Spatial-CLAP: Learning Spatially-Aware audio--text Embeddings for Multi-Source Conditions
Abstract: Contrastive language--audio pretraining (CLAP) has achieved remarkable success as an audio--text embedding framework, but existing approaches are limited to monaural or single-source conditions and cannot fully capture spatial information. The central challenge in modeling spatial information lies in multi-source conditions, where the correct correspondence between each sound source and its location is required. To tackle this problem, we propose Spatial-CLAP, which introduces a content-aware spatial encoder that enables spatial representations coupled with audio content. We further propose spatial contrastive learning (SCL), a training strategy that explicitly enforces the learning of the correct correspondence and promotes more reliable embeddings under multi-source conditions. Experimental evaluations, including downstream tasks, demonstrate that Spatial-CLAP learns effective embeddings even under multi-source conditions, and confirm the effectiveness of SCL. Moreover, evaluation on unseen three-source mixtures highlights the fundamental distinction between conventional single-source training and our proposed multi-source training paradigm. These findings establish a new paradigm for spatially-aware audio--text embeddings.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in a nutshell)
Imagine you’re in a room with your eyes closed. You hear a dog barking on your left and a car honking on your right. You don’t just know what you heard (dog, car); you also know where each sound came from (left, right). Most computer models that connect sounds with text can tell “what” is sounding, but not “where” it is happening—especially when multiple sounds happen at once.
This paper introduces Spatial-CLAP, a new way to teach computers to understand both what a sound is and where it’s coming from at the same time, even when there are several sounds together.
What questions the paper tries to answer
- How can we make audio–text models understand spatial information (the “where”), not just content (the “what”)?
- How can a model keep track of which sound is at which location when multiple sounds happen together?
- Can such a model work well on real tasks like finding the right caption for a sound or writing a caption that mentions both the sound and its direction?
How the researchers approached it (with simple analogies)
To explain the approach, think of two parts:
- The “what” learner: This part recognizes what is making the sound (like “dog bark” or “car horn”). It’s based on a successful model called CLAP that already knows a lot about sound–text matching.
- The “where” learner: This part figures out the direction a sound comes from (left, right, front-left, etc.), like how our two ears help us locate sounds.
The paper’s key ideas:
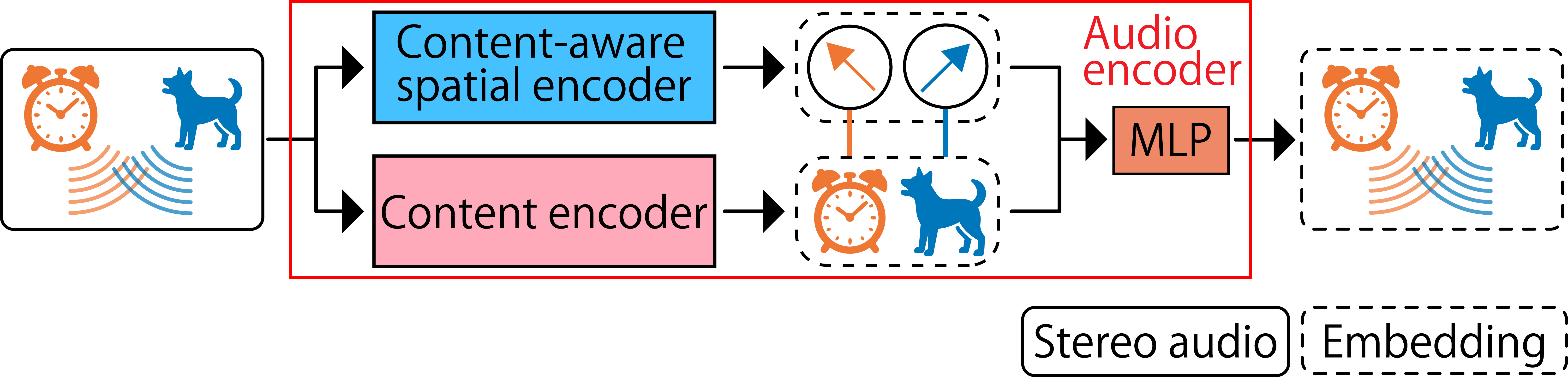
- Content-aware spatial encoder (CA-SE): Instead of learning “what” and “where” separately (which can get mixed up when multiple sounds happen), they make a “where” learner that is aware of “what.” This helps it bind the correct sound to the correct location.
