FineVision: Open Data Is All You Need
Abstract: The advancement of vision-LLMs (VLMs) is hampered by a fragmented landscape of inconsistent and contaminated public datasets. We introduce FineVision, a meticulously collected, curated, and unified corpus of 24 million samples - the largest open resource of its kind. We unify more than 200 sources into 185 subsets via a semi-automated, human-in-the-loop pipeline: automation performs bulk ingestion and schema mapping, while reviewers audit mappings and spot-check outputs to verify faithful consumption of annotations, appropriate formatting and diversity, and safety; issues trigger targeted fixes and re-runs. The workflow further applies rigorous de-duplication within and across sources and decontamination against 66 public benchmarks. FineVision also encompasses agentic/GUI tasks with a unified action space; reviewers validate schemas and inspect a sample of trajectories to confirm executable fidelity. Models trained on FineVision consistently outperform those trained on existing open mixtures across a broad evaluation suite, underscoring the benefits of scale, data hygiene, and balanced automation with human oversight. We release the corpus and curation tools to accelerate data-centric VLM research.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces FineVision, a huge, carefully cleaned, and open dataset designed to help train and test vision-LLMs (VLMs). VLMs are computer programs that can look at images and read text, then answer questions or have a conversation about what they see. The goal of FineVision is to give the open research community a high-quality “study pack” so models trained on public data can better compete with models trained on secret, private data.
Objectives and Questions
The paper asks simple but important questions:
- Can we build a large, clean, and diverse visual dataset from public sources that’s good enough to train top-performing open VLMs?
- How do we make sure the data is consistent, safe, and not accidentally leaking test answers (like having the test questions inside the study material)?
- Does better data (not just more data) actually improve model performance in real tests?
- Can we include new kinds of tasks—like controlling computer apps (GUIs)—by standardizing how actions are represented?
Methods and Approach
Think of FineVision as turning a messy, mixed-up library of pictures and text into a well-organized set of lessons.
Here’s how they built it:
- They collected over 200 public datasets (from places like GitHub, cloud folders, and research hubs) and unified them into 185 final subsets.
- They converted everything into a single “chat” format, where each sample looks like a conversation: the user asks something about an image, and the assistant answers. This makes the data perfect for training models that respond in a chat-like way.
To keep things clean and fair, they used a semi-automated pipeline with human checks:
- Data cleaning: They fixed or removed broken images, standardized text (removing weird symbols or empty answers), and made sure questions matched the images.
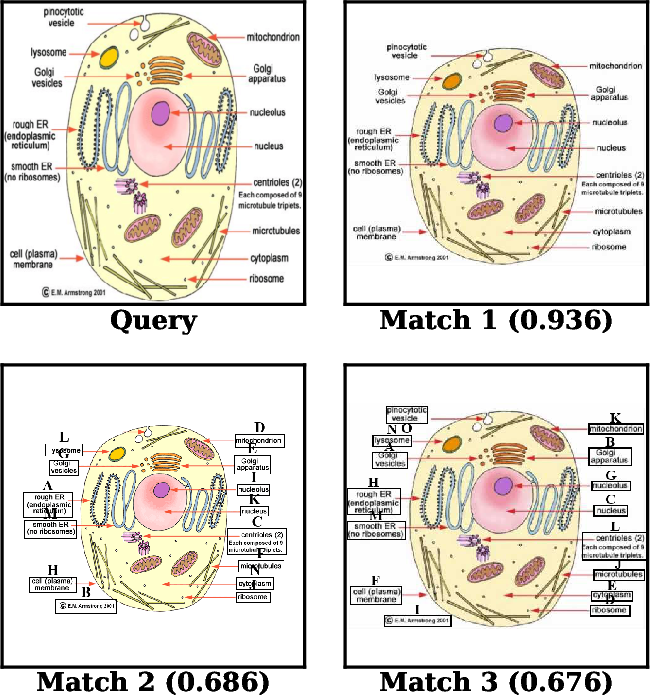
- Duplicate control: They used SSCD embeddings (a kind of smart fingerprint for images) and cosine similarity (a way to measure how similar two fingerprints are) to find near-duplicate images and to reduce overlap between training and testing. Think of this like removing copies of the same photo and making sure your study notes don’t include the exact test pictures.
