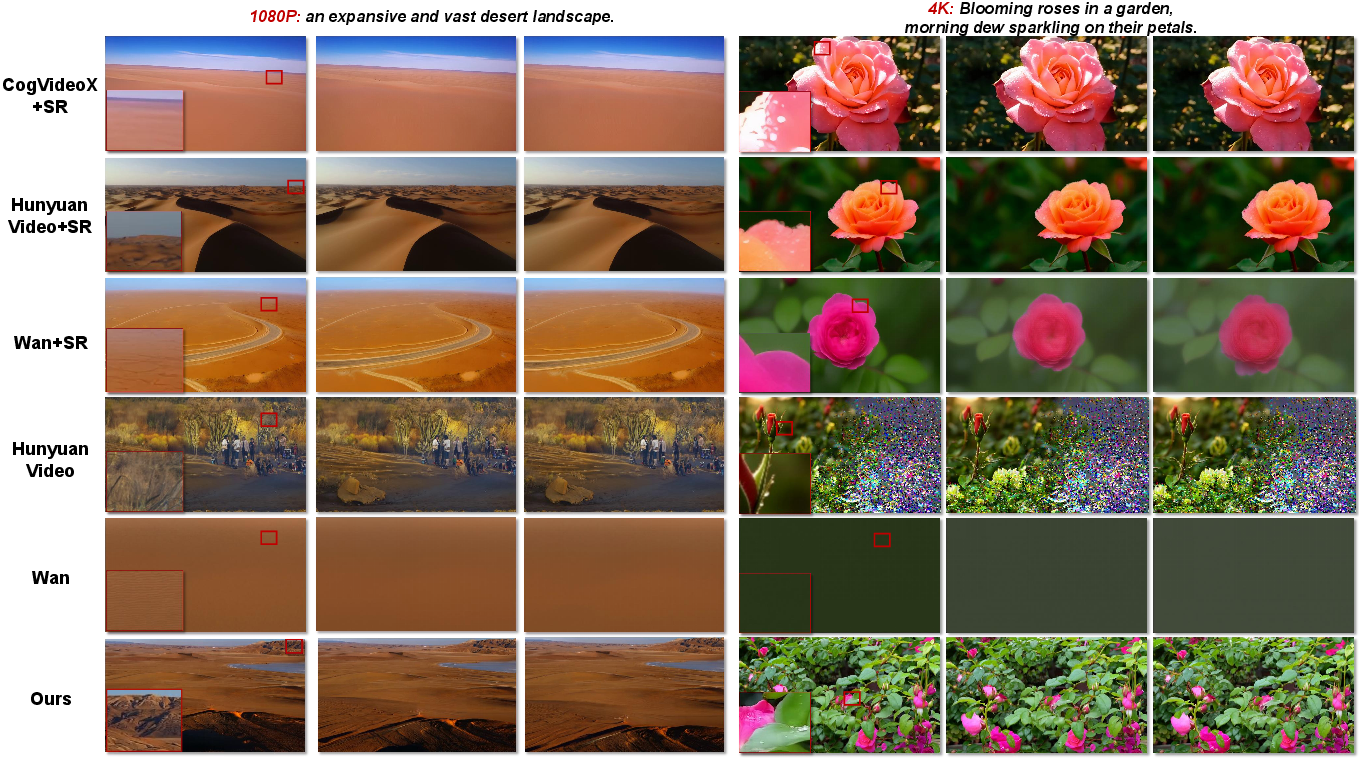
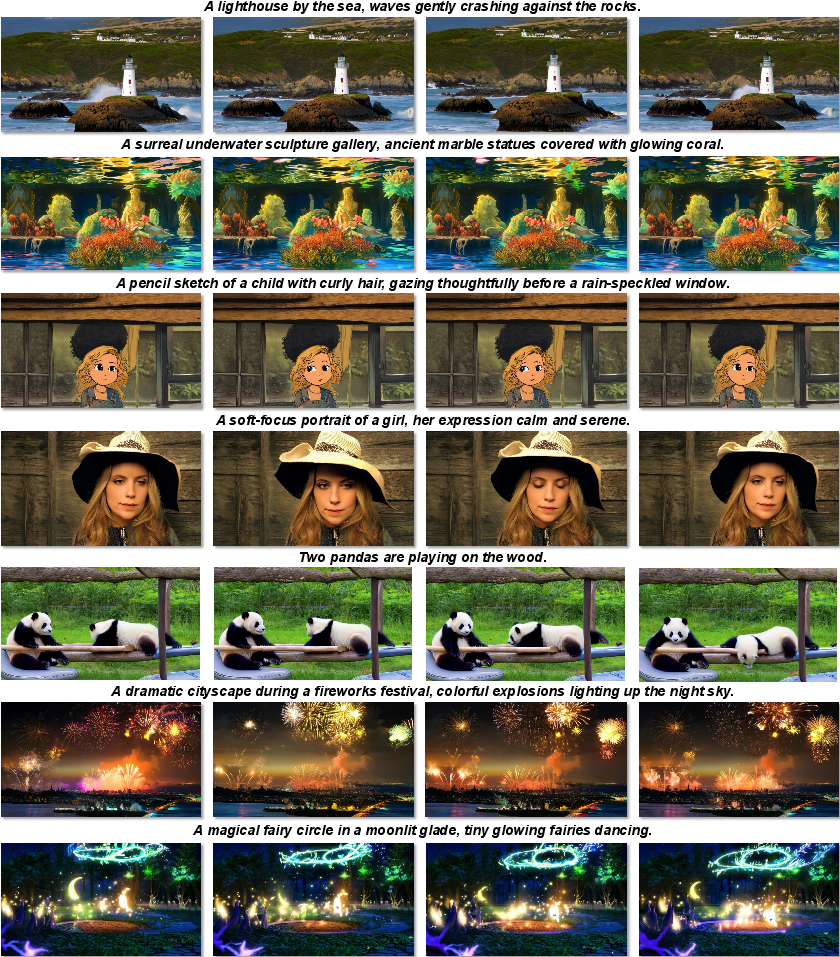
UltraGen delivers high-resolution videos that look clearer, more detailed, and more consistent than other methods, and it does so faster.
Highlights:
- It can generate native 1080P and even 4K videos directly, not just upscale smaller ones.
- It beats leading models like Wan and HunyuanVideo in both visual quality and measured scores tailored for HD.
- It avoids the common “super-resolution” shortcut, which often just sharpens the video without adding real detail.
- It runs much faster:
- About 2.7× speedup at 1080P
- About 4.78× speedup at 4K compared to a popular baseline (Wan-1.3B)
Why this matters:
- Creators can produce sharp, realistic videos with rich detail and smooth motion.
- Faster generation makes high-res video creation more practical for real projects.
What is the impact?
UltraGen shows that high-resolution video generation can be done efficiently and well. This could help:
- Filmmakers and artists create stunning videos from text prompts.
- Game designers and animators produce rich scenes quickly.
- Educators and scientists make clear, detailed visualizations.
- Social media and entertainment platforms generate high-quality content on demand.
Overall, UltraGen is a step toward AI systems that can both understand the big picture and render tiny details, making HD and 4K video generation more realistic, consistent, and fast.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, formulated as concrete, actionable gaps for future research.
- Temporal scalability remains unaddressed: attention still scales quadratically with the number of frames T within each local window ((T·W0·H0)2). Investigate temporal compression (e.g., strided temporal tokens, temporal pooling, linear attention over time, low-rank temporal adapters) to support longer durations without quadratic cost.
- Fixed, grid-based windowing may be suboptimal for dynamic content. Explore content-adaptive or deformable windowing (dynamic window sizes/positions, motion-aware partitions, learned routing) to better handle fast-moving small objects and avoid splitting salient entities across windows.
- Global branch compresses only spatially; temporal dependencies are modeled at full T. Study joint spatiotemporal compression strategies (e.g., separable temporal downsampling, temporal bottleneck tokens) and analyze their trade-offs on long-range temporal coherence.
