BLIP3o-NEXT: Next Frontier of Native Image Generation
Abstract: We present BLIP3o-NEXT, a fully open-source foundation model in the BLIP3 series that advances the next frontier of native image generation. BLIP3o-NEXT unifies text-to-image generation and image editing within a single architecture, demonstrating strong image generation and image editing capabilities. In developing the state-of-the-art native image generation model, we identify four key insights: (1) Most architectural choices yield comparable performance; an architecture can be deemed effective provided it scales efficiently and supports fast inference; (2) The successful application of reinforcement learning can further push the frontier of native image generation; (3) Image editing still remains a challenging task, yet instruction following and the consistency between generated and reference images can be significantly enhanced through post-training and data engine; (4) Data quality and scale continue to be decisive factors that determine the upper bound of model performance. Building upon these insights, BLIP3o-NEXT leverages an Autoregressive + Diffusion architecture in which an autoregressive model first generates discrete image tokens conditioned on multimodal inputs, whose hidden states are then used as conditioning signals for a diffusion model to generate high-fidelity images. This architecture integrates the reasoning strength and instruction following of autoregressive models with the fine-detail rendering ability of diffusion models, achieving a new level of coherence and realism. Extensive evaluations of various text-to-image and image-editing benchmarks show that BLIP3o-NEXT achieves superior performance over existing models.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces BLIP3o-NEXT, an open-source AI model that can create images from text and edit existing images based on instructions. Its big idea is to combine two types of AI “brains” to get the best of both worlds: one that’s good at understanding and following instructions (autoregressive) and another that’s great at drawing fine details (diffusion). The result is a model that makes images that look realistic, follow what you ask, and can make smart changes to pictures you provide.
Objectives
The paper aims to:
- Build a single model that can both generate images from text and edit images using instructions.
- Figure out which model designs work best and why.
- Use reinforcement learning (a way for AI to improve by getting feedback) to help the model follow instructions better and render text in images more clearly.
- Improve image editing so that new images stay consistent with the original photo (for example, keeping the same person’s face or background).
- Show that high-quality, large-scale training data still matters a lot.
How the Model Works (Methods)
Think of BLIP3o-NEXT as a two-step artist:
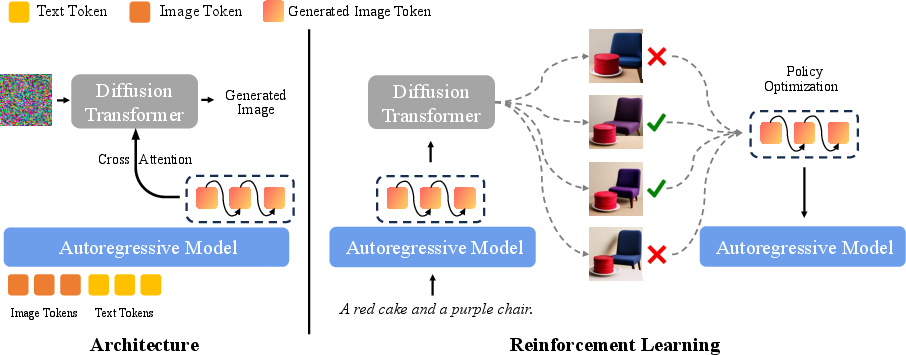
- The Autoregressive step: This part is like an author who writes one word at a time. Here, instead of words, the model predicts “image tokens,” which are tiny pieces that represent an image. It reads your text prompt (and, for editing, it also looks at your reference photos) and produces a sequence of these tokens.
- Tokens: Imagine turning a picture into a long list of small puzzle pieces. Each piece is a token.
- Hidden states: These are the model’s “thoughts” while it’s predicting each token—like notes it keeps internally.
- The Diffusion step: This part is like a painter who starts with a messy canvas full of noise and slowly cleans it up to reveal a detailed image. The painter uses the “thoughts” from the first step as guidance to create a high-quality, realistic image.
- Diffusion: Start with static (noise), then remove it step by step until a clear picture appears.
- Conditioning: The diffusion painter doesn’t work blindly—it uses the autoregressive model’s hints to know what to paint and how.
For image editing, the model uses both:
- High-level understanding from the prompt and the reference image (so it knows “what” to change).