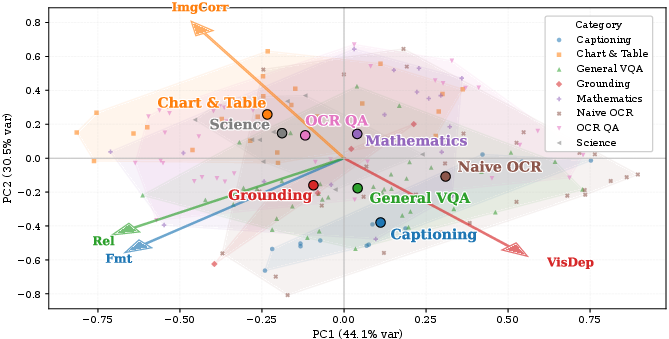
- Quality checks: Large language/vision models acted like “judges” to score turns on four axes:
- Formatting (is the text clean and well-structured?),
- Relevance (does the answer fit the question?),
- Visual Dependency (do you really need the image to answer?),
- Image–Question Correspondence (does the question clearly match what’s in the image?).
- Human reviewers audited samples and approved scripts, ensuring conversions were faithful to the original data.
- Unified action space for GUI tasks: Different datasets describe actions (like clicking or typing) in different ways. The team standardized these into a single format, using normalized screen coordinates, so models can learn consistent, reliable behaviors across apps and devices.
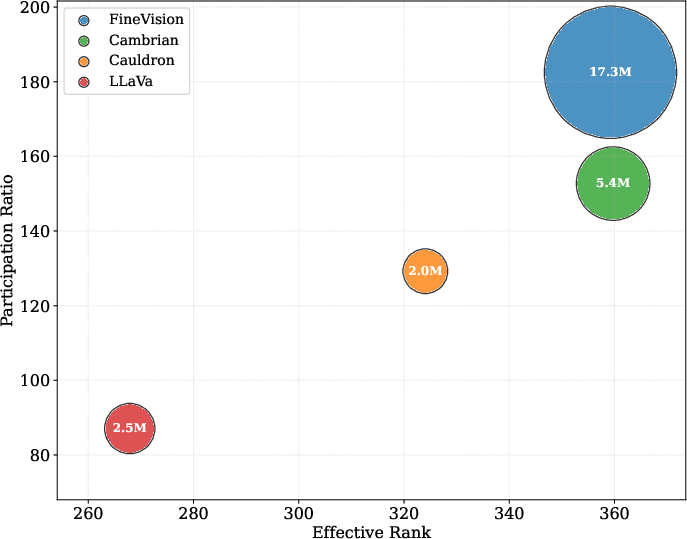
They also studied diversity using statistics from the image “fingerprints.” Two measures matter:
- Effective Rank: How many different visual concepts are covered (breadth).
- Participation Ratio: How evenly those concepts are represented (balance). This is like checking not only how many topics your textbook covers, but also whether it spreads them evenly rather than focusing on only a few.
Main Findings and Why They Matter
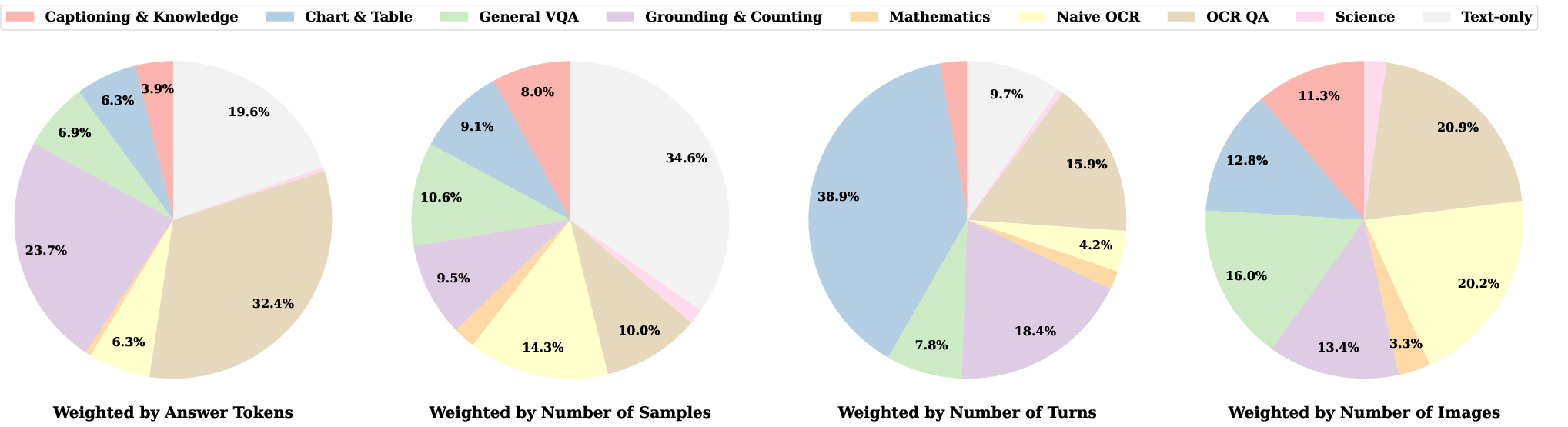
