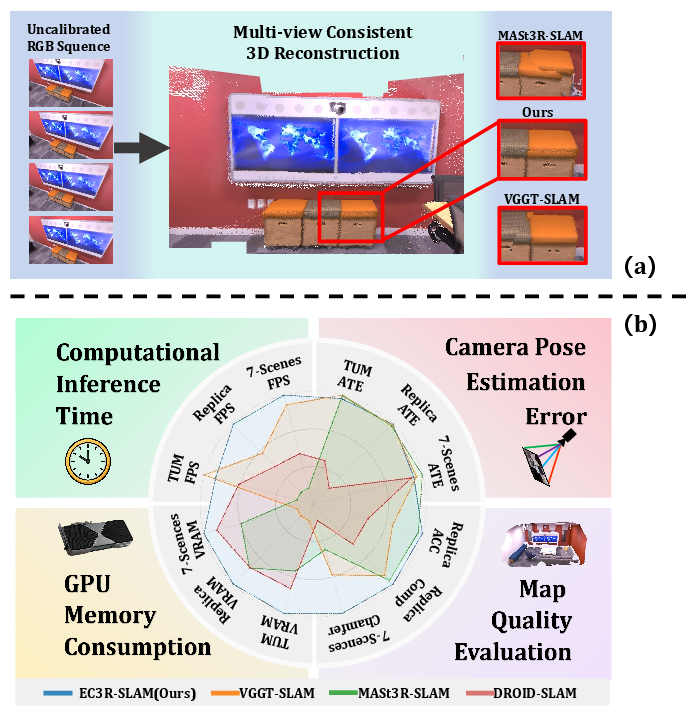
EC3R-SLAM: Efficient and Consistent Monocular Dense SLAM with Feed-Forward 3D Reconstruction
Abstract: The application of monocular dense Simultaneous Localization and Mapping (SLAM) is often hindered by high latency, large GPU memory consumption, and reliance on camera calibration. To relax this constraint, we propose EC3R-SLAM, a novel calibration-free monocular dense SLAM framework that jointly achieves high localization and mapping accuracy, low latency, and low GPU memory consumption. This enables the framework to achieve efficiency through the coupling of a tracking module, which maintains a sparse map of feature points, and a mapping module based on a feed-forward 3D reconstruction model that simultaneously estimates camera intrinsics. In addition, both local and global loop closures are incorporated to ensure mid-term and long-term data association, enforcing multi-view consistency and thereby enhancing the overall accuracy and robustness of the system. Experiments across multiple benchmarks show that EC3R-SLAM achieves competitive performance compared to state-of-the-art methods, while being faster and more memory-efficient. Moreover, it runs effectively even on resource-constrained platforms such as laptops and Jetson Orin NX, highlighting its potential for real-world robotics applications.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces EC3R-SLAM, a new way for a computer to figure out where it is and build a detailed 3D map of the world using just a single regular camera (no depth sensor). The goal is to make this fast, accurate, memory‑efficient, and easy to run on everyday devices—without needing the camera’s exact settings ahead of time (that’s called “calibration-free”).
What questions did the researchers ask?
- Can we build a detailed 3D map and track a camera’s position in real time using only one camera, while keeping the system fast and light on memory?
- Can we avoid the usual step of carefully measuring the camera’s internal settings (calibration) and still get good accuracy?
- Can we make the 3D map stay consistent over time, even when the camera revisits the same place later?
How does their method work?
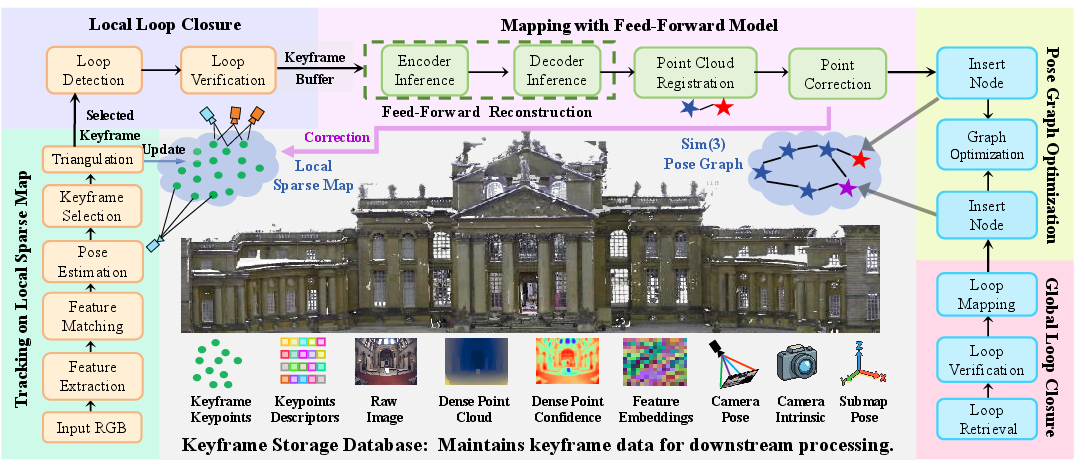
Think of exploring a house with a phone camera while making a 3D model of it. EC3R-SLAM does this in two main parts: “tracking” and “mapping,” plus a few tricks to keep everything aligned.
- Tracking (lightweight and fast)
- The system looks for small, distinctive spots in each image (like corners or patterns)—these are “features,” similar to landmarks.
- It matches those features to a small local 3D map to estimate where the camera is right now. This is like using known landmarks to figure out your location.