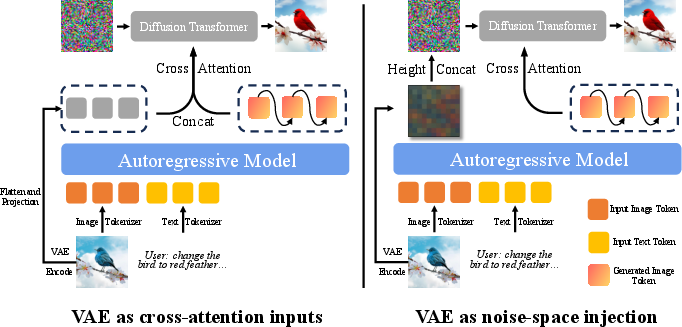
- Low-level details from the reference image’s VAE latents (a compact representation of pixel details) so the edited image stays consistent with the original look.
Reinforcement Learning (RL): The model “practices” by generating multiple images for a prompt, gets feedback (rewards) based on how well it followed instructions or rendered text, and adjusts itself to do better next time. This is similar to getting a score for each attempt and learning from it.
Data pipeline: To train well, the team used lots of diverse images, filtered out bad ones, wrote detailed captions, and also added synthetic examples (especially for tasks like putting readable text in images). Better data = better model.
Main Findings and Why They Matter
Here are the key takeaways the authors highlight:
- Simple, scalable designs work: Many architecture choices perform similarly if they scale well and run fast. You don’t always need a super complicated model to get good results.
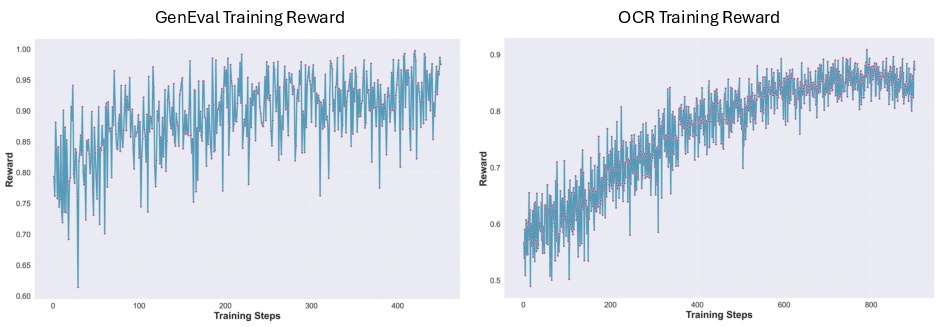
- Reinforcement Learning helps: RL noticeably improves instruction following and text rendering inside images (like shop signs or labels).
- Image editing is still tough: Keeping the new image consistent with the original (same person, same background) is hard. But combining instruction tuning, post-training, and VAE features improves consistency.
- Data is king: High-quality and large-scale data still sets the maximum performance—better data leads to better results.
Performance: BLIP3o-NEXT did very well on multiple benchmarks:
- Text-to-image tasks showed strong object composition and positioning.
- Visual text rendering improved after RL.
- Image editing performance was competitive with larger models, especially when using VAE features to preserve details from the reference image.
Open-source: They released the model weights, code, datasets, and evaluation tools so others can reproduce the results and build on them.
Implications and Impact
- Better creative tools: Designers, artists, and content creators get a model that follows instructions well and offers high-quality, realistic images.
- Smarter editing: The approach makes it easier to change parts of an image without breaking its original look, useful for product photos, portraits, and inpainting (fixing missing or damaged areas).
- RL in image generation: The paper shows that reinforcement learning—popular in LLMs—can also push image generation forward, especially for tasks with clear rewards (like “is the text readable?”).
- Data-centric AI: It reinforces a major lesson—scaling and improving data quality, along with post-training, is as important as clever model architecture.
- Future directions: To make image editing even better, the field needs improved reward models (ways to score how well an image follows instructions and matches a reference) and specialized training for tasks like inpainting and subject-driven edits.
