- The paper introduces a GPU-accelerated SfM system that significantly improves computational speed and accuracy compared to methods like COLMAP and GLOMAP.
- It employs a non-redundant view-graph and CUDA-based feature extraction, achieving near state-of-the-art accuracy with a marked reduction in runtime.
- The system’s modular architecture supports versatile applications—from autonomous driving to crowdsourced mapping—by ensuring precise pose refinement and extrinsic calibration.
CUDA-Accelerated Structure-from-Motion: cuSfM
cuSfM introduces a GPU-accelerated, modular Structure-from-Motion (SfM) system designed for high-precision, large-scale 3D reconstruction and pose estimation. The framework leverages global optimization, non-redundant data association, and advanced feature extraction/matching, achieving significant improvements in both computational efficiency and accuracy over established baselines such as COLMAP and GLOMAP. This essay provides a technical analysis of the system architecture, algorithmic innovations, experimental results, and implications for future research and deployment.
System Architecture and Pipeline
cuSfM is architected as a modular pipeline supporting multiple operational modes: pose optimization, mapping, prior map-based localization, and extrinsic parameter refinement. The system accepts initial pose estimates, image sequences, and camera parameters, and outputs refined trajectories, sparse point clouds, and optimized extrinsics.
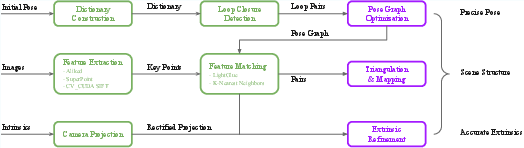
Figure 1: System architecture of cuSfM, highlighting modular data association, pose refinement, and support for multiple operational modes.
The pipeline is organized into three principal layers:
- Data Association: GPU-accelerated feature extraction and matching, loop closure detection, and non-redundant view-graph construction.
- Pose Refinement: Pose graph optimization, stereo relative pose estimation, and bundle adjustment (BA).
- Mapping and Extrinsics: Iterative triangulation, BA, and extrinsic parameter refinement for multi-camera rigs.
The architecture is extensible, supporting arbitrary camera models and undistortion operations, and is implemented with a Python wrapper (PyCuSfM) for accessibility and integration.
Non-Redundant Data Association
GPU-Accelerated Feature Extraction and Matching
cuSfM employs a modular CUDA-based feature pipeline, supporting ALIKED, SuperPoint, and SIFT (via CV_CUDA), with LightGlue as the default matcher. ALIKED+LightGlue achieves near state-of-the-art accuracy (45% AUC@5°) at a fraction of the runtime of methods like RoMa or Mast3r, with TensorRT-optimized inference reducing per-pair matching to ~20 ms.
Bag-of-Words and Loop Detection
A hierarchical, environment-specific Bag-of-Words (BoW) vocabulary is constructed using a BIRCH-based incremental clustering algorithm, enabling efficient loop closure detection and relocalization. The system maintains an inverted index for rapid candidate retrieval and employs geometric verification (fundamental matrix checks) to ensure robust loop detection.
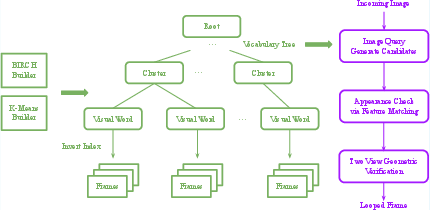
Figure 2: Vocabulary tree construction and loop detection pipeline, enabling efficient and robust place recognition.
View-Graph Construction
cuSfM departs from exhaustive or radius-based matching by constructing a minimal, non-redundant view-graph guided by pose priors. Only essential edges—sequential, loop closure, and extrinsic—are retained, reducing computational overhead and avoiding redundant correspondences.
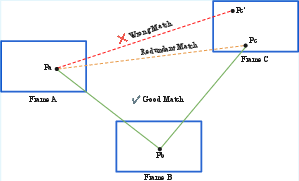
Figure 3: Redundancy in feature matching is eliminated by selecting only the minimal set of edges necessary for robust triangulation.
Pose Refinement and Mapping
Stereo Relative Pose Estimation
A novel algorithm directly estimates the translation scale between stereo pairs using only 2D observations, circumventing the need for explicit 3D triangulation or PnP. The method leverages three-view geometry and joint optimization of Sampson distances, yielding a full 6-DOF pose estimate with improved robustness to outliers.
