- The paper introduces a speculative sampling framework using Taylor series expansion to forecast future features, effectively reducing full computation steps.
- It employs a lightweight draft model combined with a layer-wise L2 error metric for verifying predictions and adaptively allocating computation.
- Experimental results demonstrate up to 7x speedup in text-to-image and text-to-video tasks while maintaining high fidelity and semantic alignment.
Introduction and Motivation
Diffusion models (DMs), particularly those based on transformer architectures (DiT), have become the backbone of high-fidelity image and video synthesis. However, their sequential denoising process, which requires a full forward pass at each timestep, imposes severe computational constraints, especially for real-time or resource-limited deployment. Existing acceleration methods—step reduction, model compression, and feature caching—either degrade output quality at high acceleration ratios or suffer from error accumulation due to lack of robust validation mechanisms. SpeCa introduces a principled speculative sampling framework, inspired by speculative decoding in LLMs, to address these limitations by forecasting future features and verifying their reliability before acceptance.
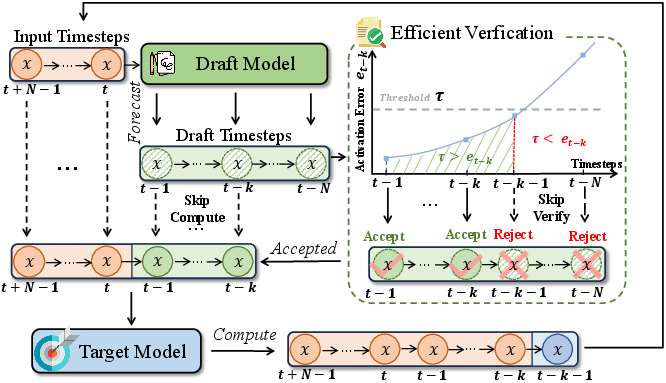
Figure 1: SpeCa's speculative execution workflow, showing draft prediction, lightweight verification, and adaptive fallback to full computation.
Methodology
Speculative Sampling via Feature Caching
SpeCa operates in three stages: (1) full forward computation at selected key timesteps, (2) multi-step feature prediction using a lightweight draft model (TaylorSeer), and (3) sequential verification of predicted features via a parameter-free, layer-wise error metric. The draft model leverages Taylor series expansion to forecast features for $k$ future timesteps, requiring no additional training and incurring negligible computational overhead.
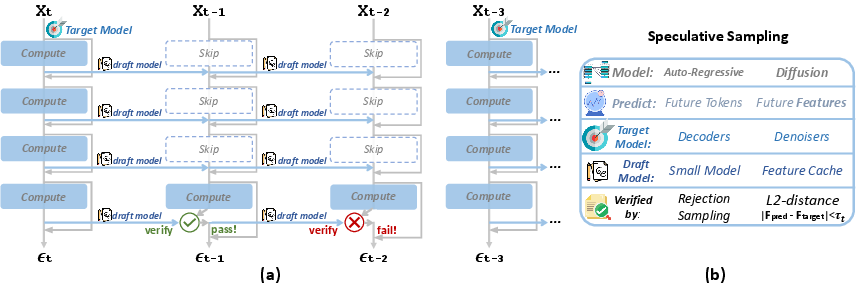
Figure 2: Overview of the SpeCa framework, highlighting TaylorSeer-based feature prediction, L2-based verification, and adaptive computation allocation.
Verification and Adaptive Computation
Predicted features are validated using a relative $\ell_2$ error metric at a deep layer (typically layer 27 in DiT), which exhibits strong correlation with final output quality. If the error at any step exceeds a dynamic threshold $\tau_t$, the prediction is rejected and the main model resumes full computation from the last accepted step. The threshold decays exponentially with timestep, allowing aggressive acceleration in early noisy stages and stricter checks as fine details emerge.