- Lack of principled guidance for hyperparameters K (number of windows) and k (spatial compression factor). Provide systematic ablations and prescriptions for selecting K, k under different resolutions, durations, and hardware budgets (quality vs speed/memory curves).
- Potential information loss in the spatially compressed global branch (depthwise conv downsampling + bilinear upsampling + 3D conv). Quantify artifacts (e.g., text legibility, line art, thin structures), and compare alternative up/downsampling modules (subpixel convs, learned upsamplers, transformer decoders).
- Time-aware fusion α(t) depends only on the denoising step; it ignores content/context. Explore content-aware gating (e.g., predicted from latent features, noise level estimation, or attention entropy) and multi-branch fusion policies (mixture-of-experts, per-head/per-token gating).
- Domain-aware LoRA design is under-specified: no exploration of rank r, per-layer placement, sharing vs per-branch LoRA, or training stability vs quality. Provide scaling rules, memory/latency impacts, and convergence behavior across ranks.
- Generality across backbones is unproven. Validate transferability of UltraGen to other DiT-based T2V models (e.g., HunyuanVideo backbones, CogVideo-X variants) and to non-DiT backbones (Mamba-style or mixed-state-space architectures).
- Impact on low-resolution performance is unknown. Evaluate whether high-resolution fine-tuning preserves or degrades 480p–720p quality, and if multi-resolution training (curriculum or joint) can avoid regressions.
- Video length and fps constraints are not characterized. Provide maximum supported T at common fps (e.g., 16/24/30/60) across memory budgets; investigate sliding-window or keyframe-caching schemes for multi-minute generation.
- Prompt adherence trade-off is acknowledged (lower CLIP than two-stage SR). Study conditioning improvements (stronger text encoders, multi-scale cross-attention, prompt augmentation) and analyze the quality–adherence Pareto frontier at native high resolution.
- Evaluation metrics (HD-FVD, HD-MSE, HD-LPIPS) are insufficiently specified. Release metric code, reference encoders/training details, datasets/protocols, and report human preference studies to validate correlation with perception.
- Dataset transparency is lacking. Specify fine-tuning/validation datasets, resolution distributions, licensing, and domain coverage; assess cross-dataset generalization and out-of-domain robustness (e.g., scientific, medical, charts).
- Efficiency and memory profiling are incomplete. Provide per-layer FLOPs/VRAM breakdowns for local/global branches, sensitivity to K and k, kernel-level performance (FlashAttention, fused ops), and portability to consumer GPUs (24–48 GB).
- Comparisons omit several efficient attention baselines. Benchmark against ring/sparse/blockwise attention, kernelized approximations (Performer, Nyström), state-space hybrids (Mamba), and recent multi-scale DiT variants under matched compute.
- Boundary consistency is only qualitatively assessed. Introduce quantitative seam metrics (e.g., boundary LPIPS gradients, edge continuity across windows) and failure-case taxonomies (tiling, double-object duplication, seam flicker).
- Scaling beyond 4K is untested. Examine 8K and ultra-wide/aspect-ratio extremes, analyze training stability, and provide guidelines for window hierarchies and compression ratios at extreme resolutions.
- Applicability to editing and video-to-video tasks is unverified. Study how localized edits, masks, tracking constraints, or ControlNet-like modules interact with fixed windows and cross-window fusion.
- Safety, bias, and watermarking are not addressed. Evaluate content safety, demographic biases at high resolution, and integrate watermarking/detection compatible with hierarchical attention and compression.
- Audio-visual conditioning is out of scope. Explore alignment with audio tracks, lip-sync, and cross-modal coherence under the proposed attention decomposition.
- 3D convolution decompression design space is unexplored. Ablate kernel size, depth, and receptive field; compare with transformer-based temporal refiners or residual diffusion steps post-upsampling.
- Cross-window communication is limited to alternating shifted partitions across adjacent layers. Investigate additional sparse global tokens, cross-window routing layers, or learnable inter-window connectors to accelerate semantic propagation across distant windows.
- Training cost and environmental impact are not reported. Provide full training compute (GPU-hours), energy/carbon estimates, and data–compute scaling laws for achieving 1080p/4K quality.