In short, BLIP3o-NEXT demonstrates that combining an instruction-savvy “writer” model with a detail-perfect “painter” model, plus careful training and good data, can set a new standard for making and editing images directly from natural language.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
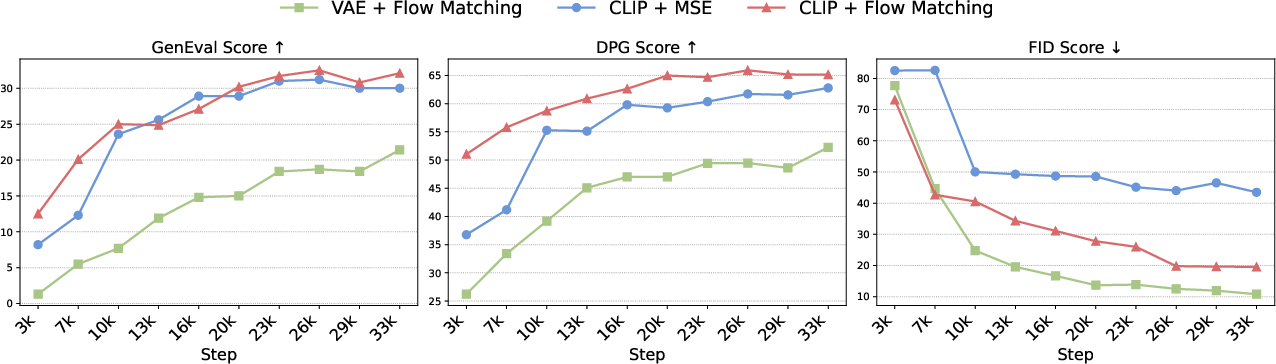
- Lack of controlled, quantitative ablations comparing conditioning strategies (hidden states vs continuous embeddings vs learnable queries), under matched compute/data, to substantiate the claim that “most architectures deliver comparable performance.”
- Unspecified and untested impact of allocating parameters between the autoregressive module and diffusion backbone (e.g., AR vs diffusion size ratios) on quality, speed, and instruction-following.
- No analysis of how discrete visual tokenization (SigLIP2-derived, 729 tokens at 384×384) is trained, what its codebook looks like, and how quantization affects reconstruction fidelity, instruction-following, and diversity.
- Missing evaluation of scalability to higher resolutions and variable aspect ratios, including how token length and conditioning change beyond 384×384 (e.g., 1024–4K), and whether an upscaling pipeline is needed.
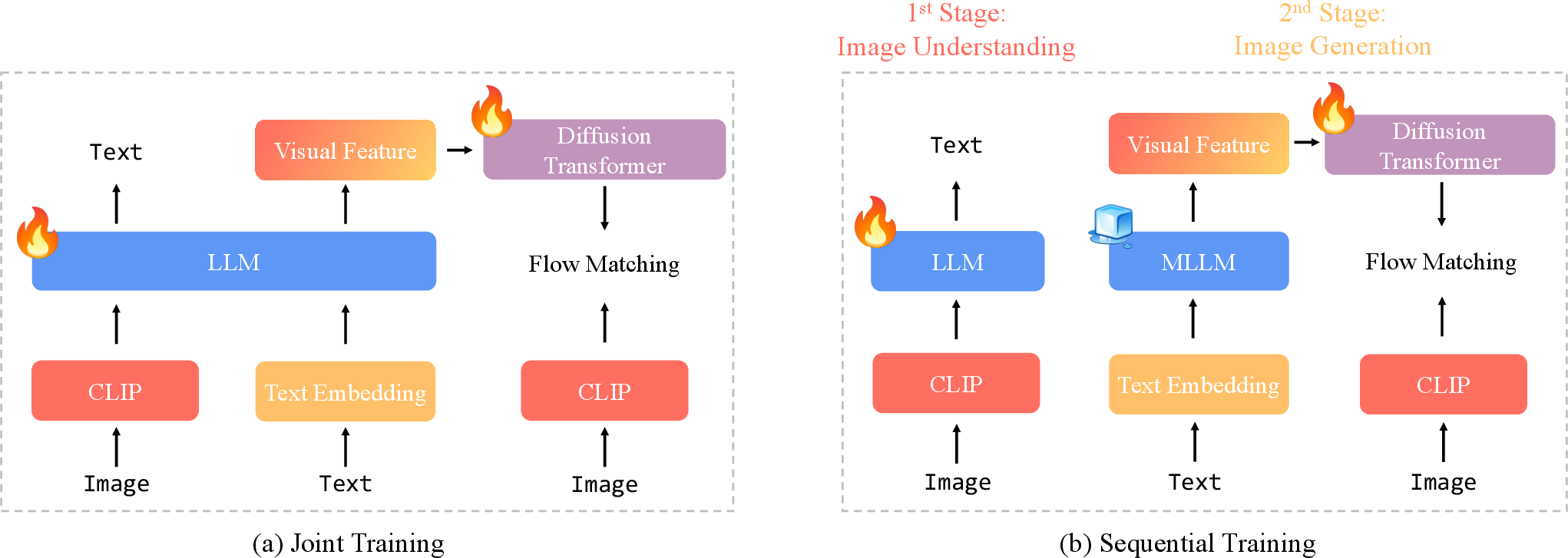
- The joint training objective is under-specified: no details or ablations on the cross-entropy vs diffusion loss balancing factor λ, scheduling, or whether stage-wise vs joint training yields better results or avoids interference with language abilities.