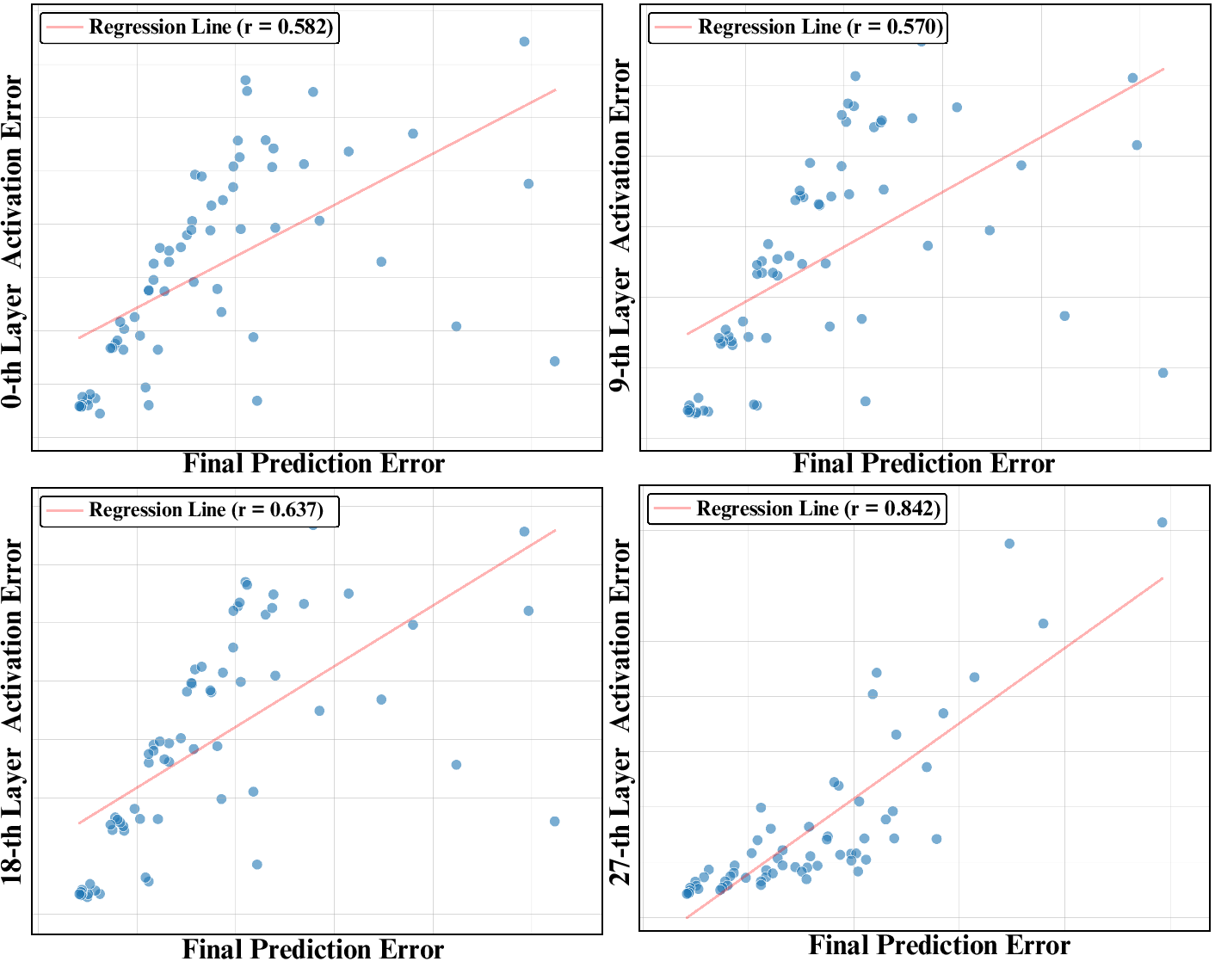
Figure 3: Strong correlation between errors at layer 27 and final output, validating deep layer monitoring for verification.
Computational Complexity
Let $T$ be the total number of timesteps, $\alpha$ the acceptance rate of speculative predictions, and $\gamma$ the verification cost ratio. The overall speedup is given by:
$\mathcal{S} = \frac{1}{1-\alpha + \alpha \cdot \gamma}$
Empirically, $\gamma < 0.05$ and $\alpha \approx 0.85$ yield $5\times$–$7\times$ acceleration with minimal quality loss.