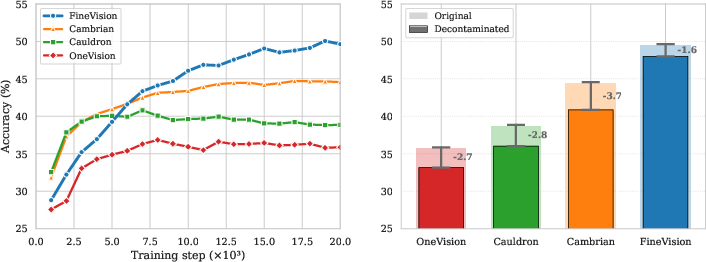
- Scale and quality: FineVision contains over 24 million samples, 17 million images, and 89 million conversation turns—much larger and more diverse than popular open datasets like The Cauldron, LLaVA-OneVision, and Cambrian.
- Better performance: Training the same small VLM (about 460 million parameters) on FineVision led to the best average scores across 11 standard benchmarks (like chart reading, document questions, math, and OCR). Compared to the baselines, FineVision gave big gains—up to double-digit percentage point improvements.
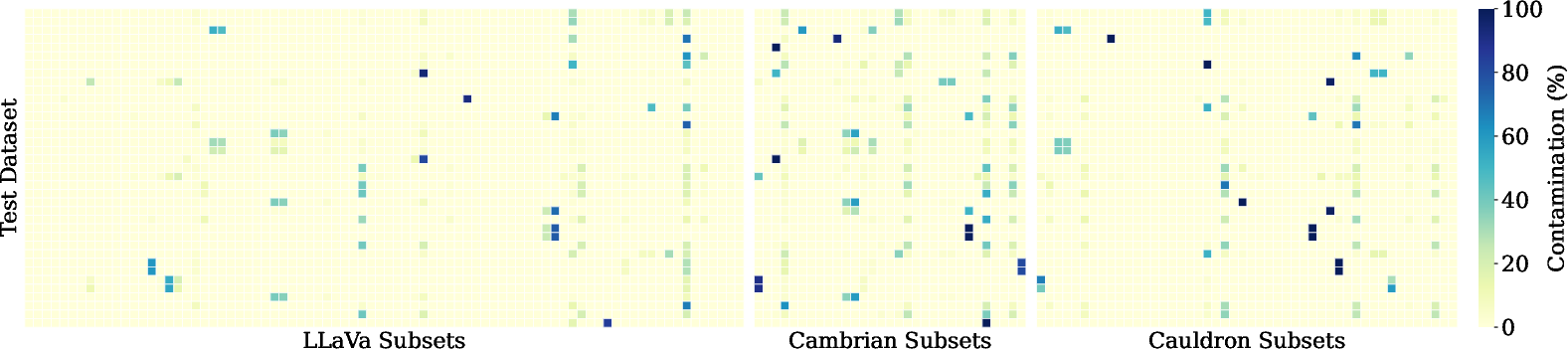
- Lower contamination: FineVision had a lower rate of “training data containing test images” than competitors. Even after removing suspected contaminations, models trained on FineVision still performed best and dropped the least in score. This shows the advantage isn’t just because of overlap between training and tests.
- New capabilities (GUI): Because the dataset includes standardized GUI action data, models trained on FineVision can handle tasks like finding buttons or acting in apps better than similar models trained elsewhere. In tough benchmarks like ScreenSpot, a small model trained on FineVision reached performance similar to another model four times its size after fine-tuning on related data.