- Stereo input: The model listens with two “ears” (stereo microphones), which is crucial for locating sounds in space.
- Contrastive learning: Think of teaching by example and counterexample. The model sees pairs that match (an audio clip and its correct caption) and tries to pull them together in its memory. It also sees mismatched pairs and learns to push them apart.
- Spatial contrastive learning (SCL): A clever training trick. They create “hard negatives” by swapping the locations of sounds. For example:
- Correct: “dog on the left, car on the right”
- Swapped (wrong): “dog on the right, car on the left”
- By telling the model the swapped one is wrong, it learns to care about which sound is at which place—not just the list of sounds or the list of directions separately.
How they built the data:
- They started with normal, single-channel audio clips paired with captions (from AudioCaps).
- They turned those into stereo “room” recordings using simulated room echoes (like placing sounds in a virtual room).
- For scenes with multiple sounds, they mixed two or more sounds together and wrote captions that included both content and direction (e.g., “a dog barks on the left and a car honks on the right”).
What they found and why it matters
Main results:
- Better at multi-sound scenes: Spatial-CLAP was much better than previous methods at handling mixtures (like two different sounds at different directions).
- Strong “what–where” binding: It was best at telling which sound happened where, not just what happened or where something happened in general.
- The SCL trick helps: Adding the “swapped positions” negatives made the model even more reliable in multi-sound situations.
- Still good at single-sound tasks: It didn’t lose its ability to understand content when there was only one sound.
- Works for captioning: When used to help a text generator write descriptions, the model produced better captions that included correct spatial phrases (like “on the left”).
Why this matters:
- Real life is full of overlapping sounds. Knowing both “what” and “where” is essential for devices like home assistants, robots, AR/VR headsets, hearing aids, and safety systems.
- This work shows how to train models that understand complex audio scenes more like humans do.
What this could lead to
- Smarter sound search: You could search for “a baby crying behind me” and find the exact clip, not just any baby cry.
- Better assistive tech and robots: Devices could focus on the right sound in the right direction (e.g., hear your voice on the left in a noisy room).
- More immersive AR/VR: Systems could place and describe virtual sounds accurately in space.
- Stronger foundations for future research: The authors released code and models, making it easier for others to build and improve spatial audio–text systems.
In short, the paper takes a big step toward teaching machines to understand sound scenes the way we do: knowing both what is happening and where it’s happening, even when many things happen at once.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of unresolved issues that the paper leaves open. Each point highlights a concrete gap or limitation that future work can address:
- Real-world generalization: No evaluation on recorded spatial audio (e.g., binaural HRIRs, Ambisonics/FOA, microphone arrays, mobile devices); results are limited to simulated RIRs with clean monaural sources.
- Limited microphone geometry: Only a fixed two-microphone stereo setup is used; generalization to different array topologies, spacings, and device-dependent transfer functions is untested.
- Front–back ambiguity and coarse spatial resolution: DoA is folded into five azimuthal classes (“front-left,” “front,” “front-right,” “left,” “right”), leaving out back, elevation, distance, and continuous angle estimation; how to extend to full 3D localization is unanswered.
- Synthetic data bias: RIRs cover a narrow T60 range (130–260 ms) and simulated rooms; robustness to real reverberation extremes, outdoor scenes, occlusions, and non-shoebox acoustics is unknown.
- Noise and interference robustness: No experiments with diffuse background noise, non-point sources, device noise, or low SNR; resilience to realistic acoustic clutter remains unassessed.
- Source polyphony and scalability: Training batches only include one- and two-source samples; performance for higher polyphony (≥3–4 sources) and mixtures with many concurrent events is largely unexplored beyond a small “unseen three-source” evaluation.
- SCL scalability: Spatial contrastive learning requires n!-1 negatives for n sources; the paper uses two-source swaps only and does not propose a tractable strategy for higher n (e.g., partial swaps, subset pairing, curriculum, stochastic pairing).
- Embedding capacity limits: A single fixed-dimensional embedding must encode multiple source–location bindings; how capacity scales with source count and scene complexity is not characterized (e.g., saturation, interference between bindings).
