- The paper introduces Critic-LLM-RS, integrating collaborative filtering to refine LLM recommendations without additional model tuning.
- It demonstrates enhanced performance on key metrics such as hit rate, NDCG, and precision at N using real-world datasets.
- The approach leverages a separate Recommendation Critic for real-time feedback, offering a scalable and efficient alternative to fine-tuning.
Enhance LLMs as Recommendation Systems with Collaborative Filtering
The paper "Enhance LLMs as Recommendation Systems with Collaborative Filtering" presents an innovative approach to integrate the capabilities of LLMs with collaborative filtering, a prominent technique in recommendation systems. This integration addresses the existing gap in LLM-based recommendation strategies by harnessing collaborative filtering without additional tuning of the LLMs.
Introduction to Critique-Based LLMs
In the field of recommendation systems, LLMs have been predominantly adapted either through tuning or non-tuning approaches. The tuning methods involve fine-tuning models for specific tasks, whereas non-tuning strategies leverage pre-trained models to generate recommendations through carefully designed prompts. The latter approach, while cost-effective and less complex, lacks the integration of domain-specific knowledge, particularly the insights offered by collaborative filtering. This paper introduces a critique-based LLM recommendation system, referred to as Critic-LLM-RS, which integrates collaborative filtering via an auxiliary model termed the Recommendation Critic (R-Critic).
Critic-LLM-RS Architecture
The architecture of Critic-LLM-RS is designed to enhance non-tuning LLM-based strategies by integrating collaborative filtering feedback into the recommendation process. The system incorporates a pre-trained LLM and a separate machine learning model, R-Critic, which is tasked with providing critiques on the LLM-generated recommendations based on collaborative filtering principles.
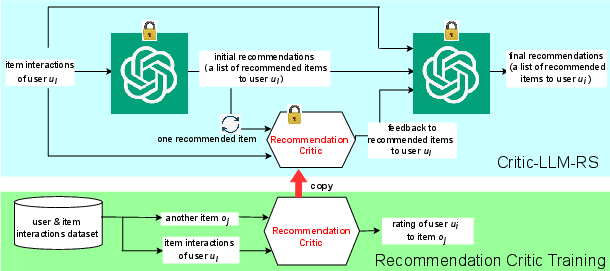
Figure 1: Critic-LLM-RS Architecture.