Implications and Impact
FineVision shows that open data, when collected and cleaned well, can power high-performing models without relying on private, hidden datasets. This matters because:
- It makes AI research more fair and accessible: anyone can use the same high-quality data to reproduce results.
- It pushes the field forward: better data leads to stronger models, especially for tasks that need careful reading, reasoning, and even interacting with computer interfaces.
- It provides tools and recipes: the authors released their curation pipeline, deduplication tools, and precomputed embeddings, so other researchers can build on this work and improve it.
In short, FineVision is like giving the community a giant, well-organized toolbox—filled with clean images, clear conversations, and standardized actions—so open vision-LLMs can learn more, generalize better, and start doing new things across many kinds of tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research and dataset development.
- Attribution of gains: disentangle the effect of scale versus curation by running token-matched comparisons (downsample FineVision to match baselines and/or upsample baselines) and mixture-matched comparisons (same categories/ratios across datasets).
- Robustness across model scales and architectures: replicate results on larger/smaller backbones, multi-encoder designs, and different pretrain/SFT schedules to test whether FineVision’s benefits persist under common VLM recipes.
- Training budget parity: control for total tokens/updates and report confidence intervals over multiple seeds to assess statistical significance and training stability across datasets.
- Long-context limitations: quantify truncation rates under the 8,192-token cap, measure performance on long-document/multi-document reasoning tasks, and explore high-resolution tiling or sparse-attention strategies for document-intensive benchmarks.
- Multi-image and video coverage: evaluate multi-image reasoning explicitly and extend the corpus, schema, and evaluation to video (temporal grounding, step-by-step reasoning, and action understanding).
- GUI/agentic evaluation gaps: go beyond ScreenSpot by releasing standardized, executable, cross-platform GUI benchmarks; report action execution accuracy, trajectory fidelity, and generalization to unseen apps/platforms.
- Action-space unification validation: quantify mapping accuracy from source action schemas to the unified API (precision/recall on parameter reconstruction, function aliasing errors) and measure the impact on downstream agent performance.
- Decontamination scope: add text-level near-duplicate/semantic matching (e.g., for OCR/doc QA) and multi-modal (image+text) contamination checks; validate across more than 66 benchmarks and newly released test sets.
- Threshold sensitivity for SSCD: provide precision–recall calibration and human-validated audits for the cosine similarity threshold τ=0.95; report false positive/negative rates and sensitivity analyses across tasks and image domains.
- Release variants: ship a fully decontaminated FineVision variant (and per-benchmark filtered shards) alongside the original, with indices of flagged items for transparent downstream use.
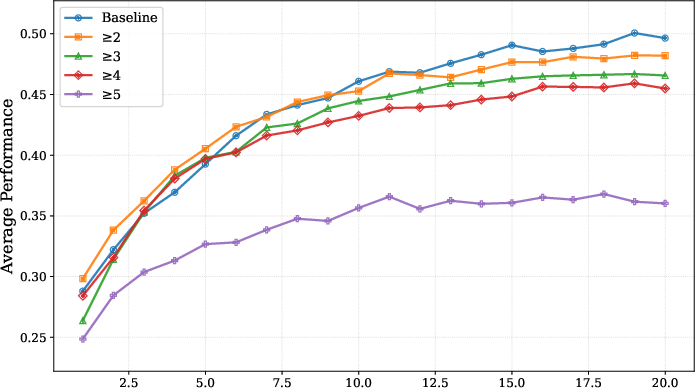
- Intra-/cross-source duplicate handling: report per-source duplicate rates, merging decisions, and the impact of duplicate collapsing on downstream performance and category balance.
- Quality ratings validity: validate VLM-as-judge scores against human annotations (inter-annotator agreement, calibration plots), test robustness across judges (e.g., Qwen vs. GPT-4V vs. LLaVA), and quantify how ratings predict training gains.
- Data selection strategies: systematically compare quality-based reweighting, difficulty-based filtering, and curriculum methods (e.g., Self-Filter, cross-modal agreement, self-play) versus breadth preservation, across model scales.
- Conversion fidelity: quantify LLM-assisted conversion errors (missed fields, instruction drift, hallucinated rationales), report audit sample sizes/coverage, inter-reviewer agreement, and residual error rates by task type.