- Temporal dynamics and motion: The model aggregates over time and is not explicitly evaluated on moving sources or time-varying correspondences; handling of dynamic scenes is an open question.
- Per-source disentanglement: The representation is global and does not yield per-source embeddings or a set-structured output; methods to recover source-wise attributes (content, DoA) from the joint embedding are missing.
- Caption order sensitivity: Multi-source captions are concatenations; whether retrieval and captioning are sensitive to the order of per-source phrases (and how to enforce order-invariance or canonicalization) is not analyzed.
- Open-vocabulary spatial language: Spatial phrases are restricted to five tokens; robustness to diverse natural-language spatial descriptions (synonyms, relative directions, distances, comparative relations) is untested.
- Cross-lingual generalization: Only English captions are used; performance for other languages and multilingual spatial expressions remains unknown.
- Downstream breadth: Beyond retrieval, spatial classification, and captioning, transfer to other spatial downstream tasks (e.g., open-vocabulary SELD metrics, multi-object tracking, separation/diarization, AR/VR interaction) is not evaluated.
- Metric validation: New spatial metrics (DW-SBERT, “Spatial description” rate) are not validated against human judgments; sensitivity, reliability, and failure modes of these metrics need assessment.
- Zero-shot spatial generalization: While content is open-vocabulary via CLAP, zero-shot handling of novel spatial concepts (e.g., “behind,” elevation terms, relative positioning) is not measured.
- Robustness to label noise: Each monaural AudioCaps clip is treated as a single spatial source even if it contains mixtures; the impact of this label noise on learned content–space bindings is not quantified.
- SCL applicability to real data: SCL relies on access to separated sources and controllable RIR permutations; how to implement analogous hard negatives with real recordings (weak labels, pseudo-labels, or self-supervised augmentations) is not discussed.
- Trade-off control (content vs. spatial): The unified embedding mixes content and spatial cues; mechanisms to tune sensitivity (e.g., disentangled heads, task-conditioned pooling) and analyze trade-offs are not explored.
- Elevation and distance cues: No modeling or evaluation of elevation or source distance; how to incorporate ITD/ILD–based elevation cues, spectral notches, or distance attenuation into CA-SE is open.
- Hyperparameter/systematic ablations: No study of batch composition (ratio of single/multi-source), number/type of negatives, embedding dimensionality, or MLP bottleneck size on performance and stability.
- Generalization across domains: No cross-corpus testing (e.g., DCASE SELD datasets, TAU-NIGENS, LOCATA) to assess out-of-distribution robustness in content and acoustics.
- End-to-end captioning fine-tuning: Captioning freezes the audio encoder; whether joint fine-tuning improves spatial language grounding without degrading generalization remains untested.
- Interpretability and calibration: No analysis of how embedding similarity varies with controlled spatial changes (e.g., monotonicity with azimuth offset, sensitivity to small DoA shifts); interpretability tools for content–space binding are absent.