- Reproducibility and artifact release are unclear. Clarify release plans for code, pretrained weights, and HD metric implementations; provide inference scripts and exact prompts to replicate figures and tables.
Practical Applications
Practical Applications of UltraGen: High-Resolution Video Generation with Hierarchical Attention
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. Each item includes sector mappings, potential tools/products/workflows, and key dependencies or assumptions.
Immediate Applications
- Media and Entertainment (film, TV, streaming)
- Use case: Native 1080P–4K text-to-video B‑roll, establishing shots, mood boards, and previsualization without two-stage super-resolution pipelines.
- Why now: UltraGen achieves native 4K with improved HD-FVD/LPIPS and 4.78× inference speedup vs a baseline Diffusion Transformer, making HD generation more practical for short clips (e.g., ~81 frames).
- Tools/workflows:
- UltraGen-powered “T2V Studio” for VFX/storyboarding.
- Plugins for NLE and VFX tools (e.g., Adobe Premiere/After Effects, Nuke) to generate or replace shots at 4K directly.
- Virtual production background plate generation for LED volumes.
- Dependencies/assumptions: Access to GPUs with sufficient VRAM; clip durations still limited; prompt fidelity depends on the backbone (e.g., Wan 1.3B); content safety and licensing review.
- Advertising and Marketing
- Use case: Programmatic generation of high-resolution campaign assets (4K variants, multi-aspect-ratio video creatives) with brand-consistent scenes.
- Tools/workflows:
- API-based “UltraGen Ads Renderer” integrated into adtech pipelines for batch generation and A/B testing.
- Dependencies/assumptions: Brand safety filters; prompt governance; human-in-the-loop QA; cloud compute provisioning.
- Gaming and XR
- Use case: Offline generation of cinematic intros, cutscenes, environment fly-throughs, skyboxes, and billboards at 4K for prototypes or content iteration.
- Tools/workflows:
- Unreal/Unity pipeline integration to import UltraGen outputs as assets.
- Dependencies/assumptions: Offline (non-real-time) generation; short clip length; audio/synchronization not handled by UltraGen.
- E-commerce and Retail
- Use case: Product showcase clips at 4K (angles, styles, seasonal context) for PDPs and storefronts.
- Tools/workflows:
- “Product Video Studio” that prompts UltraGen with product attributes and brand guidelines.
- Dependencies/assumptions: Legal/IP clearance for product likenesses; human review for factual correctness.
- Real Estate and Architecture
- Use case: Short, high-resolution concept videos for interior/exterior mood and design proposals.
- Tools/workflows:
- CAD/BIM-to-prompt templating for quick 4K visualizations.
- Dependencies/assumptions: Does not replace physically accurate rendering; architectural accuracy requires careful prompt design.
- Education and Corporate Training
- Use case: HD explainer clips and microlearning modules (safety procedures, device operation, onboarding content).
- Tools/workflows:
- LMS plugins to generate 1080P/4K visuals from lesson scripts/templates.
- Dependencies/assumptions: Factual accuracy verification by SMEs; content moderation.
- Synthetic Data for Computer Vision (CV)
- Use case: High-resolution synthetic datasets for training detection/tracking systems (surveillance, retail analytics, autonomous systems), improving robustness to high-resolution domains.
- Tools/workflows:
- “UltraGen Data Engine” with controllable prompts/scenes; optional pseudo-labeling pipelines.
- Dependencies/assumptions: Domain gap and physical realism constraints; careful curation and validation; licensing of pretraining datasets.
- Cloud AI Platforms and Model Serving
- Use case: Managed “HD Video Generation as a Service” with reduced cost per 4K clip vs full-attention Transformers.
- Tools/workflows:
- Autoscaling microservices using hierarchical attention; cost/capacity calculators based on UltraGen’s measured speedups.
- Dependencies/assumptions: GPU availability; throughput/latency SLAs; fair-use policies.
- Benchmarking and Evaluation (academia and industry labs)
- Use case: Adoption of HD-FVD, HD-MSE, and HD-LPIPS to evaluate HD video quality more faithfully than low-res metrics; internal leaderboards for model selection.
