- The paper introduces FORA, which leverages caching of intermediate outputs in Diffusion Transformers to bypass redundant computations.
- The method recalculates features every N-th time step to balance computational savings and output quality without retraining.
- Experimental evaluations on ImageNet and MSCOCO demonstrate up to 8-fold speed improvements with minimal impact on quality metrics like FID.
Introduction
The emergence of diffusion models has transformed generative tasks, capitalizing on their robust capabilities to generate high-quality, diverse outputs. However, as these models scale, particularly with the advent of Diffusion Transformers (DiT), the computational demands for inference grow significantly. Addressing this challenge, Fast-Forward Caching (FORA) offers an elegant solution by integrating a caching mechanism that harnesses the repetitive nature of the diffusion process. This essay explores the FORA method, examining its integration with existing DiT frameworks and its potential to enhance real-time application capabilities.
Methodology
FORA builds on existing research efforts that have sought to optimize diffusion models' efficiency by caching redundant computations. Notably, while prior methods have predominantly focused on U-Net diffusion models, FORA specifically targets transformer-based models. The core premise involves caching and reusing intermediate outputs from attention and MLP layers in DiTs. This strategy reduces computational overhead, eliminating the need for model retraining and promoting seamless integration with existing transformer-based diffusion frameworks.
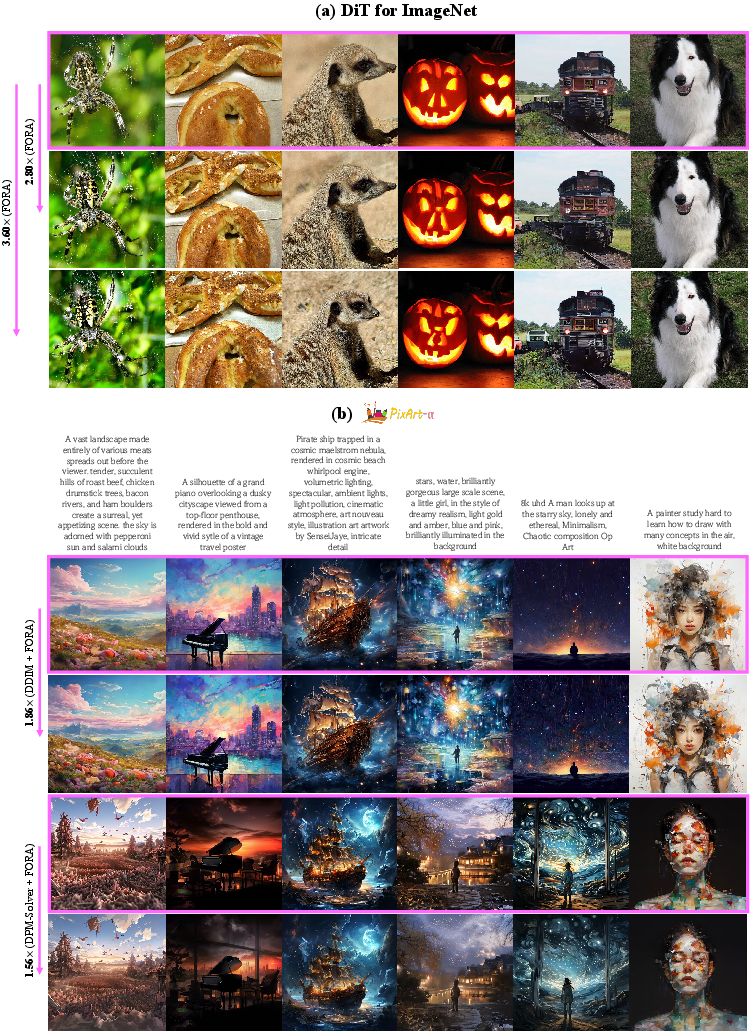
Figure 1: Image generations with FORA on DiT and PixArt-. The image sizes are 512 × 512.
Static Caching Mechanism
The study identifies feature similarities across time steps in diffusion models, suggesting opportunities for computational optimization. FORA's static caching mechanism capitalizes on this by recomputing and caching features at regular intervals, determined by a hyperparameter N. This approach involves recalculating features for every N-th time step, subsequently reusing these cached features in intermediate steps to bypass redundant calculations. This method balances computational savings with output quality by adjusting N.
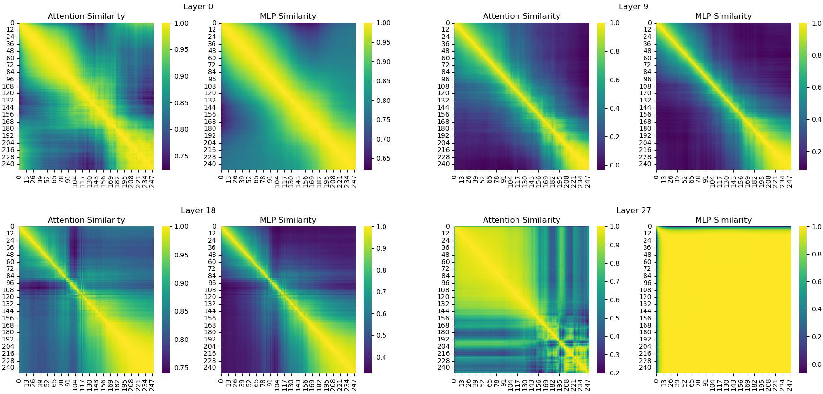
Figure 2: Feature similarity analysis across time steps in DiT for attention and MLP layers.
