- The paper introduces the Parallel Scaling Law, showing a power-law relationship between the number of training languages and reasoning generalization.
- It employs the Multilingual Transferability Index and analyzes RL and SFT paradigms to quantify cross-lingual performance improvements.
- The study finds that bilingual training yields a significant boost, revealing a Monolingual Generalization Gap in English-only models.
Parallel Scaling Law and Cross-Linguistic Reasoning Generalization in Large Reasoning Models
Introduction
This paper presents a systematic investigation into the cross-lingual generalization of Large Reasoning Models (LRMs) trained primarily on English data, with a particular focus on the effects of Reinforcement Post-Training (RPT) and parallel data exposure. The authors introduce the Multilingual Transferability Index (MTI) to quantify reasoning transfer across languages and propose the Parallel Scaling Law, a power-law relationship governing the improvement in cross-lingual reasoning as the number of parallel training languages increases. The study is structured into observational, interventional, and parallel training experiments, providing a comprehensive analysis of the factors influencing multilingual reasoning generalization.
Observational Study: Cross-Lingual Transferability in Open-Source LRMs
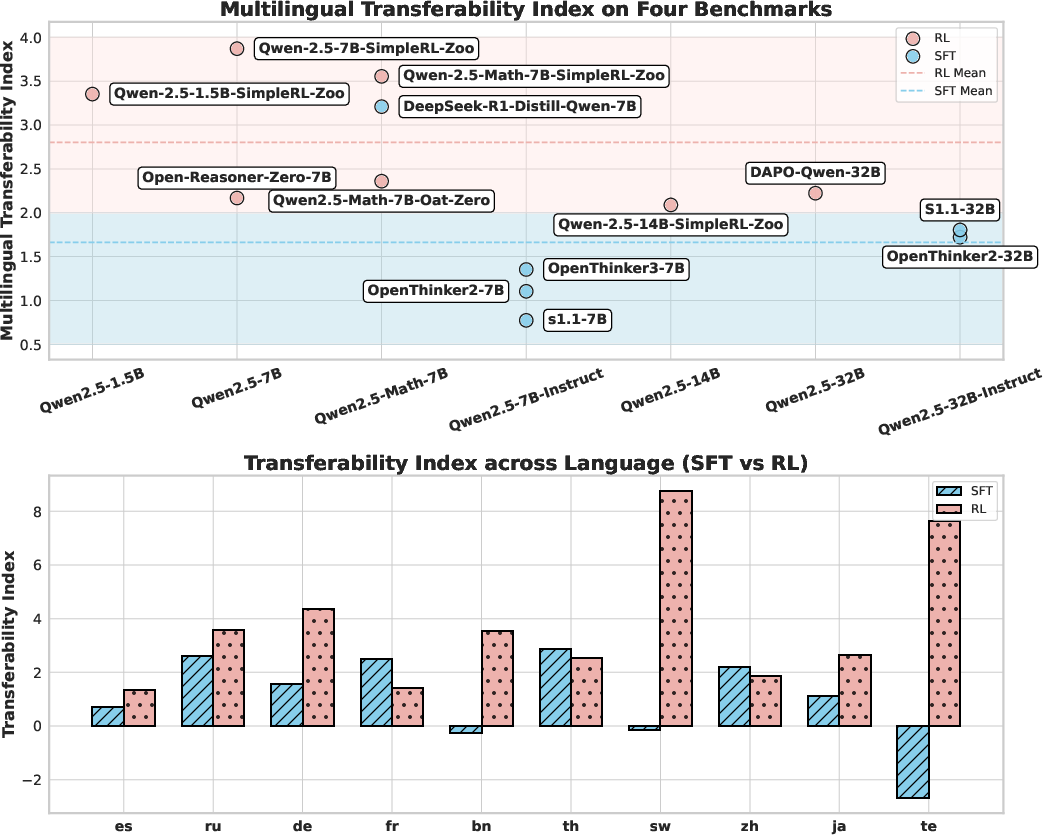
The initial observational study evaluates 13 open-source English-centric LRMs across four multilingual reasoning benchmarks (MATH500, AIME24, AIME25, GPQA-Diamond) and eleven languages. The MTI metric is used to assess the relative gain in reasoning accuracy for unseen languages compared to the training set.