- Tools/workflows:
- “HD-Video Eval Suite” with reproducible scripts and reference HD datasets; CI gating in production model releases.
- Dependencies/assumptions: Availability of representative high-resolution reference sets; community validation of metric correlations with human judgment.
- Research Acceleration (computer vision and generative modeling)
- Use case: Rapid prototyping of compute-efficient architectures using global-local decomposition, spatial compression, domain-aware LoRA, and cross-window hierarchical attention.
- Tools/workflows:
- Modular PyTorch library implementing UltraGen blocks; LoRA adapters for global/hierarchical branches to reuse local weights.
- Dependencies/assumptions: Access to pre-trained low-resolution backbones (e.g., Wan 1.3B), 3D-VAEs, and training data; licensing and reproducibility constraints.
- Sustainability/Cost-Aware ML Operations
- Use case: Immediate measurement and reporting of compute/time reductions from hierarchical attention in procurement and internal sustainability dashboards.
- Tools/workflows:
- KPI dashboards linking inference time and energy estimates per generated minute at 4K.
- Dependencies/assumptions: Accurate metering of energy use; consistent benchmarking setups.
Long-Term Applications
- Real-Time or Near Real-Time 4K Generation for Interactive Media
- Use case: Live broadcast overlays, interactive AR/VR scenes, real-time virtual production elements at high resolution.
- Enablers: Further architectural optimization (e.g., fused kernels, quantization/distillation), streaming/causal attention.
- Dependencies/assumptions: Specialized accelerators; tight latency constraints; improved memory management and token caching.
- Long-Form, High-Resolution Video Generation (minutes or longer)
- Use case: Full-length 4K sequences for film previsualization, episodic content generation, synthetic training corpora.
- Enablers: Combining UltraGen with long-context methods (e.g., linear attention or recurrent state models) and test-time adaptation.
- Dependencies/assumptions: Memory-efficient training/inference; dataset scaling; continuity of global semantics over long durations.
- Physics- and Domain-Aware Generative Simulation
- Sectors: Robotics, autonomous driving, drones, smart cities.
- Use case: 4K synthetic worlds with controllable dynamics and physics-consistent motion for perception and planning.
- Enablers: Integrating physical priors, simulation feedback, and sensor models (e.g., rolling shutter, HDR).
- Dependencies/assumptions: Model grounding in physics; domain gap mitigation; safety-critical validation.
- Healthcare and Scientific Communication
- Use case: Surgical workflows, patient education, high-resolution science visualizations and experiment simulations.
- Enablers: Domain-adapted LoRA heads, expert-in-the-loop verification, knowledge-grounded prompting.
- Dependencies/assumptions: Regulatory compliance (HIPAA, MDR), clinical validation, strict content governance.
- Personalized and Customized Video Generation at 4K
- Sectors: Consumer apps, creator economy, education.
- Use case: Style- or identity-conditioned HD clips (avatars, branded content, lesson-specific videos) with fine spatial detail.
- Enablers: Efficient user-specific adapters (LoRA/PEFT) on top of UltraGen’s local/global branches.
- Dependencies/assumptions: Privacy-preserving customization; rights management; scalable adapter hosting.
- Standardization and Policy for HD Generative Video
- Use case: Formal adoption of HD video quality metrics (e.g., HD-FVD/LPIPS variants) in industry benchmarks and regulatory assessments; provenance and watermark standards for 4K generative media.
- Enablers: Cross-industry task forces (media, platforms, academia) and standard bodies to validate metrics and protocols.
- Dependencies/assumptions: Consensus on reference datasets; interoperable watermarking; alignment with platform policies.
- On-Device/Edge 4K Generation
- Sectors: XR headsets, mobile creator tools, embedded systems.
- Use case: Local generation of short HD clips without cloud dependence (privacy, latency).
- Enablers: Distillation, pruning, low-rank factorization, mixed precision; hardware support (mobile NPUs).
- Dependencies/assumptions: Significant efficiency gains beyond current speedups; memory footprint reduction; thermal/power budgets.