Pose Graph Optimization
The pose graph comprises sequential, loop closure, and extrinsic constraints. Optimization is performed over either camera frames or vehicle rigs, with the latter yielding superior accuracy due to reduced parameterization and implicit rigidity.
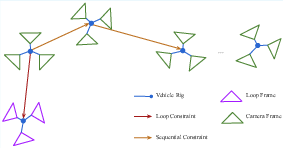
Figure 4: Pose graph structure with sequential, loop closure, and extrinsic constraints, supporting both camera and vehicle rig configurations.
Iterative Triangulation and Bundle Adjustment
cuSfM alternates between multi-view triangulation (using DLT and midpoint methods) and BA, incorporating robust loss functions and outlier rejection. The system supports both global and rolling shutter models, and allows for fixed or adjustable pose subsets, enabling incremental map updates and crowdsourced mapping.
Extrinsic Parameter Refinement
cuSfM supports joint optimization of vehicle and camera extrinsics, enforcing rigid-body constraints and incorporating prior calibration information. This is critical for multi-camera systems in autonomous vehicles and robotics, where accurate inter-camera calibration directly impacts global pose estimation.
Experimental Evaluation
Computational Efficiency
On KITTI, cuSfM achieves an order-of-magnitude reduction in mapping time compared to COLMAP (16.5s vs. 340s per 100 frames in view-graph mode), and a 6x speedup over GLOMAP, despite using more computationally intensive features. The non-redundant view-graph approach is key to this efficiency.
Accuracy
cuSfM consistently outperforms COLMAP and GLOMAP in both simulated (SDG) and real-world (KITTI) datasets. On SDG, cuSfM achieves up to 90% lower RMSE than baselines. On KITTI, trajectory refinement reduces RMSE by up to 42% over initial PyCuVSLAM trajectories, with further gains from extrinsic refinement.
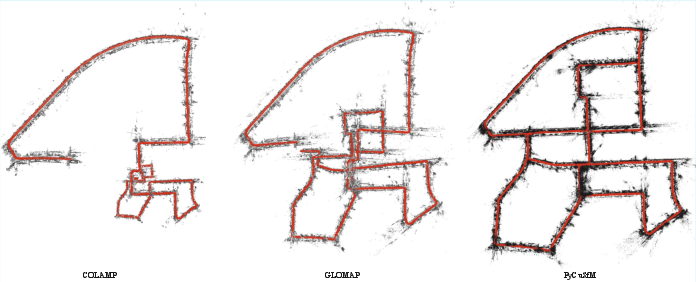
Figure 5: Trajectory comparison on KITTI 00 sequence, illustrating improved accuracy and consistency of cuSfM over COLMAP and GLOMAP.
Multi-Mode Functionality
cuSfM supports map integration, localization, and crowdsourced mapping. The system can align new trajectories to existing maps, update environmental structure, and perform single-frame localization, capabilities not present in other open-source SfM systems.

Figure 6: Map integration capabilities—new trajectory data, previous map, and integrated map with updated structure.
High-Quality 3D Reconstruction
cuSfM demonstrates the ability to reconstruct dense, high-fidelity point clouds with over 1.4 million landmarks in complex indoor environments, supporting downstream applications such as NeRF and 3DGS.