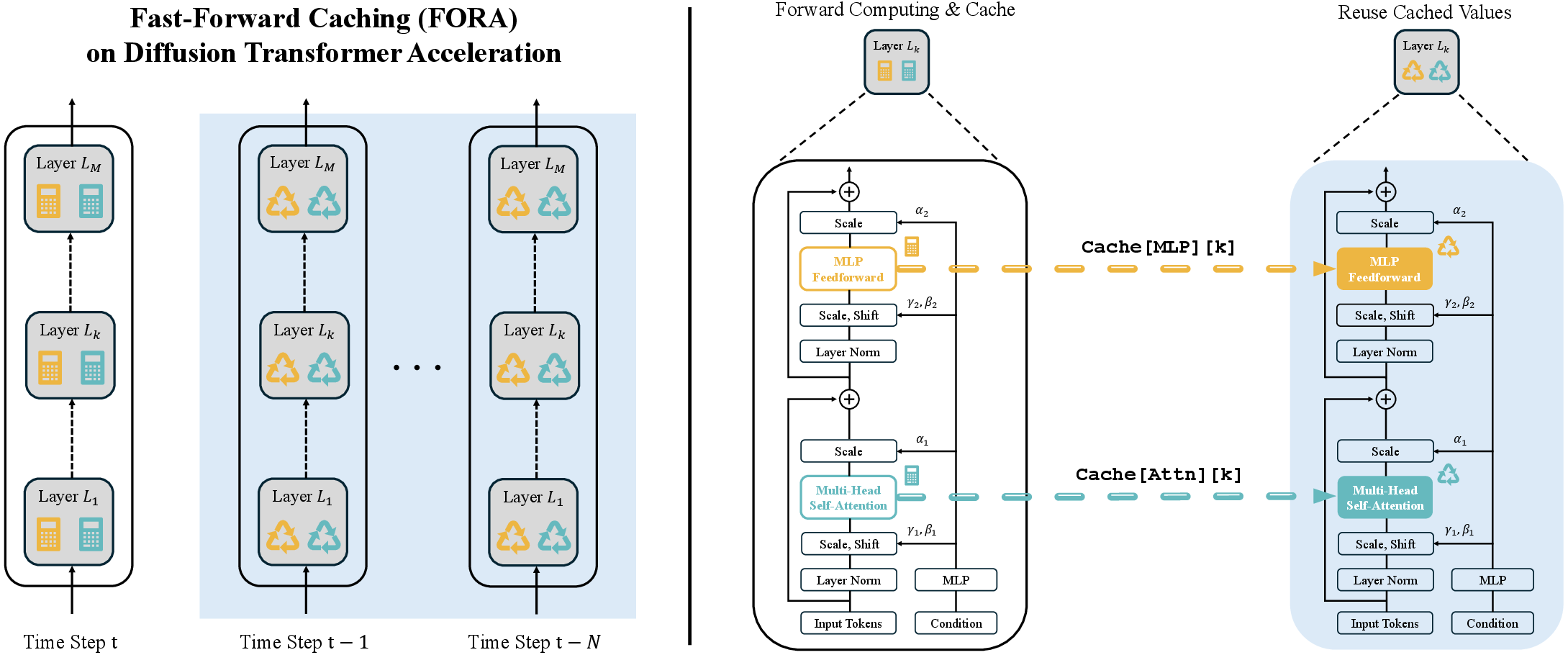
Figure 3: Static Caching in FORA for DiT architecture.
Experimental Evaluation
The performance of FORA was evaluated across several aspects, with significant attention given to its integration with state-of-the-art models like DiT and PixArt-α. Tests conducted on ImageNet and MSCOCO datasets demonstrated that FORA achieves notable speed enhancements, with evaluations indicating up to an 8-fold acceleration in some configurations without a significant compromise in quality metrics such as the FID score.
Implications and Future Directions
FORA represents a significant step forward for transformer-based diffusion models, particularly in real-time applications where computational efficiency is paramount. The methodology not only addresses existing bottlenecks but sets the stage for further refinements. Future work could explore dynamic caching mechanisms that adapt more precisely to the inherent temporal patterns of diffusion processes, potentially unlocking even greater efficiencies.
In summary, Fast-Forward Caching stands as a promising approach for mitigating the intensive computational demands of advanced diffusion models. Its capacity to enhance real-time processing without losing sight of output quality underscores its potential impact across various applications, from image synthesis to broader generative tasks.