- General-Purpose Hierarchical Attention Engines
- Use case: Broad integration of global-local decomposed attention and spatial compression into mainstream ML frameworks for images, videos, and 3D.
- Enablers: Standardized kernels and APIs; compiler support (e.g., TensorRT, TVM).
- Dependencies/assumptions: Wide community adoption; robust reference implementations; patents/IP landscape clarity.
- Enterprise-Grade Governance for Generative HD Video
- Use case: Policy frameworks for dataset sourcing, consent management, and audit trails in high-resolution generative pipelines.
- Enablers: Tooling around dataset lineage, safety classifiers (NSFW, bias detection), and human review checkpoints.
- Dependencies/assumptions: Organizational readiness; evolving regulations; cross-jurisdictional compliance.
Notes on feasibility and assumptions that cut across applications:
- Hardware: Although UltraGen is notably faster than full-attention baselines, 1080P/4K generation is still GPU-intensive; consumer-grade local inference may be limited in the near term.
- Clip Length: Demonstrated settings focus on short clips (~81 frames); scaling duration requires additional research.
- Prompt Fidelity: High-resolution prompt adherence may depend on the underlying backbone model; CLIP alignment can lag two-stage SR pipelines.
- Data and Licensing: Training and deployment require careful handling of data rights and content safety.
- Audio and Multimodality: UltraGen targets video frames; audio generation/synchronization would require a separate component or future integration.
- Reproducibility and Tooling: Availability of pre-trained backbones (e.g., Wan 1.3B), 3D-VAEs, and open-source UltraGen modules will shape adoption speed.
Glossary
- 3D convolution: A neural network operation that processes data across three dimensions (time and space) to model spatiotemporal patterns. "we utilize a 3D convolution to perform joint spatio-temporal processing to ensure temporally consistent decompression."
- 3D variational autoencoder (3D-VAE): A generative encoder-decoder model that compresses video into a latent space across temporal and spatial dimensions. "Typically, a 3D variational autoencoder (3D-VAE) is first used to encode an input video into a latent representation"
- attention map: The matrix of similarity scores in self-attention indicating how tokens attend to each other. "the self-attention module computes an attention map, which scales quadratically with the sequence length."
- attention window: A restricted spatial region within which attention is computed to reduce cost. "by introducing an attention window of size ."