- Limited RL scope: RL is applied only to the autoregressive module; no controlled comparison to RL on the diffusion model with equivalent acceleration and compute, nor hybrid RL on both modules.
- RL stability/generalization details are missing: no sensitivity analysis to GRPO hyperparameters (KL coefficient, group size G, clip range), sample efficiency, policy collapse risks, or catastrophic forgetting of language reasoning.
- Reward design remains narrow (GenEval composition, OCR text): no composite reward for aesthetics, realism, preference alignment, faithfulness, and edit consistency; no study of reward hacking, weighting, or calibration across dimensions.
- Inference efficiency claims are qualitative: absent throughput/latency benchmarks, memory footprint, KV cache usage, and speed-quality trade-off across sampling steps; no comparison to diffusion-centric baselines under matched conditions.
- Editing consistency lacks a standardized, verifiable metric: reliance on GPT-4.1 judgments and qualitative examples without pixel/feature-level measures (e.g., LPIPS, DINO/CLIP similarity, ID/subject similarity for non-face entities, mask-region preservation).
- VAE latent integration for editing is only qualitatively assessed: no quantitative ablation of cross-attention conditioning vs noise-space injection vs combined, across edit categories; sensitivity to SANA’s downsampling ratio (32) and exploration of stronger/hybrid VAEs.
- No implementation or evaluation of the proposed system prompt strategies distinguishing inpainting vs subject-driven generation; unclear gains and failure modes for task-specific prompting.
- Masked or region-specific editing is not addressed (e.g., segmentation masks, bounding boxes), nor multi-image references or structural constraints (pose/layout), limiting edit controllability.
- Data engine transparency is incomplete: limited provenance/licensing details, potential evaluation contamination, demographic/domain bias analysis, and ablations separating data scale vs quality effects; unclear impact of prompt rewriting on model behavior.
- Safety, privacy, and ethics are unaddressed: watermark retention/removal, copyright adherence, identity/subject consent in subject-driven edits, content safety filters, and privacy risks from using reference images.
- Evaluation breadth is limited: absence of standard text-to-image metrics (FID, TIFA, HPSv2.1, PickScore/ImageReward/UnifiedReward) and human preference studies; reliance on GPT-based evaluation introduces potential biases and weak reproducibility.
- Diversity control via discrete tokens is unexplored: no ablations on temperature/top-k/top-p for AR sampling, and how token entropy interacts with diffusion fidelity and mode collapse.
- Robustness is not characterized: sensitivity to noisy/low-quality references, adversarial prompts, extreme compositions, long prompts, multilingual text rendering (non-English scripts), and domain/out-of-distribution shifts.
- Conditioning alignment is opaque: no analysis of how AR hidden states align with diffusion cross-attention, conditioning length effects, or auxiliary alignment losses to ensure stable semantic grounding.
- The frozen diffusion during RL may cause mismatches: no study of joint RL/fine-tuning on diffusion, curriculum or alternated updates, or how decoder stasis limits improvements in text rendering and composition.
- Missing scaling laws: no curves for performance vs parameters/compute/data scale; no exploration of diminishing returns or optimal training budgets for AR+Diff fusion.
- Training recipe reproducibility gaps: incomplete reporting of compute budgets, optimizer specifics, LR schedules, tokenization training details, seeds, and exact dataset mixtures/repetition ratios.
- Extension to video/3D remains open: how AR+Diff with VAE-latent conditioning generalizes to temporal coherence (video) and 3D/NeRF consistency, and which rewards/metrics enable stable temporal editing.
- High-resolution text layout and typography are under-evaluated: lack of rigorous benchmarks for diverse fonts, kerning, long-form text, and layout preservation at large aspect ratios/resolutions.
These gaps highlight concrete experiments, metrics, and engineering directions to strengthen architectural claims, improve editing consistency and controllability, expand RL efficacy, and ensure robust, safe, and reproducible image generation.
Practical Applications
Overview
Below are actionable, real-world applications derived from the paper’s architecture, training recipe, reinforcement learning pipeline, and image-editing innovations. Each item is categorized and linked to sectors, with expected tools/workflows and feasibility notes.
Immediate Applications
These can be deployed now using BLIP3o-NEXT’s open-source weights, code, and evaluation pipelines, plus standard GPU infrastructure.