Experimental Results
Text-to-Image Generation
On FLUX.1-dev, SpeCa achieves a $6.34\times$ acceleration with only a $5.5\%$ drop in ImageReward, outperforming all baselines. At high acceleration ratios, competing methods (TeaCache, TaylorSeer, ToCa, DuCa) exhibit catastrophic quality degradation, while SpeCa maintains robust fidelity and semantic alignment.
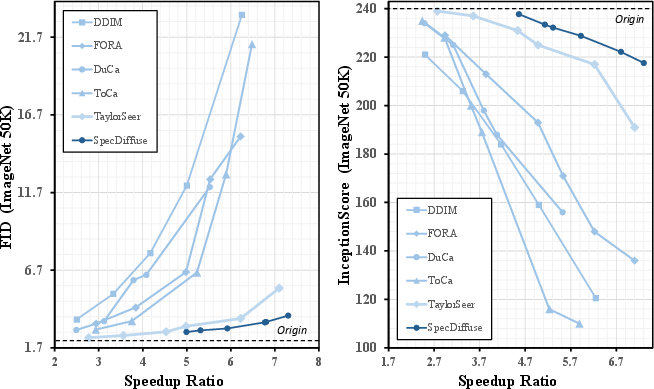
Figure 4: Comparison of caching methods in terms of Inception Score (IS) and FID. SpeCa achieves superior performance, especially at high acceleration ratios.
Figure 5: SpeCa preserves object morphology and detail, avoiding spelling errors and distortions seen in other methods.
Figure 6: Text-to-image comparison: SpeCa achieves visual fidelity on par with FLUX.
Text-to-Video Generation
On HunyuanVideo, SpeCa attains $6.16\times$ acceleration with a VBench score of $79.84\%$, matching or exceeding the quality of full-step inference and outperforming all step-reduction and caching baselines.
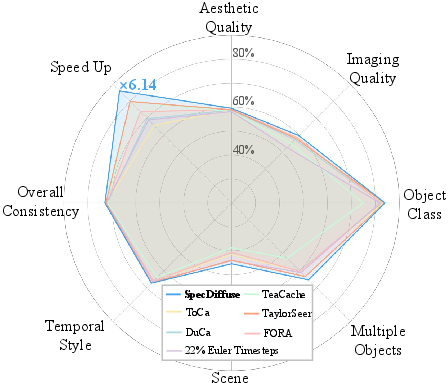
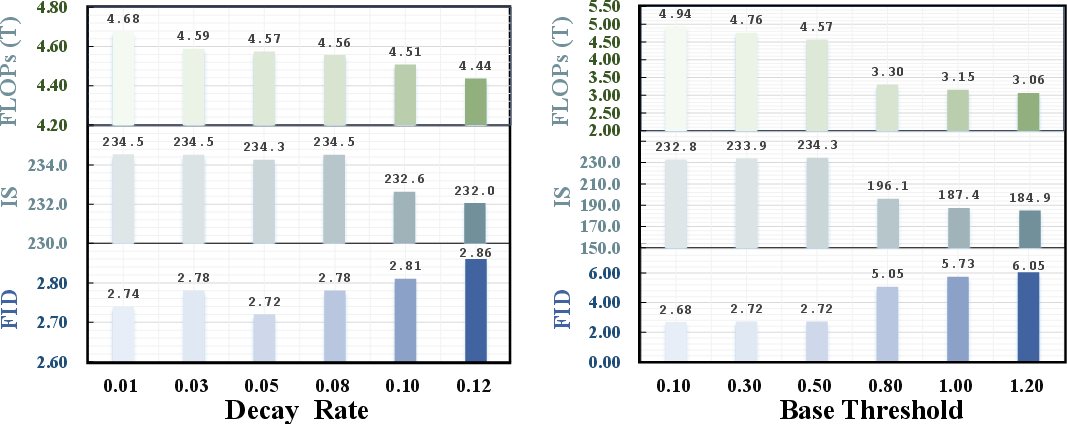
Figure 7: VBench performance of SpeCa versus baselines, demonstrating superior quality-efficiency tradeoff.