- bilinear interpolation: A method to upsample images by linearly interpolating pixel values in two dimensions. "we first apply bilinear interpolation to upsample the spatial resolution from to ."
- CLIP score: A metric that measures alignment between visual content and text prompts using the CLIP model. "Additional CLIP score~\cite{clip} and temporal consistency~\cite{huang2024vbench} are included for a more comprehensive evaluation."
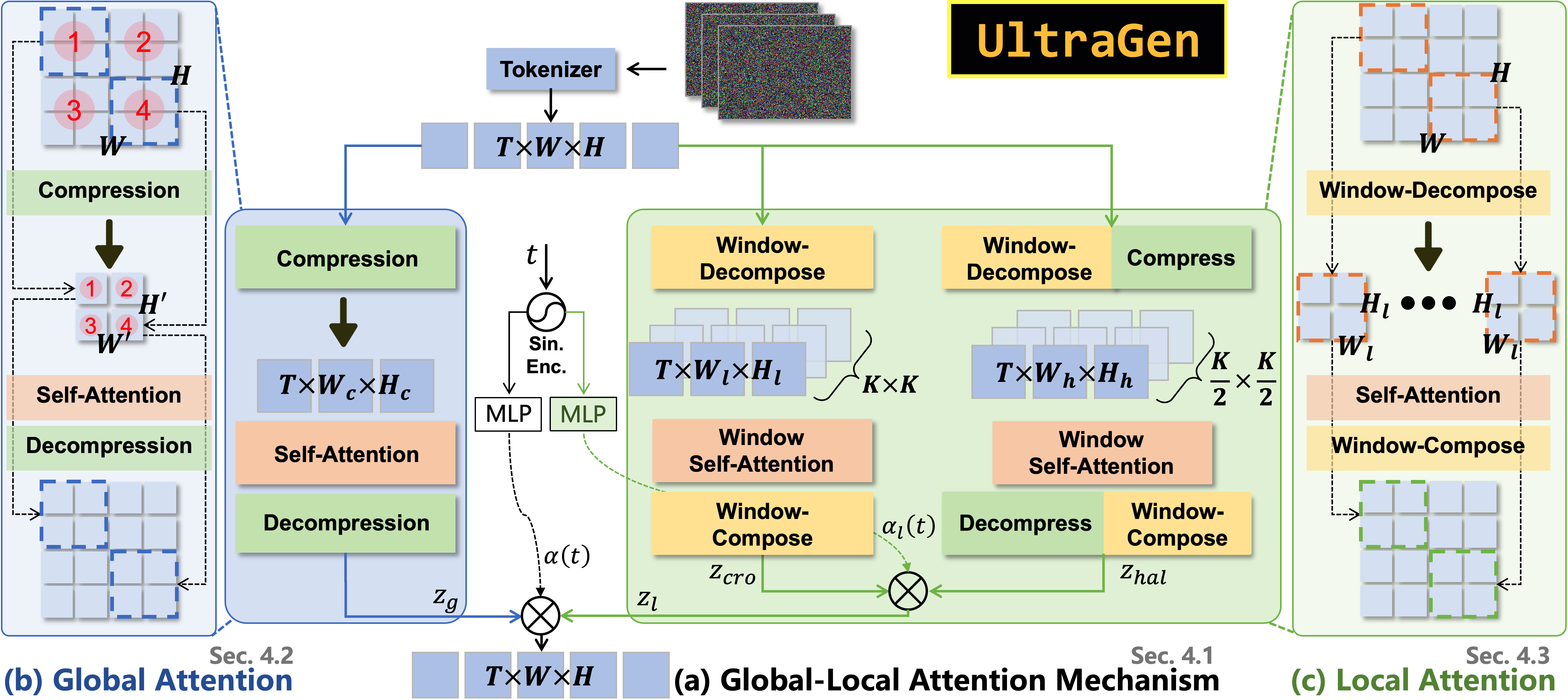
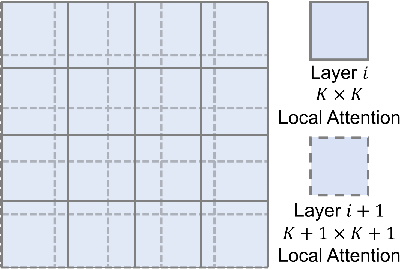
- cross-window local attention: An attention scheme that enables interaction across neighboring local windows to reduce boundary artifacts. "This cross-window local attention strategy enables hierarchical interaction across neighboring windows between adjacent transformer layers."
- denoising timesteps: Iteration indices in the diffusion process indicating stages of noise removal and detail refinement. "During the diffusion process, different denoising timesteps focus on various video aspects"
- diffusion process: The iterative generative procedure that starts from noise and denoises to produce samples. "During the diffusion process, different denoising timesteps focus on various video aspects"
- diffusion transformer (DiT): A transformer-based architecture specialized for diffusion models in vision tasks. "With DiT~\cite{flux2024}, transformer-based architectures have become the leading paradigm in video generation"
- domain-aware LoRA: A low-rank adaptation technique specialized to a particular attention domain (e.g., global) using lightweight residuals. "we propose a domain-aware LoRA mechanism, which adapts the local attention parameters for global modeling."
- depthwise convolution: A convolution where each channel is processed independently, reducing parameters and computation. "we adopt a channel-wise (i.e., depthwise) convolution mechanism"
- FFN (feed-forward network): The per-token multi-layer perceptron within transformer blocks that processes attended features. "for each projection weight and the FFN parameters $W_{\text{FFN}$, we introduce a lightweight, trainable low-rank residual"
- full self-attention: Attention computed across all tokens in the sequence, modeling long-range dependencies but at high cost. "Full self-attention is then used to jointly model spatial and temporal relationships"
- global attention: An attention mechanism that models interactions across the entire spatial domain to ensure semantic consistency. "we introduce a global attention module to capture long-range dependencies and ensure semantic consistency."
