Learning an Image Editing Model without Image Editing Pairs (2510.14978v1)
Abstract: Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-LLMs (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a computer to edit images based on written instructions (like “make the sky pink” or “remove the cup”) without needing example “before-and-after” image pairs. The authors build a system called NP-Edit that learns from feedback given by a smart vision-LLM (a model that can “look” at images and “read” text) and makes sure edits still look like real photos.
What questions did the researchers ask?
They focused on three main questions, phrased in simple terms:
- Can we train an image editor without showing it matching “before-and-after” examples?
- Can a vision-LLM (VLM)—acting like a judge—tell the editor if it followed the instruction and didn’t mess up the rest of the image?
- Can we keep the edited images looking realistic while still following the instruction?
How did they do it?
Think of the system as three parts: a learner (the image editor), a judge (the VLM), and a safety rail (to keep images realistic).
Key ideas and how they work (in everyday language)
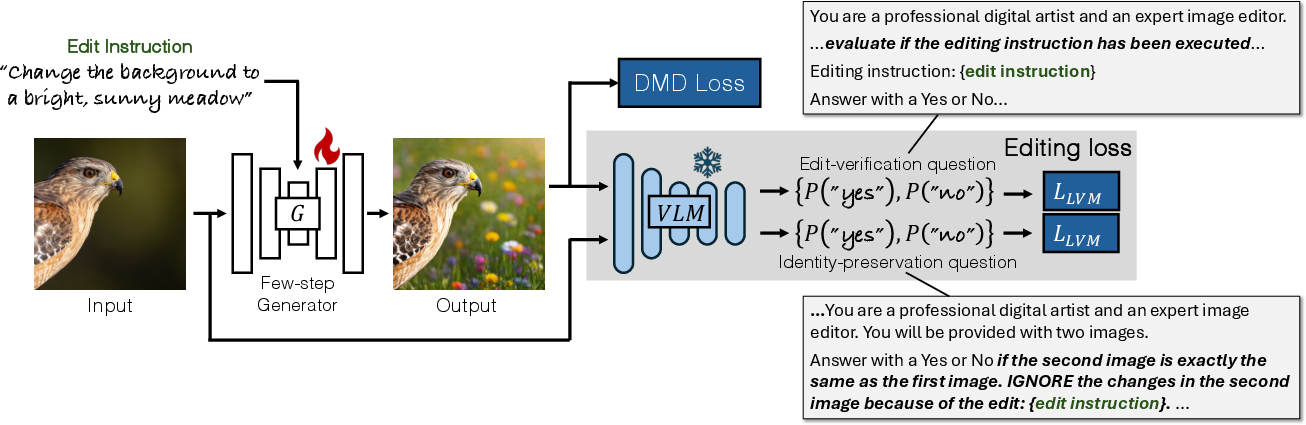
- Few-step diffusion editing: Modern image generators often work by adding noise to an image and then removing it step-by-step to create or edit a picture. Doing this in many small steps can be slow. The authors train a faster editor that works in just a few steps (like 4), which is quicker and still looks good. During training, they “unroll” two steps so the judge’s feedback can flow back and teach the editor what to change.
- The judge (VLM) gives clear, simple feedback: After the editor tries an edit, the VLM is asked yes/no questions like:
- “Did the edit instruction happen?” (Edit verification)
- “Aside from the requested change, is the edited image still the same as the original?” (Identity preservation)
- These yes/no answers become a learning signal, so the editor knows exactly what to improve.
- Staying realistic with a “teacher” model: To make sure results still look like real photos, the editor is nudged to match the style and realism of a strong, pre-trained text-to-image model. This is called distribution matching (you can think of it as keeping the edited images inside the “universe” of real-looking images the teacher knows well). It acts like safety rails to prevent weird or fake-looking results.
- No paired data needed: Instead of collecting hard-to-find “before-and-after” training pairs, they use large sets of images and automatically written instructions/captions (created and checked by a VLM). The editor learns by repeatedly trying edits, getting judged, and adjusting.
- Why “few steps”? If the images are too noisy during training, the judge gets confused. Few-step generation produces clearer pictures sooner, making the judge’s feedback more reliable and training faster.
What did they find?