Class-Conditional Image Generation
On DiT-XL/2, SpeCa delivers $7.3\times$ acceleration with FID $3.78$, outperforming DDIM step reduction (FID $23.13$ at $6.25\times$) and all feature caching methods. The method maintains trajectory alignment with the original diffusion process, as confirmed by PCA analysis.
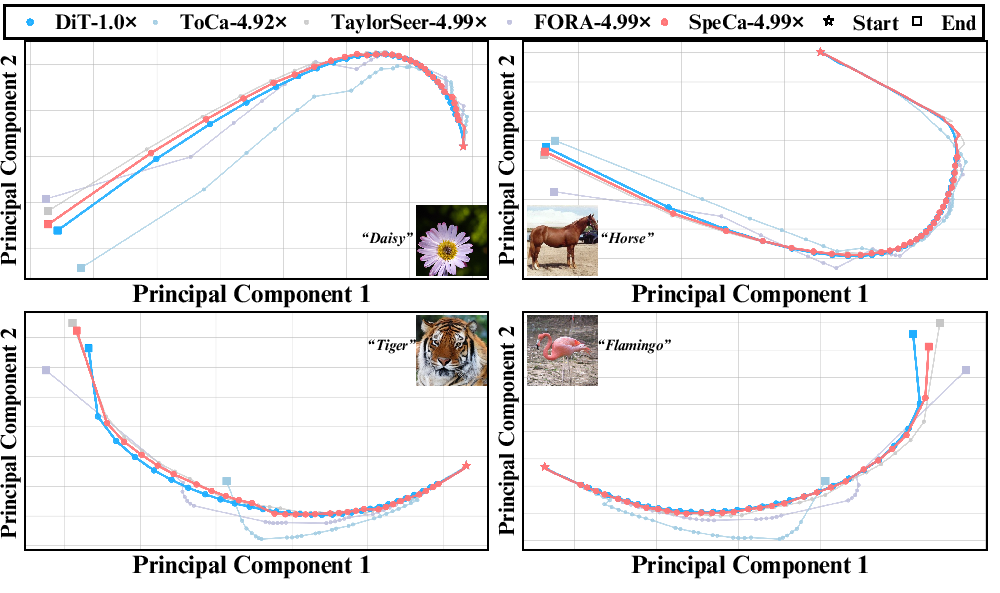
Figure 8: Scatter plot of feature evolution trajectories; SpeCa closely tracks the original diffusion path even at high acceleration.
Ablation and Theoretical Analysis
Hyperparameter studies reveal that base threshold $\tau_0$ and decay rate $\beta$ control the trade-off between acceleration and quality. Deep layer validation is essential for robust error detection. TaylorSeer outperforms alternative draft models (Adams-Bashforth, direct reuse) in both accuracy and stability. The $\ell_2$-norm is the optimal error metric for verification, balancing semantic sensitivity and computational efficiency.
Practical Implications and Future Directions
SpeCa is a plug-and-play framework requiring no retraining, compatible with any transformer-based diffusion model. Its sample-adaptive computation allocation enables efficient resource usage, accelerating simple samples more aggressively while preserving quality for complex cases. The method is agnostic to noise schedule and model architecture, facilitating broad adoption in real-world generative applications, including mobile and edge deployment.
Theoretically, SpeCa guarantees distributional convergence to the original model under appropriate threshold scheduling, with error propagation tightly controlled via martingale analysis. Future work may extend speculative sampling to multimodal and non-visual domains, integrate with hardware-aware optimizations, and explore synergies with pruning and quantization for further efficiency gains.
Conclusion
SpeCa establishes a new paradigm for efficient diffusion model inference, combining speculative feature prediction, rigorous layer-wise verification, and adaptive computation allocation. It achieves state-of-the-art acceleration ratios with minimal quality degradation across diverse generative tasks and architectures. The framework's theoretical guarantees and empirical robustness position it as a benchmark for future research in scalable, high-fidelity generative modeling.