- Conversational templating effects: measure how template variability and multi-turn grouping affect learning (e.g., ablate across template pools, grouping strategies, and rationale inclusion).
- Visual diversity metrics: corroborate SSCD-based diversity with alternative embeddings (e.g., CLIP, DINOv2, VLM2Vec), control for dataset size via stratified bootstrapping, and report uncertainty intervals for effective rank and participation ratio.
- Category mixture optimization: provide principled recipes or automated tools to reweight categories/qualities for target tasks, including small-compute “starter” mixtures and curricula for labs with limited resources.
- Resolution policy: evaluate the impact of the 2048px cap on chart/doc/OCR tasks; explore adaptive cropping, multi-scale inputs, or tiling; report resolution–accuracy trade-offs and truncation statistics.
- Packing and masking details: document and validate attention masking under sequence packing to prevent cross-sample leakage; quantify any measurable effects on training dynamics.
- Language coverage and multilingual evaluation: measure language distribution, add non-English sources where licenses permit, and evaluate on multilingual OCR/QA benchmarks.
- Bias, fairness, and representativeness: audit demographic/geographic/domain balance; measure subgroup performance gaps and harmful stereotype propagation; release bias audit reports and mitigation baselines.
- Safety and PII handling: define safety filters formally, report false positive/negative rates, and add PII detection/removal metrics (e.g., faces, IDs, signatures), including per-category safety risk profiles.
- Licensing and provenance: publish per-sample license metadata, compatibility analyses, and provenance audit trails; clarify redistribution rights for each subset and provide robust takedown/update mechanisms.
- Update cadence and versioning: establish procedures for periodic refreshes (new sources, re-licenses, benchmark expansions), semantic versioning, and changelogs to manage dataset drift.
- Reproducibility of conversion randomness: release seeds, template distributions, and deterministic conversion options; provide per-dataset conversion logs and validation reports to facilitate exact regeneration.
- Benchmark breadth: extend evaluation beyond the current 11 tasks to include recently proposed and harder OOD benchmarks (e.g., chart reasoning with long context, real-world GUI suites, adversarial OCR), and assess generalization to novel domains.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the released dataset, pipelines, and metrics.
- Open VLM training with state-of-the-art open data
- Sectors: software, AI labs, academia
- What: Train small-to-mid VLMs that outperform prior open-data baselines across 11 benchmarks using the FineVision corpus.
- Tools/Workflows: HuggingFaceM4/FineVision dataset; nanoVLM/SmolVLM training recipes; lmms-eval for evaluation; vLLM for serving.
- Assumptions/Dependencies: Sufficient GPU budget; adherence to original dataset licenses; model safety filters and red-teaming remain the deployer’s responsibility.
- Domain-adapted document AI (OCR + DocVQA)
- Sectors: finance (invoices, KYC), legal (contracts), public sector (e-forms), enterprise back-office
- What: Fine-tune compact VLMs for document transcription, layout-aware Q&A, and chart/table lookup on top of FineVision’s OCR/DocVQA/Chart subsets.
- Tools/Workflows: Per-turn quality ratings for filtering; instruction-format conversion templates; high-resolution image preprocessing.
- Assumptions/Dependencies: Domain-specific adaptation data; PHI/PII handling and privacy compliance; guardrails against hallucinations.
- GUI automation and test agents (vision-to-action)
- Sectors: RPA, QA engineering, customer support tooling, accessibility
- What: Build screen-aware assistants that localize UI elements and issue structured actions (click/type/scroll) using the unified, typed action schema and normalized coordinates.
- Tools/Workflows: FineVision GUI/agentic subsets; ScreenSpot benchmarks for validation; integration with OS/browser automation frameworks.
- Assumptions/Dependencies: OS/app variability; latency and accuracy constraints; safety interventions to prevent destructive actions.
- Training-data deduplication and benchmark decontamination
- Sectors: MLOps/dataops, dataset marketplaces, model evaluation
- What: Deploy hygiene pipelines that remove near-duplicates and flag potential test leakage using SSCD embeddings and cosine similarity.
- Tools/Workflows: Open-source large-scale image deduplication pipeline; precomputed embeddings for 66 benchmarks; τ=0.95 similarity threshold as a starting point.
- Assumptions/Dependencies: Threshold tuning for niche domains; image-only matching (text-only leakage needs separate handling); compute for embedding/indexing at scale.