Here is what their tests showed:
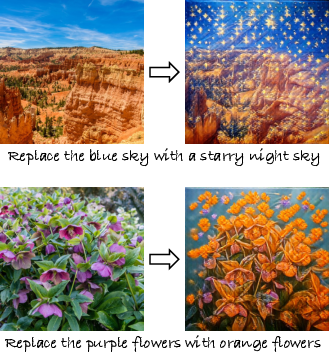
- Competitive quality without paired data: NP-Edit performs as well as or better than many editing models that were trained using large, supervised “before-and-after” datasets, especially when everyone is limited to a few editing steps.
- Strong realism and instruction-following: Their system scored high on following the instruction (semantic consistency) and on the look/quality of the images (perceptual quality), on common benchmarks like GEdit-Bench and ImgEdit.
- Works for free-form edits, too: On “customization” tasks (for example, placing the same object in different scenes), NP-Edit was comparable to other top methods, even with fewer steps.
- Better than a popular RL approach given the same judge: When compared to a reinforcement learning (RL) method that also uses a VLM as a judge (Flow-GRPO), NP-Edit did better—without needing an initial supervised training stage.
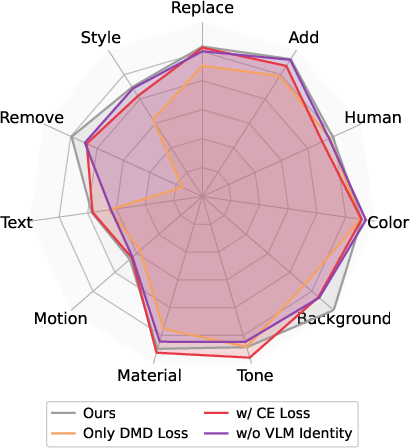
- Every piece matters: Ablation studies (turning parts off to test their importance) showed:
- Without the judge’s feedback, the model doesn’t follow instructions well.
- Without the realism safety rails (distribution matching), images can look fake or training can become unstable.
- Asking yes/no questions and including an identity check improves results.
- More diverse data and stronger VLM judges both lead to better performance.
Why it matters
Collecting “before-and-after” image pairs for every kind of edit is hard and expensive. This work shows you can skip that step: a smart judge can guide the learning. That means:
- Faster progress: New editors can be trained without building huge paired datasets.
- Scales with better judges: As vision-LLMs get smarter, this approach should naturally improve.
- Practical speed: The editor works in just a few steps, which is useful for apps where users want quick results.
Implications and potential impact
- Easier training for many tasks: This “learn from a judge” idea could help train not just image editors, but other tools (like style transfer or object insertion) without paired examples.
- Better, safer editing tools: The “safety rails” keep edits realistic, making the system more reliable for creative software, photo apps, and design tools.
- Future improvements: Using even stronger VLMs and bigger, more varied datasets should make edits more accurate and detailed. The authors note a current limit: without pixel-perfect supervision, tiny details or exact identities can sometimes drift. They also mention that running a large VLM judge needs memory, but future, more efficient judges could help.
In short, the paper shows a practical, scalable way to train high-quality image editors by combining a helpful judge (VLM feedback) with safety rails (distribution matching), all without needing hard-to-get “before-and-after” training pairs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues, uncertainties, and unexplored areas that future work could concretely address:
- Robustness to VLM inaccuracies: The approach assumes VLM answers are correct; there is no systematic calibration, adversarial testing, or uncertainty estimation for VLM judgments, especially under hard or ambiguous edits.
- Bias and coverage of VLM “judge”: No analysis of how VLM reward quality varies across domains (e.g., non-photorealistic, medical, scientific diagrams), sensitive attributes, or culturally diverse content; bias mitigation is not addressed.
- Binary “Yes/No” supervision is coarse: Editing quality is reduced to two tokens; richer, graded signals (scores, rationales) or multi-criteria judgment are not explored.
- Reward hacking failure modes: The model might learn to maximize VLM “Yes” responses via artifacts that mislead the judge; countermeasures (e.g., adversarial evaluation, ensemble judges) remain open.
- Identity preservation without pairs: Pixel- or instance-level alignment is weak; the paper shows LPIPS helps but degrades edits. Designing identity-aware objectives that preserve instance-level features without paired data is an open challenge.
- Spatial control and locality: The method lacks explicit mask/region guidance; how to precisely constrain edits to specified areas or avoid unintended collateral changes is not explored.
- Structured constraints: Geometry-, physics-, and layout-consistent edits (e.g., viewpoint changes, shadows, reflections) are not studied; integrating differentiable constraints or specialized detectors is open.