- global-local attention decomposition: Splitting attention into global and local branches to balance efficiency and coherence. "UltraGen features a hierarchical dual-branch attention architecture based on global-local attention decomposition"
- global-local fusion module: A component that combines global and local features, often with a learnable mixing factor. "we introduce a global-local fusion module that combines these representations using a learnable fusion factor ."
- HD-FVD: A high-resolution variant of Fréchet Video Distance for measuring realism and diversity in HD videos. "HD-FVD measures the similarity between generated and real high-resolution videos"
- HD-LPIPS: A high-resolution variant of the perceptual similarity metric LPIPS to assess semantic-level detail. "2) HD-MSE and 3) HD-LPIPS assess the fine-grained pixel-level and semantic-level~\cite{zhang2018lpips} details of the generated videos, respectively."
- HD-MSE: A high-resolution mean squared error metric evaluating pixel-level fidelity. "2) HD-MSE and 3) HD-LPIPS assess the fine-grained pixel-level and semantic-level~\cite{zhang2018lpips} details of the generated videos, respectively."
- Hierarchical Local Attention (HLA): An intermediate-scale local attention that captures finer motion/details beyond basic local windows. "we introduce a Hierarchical Local Attention (HLA) mechanism"
- hierarchical cross-window local attention mechanism: A design that partitions windows differently across layers to create overlaps and improve continuity. "a hierarchical cross-window local attention mechanism to reduce computational costs while enhancing information flow across different local windows."
- latent representation: The compressed internal feature tensor produced by an encoder capturing essential video information. "encode an input video into a latent representation"
- local attention: Attention computed within small spatial windows to reduce complexity while preserving fine details. "The local attention branch focuses on generating fine-grained %high-resolution content within individual black{local spatial windows}"
- LoRA: Low-Rank Adaptation; a technique to efficiently adapt model weights via low-rank updates. "we propose a domain-aware LoRA mechanism"
- MLP: A multi-layer perceptron used to project features, such as time embeddings, into desired dimensions. "then project it into a -dimensional fusion factor via an MLP"
- patchify module: A component that reshapes spatial-temporal latents into a sequence of tokens by partitioning into patches. "black{Then, the video latents are reshaped into a 1D token sequence with sequence length via a patchify module.}"
- shifted window strategy: Alternating window partitioning across layers to create overlaps and share boundary information. "we apply a shifted window strategy with partitions that partially overlap with the even-layer windows."
- Sinusoidal Encoding: A positional encoding method using sinusoidal functions to embed scalar inputs like timesteps. "We embed into a 256-dimensional time feature vector using Sinusoidal Encoding"
- spatially compressed global modeling strategy: Compressing spatial dimensions before attention to reduce cost while modeling global context. "We further propose a spatially compressed global modeling strategy to efficiently learn global dependencies"
- Spatially-Compressed Global Attention: Performing attention on spatially downsampled latents, then decompressing with spatiotemporal ops. "Spatially-Compressed Global Attention"
- spatiotemporal dependencies: Relationships across both space and time in video data. "to model spatiotemporal dependencies in video sequences."
- stride: The step size of convolution kernels across input dimensions, controlling downsampling. "with stride along the spatial dimensions "
- super-resolution: A post-processing method to upscale low-resolution outputs to higher resolution, often enhancing sharpness. "video super-resolution models"
- temporal consistency: The stability and coherence of content across consecutive frames in a video. "Our model also achieves the best temporal consistency"
- time-aware global-local composition: A fusion strategy where global/local mixing weights depend on the diffusion timestep. "Time-aware Global-Local Composition."
- token sequence: A flattened sequence of spatiotemporal patches used as transformer inputs. "reshaped into a 1D token sequence with sequence length "
- two-stage pipeline: A generation approach that first produces low-resolution video and then upsamples via super-resolution. "resort to a two-stage pipeline that first generates low-resolution videos and subsequently applies video super-resolution models."
- quadratic computational complexity: Cost that scales with the square of sequence length or resolution, typical of full attention. "quadratic computational complexity of the full-attention mechanism"
Collections
Sign up for free to add this paper to one or more collections.