- Dataset health dashboards and data governance
- Sectors: AI governance, compliance, platform trust & safety
- What: Monitor curation quality with four per-turn axes (Formatting, Relevance, Visual Dependency, Image–Question Correspondence) and diversity metrics (effective rank, participation ratio).
- Tools/Workflows: LLM/VLM-as-judge prompts; PCA-based summaries; per-turn scores released for filtering/reweighting.
- Assumptions/Dependencies: Judge-model bias and drift; periodic recalibration; policy thresholds for accept/reject decisions.
- Unified multimodal chat schema for data consolidation
- Sectors: data engineering, dataset curation, research
- What: Convert heterogeneous multimodal corpora into a consistent instruction-tuning chat format to streamline training mixtures and ablations.
- Tools/Workflows: Semi-automated converters with human-in-the-loop audits; templated Q/A generation; metadata preservation for downstream filtering.
- Assumptions/Dependencies: Human reviewer bandwidth; faithfulness checks for templated conversions; source license compatibility.
- Reproducible benchmarking and ablation studies
- Sectors: academia, applied research
- What: Run controlled comparisons of data mixtures, filtering policies, and contamination-removal effects with shared evaluation harnesses.
- Tools/Workflows: lmms-eval suite; released decontamination reports; training curves and normalized score tracking.
- Assumptions/Dependencies: Consistent seeds/hyperparameters; access to the same model backbones and tokenization.
- Assistive screen-reading and action hints
- Sectors: accessibility, consumer productivity
- What: On-screen OCR + “what to click next” hints for users with motor or visual impairments, powered by GUI-action understanding.
- Tools/Workflows: Screen capture; real-time model inference; action ranking and confirmation UI.
- Assumptions/Dependencies: Strict safety/consent flows; user customization; on-device or private-edge inference to protect sensitive content.
- Data-centric curriculum and sampling strategies
- Sectors: research, MLOps
- What: Use per-turn quality scores and category labels to craft curricula (e.g., warm-up on high-formatting/high-relevance data, then mix in visually demanding tasks).
- Tools/Workflows: Score-aware data loaders; dynamic reweighting; mixture design experiments.
- Assumptions/Dependencies: Score stability across domains; avoiding over-filtering that can reduce generalization.
Long-Term Applications
These applications require further research, scaling, ecosystem integration, or standardization before broad deployment.
- General-purpose desktop/mobile multimodal copilots
- Sectors: productivity software, enterprise IT
- What: Reliable agents that perceive screens, reason over multi-step workflows, and execute robust action sequences across heterogeneous apps.
- Tools/Workflows: Expanded GUI interaction datasets; richer unified action taxonomies; feedback-driven correction loops; safety sandboxes.
- Assumptions/Dependencies: Larger/safer models; robust OS/app generalization; user permissioning, audit trails, and rollback.
- Regulatory standards for dataset hygiene and test integrity
- Sectors: public sector procurement, regulated industries
- What: Policies that mandate deduplication/decontamination audits, per-turn quality reporting, and provenance tracking for training datasets.
- Tools/Workflows: Third-party “data audit certificates”; standardized contamination reports; reproducible SSCD-based checks.
- Assumptions/Dependencies: Cross-agency agreement on thresholds; handling false positives/negatives; legal frameworks for redress.
- Multimodal compliance and IP risk scanning
- Sectors: legal/IP, compliance, data marketplaces
- What: Routine scanning of training corpora against copyrighted benchmarks or held-out evaluation suites to mitigate leakage and IP exposure.
- Tools/Workflows: Continually updated embedding registries of “do-not-train” sets; similarity watchlists; automated reporting.
- Assumptions/Dependencies: Coverage of relevant protected corpora; cooperative disclosure by benchmark owners; defense against adversarial copies.
- On-device multimodal assistants
- Sectors: mobile, edge/IoT, automotive
- What: Privacy-preserving OCR, chart reading, and screen guidance running on-device using compact VLMs trained on high-quality open data.
- Tools/Workflows: Quantization/distillation; memory-efficient vision encoders; offline inference stacks.
- Assumptions/Dependencies: Hardware acceleration; energy constraints; robust performance in low-resource settings.
- Cross-application RPA marketplaces and action-sharing
- Sectors: enterprise software, ISVs
- What: Shareable, auditable “action recipes” for common workflows (onboarding, reporting) encoded in a standardized action schema.