- Text editing fidelity: Robust editing of in-image text (fonts, legibility, OCR alignment) isn’t explicitly evaluated; integrating OCR-based rewards or typography constraints is unexplored.
- Multi-step supervision: VLM judgments on noisy intermediate steps are unreliable, motivating few-step training; strategies for stable multi-step training (e.g., denoising-aware prompts, progressive rewards) are not investigated.
- Caption dependence in DMD: Distribution matching relies on edited-image captions (often VLM-generated). Sensitivity to caption quality, mismatch with actual edits, and failure modes when captions drift are unquantified.
- Teacher-model bias propagation: DMD aligns outputs to the teacher’s learned image manifold, potentially reintroducing biases/artifacts the paper aims to avoid; alternatives that anchor to real image distributions are not explored.
- Data quality and noise: The instruction dataset (3M local; ~600K free-form) is VLM-generated/validated; label noise, instruction correctness, and hallucination rates are not audited or de-noised.
- Synthetic vs real references: For customization, some references are model-generated; the impact of synthetic references on generalization and identity preservation is unstudied.
- Dataset diversity and balance: Coverage across edit types, object categories, lighting, occlusions, resolutions, and non-English instructions is not characterized; multilingual instruction following remains open.
- Scaling laws: While performance improves with data and stronger VLMs, there is no quantitative scaling analysis versus model size, data size, and VLM capacity to guide resource allocation.
- Parameter-efficient fine-tuning: The method uses full fine-tuning of a 2B DiT; the trade-offs for LoRA/adapters, partial freezing, and layer-wise updates (cost, stability, performance) are not examined.
- Compute and memory overhead: VLM-in-the-loop training imposes VRAM and runtime costs; the paper doesn’t quantify throughput, latency, or cost vs. quality trade-offs or propose optimizations (e.g., caching features).
- Safety and misuse: Editing can enable deepfake-like manipulations; there is no mechanism for detecting harmful instructions, enforcing safety constraints, or preventing identity misuse.
- Evaluation breadth and rigor: Reliance on VIEScore (GPT-4o-based) lacks cross-judge validation, human preference studies, task-specific metrics (e.g., pose/action consistency), or fairness/robustness reporting.
- Per-category failure analysis: Systematic breakdown of failure cases (e.g., removal, replace, style) and targeted remedies (losses, prompts, auxiliary models) are limited.
- Sequential/compositional edits: Handling multi-instruction sequences, cumulative edits, and compositionality is not studied; maintaining consistency across editing chains remains open.
- Region-aware rewards: VLM questions ignore spatial locality; integrating referring expressions, grounding modules, or segmentation-aware reward shaping is unexplored.
- Confidence-aware generation: The model does not expose a confidence score or uncertainty about edit success; mechanisms for self-assessment and fallback strategies are lacking.
- Alternative post-training paradigms: Comparisons focus on RL (Flow-GRPO); adapting DPO or hybrid RL/DPO for image editing—and their stability without paired SFT—are untested.
- Warmup identity loss trade-offs: The identity warmup may inhibit large edits; its duration/intensity vs. final edit strength fidelity trade-offs are not analyzed.
- High-resolution and photorealism limits: Maximum output resolution, fine-grain detail preservation, and degradation at higher resolutions are not reported.
- Generalization to additional tasks: Inpainting, restoration, relighting, and compositing beyond the evaluated benchmarks are not assessed; extending the framework to these remains open.
- Instruction robustness and OOD detection: Mechanisms to detect unsupported or out-of-distribution edit instructions and gracefully decline or request clarification are not implemented.
- Integration with user-provided guidance: Combining language instructions with masks, sketches, keypoints, or bounding boxes for more controllable editing is left for future work.
- Data licensing and ethics: Source data licensing, privacy, and consent issues—especially for identity-centric customization—are not discussed.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be implemented now by leveraging the paper’s core contributions: VLM-based differentiable feedback for instruction-following edits and distribution matching (DMD) for realism, within a few-step diffusion editing model.
- Instruction-driven photo editing in consumer apps
- Sector: software, consumer imaging, mobile
- What: One-click, natural-language edits such as remove object, change background, adjust color/material, stylize, add/replace elements, and simple action edits while preserving the core content of the reference image.
- Tools/workflows:
- “Instruction Edit” mode in photo apps (mobile and desktop) using a few-step editing head for low-latency inference.
