- The paper introduces a probabilistic framework that models language and audio data using Gaussian embeddings to address many-to-many correspondences.
- It employs novel loss functions, including Probabilistic Pairwise Contrastive Loss and Hierarchical Inclusion Loss, to enhance semantic hierarchy learning.
- Experimental results demonstrate improved audio-text retrieval and semantic understanding over deterministic models like CLAP.
ProLAP: Probabilistic Language-Audio Pre-Training
Introduction
The integration of language and audio data into a cohesive representation framework has significantly advanced the domain of audio understanding. Traditional models, such as Contrastive Language-Audio Pre-training (CLAP), have facilitated this development by employing deterministic embeddings that assume a one-to-one correspondence between audio and text. However, this assumption falls short in real-world scenarios where the relationship between language and audio is inherently many-to-many. For instance, a single audio segment may align with multiple textual descriptions varying in specificity and paraphrase content.
In response to these limitations, the study introduces Probabilistic Language-Audio Pre-training (ProLAP), which represents language-audio joint embeddings using probability distributions rather than fixed point vectors. This approach leverages probabilistic modeling to address the complexities of many-to-many correspondences in audio-text data, capturing the semantic hierarchy present in the data more effectively than prior deterministic approaches.
Methodology
ProLAP innovatively extends the CLAP framework by introducing a probabilistic embedding space where each input is modeled as a Gaussian random variable with a specific mean and variance. This probabilistic approach accommodates the uncertainty and variability inherent in audio-text correspondences, which deterministic embeddings struggle to capture.
Model Overview:
- Encoders: ProLAP employs separate encoders for audio and text inputs, learning shared representations through Gaussian distributions.
- Loss Functions: The probabilistic framework necessitates novel loss functions to optimize learning effectively:
- Probabilistic Pairwise Contrastive Loss (PPCL): Integrates probabilistic distance measures in place of traditional cosine similarity to account for the distributional nature of embeddings.
- Hierarchical Inclusion Loss: Encourages the model to learn semantic hierarchies by modeling inclusion relationships between less certain (e.g., abstract) and more certain (e.g., specific) embeddings.
- Mask Repulsive Loss: Prevents the degeneration of representations by ensuring distinguishable embeddings for masked inputs, which is crucial for robust hierarchical learning.
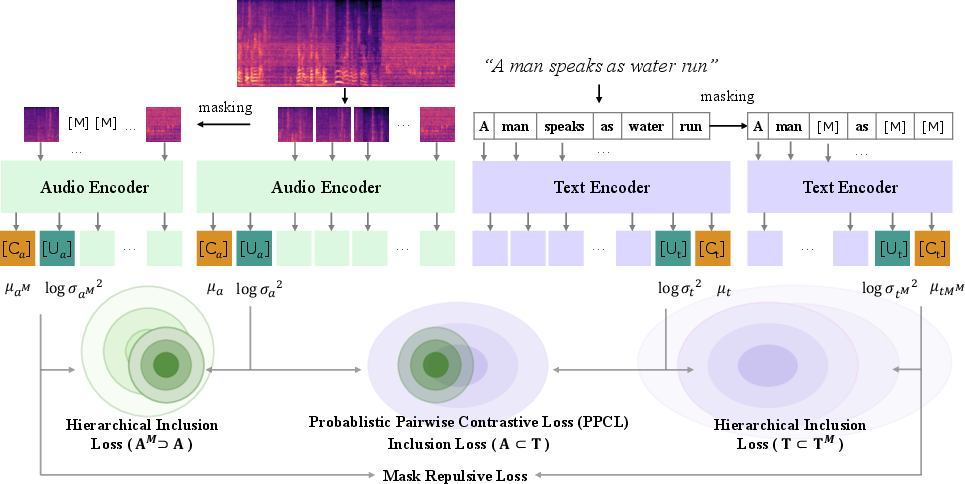
Figure 1: Overview of ProLAP. ProLAP models the representation as a Gaussian random variable following N(μ,σ2).
Experimental Results
The efficacy of ProLAP was validated through extensive experiments, comparing its performance against standard CLAP and its variations on tasks including audio-text retrieval and audio traversal.
Retrieval Tasks:
In audio-text retrieval evaluations using datasets such as AudioCaps and ClothoV2, ProLAP consistently outperformed existing models. It demonstrated superior recall rates across various settings, indicating its robustness and generalization capabilities even on out-of-domain data.
Semantic Understanding:
The audio traversal task introduced in this work further showcased ProLAP's competency in capturing semantic hierarchies. By tracing conceptual levels from abstract to concrete, ProLAP exhibited a nuanced understanding of the hierarchical nature of audio-text relationships, surpassing baseline models in precision and recall.
Uncertainty Analysis:
Visualizations of probabilistic embeddings illustrated ProLAP's ability to produce distinct and semantically coherent representations, effectively distinguishing between various levels of masked inputs.
Conclusion
ProLAP represents a significant advancement in language-audio joint representation learning by integrating probabilistic embeddings. Its novel approach addresses the deficiencies of deterministic mappings, providing a sophisticated tool for capturing the intricate many-to-many correspondences that characterize real-world audio-text tasks. The introduction of hierarchical and mask-related loss functions enhances ProLAP's ability to learn and utilize semantic hierarchies, making it a valuable contribution to the field of audio processing and multimodal learning. Future work could explore the broader applicability of probabilistic embeddings across different modalities and further refine the loss mechanisms for even greater performance improvements.