- Tools/Workflows: Action trajectory repositories; validation harnesses; parameterized templates with environment normalization.
- Assumptions/Dependencies: Vendor participation; privacy-safe sharing; versioning across app updates and UI shifts.
- Advanced data selection and curriculum learning research
- Sectors: academia, frontier labs
- What: Systematic exploration of score-aware sampling, self-play, and difficulty-driven selection using FineVision’s released per-turn metrics at scale.
- Tools/Workflows: Score-conditioned schedulers; multi-objective mixture optimization; closed-loop “judge-in-the-training” pipelines.
- Assumptions/Dependencies: Avoiding selection bias; maintaining diversity/coverage to preserve generalization.
- Multilingual, video, and long-context extensions
- Sectors: education, media, operations
- What: Extend the pipeline and corpus to videos, interleaved long documents, and multilingual tasks for richer perception–reasoning capabilities.
- Tools/Workflows: Video-text alignment and safety filters; long-context packing; multilingual judge models.
- Assumptions/Dependencies: Additional curated data sources; cost of high-res/long-context training; evaluation benchmarks beyond images.
- Safety, bias, and fairness auditing at dataset scale
- Sectors: AI ethics, policy, platform integrity
- What: Use per-category/per-turn diagnostics to identify skew, harmful content, or under-represented visual concepts; drive corrective rebalancing.
- Tools/Workflows: Bias dashboards; targeted data enrichment; structured human audits in the loop.
- Assumptions/Dependencies: Ground-truth labels for sensitive attributes; community norms on acceptable trade-offs; continuous monitoring.
- High-stakes domain agents (healthcare/finance) with privacy-preserving data
- Sectors: healthcare, finance, insurance
- What: Specialized agents for forms parsing, chart interpretation, and workflow assistance under strict privacy and reliability constraints.
- Tools/Workflows: Synthetic/weakly-supervised domain data generation; HIPAA/GDPR-aligned pipelines; human verification gates.
- Assumptions/Dependencies: Access to compliant domain data; rigorous uncertainty estimation; certification and post-deployment monitoring.
- “Data firewall” products for model development lifecycles
- Sectors: MLOps, enterprise IT
- What: Gateways that enforce hygiene checks (duplication, contamination, safety) before data enters training or evaluation pipelines.
- Tools/Workflows: API-based pre-ingest scanning; audit logs; policy-as-code for data acceptance.
- Assumptions/Dependencies: Standardized interfaces across teams/vendors; continuous updates to detection models and blocklists.
Glossary
- Action space: The set of permissible, structured actions (with parameters) an agent can execute in an environment such as a GUI. "By unifying the action space, we enable cross-domain training and allow models to learn coherent action patterns across heterogeneous GUI environments (desktop, mobile, or browser)."
- Agentic: Pertaining to models or systems that can take actions autonomously within an environment (e.g., GUIs). "As the field expands into agentic and GUI-grounded tasks, the need has moved from aggregation to principled, scalable curation."
- Canonicalization: The process of transforming data into a standard, canonical form to ensure consistency across sources. "canonicalization and image {paper_content} text cleaning"
- Cosine similarity: A vector similarity measure equal to the cosine of the angle between two embedding vectors, commonly used for near-duplicate detection. "We perform hygiene in two stages using self-supervised copy-detection descriptors (SSCD) \citep{sscd2023} and cosine similarity:"
- Covariance-spectrum statistics: Metrics derived from the eigenvalue spectrum of an embedding covariance matrix to characterize diversity and balance. "We analyze visual diversity using covariance-spectrum statistics of self-supervised copy-detection (SSCD) embeddings~\citep{sscd2023} (same pipeline as for deduplication), computed per dataset without subsampling."
- Decontamination: The removal or flagging of training samples that overlap with evaluation sets to prevent test leakage. "de-duplication and test-set decontamination using SSCD embeddings \citep{sscd2023};"
- De-duplication: The identification and removal or consolidation of duplicate or near-duplicate data points. "alongside rigorous de-duplication within and across sources and decontamination against 66 evaluation benchmarks to protect test integrity."