- Batch-edit CLI/SDKs for social media managers and creators.
- Assumptions/dependencies:
- A sufficiently strong VLM (e.g., LLaVA-7B class) resident on GPU/accelerator during training; at inference time, only the editor is needed.
- Identity preservation is good but not pixel-perfect; high-stakes use may require extra alignment losses or manual review.
- Creative production and marketing automation
- Sector: media/entertainment, advertising, e-commerce
- What: Rapid generation of on-brand variants (style changes, background localization, colorways) and compliance-safe imagery (e.g., removing alcohol, flags, or other regulated elements per region).
- Tools/workflows:
- Brand-safe editor with rule templates mapped to yes/no VLM questions (e.g., “Are all alcoholic beverages removed?”).
- Campaign A/B pipelines that auto-generate and verify multiple visual variants in a few steps.
- Assumptions/dependencies:
- VLM-as-judge templates need domain-specific curation to avoid false approvals.
- Base text-to-image model quality sets an upper bound on realism the DMD can enforce.
- Product image editing at scale for e-commerce
- Sector: retail/e-commerce
- What: Background swaps, color/material changes, logo insertions/removals, “lifestyle” scenes from basic studio shots, and cleanup of artifacts or photobombers.
- Tools/workflows:
- Headless editing microservice/API for DAM (digital asset management) systems; batch pipelines for catalogs.
- Assumptions/dependencies:
- Strong identity preservation is generally sufficient for catalog workflows; for pixel-critical edits (e.g., stitching lines), add perceptual/structure-preserving losses or light human QA.
- Content moderation and redaction workflows
- Sector: policy/compliance, finance, public sector, enterprise IT
- What: Object removal (weapons, sensitive logos), anonymization (blur/remove faces, license plates), redaction of PII on document images.
- Tools/workflows:
- “Policy templates” converted to binary VLM questions during training and to runtime QA checkers for verification on outputs.
- Assumptions/dependencies:
- Reliability of removal for edge cases (tiny objects, clutter) may require additional detectors or hybrid rules; false negatives should be flagged for manual review.
- Legal/compliance sign-off requires auditable prompts and logs.
- Dataset augmentation for computer vision and robotics
- Sector: autonomy/robotics, CV research, simulation
- What: Domain randomization for sim-to-real transfer—add/remove objects, varied backgrounds, lighting adjustments—while maintaining core scene semantics.
- Tools/workflows:
- Synthetic augmentation recipes that run instruction templates over unlabeled corpora; use DMD to keep images realistic.
- Assumptions/dependencies:
- VLM judgments can be biased or brittle for adversarial/ambiguous scenes; add simple detectors (depth/segmentation) or human spot checks for critical training sets.
- Personalization and customization (DreamBooth-style)
- Sector: creator tooling, branding
- What: Place a user’s object/mascot/logo into new contexts without paired training data or long fine-tuning, leveraging the few-step editor’s customization ability.
- Tools/workflows:
- “Custom object in many contexts” assistant integrated into creative suites; templates for backgrounds and styles validated by VLM questions.
- Assumptions/dependencies:
- Identity fidelity can drift on fine-grained details; optionally add LPIPS-like constraints or a small SFT warm-start to improve identity.
- Developer libraries for “no-pair” fine-tuning and VLM-judged post-training
- Sector: software/ML platforms, open-source
- What: A turnkey training recipe that uses VLM binary QA as differentiable loss plus DMD to adapt base text-to-image models into instruction-following editors without paired data.
- Tools/workflows:
- “No-Pair Editor Trainer” library with plug-in support for LLaVA/InternVL backbones; recipes for unrolled few-step training.
- Assumptions/dependencies:
- Licensing for base models and VLMs; GPU memory budget to co-run VLM and generator during training.
- Quality assurance harness for generative outputs
- Sector: MLOps, enterprise AI governance
- What: Reusable VLM QA prompts to verify specific constraints (presence/absence of elements, style consistency, brand colors).
- Tools/workflows:
- VLM-QA “verification gates” in CI/CD for creative pipelines; dashboards for pass/fail analytics.
- Assumptions/dependencies:
- VLM QA calibration and logging for audits; periodic prompt updates to mitigate drift and biases.
Long-Term Applications
These applications require further research, scaling, or engineering, particularly in VLM reliability, identity preservation, multimodal extension (video/3D), and safety.