Glossary
- A2T (audio-to-text): Retrieval setup where an audio query is used to find its matching text. Example: "audio-to-text (A2T)"
- ACCDOA: A unified vector representation coupling event activity with direction of arrival for SELD. Example: "unified vector representations named ACCDOA"
- Adam: An adaptive gradient-based optimizer commonly used to train deep networks. Example: "using Adam"
- AdamW: Adam variant with decoupled weight decay for better generalization. Example: "using AdamW"
- AudioCaps 2.0: A dataset of audio clips paired with human-written captions. Example: "AudioCaps 2.0"
- AudioCLIP: An audio–text model extending CLIP-like training to audio. Example: "AudioCLIP"
- automated audio captioning: Task of generating natural-language descriptions from audio. Example: "automated audio captioning"
- BERTScore: A captioning metric that measures semantic similarity using contextual embeddings. Example: "BERTScore"
- BLEU: A precision-based n-gram overlap metric for evaluating generated text. Example: "BLEU"
- CA-SE (content-aware spatial encoder): A spatial encoder designed to produce spatial embeddings bound to content. Example: "content-aware spatial encoder (CA-SE)"
- CE (content encoder): The module that extracts content-focused embeddings from audio. Example: "content encoder (CE)"
- CIDEr: A consensus-based metric for caption evaluation emphasizing term frequency–inverse document frequency. Example: "CIDEr"
- CLAP (Contrastive language--audio pretraining): Framework that aligns audio and text embeddings via contrastive learning. Example: "Contrastive language--audio pretraining (CLAP)"
- contrastive learning: Learning paradigm that pulls matched pairs together and pushes mismatched pairs apart in embedding space. Example: "contrastive learning framework"
- content--space correspondence: The binding between each sound source’s content and its spatial location. Example: "content--space correspondence"
- Direction-wise SBERT (DW-SBERT): A spatially oriented metric that compares caption segments per direction using SBERT. Example: "Direction-wise SBERT (DW-SBERT)"
- direction of arrival (DoA): The angle from which a sound reaches the microphones. Example: "direction of arrival (DoA)"
- embed-ACCDOA: A SELD approach that uses CLAP-based embeddings within the ACCDOA framework for open-vocabulary settings. Example: "embed-ACCDOA"
- fixed-RIR: Evaluation setting where a single, pre-selected room impulse response is used to isolate content effects. Example: "fixed-RIR"
- GPT-2: A transformer-based LLM used here as a caption decoder. Example: "GPT-2"
- HTS-AT: A transformer-based audio tagging backbone used as the content encoder. Example: "HTS-AT"
- InfoNCE loss: A contrastive loss that maximizes similarity of true pairs over in-batch negatives. Example: "InfoNCE loss"
- METEOR: A captioning metric emphasizing recall, stemming, and synonymy. Example: "METEOR"
- MLP (multilayer perceptron): A feed-forward neural network used to map concatenated features to embeddings. Example: "multilayer perceptron (MLP)"
- Pengi: An audio–LLM connecting audio encoders with LLMs. Example: "Pengi"
- permutation problem: Ambiguity in assigning multiple sources to multiple locations when content and space are unaligned. Example: "permutation problem under multi-source conditions."
- permutation-invariant training: Training strategy that handles label ambiguity by optimizing over all output-target permutations. Example: "permutation-invariant training"
- Polyphonic SELD: SELD setting with multiple overlapping sound events active simultaneously. Example: "Polyphonic SELD"
- pyroomacoustics: A library for simulating acoustic rooms and RIRs. Example: "pyroomacoustics"
- R@1 (recall@1): Retrieval metric measuring the fraction of queries whose correct match is ranked first. Example: "recall@1 (R@1) score"
- ReLU: A nonlinear activation function used in MLP layers. Example: "ReLU activations"
- RIRs (room impulse responses): Filters characterizing how sound propagates from a source to microphones in a room. Example: "room impulse responses (RIRs)"
- RoBERTa-base: A pretrained transformer text encoder used for text embeddings. Example: "RoBERTa-base"
- ROUGE-L: A recall-oriented metric based on longest common subsequence for text evaluation. Example: "ROUGE-L"
- SALMON: An audio–LLM for multimodal understanding. Example: "SALMON"
- SBERT (SentenceBERT): A sentence embedding model used for semantic similarity scoring. Example: "SentenceBERT (SBERT)"
- SELD (sound event localization and detection): Task of jointly detecting sound events and estimating their directions. Example: "sound event localization and detection (SELD)"
- SELDNet: A neural architecture for SELD using convolutional and recurrent layers. Example: "SELDNet"
- short-time Fourier transform (STFT): Time–frequency representation of audio used as neural network input. Example: "short-time Fourier transforms"
- SCL (spatial contrastive learning): Training strategy that uses swapped spatial assignments as hard negatives to enforce binding. Example: "spatial contrastive learning (SCL)"
- SPICE: A semantic scene graph-based captioning metric. Example: "SPICE"
- SPIDEr: A captioning metric combining SPICE and CIDEr. Example: "SPIDEr"
- spatial audio captioning: Generating captions that describe both content and spatial attributes of sounds. Example: "spatial audio captioning"
- T2A (text-to-audio): Retrieval setup where a text query is used to find its matching audio. Example: "text-to-audio (T2A)"
- track-wise formulations: SELD outputs assigned to a fixed number of tracks to handle multiple sources. Example: "track-wise formulations"
Collections
Sign up for free to add this paper to one or more collections.