R-Critic is trained using user-item interaction datasets and is capable of predicting user preferences by analyzing similarities between users and their historical interactions with items. This model, once trained, can effectively critique the recommendations provided by the LLM, enabling real-time refinement of recommendations without the costly process of fine-tuning the LLM itself.
Evaluation and Results
The efficacy of Critic-LLM-RS has been validated through extensive experimentation on real-world datasets. The model demonstrates a remarkable improvement in recommendation performance across standard metrics such as hit rate (HR), Normalized Discounted Cumulative Gain (NDCG), and Precision at N, when compared to state-of-the-art LLM-based recommendation systems.
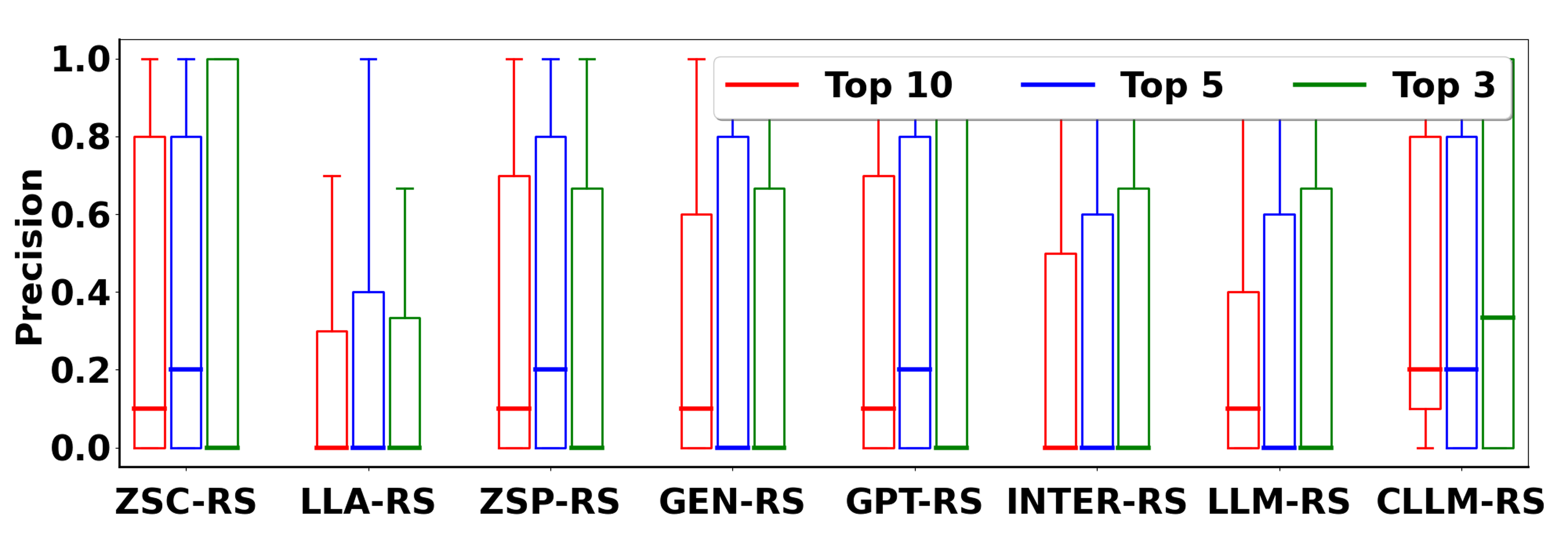
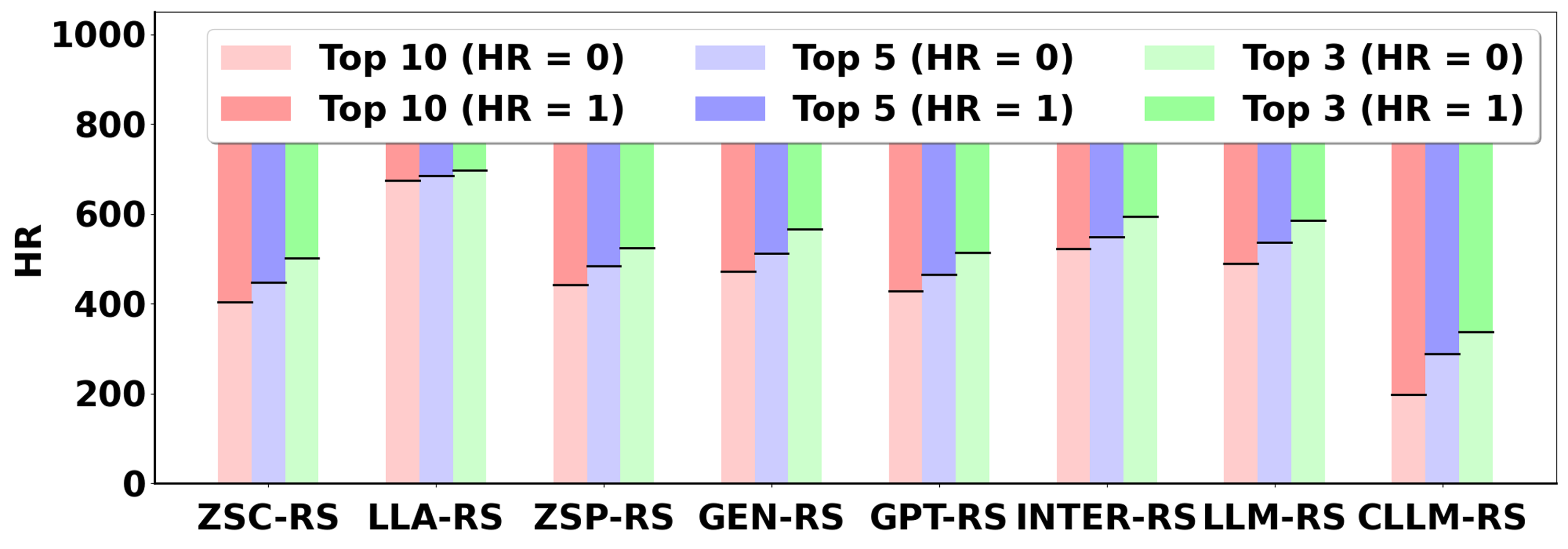
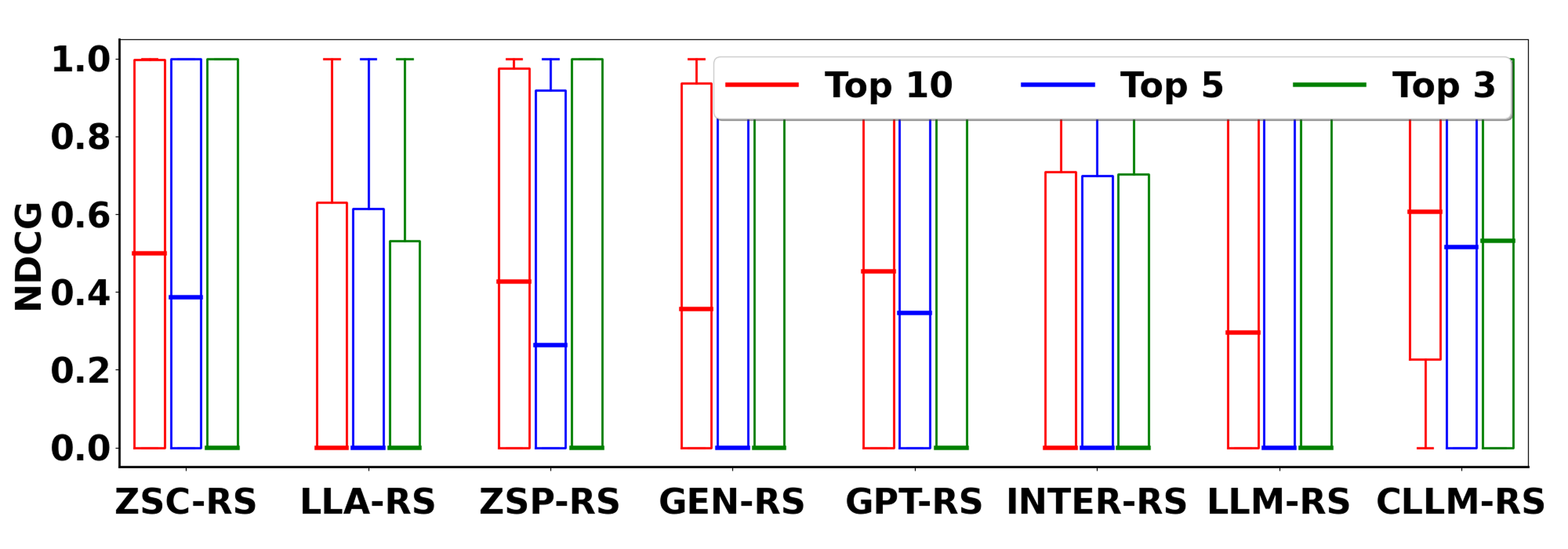
Figure 2: Evaluation on Books with Oracle.
The evaluation involves two settings—recommendation with an oracle that resembles a perfect ground truth, and recommendation using a specified candidate set. Critic-LLM-RS consistently outperformed baseline models in both settings, with significant improvement in the ranking quality and precision of the recommendations.