- Video editing without paired supervision
- Sector: media/entertainment, social platforms
- What: Extend NP-Edit to temporally consistent, instruction-driven video edits (add/replace/remove, style, action tweaks) with VLM feedback upgraded to video QA.
- Tools/workflows:
- Few-step video diffusion with differentiable VLM video-judges; temporal identity-preservation losses; content verification over sequences.
- Assumptions/dependencies:
- Strong, efficient video VLMs; robust temporal coherence constraints; significant compute.
- 3D/NeRF/asset editing with VLM feedback
- Sector: gaming, AR/VR, 3D content creation
- What: Instruction-based edits on 3D assets (geometry/material/lighting) guided by VLM judgments over renderings; DMD generalized to 3D distributions.
- Tools/workflows:
- “No-pair 3D editor” that optimizes assets directly with differentiable multi-view QA; CAD-aware constraints.
- Assumptions/dependencies:
- Differentiable rendering loops; reliable 3D-aware VLMs; geometry-aware identity preservation.
- High-stakes domains: medical, scientific, forensic
- Sector: healthcare, life sciences, forensics
- What: Controlled edits for anonymization (e.g., removing burn-in or PHI), data augmentation for rare pathologies, or artifact cleanup with stringent realism constraints.
- Tools/workflows:
- Editor modes with locked clinical constraints; VLM QA paired with domain-specific detectors; fail-safe conservative settings.
- Assumptions/dependencies:
- Regulatory approval; clinically validated QA; near-zero tolerance for hallucinations; strong provenance tracking.
- Interactive agents for iterative editing with self-correction
- Sector: productivity tools, creative AI
- What: Agentic loops where the editor proposes an edit, VLM critiques, and the editor refines over a few iterations while preserving identity and realism.
- Tools/workflows:
- Edit–evaluate–refine controllers; multi-constraint VLM prompts (instruction adherence, realism, identity).
- Assumptions/dependencies:
- Robustness against cycling or overfitting to VLM quirks; latency budgets for interactive sessions.
- On-device, private editing with compact VLMs
- Sector: mobile, edge computing, privacy
- What: Real-time instruction-based edits on-device with quantized/fused few-step editors and compressed VLMs for training-time personalization and inference-time QA.
- Tools/workflows:
- Model distillation and quantization toolchains; partial offloading/hybrid execution.
- Assumptions/dependencies:
- Memory-efficient VLMs; hardware acceleration; acceptable quality–latency trade-offs.
- Policy and standards for VLM-as-a-judge editing
- Sector: policy/regulation, industry consortia
- What: Best-practice guidelines and audits for using VLMs as differentiable judges in training loops—bias testing, safety constraints, transparency, provenance.
- Tools/workflows:
- Standardized QA prompt suites; fairness and safety benchmarks; watermark/provenance-preserving edit requirements.
- Assumptions/dependencies:
- Multi-stakeholder alignment; open benchmarks; legal frameworks for accountability.
- Enterprise-scale content governance with automated compliance checks
- Sector: finance, pharma, consumer goods, public sector
- What: Massive-scale asset governance where each edit passes automated VLM checks for policy compliance (e.g., disclaimers present, restricted items absent, region-specific norms).
- Tools/workflows:
- Policy-as-code mapped to VLM QA; exception routing; detailed audit logs tying prompts, edits, and QA decisions.
- Assumptions/dependencies:
- High-precision QA for edge cases; human-in-the-loop escalation; ongoing monitoring for drift.
- Safer deepfake-resistant editing and provenance-aware workflows
- Sector: security, journalism, social platforms
- What: Constrained editing modes that preserve provenance/watermarks and disallow harmful manipulations; VLM QA to enforce allowed scopes.
- Tools/workflows:
- Secure editing envelopes; cryptographic provenance (e.g., C2PA) integrated with editor outputs; disallowed-edit detectors.
- Assumptions/dependencies:
- Reliable watermark/provenance tooling; robust policy checkers; ecosystem adoption.
- Multilingual and accessibility-centric editing
- Sector: global education, accessibility tech
- What: Natural-language edits in many languages; voice-driven instructions mapped to the same VLM-verified editing pipeline.
- Tools/workflows:
- Multilingual VLM judges; speech-to-instruction front-ends.
- Assumptions/dependencies:
- Strong multilingual VLMs; careful prompt design to avoid cultural bias.