- Embeddings: Dense vector representations of data (e.g., images, text) used for similarity, retrieval, and analysis. "SSCD embeddings \citep{sscd2023}"
- Entropy regularization: A technique that encourages a more uniform distribution (higher entropy), often used to spread variance across embedding dimensions. "SSCD descriptors are optimized to distinguish near-duplicates and, via entropy regularization, promote uniform occupancy of the embedding space, making distances more comparable across regions and suitable for diversity measurement."
- EXIF metadata: A standard for storing image metadata (e.g., orientation, camera info) used to correctly interpret and process images. "We also orient images via EXIF metadata and convert all formats to RGB."
- Effective rank: An entropy-based measure of the number of significant dimensions in a covariance spectrum, indicating conceptual breadth. "Effective Rank $r_{\text{eff} = \exp(H(p))$ with and (equivalent to the Vendi Score~\citep{friedman2023vendi})."
- Function signature: The formal specification of a function’s name and its typed parameters and their order. "a parser that extracts and normalizes arbitrary function signatures, ensuring consistent parameter ordering and reconstruction"
- Human-in-the-loop: A workflow where human reviewers oversee, audit, and correct automated processes to ensure quality. "semi-automated, human-in-the-loop curation workflow that unifies over 200 sources and enforces a consistent chat schema."
- Instruction tuning: Fine-tuning models on instruction–response pairs to improve instruction following and conversational abilities. "a standardized chat format suitable for instruction tuning"
- LLM/VLM-as-a-judge: Using large language or vision–LLMs to evaluate and score data quality or model outputs. "per-turn quality assessment with LLM/VLM-as-a-judge \citep{zheng2023mtbench,wang2023judge}"
- lmms-eval: A framework for evaluating multimodal LLMs across standardized benchmarks. "We use the lmms-eval framework \citep{zhang2024lmms} to evaluate models on a diverse suite of 11 benchmarks"
- Normalized coordinates: Coordinates scaled to a standard range (e.g., [0,1]) to be resolution-independent. "Screen coordinates are expressed in normalized form [0,1] to ensure resolution-agnostic training."
- Participation ratio: A measure of how uniformly variance is distributed across dimensions in the covariance spectrum, indicating conceptual balance. "Participation Ratio ."
- PCA (Principal Component Analysis): A dimensionality reduction technique that projects data onto orthogonal directions of maximum variance. "We apply per-dataset PCA over the different characteristic scores."
- Resolution-agnostic: Independent of image resolution, enabling models to operate consistently across different scales. "Screen coordinates are expressed in normalized form [0,1] to ensure resolution-agnostic training."
- Schema mapping: Translating source annotation formats into a unified target schema to ensure consistency across datasets. "Automation performs bulk ingestion and schema mapping; reviewers then verify key steps through targeted audits and spot-checks."
- Self-supervised copy-detection descriptors (SSCD): Learned image features trained without labels to detect near-duplicate content reliably. "self-supervised copy-detection descriptors (SSCD) \citep{sscd2023}"
- Sequence packing: Packing multiple sequences or turns into fixed-length contexts to maximize training throughput. "With sequence packing to the max length of 8192, this covers more than one effective epoch over the FineVision dataset."
- Train–test leakage: Undesired overlap between training and evaluation data that inflates performance estimates. "mitigating train--test leakage \citep{razeghi2022impact}, see Fig. \ref{fig:decontam}."
- Typed action schema: A structured schema where actions and their parameters have explicit types, aiding consistency and validation. "and produces a coherent, typed action schema."
- Vendi Score: A diversity metric equivalent to the effective rank computed from the normalized eigenvalue distribution. "(equivalent to the Vendi Score~\citep{friedman2023vendi})."
- Visual Dependency: The degree to which answering a question requires visual information rather than text alone. "We characterize every training turn by scoring it from 1-5 with LLM/VLM-as-a-judge (Qwen3-32B for text-only criteria and Qwen2.5VL-32B-Instruct for image-conditioned criteria, served locally via vLLM) along four characteristic axes: Formatting, Relevance, Visual Dependency, and Image--Question Correspondence (see Appendix~\ref{app:quality_ratings} for the full prompts)."
- vLLM: A high-throughput inference engine for serving LLMs efficiently. "served locally via vLLM"
- Welford’s algorithm: A numerically stable online algorithm for computing variance and covariance without storing all data. "Covariances are computed in a numerically stable way (e.g., via Welford's algorithm)."
Collections
Sign up for free to add this paper to one or more collections.