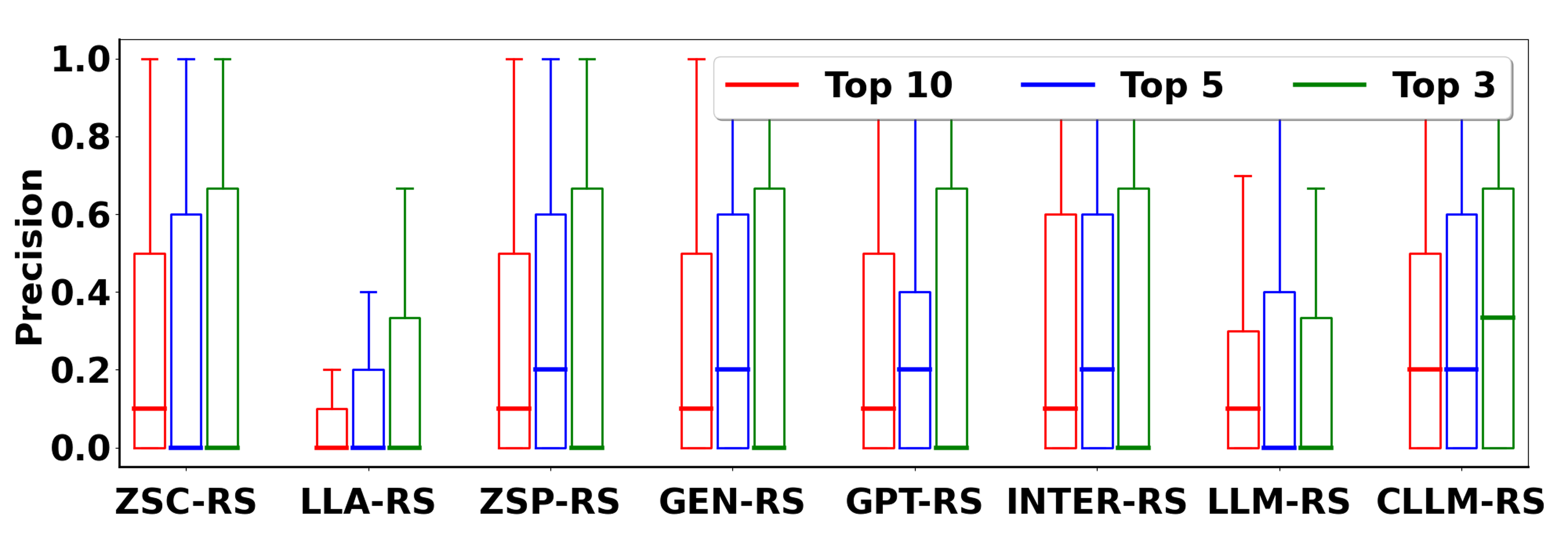
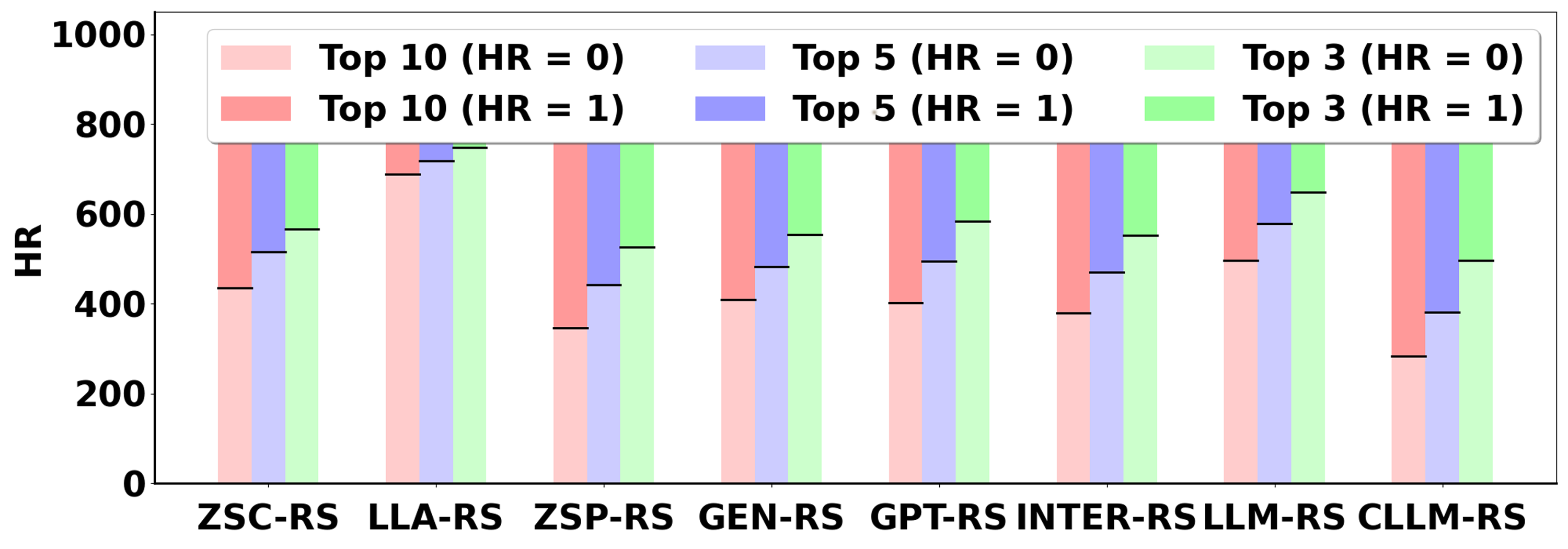
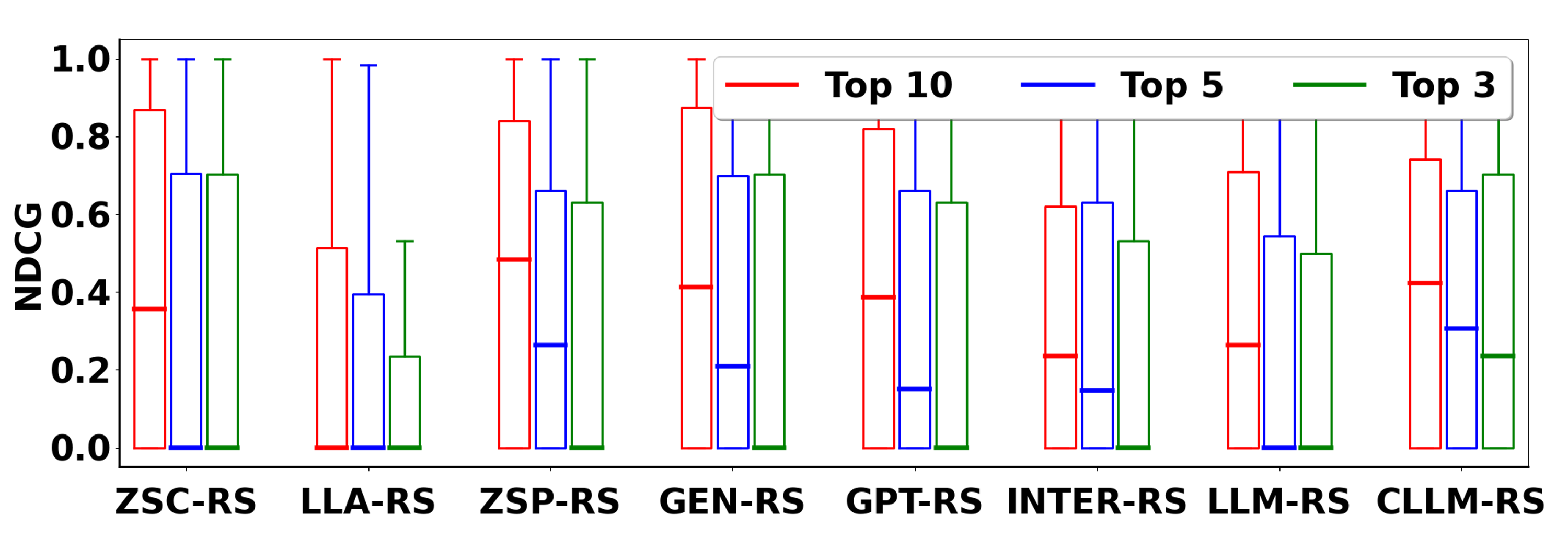
Figure 3: Evaluation on Movies with Oracle.
Comparative Analysis
The study includes a comparison with fine-tuning methods to highlight the advantages and limitations of non-tuning approaches. While fine-tuning strategies slightly improve recommendation quality, they are hindered by their computational expense and maintainability issues. Critic-LLM-RS, on the other hand, maintains high efficiency and adaptability without necessitating alterations to the base LLM architecture.