- Green AI and cost-efficient creative pipelines
- Sector: sustainability, cloud ops
- What: Few-step editors reduce inference/training energy compared to multi-step flows; schedule editors to low-carbon cloud regions.
- Tools/workflows:
- Carbon-aware job schedulers; model compression; step-count tuning for SLA/quality balance.
- Assumptions/dependencies:
- Accurate energy accounting; acceptance of small quality trade-offs for sustainability gains.
Cross-cutting assumptions and dependencies
- VLM reliability and bias: The approach depends on VLMs producing accurate yes/no judgments; domain-specific calibration and bias checks are essential.
- Teacher model quality for DMD: Distribution matching anchors realism to the teacher’s learned manifold; weak teachers limit ceiling performance, especially under domain shift.
- Identity preservation limits: For tasks needing pixel-level faithfulness, add perceptual/structural losses, light paired data, or human QA.
- Compute and memory: Training co-locates a VLM and the generator; plan for VRAM/throughput or use parameter-efficient VLMs.
- Licensing and IP: Ensure permissible use of base models, VLMs, and datasets; maintain provenance logs for compliance.
- Safety and misuse: Introduce constrained modes, disallowed-edit detectors, and audit trails to mitigate harmful manipulations.
Glossary
- Adversarial loss: A training objective where a generator is optimized against a discriminator to improve realism. "using adversarial loss~\citep{sauer2024adversarial,kang2024distilling,yin2024improved,sauer2024fast,xu2024ufogen}"
- Autoregressive loss: Loss used to train sequence models by maximizing the likelihood of next-token predictions. "and is trained via standard autoregressive loss to maximize the probability of predicting the correct answer:"
- Auxiliary model: A secondary trainable model used to estimate the student’s output distribution for distillation. "and a trainable auxiliary model, respectively."
- Backward diffusion trajectory: The reverse denoising path from noise toward a clean sample in diffusion sampling. "we propose to unroll the backward diffusion trajectory starting from noise"
- Binary cross-entropy: A loss function for binary classification tasks comparing predicted probabilities to binary labels. "The loss is then a binary cross-entropy over the predicted logit difference"
- CLIPScore: A text-image alignment metric based on CLIP embeddings. "We also report CLIPScore~\citep{radford2021learning}"
- Consistency models: Models that enable few-step generation by learning consistent mappings across noise levels. "including consistency models~\citep{kim2023consistency,geng2024consistency,song2023consistency,yang2024consistency,song2023improved,lu2024simplifying,heek2024multistep}"
- Cross-entropy: A general loss function measuring divergence between predicted distributions and true labels. "The final loss simplifies to a cross-entropy over the total vocabulary length."
- Direct Preference Optimization (DPO): A post-training method that optimizes models directly from preference data without RL. "using either Direct Preference Optimization (DPO)~\citep{wallace2024diffusion,yang2024using}"
- DINOv2: A self-supervised vision model used for feature similarity evaluation. "similarity in DINOv2~\citep{oquab2023dinov2} feature space after background masking"
- DiT-based: Refers to Diffusion Transformer architectures for image generation. "a 2B parameter internal DiT-based \citep{peebles2023scalable} latent space diffusion model."
- Distribution Matching Distillation (DMD): A distillation objective aligning a student’s output distribution to a teacher’s by minimizing KL divergence. "We apply Distribution Matching Distillation (DMD)~\citep{yin2024one, yin2024improved} between the fine-tuned model"
- DreamBooth: A dataset and method for customizing generative models to specific objects. "We use the widely adopted DreamBooth~\citep{ruiz2022dreambooth} dataset for evaluation."
- Flow-GRPO: An RL-based post-training technique for diffusion/flow models using group-relative preference optimization. "we also outperform RL-based techniques like Flow-GRPO."
- Flow-based models: Generative models that learn distributions via continuous-time flows or denoising processes. "Diffusion or flow-based models are a class of generating models that learn the data distribution by denoising samples corrupted by different levels of Gaussian Noise"
- Flow-matching: A training framework that matches probability flows to enable efficient generative modeling. "Standard diffusion (or flow-matching) models require many sampling steps"
- Forward diffusion process: The process of gradually adding noise to real data to produce a tractable noised distribution. "a forward diffusion process creates noisy samples"
- Gaussian noise: Random noise with a normal distribution used in diffusion training. "different levels of Gaussian Noise"
- Geometric mean: A multiplicative average used to combine metric scores. "for the Overall score, we take the geometric mean between SC and PQ"
- Kullback–Leibler (KL) divergence: A measure of difference between two probability distributions. "DMD minimizes the Kullback–Leibler (KL) divergence between the real image distribution"
- Latent space diffusion model: A diffusion model operating in a compressed latent representation rather than pixel space. "latent space diffusion model."