- Brand-safe content generation and editing (Media, Marketing, E-commerce)
- Create and iteratively edit campaign assets, product images, lifestyle shots, and social posts with strong instruction following and improved text rendering (e.g., accurate signage, labels).
- Workflow: Prompt → AR token generation → Diffusion refinement → A/B test with GenEval-like verifiable metrics → Deploy.
- Tools: Figma/Adobe plugins; web APIs; batch processors for catalogue imagery.
- Assumptions/Dependencies: Access to GPUs; content policy filters; prompt templates; upscaling for >384×384 output; human-in-the-loop approvals.
- Product listing automation with reference-image edits (E-commerce)
- Background replacement, style normalization, lighting adjustments, and multilingual text-on-image for SKUs using VAE-latent-conditioned editing for better consistency.
- Tools: Listing editors integrated into CMS; automated background standardizers; OCR-assisted text placement.
- Assumptions/Dependencies: Clean reference images; watermark- and rights-aware datasets; OCR checks; image provenance logs.
- Retail signage and packaging mockups with robust text rendering (Manufacturing, Retail Design)
- Generate packaging, shelf labels, event signage with improved verifiable text accuracy (leveraging RL + OCR-based rewards).
- Tools: Signage generators; packaging mockup assistants; compliance checks via PaddleOCR.
- Assumptions/Dependencies: Reward functions for text correctness; brand styleguide constraints; QA for localization.
- Localization at scale for visual assets (Media, Education, Government Comms)
- Translate and regenerate visuals (labels, instructions, public notices) while maintaining layout consistency via VAE latent conditioning and instruction-following.
- Tools: Localization pipelines; prompt rewriting; CLIP- or OCR-based alignment checks.
- Assumptions/Dependencies: Accurate translation; culturally appropriate imagery; accessibility standards.
- Creative ideation boards and mood panels (Design, Interior, Fashion)
- Rapid concept visualization and iterative editing (subject-driven vs. inpainting) using system prompts for better task separation.
- Tools: “Edit intent” toggles in UI; mood board generators; iterative edit histories.
- Assumptions/Dependencies: Curated design prompts; controllable seed management; export to standard formats.
- Synthetic dataset generation for OCR and visual composition (Software, Academia)
- Produce high-quality synthetic images for training/evaluating OCR, object relationships, and composition (e.g., GenEval-style tasks).
- Tools: Synthetic data engines; integrated reward-driven sampling; benchmark suites.
- Assumptions/Dependencies: Reward models calibrated to target tasks; dataset governance; bias and diversity controls.
- Reproducible multimodal RL experiments (Academia)
- Leverage compatibility with LLM RL infrastructures (GRPO) to study policy optimization on discrete image tokens; test reward designs on text rendering and multi-object composition.
- Tools: Open-source training scripts; reward model libraries; benchmark automation.
- Assumptions/Dependencies: Compute; standardized reward definitions; careful hyperparameter management.
- Quality assurance gates for image generation (Enterprise Software)
- Integrate verifiable metrics (GenEval, OCR correctness) into CI/CD for content pipelines to auto-flag low-quality or misaligned outputs.
- Tools: “Visual QA” steps; scoreboards; auto-regeneration loops; audit logs.
- Assumptions/Dependencies: Thresholds tuned per domain; stable evaluators; content provenance tracking.
- Small business visual assistants (Daily Life, SMB)
- Simple web apps that generate/edit flyers, menus, event invitations, and product photos with accurate on-image text and consistent branding.
- Tools: Template-driven editors; mobile apps; preset style guides.
- Assumptions/Dependencies: Lightweight inference or hosted APIs; default safety filters; straightforward UX.
- Educational visual aids and worksheets (Education)
- Generate diagrams, step-by-step visuals, and annotated images with controllable text and layout; iterate edits to align with lesson plans.
- Tools: Classroom content generators; instructor dashboards; rubric-based evaluators.
- Assumptions/Dependencies: Age-appropriate filters; curriculum alignment; accessibility (alt text, contrast).
- Benchmarking suites for image editing consistency (Academia, Standards Orgs)
- Use the released evaluation pipelines to build standardized tests for instruction-following and reference-image consistency; publish comparative leaderboards.
- Tools: ImgEdit-like evaluations; reward aggregators; public reports.
- Assumptions/Dependencies: Open datasets; clear protocols; community buy-in.
- Cost-aware server-side generation for mid-resolution assets (Software, Cloud)
- The 3B AR + diffusion architecture supports practical server-side deployment for 384×384 assets with diffusion acceleration.