Key findings include:
Interventional Study: Isolating Factors in Reasoning Generalization
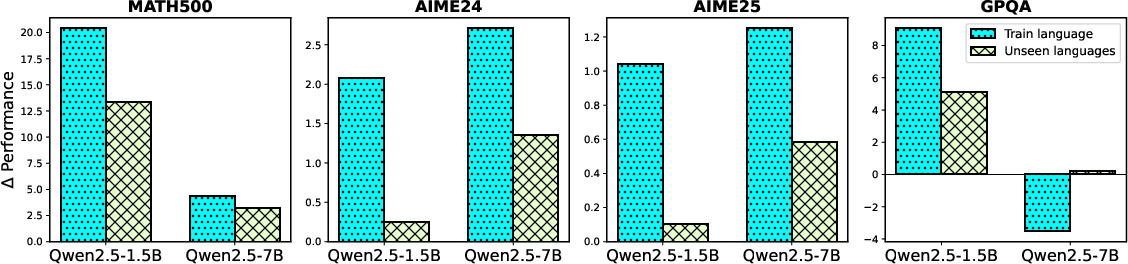
To control for confounding variables, the interventional study systematically varies initial model type, model family, and model size using a curated dataset and the GRPO algorithm for RPT.
Initial Model Type
- Instruction-tuned models achieve the highest reasoning accuracy and language consistency but exhibit lower MTI compared to base and math-specialized models.
- Base and math-specialized models retain more general pre-trained knowledge, resulting in higher cross-lingual transferability.
Model Family
Model Size
Parallel Training Study: The Parallel Scaling Law
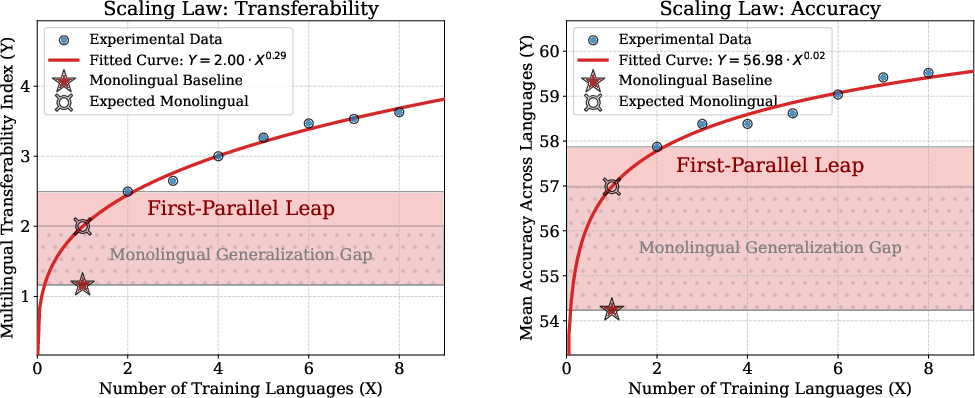
The parallel training study exposes models to parallel data in up to seven languages, revealing three key phenomena:
First-Parallel Leap
- The transition from monolingual to bilingual training yields a disproportionately large improvement in both accuracy and MTI, far exceeding the cumulative gains from additional languages.
Parallel Scaling Law
Monolingual Generalization Gap
- The actual performance of English-only models falls short of the power-law prediction, revealing a Monolingual Generalization Gap. This gap indicates that reasoning skills acquired through monolingual training are not fully language-agnostic.
Analysis: Parallel vs. Unparallel Data and Language Selection
Parallel data provides explicit semantic equivalence signals, forcing the model to learn unified, language-agnostic reasoning representations. Training with unparallel data yields inferior performance, underscoring the necessity of parallel exposure.

Figure 5: Accuracy difference comparison across parallel and unparallel data training, demonstrating the superiority of parallel data.
The choice of parallel language has only minor effects on MTI and off-target rates, with low-resource languages consistently benefiting the most from parallel training.

Figure 6: Multilingual reasoning performance across different parallel languages, showing consistent gains regardless of language selection.
Implications and Future Directions
The findings challenge the assumption that LRM reasoning mirrors human cognition, as human reasoning is largely language-independent. The observed over-reliance on English-specific patterns in strong English-centric models suggests that current LRM architectures and training paradigms do not fully disentangle reasoning from linguistic processing. The Parallel Scaling Law provides a principled framework for improving cross-lingual generalization, with practical implications for building more robust, language-agnostic LRMs.
Future research should extend these analyses to other domains (e.g., coding, agent planning), develop advanced parallel training strategies to overcome diminishing returns, and pursue mechanistic interpretability to elucidate the internal representations underlying reasoning and language coupling.
Conclusion
This work establishes a rigorous framework for understanding and improving cross-lingual reasoning generalization in LRMs. The introduction of the Multilingual Transferability Index, the identification of the First-Parallel Leap, and the formulation of the Parallel Scaling Law collectively advance the field's understanding of multilingual reasoning. The Monolingual Generalization Gap highlights the limitations of current approaches and motivates the development of more language-agnostic reasoning models. These insights are critical for the next generation of LRMs capable of robust, universal reasoning across diverse linguistic contexts.