- The paper introduces a Multilingual Grade School Math (MGSM) benchmark, showing that Chain-of-Thought prompting improves reasoning in multiple languages.
- It employs various prompting strategies with models like GPT-3 and PaLM, revealing that intermediate reasoning steps markedly boost performance, especially in PaLM-540B.
- Findings indicate that increased model scale and optimized CoT prompts enable robust cross-lingual generalization, paving the way for advanced multilingual AI systems.
LLMs as Multilingual Chain-of-Thought Reasoners
Introduction
The paper "LLMs are Multilingual Chain-of-Thought Reasoners" (2210.03057) presents an inquiry into the multilingual reasoning capacities of LLMs. The study evaluates these capacities using a newly developed Multilingual Grade School Math (MGSM) benchmark, which involves the manual translation of 250 math problems from the GSM8K dataset into ten languages. This benchmark allows for a comprehensive examination of LLMs across diverse languages, including underrepresented ones like Bengali and Swahili. A notable outcome is the emergence of an ability to solve tasks through chain-of-thought (CoT) prompting, which improves markedly with model scale. Additionally, the multilingual reasoning competence is not limited to mathematical tasks but extends to commonsense reasoning and semantic judgments.
MGSM Benchmark
The MGSM benchmark represents an innovative approach to evaluating multilingual reasoning by extending GSM8K problems into ten typologically distinct languages. This is a pioneering effort to examine the arithmetic reasoning abilities in a multilingual context. The MGSM dataset leverages manual translation to ensure linguistic accuracy across languages such as Chinese, German, French, and others less represented in LLMs' pre-training data. This manual translation process involved professional translators and rigorous quality assurance measures to ensure the integrity of the benchmark.
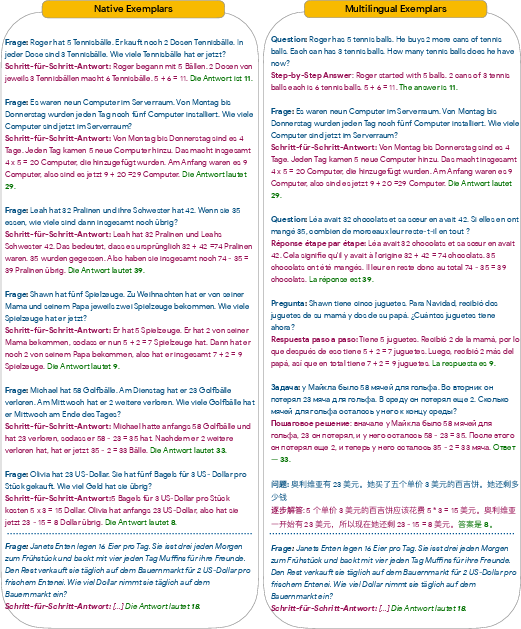
Figure 1: Prompt template with CoT in the question language (Native-CoT), solving a problem in German.
Multilingual Chain-of-Thought Prompting
Chain-of-thought prompting facilitates the depiction of reasoning steps that guide LLMs in solving complex problems. This technique proves to be impactful in multilingual settings as well. Various prompting strategies are explored, including Direct, Native-CoT, EN-CoT, and Translate-EN. The study identifies that English CoT (EN-CoT) often yields competitive results compared to reasoning directly in the problem's native language (Native-CoT), suggesting a robust capability for cross-lingual transfer when leveraging English intermediate steps.
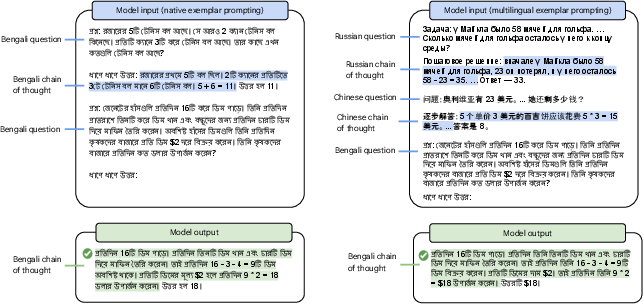
Figure 2: The chain-of-thought prompts and example model outputs in the MGSM experiments. The solutions are written in the same language as the questions of interest (Native-CoT).
Experiments on MGSM
The paper's experimental evaluation involves two prominent LLMs, GPT-3 and PaLM. The findings underscore that intermediate reasoning steps significantly enhance the models' performance across all languages, especially for the PaLM-540B model, which demonstrates exceptional multilingual reasoning skills irrespective of the language's representation in the training data. Furthermore, Explore-EN settings enabled PaLM to achieve a remarkable average solve rate across languages, showcasing adaptability of English-based reasoning prompts.

Figure 3: Prompt template in the English CoT setting (EN-CoT), solving a problem in German.
Extension to Other Benchmarks
Besides MGSM, the study broadens its scope to encompass other multilingual reasoning benchmarks like XCOPA and XL-WiC. On XCOPA, PaLM achieves state-of-the-art performance by adopting multilingual CoT prompting, surpassing previous approaches that rely on extensive training data. The XL-WiC findings further illustrate PaLM's efficacy in context-based semantic judgments, despite the task's inherent challenges.

Figure 4: The multilingual chain-of-thought prompt used in the XL-WiC experiments.
Implications and Future Directions
This comprehensive analysis suggests that as LLMs increase in scale, their capacity for multilingual reasoning dramatically improves, allowing for robust cross-lingual generalization. Such advancements are crucial for the development of multilingual AI systems with nuanced reasoning capabilities. Future work might explore optimizing CoT prompts and extending benchmarks to include even more diverse languages and reasoning tasks. By enhancing multilingual prompts, researchers can further uncover and refine the transferable reasoning attributes seen in large-scale models.
Conclusion
The paper demonstrates that LLMs possess formidable multilingual reasoning abilities by employing CoT prompting strategies, thereby paving the way for more informed evaluations in multilingual contexts. The introduction of the MGSM benchmark plays a pivotal role in this exploration, providing invaluable insights into LLM capabilities across a spectrum of languages. Ultimately, these findings not only advance the understanding of LLMs but also inspire continued research into optimizing multilingual reasoning across diverse AI applications.