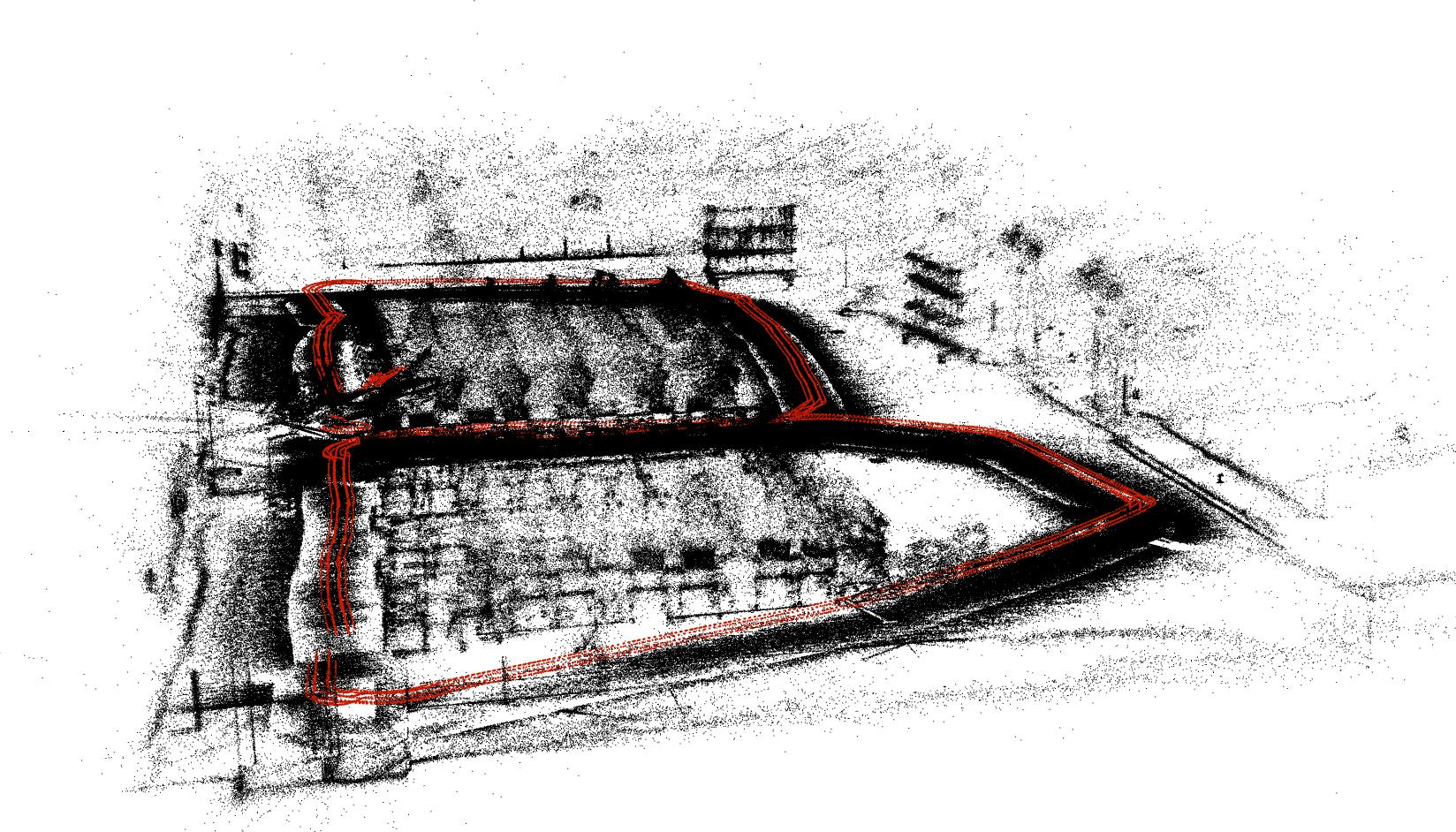
Figure 7: High-quality 3D reconstruction of an indoor meeting room with over 1.4 million 3D landmarks.
Implications and Future Directions
cuSfM establishes a new standard for offline, high-precision SfM in robotics, autonomous driving, and large-scale mapping. The system's modularity, extensibility, and open-source implementation facilitate integration with emerging feature extractors, matchers, and camera models. The non-redundant data association paradigm and direct 2D-based scale estimation represent significant algorithmic contributions, with demonstrated impact on both efficiency and accuracy.
Future research directions include:
- Extension to dynamic and large-scale urban environments with frequent appearance changes.
- Integration with neural implicit representations for dense reconstruction.
- Real-time or near-real-time adaptation for online mapping scenarios.
- Further generalization to heterogeneous sensor suites (e.g., LiDAR, event cameras).
Conclusion
cuSfM delivers a CUDA-accelerated, globally optimized SfM system with state-of-the-art efficiency and accuracy. Its innovations in non-redundant data association, GPU-accelerated feature processing, and robust pose refinement enable practical deployment in demanding real-world applications. The open-source release provides a foundation for further research and industrial adoption in computer vision and robotics.