- Tools: Autoscaling GPU clusters; KV-cache utilization for AR; deterministic seeds for reproducibility.
- Assumptions/Dependencies: Efficient diffusion acceleration; caching strategies; monitoring for drift.
Long-Term Applications
These depend on further research in reward design, scaling, diffusion acceleration, dataset quality, or new task formulations.
- High-fidelity subject-driven editing with pixel-level guarantees (Media, E-commerce)
- Stronger consistency between outputs and reference images (e.g., exact textures, logos, facial features) via improved VAE latents, better reconstruction tasks, and editing-specific RL.
- Tools: Consistency reward models; identity/brand lock modules; edit-type-aware system prompts.
- Assumptions/Dependencies: New reward functions for fine-grained similarity; legal/ethical guardrails.
- Unified reward models balancing quality, instruction-following, and human preference (Software, Academia)
- Move beyond single-dimension verifiable rewards to multi-criteria preference learning (UnifiedReward-like) for holistic quality control.
- Tools: Composite reward aggregators; human-in-the-loop feedback platforms; preference datasets.
- Assumptions/Dependencies: Robust, unbiased preference data; standardization across domains; interpretability.
- Domain-specific generators (Healthcare, Engineering, Scientific Visualization)
- Specialized models for medical diagrams, lab process illustrations, or CAD-like renders, benefiting from AR reasoning and diffusion fidelity.
- Tools: Regulated datasets; domain-tuned prompts; expert-in-the-loop validators.
- Assumptions/Dependencies: Access to licensed, high-quality domain data; strict compliance; risk mitigation against hallucinations.
- Synthetic perception data for robotics and autonomous systems (Robotics)
- Generate diverse, label-rich visuals for training and domain randomization (lighting, backgrounds, occlusions), improving downstream robustness.
- Tools: Scenario generators; label consistency checkers; sim-to-real pipelines.
- Assumptions/Dependencies: Accurate physical priors; task-relevant annotation schemas; transfer learning strategies.
- Interactive co-creation agents (Productivity, Creative Tools)
- Multimodal assistants that understand context (previous edits, reference assets) and apply stepwise reasoning for complex visual tasks.
- Tools: In-context edit memory; structured “plan and execute” workflows; reversible edit logs.
- Assumptions/Dependencies: Continual learning safeguards; user intent detection; privacy controls for assets.
- Policy-grade provenance, auditing, and evaluation standards (Policy, Compliance)
- Institutionalize standardized benchmarks and audit trails for generated/edited images (e.g., public-sector communication, consumer protection).
- Tools: Provenance metadata; evaluation dashboards; conformance testing suites.
- Assumptions/Dependencies: Regulatory frameworks; watermarking/signature tech; public reporting norms.
- On-device or edge deployments with fast diffusion acceleration (Mobile, AR/VR)
- Real-time editing and generation for AR experiences, try-ons, and overlays via lighter diffusion backbones, quantization, and caching.
- Tools: Edge inference runtimes; low-power accelerators; progressive generation UX.
- Assumptions/Dependencies: Hardware advances; efficient model compression; safety/latency trade-offs.
- Video, 3D asset, and multimodal expansion (Media, Gaming, Digital Twins)
- Extend the AR + diffusion paradigm to temporal and spatial modalities: controllable video generation, textured 3D models, scene edits.
- Tools: SDE/ODE-based GRPO variants (DanceGRPO, MixGRPO) adapted to video/3D; multimodal reward models.
- Assumptions/Dependencies: Scalable training data; temporal consistency rewards; renderer integrations.
- Automated compliance gating for brand and legal constraints (Finance, Retail, Gov)
- Incorporate rulesets (logos, disclaimers, regulated text) into the generation loop with verifiable checks to block violations.
- Tools: Rule-aware prompts; constraint solvers; post-generation validators.
- Assumptions/Dependencies: Machine-readable policies; reliable detectors; escalation workflows.
- Curriculum-driven visual learning platforms (Education)
- Adaptive, reward-guided generators for personalized study materials with verified correctness (diagrams with labels, math visuals).
- Tools: Teacher-in-the-loop RL; alignment with standards; continuous assessment.
- Assumptions/Dependencies: Pedagogical validation; content safety; age-appropriate tuning.
- Data engine innovation and governance (Cross-sector)
- Scalable pipelines for filtering, captioning, distillation, and synthetic augmentation that raise the performance ceiling while ensuring ethical sourcing.
- Tools: Data curation dashboards; bias/quality monitors; licensing trackers.
- Assumptions/Dependencies: Policy-compliant sources; transparent documentation; community standards.