- LLaVa-OneVision-7B: A 7B-parameter VLM combining a vision encoder and LLM for multimodal understanding. "we use LLaVa-OneVision-7B~\citep{li2024llava} as the VLM"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique for large models. "requiring costly LoRA fine-tuning~\citep{hu2021lora}"
- LPIPS: A perceptual similarity metric measuring human-perceived image differences. "adding a perceptual similarity loss (e.g., LPIPS~\citep{zhang2018unreasonable})"
- Meanflow: A few-step generative modeling approach using mean-flow dynamics. "meanflow~\citep{geng2025meanflow}"
- MDINOv2-I: A masked DINOv2 identity similarity metric for customization tasks. "denoted as MDINOv2-I."
- ODE trajectories: Deterministic paths defined by ordinary differential equations used in distillation or sampling. "by matching ODE trajectories~\citep{song2023consistency,salimans2022progressive,geng2023one}"
- Optimization-based techniques: Methods that optimize parameters per instance or over datasets to achieve editing goals. "or flexible but slow optimization-based techniques~\citep{gal2022image,ruiz2022dreambooth,kumari2023multi}"
- Perceptual Quality (PQ): A metric evaluating realism and absence of artifacts in generated images. "Perceptual Quality (PQ) score"
- Projector module: A component that maps vision encoder outputs into the LLM embedding space. "A projector module, , projects the vision-encoded tokens into the LLM word embedding space"
- Reinforcement Learning (RL): A framework where models are trained using reward signals to optimize behavior. "using either Direct Preference Optimization (DPO)~\citep{wallace2024diffusion,yang2024using} or Reinforcement Learning (RL)~\citep{black2023training}"
- Score distillation: A technique using teacher model scores to guide student generation. "applying score distillation~\citep{luo2023diff,yin2024one,yin2024improved,zhou2024score}"
- SigLIP: A vision encoder using sigmoid loss for image-text alignment. "SigLIP~\citep {zhai2023sigmoid} vision encoder"
- Sigmoid function: A squashing function mapping real numbers to (0,1), used for probabilities. "σ is the sigmoid function"
- Supervised Fine-Tuning (SFT): Training a model on labeled/paired data to improve task performance. "requiring a Supervised Fine-Tuning (SFT) phase with paired editing data."
- Teacher model: The pre-trained reference model whose distribution guides student training. "pre-trained text-to-image (teacher) model"
- TIFA: A text-image faithfulness metric assessing semantic alignment. "and TIFA~\citep{hu2023tifa} to measure text alignment"
- Token: A discrete unit (image or text) processed by encoders/LLMs during multimodal training. "encoded into a set of tokens using the vision encoder"
- Turbo-Edit: A zero-shot few-step image-editing baseline used for comparison. "We also include Turbo-Edit~\citep{deutch2024turboedit}, a state-of-the-art zero-shot few-step method"
- VAE encoding: The latent representation produced by a Variational Autoencoder for images. "we concatenate the VAE encoding of the reference image"
- Velocity (diffusion): The vector field predicted to guide denoising toward clean samples. "represents the predicted velocity from the teacher"
- VIEScore: A VLM-based evaluation metric scoring semantic consistency and perceptual quality. "we use GPT4o-based VIEScore~\citep{ku2023viescore} metric."
- Vision LLM (VLM): A multimodal model that understands images and text jointly. "Vision LLMs (VLMs) trained from multimodal image-text data have shown exemplary visual understanding and reasoning capabilities"
- Visual instruction tuning: Aligning VLMs with instruction-following datasets for better task performance. "via visual instruction tuning~\citep{liu2023visual}"
- VRAM: GPU memory used to store model parameters and activations during training/inference. "introducing VRAM overhead."
- Zero-shot: Performing tasks without task-specific paired training data by leveraging generalization. "using zero-shot editing techniques~\citep{hertz2022prompt}"
Collections
Sign up for free to add this paper to one or more collections.