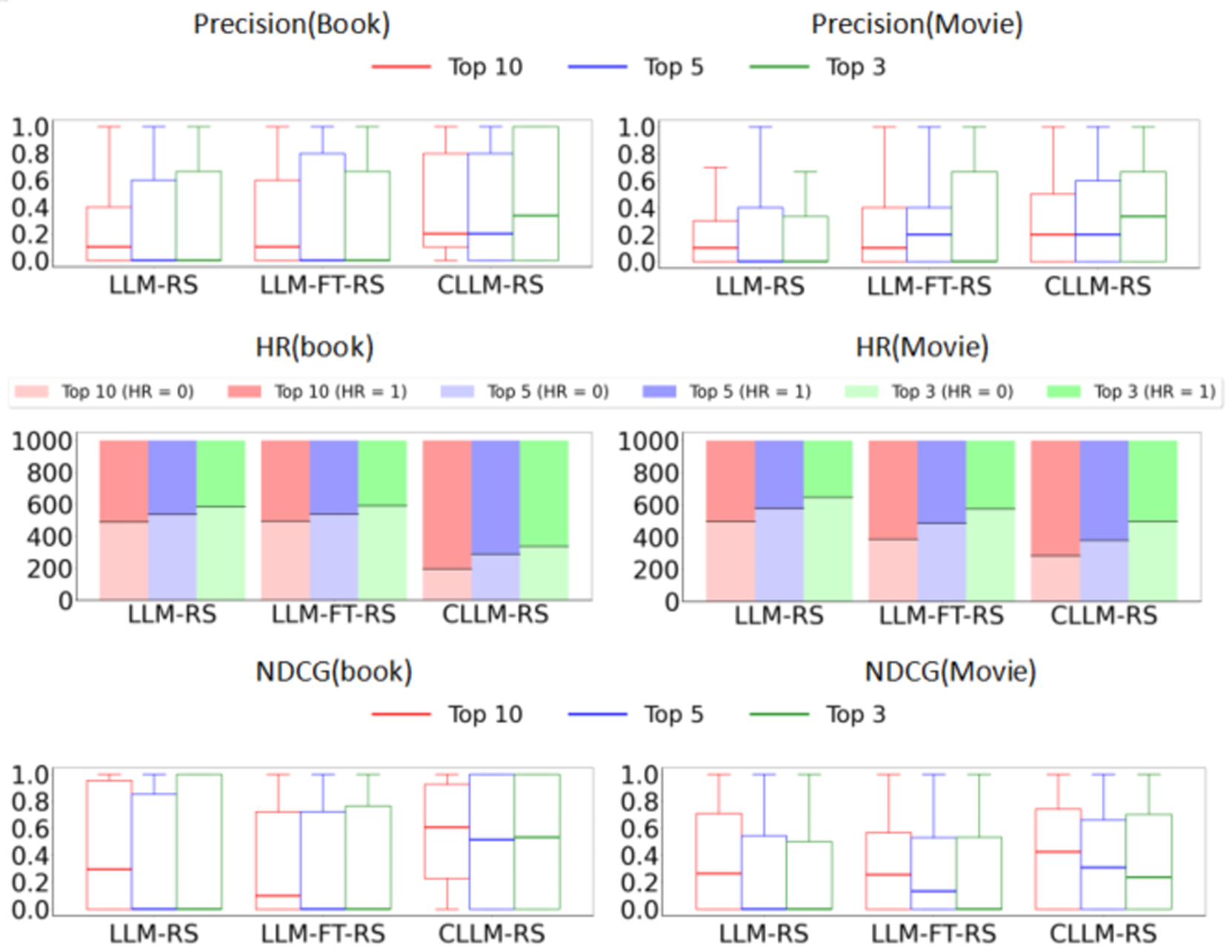
Figure 4: Critic-LLM-RS vs Fine-tuned Method.
Additionally, a comparative analysis with GPT-4o integrated with collaborative filtering feedback underscores the robust performance of Critic-LLM-RS, pointing towards its scalability to more complex and larger black-box LLMs.
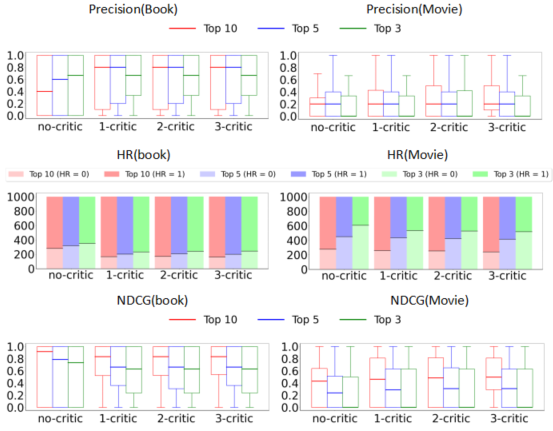
Figure 5: Critic-GPT4o-RS vs GPT4o-RS Method.
Conclusion
The introduction of Critic-LLM-RS signifies a notable advancement in LLM-based recommendation systems by incorporating collaborative filtering without the need for model tuning. This approach not only bridges the gap between domain-specific knowledge and LLM capabilities but also amplifies the relevance and precision of recommendations. Future work may explore further enhancements in critique mechanisms and their potential integration with emerging LLM architectures for broader application across varied recommendation scenarios.