Notes on Feasibility and Dependencies
- Compute and latency: Diffusion remains the primary latency bottleneck; acceleration and caching strategies are key.
- Resolution and fidelity: The current pipeline focuses on 384×384 tokens; production often requires upscaling and super-resolution.
- Reward design: Verifiable rewards (e.g., OCR, GenEval) work well for narrow tasks; multi-objective, preference-aligned rewards are still a research gap.
- Data quality and licensing: Performance hinges on diverse, clean, licensed datasets with strong caption alignment and governance.
- Safety, ethics, and IP: Policies for identity, brand, and sensitive content are essential; provenance and audit tooling should be part of deployments.
- Open-source ecosystem: Adoption benefits from maintained code, checkpoints, evaluation scripts, and community benchmarks; versioning and reproducibility matter.
Glossary
- Autoregressive + Diffusion: A hybrid architecture that uses an autoregressive module to produce conditions for a diffusion module to synthesize images. "BLIP3o-NEXT adopts a hybrid Autoregressive + Diffusion architecture"
- Autoregressive model: A model that generates outputs token-by-token conditioned on prior tokens and inputs. "The autoregressive model is trained on three primary tasks: (1) text-to-image generation, (2) input image reconstruction, and (3) image editing"
- Brownian motion: A stochastic process used to inject randomness in trajectory sampling for RL in diffusion models. "where denotes Brownian motion and controls the magnitude of randomness."
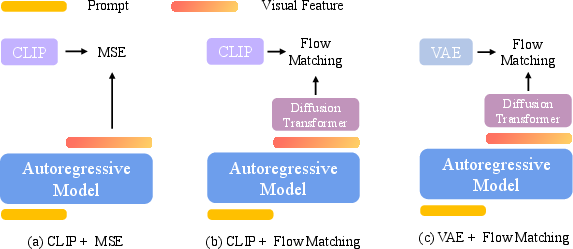
- CLIP representations: Semantic image embeddings produced by CLIP, used as conditioning inputs for generation. "The autoregressive model directly generates continuous embeddings (e.g., CLIP representations), which are then used as conditions for the diffusion model"
- Conditioning signal: Information passed to the diffusion model to guide image synthesis. "the hidden states from the autoregressive model are directly used as the conditioning signal for the diffusion model"
- Continuous embeddings: Real-valued vector representations, often used as conditions for generative models. "The autoregressive model directly generates continuous embeddings (e.g., CLIP representations)"
- Cross-attention: An attention mechanism that fuses conditioning tokens with the diffusion transformer’s internal states. "(1) VAE features as cross-attention inputs in DiT."
- Cross-entropy loss: A standard next-token prediction loss used to train autoregressive models. "denotes the cross-entropy loss over text and discrete image tokens in autoregressive model"
- DanceGRPO: An RL method extending GRPO to various visual generation modalities under stochastic formulations. "DanceGRPO extends GRPO to a broader range of visual generation tasks, including text-to-image, text-to-video, and image-to-video."
- Diffusion model: A generative model that iteratively denoises random noise into an image under conditioning. "The diffusion model subsequently leverages the final hidden states of generated discrete tokens as conditioning signals to synthesize the final image."
- Diffusion Transformer (DiT): A transformer-based diffusion model used for image generation. "the diffusion transformer with SANA1.5"
- Direct Preference Optimization (DPO): An RL method that optimizes models directly from preference data without reward modeling. "Qwen-Image is the representative model to successfully apply both DPO and Flow-GRPO within a native image generation model."
- Flow-GRPO: An RL framework applying GRPO to flow/diffusion models with stochastic trajectory sampling. "After the DPO stage, Qwen-Image uses additional fine-grained reinforcement learning with GRPO, following the Flow-GRPO framework"
- Flow matching: A training approach that models trajectories via velocity fields to align distributions in flow-based generative models. "trajectories are sampled according to the flow matching dynamics:"
- GenEval: A verifiable benchmark for compositional object evaluation in image generation. "evaluation is performed with the GenEval evaluator."
- Group Relative Policy Optimization (GRPO): A policy optimization algorithm that normalizes rewards across sampled groups for stable updates. "We use the Group Relative Policy Optimization (GRPO) algorithm under BLIP3o-NEXT framework."
- Hidden states: Internal token representations produced by transformers used for downstream conditioning and decoding. "hidden states are then used as conditioning signals for a diffusion model"
- Hyperparameters: Tunable parameters controlling optimization behavior in training. "Here, and are hyperparameters"
- Image reconstruction task: A training objective where the model reproduces the input image to improve fidelity and consistency. "We perform an image reconstruction task, where the reference image is provided as input and the text prompt is “Keep the image unchanged.”."
- Inpainting: Editing that fills or modifies specific regions of an image while preserving surrounding context. "system prompts that explicitly distinguishes between inpainting and subject-driven generation tasks."
- Instruction tuning: Fine-tuning on curated instruction-following datasets to align generation with user intent. "and BLIP3o-60K as the instruction tuning dataset."
- KL divergence: A regularization term penalizing divergence from a reference policy during RL training. "a KL divergence penalty that constrains policy updates relative to the reference policy."
- KV cache: Cached key-value attention states enabling faster transformer inference; typically absent in diffusion models. "applying RL to diffusion model is slower due to the lack of KV cache support and the need for multiple time steps."
- Learnable query tokens: Trainable tokens that compress conditioning information into a fixed-size representation. "continuous embeddings and learnable query tokens generate conditioning signals by sampling from AR models"
- Mixture of Transformers: An architecture with multiple transformer experts for understanding and generation that share multimodal attention. "Mixture of Transformers"
- Multimodal self-attention: Attention across tokens from different modalities within the same transformer block. "tokens from different modalities interact through shared multimodal self-attention within each transformer block."
- Multitask learning: Joint training on multiple objectives to improve generalization and task synergy. "we adopt a multitask learning setup that jointly trains the model on both image reconstruction and image editing objectives."
- Noise-space injection: A conditioning strategy that concatenates VAE features with the diffusion noise tensor during denoising. "VAE features as noise-space injection."
- Optical Character Recognition (OCR): Automated text extraction from images used to evaluate visual text rendering. "OCR-based evaluation for visual text rendering."
- Ordinary Differential Equation (ODE): Deterministic formulation of flow dynamics; combined with SDE for efficient RL. "MixGRPO further improves computational efficiency by combining SDE and ODE based formulations."
- Policy optimization: The process of updating a policy to maximize expected reward under constraints. "policy optimization is performed directly on the AR model"
- Prompt rewriting: Automatic enhancement of prompts to improve instruction following and generation quality. "we use prompt rewriting to enrich prompt details and improve instruction following abilities"
- Quantization: Mapping continuous embeddings to a discrete token vocabulary for autoregressive prediction. "the resulting continuous embeddings are quantized into a finite vocabulary of tokens"
- Rectified flows: A flow-based sampling formulation extended for GRPO in visual generation. "reformulates both diffusion sampling and rectified flows within the framework of stochastic differential equations"
- Reward models: Models or functions that score generated outputs to guide RL training (e.g., quality, alignment, preference). "reward models that can effectively capture and balance multiple dimensions, including image quality, instruction following, and human preference alignment."
- Rollouts: Sampled trajectories or outputs used to compute rewards and advantages in RL. "rollouts are rendered from the diffusion transformer"
- Semantic compositionality: The ability to combine multiple semantic elements coherently in generation. "combines the semantic compositionality and global structure understanding captured by the autoregressive model"
- SigLIP2: A vision encoder producing continuous embeddings for images prior to quantization. "each image is first encoded using the SigLIP2 model"
- Stochastic Differential Equation (SDE): A probabilistic formulation of flow dynamics enabling exploration in RL. "Flow-GRPO reformulates trajectory sampling as a stochastic differential equation (SDE)"
- Subject-driven generation: Editing or synthesis focused on preserving the identity and appearance of the subject. "subject-driven generation emphasizes maintaining consistency in the subject’s appearance."
- Variational Autoencoder (VAE): A latent-variable generative model used for compressing and reconstructing images. "the VAE in SANA uses a downsampling ratio of 32 to accelerate training and inference"
- VAE features: Latent representations extracted from a VAE used as low-level conditioning signals. "integrating the VAE features of reference images for editing tasks"
- VAE latents: Compressed latent tensors from a VAE used to preserve fine-grained details during diffusion. "incorporate low-level, detail-preserving VAE latents as additional conditioning signals"
- Velocity: The time derivative of the flow state used in flow matching and rectified flow training. "where is the velocity predicted by the model."
- Vision–LLM (VLM): A multimodal model jointly processing images and text for understanding and generation. "visionâLLMs such as Qwen-VL"
- Visual text rendering: Generating legible, accurate text within images; often evaluated via OCR. "Visual text rendering: training prompts are also sourced from Flow-GRPO"
Collections
Sign up for free to add this paper to one or more collections.