- If the matches become unreliable, the current image is saved as a “keyframe” (an important snapshot).
- Mapping (detailed 3D, done in short bursts)
- Instead of processing every frame (which is slow and uses lots of memory), the system waits until it has a tiny batch of keyframes (just 5) and runs a “feed‑forward” 3D model on them.
- “Feed‑forward” means the model quickly predicts depth (how far each pixel is) and even guesses the camera’s internal settings—all in one go, without heavy, time‑consuming optimization.
- This creates a small, local 3D “submap,” like a puzzle piece.
- Putting puzzle pieces together
- Each new submap is aligned to the growing global map by rotating, moving, and slightly scaling it so it fits tightly—like snapping a puzzle piece into place.
- The system then fine‑tunes all submaps together using a “pose graph”—imagine adjusting all puzzle pieces so they agree with one another everywhere.
- Keeping the map consistent with loop closures
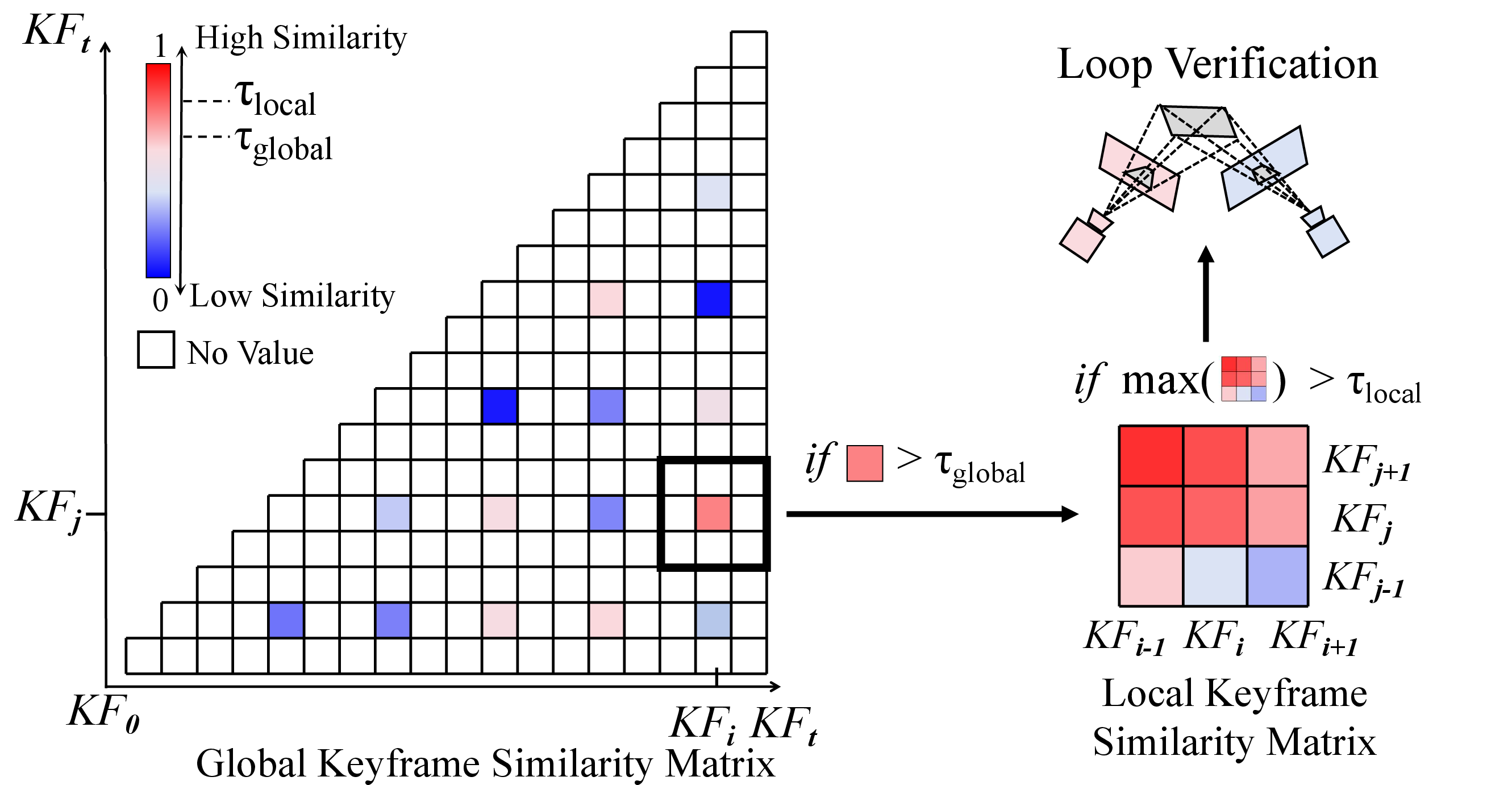
- Local loop closure: checks nearby, recent frames to see if they look the same; if yes, it tightens the map locally.
- Global loop closure: checks for places you’ve seen long ago (like recognizing you’ve returned to the kitchen) and fixes long‑term drift. Cleverly, it reuses features from the 3D model, so it doesn’t need a separate place-recognition network.
- Extra stabilization
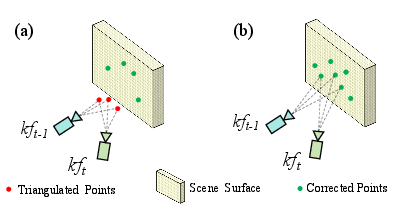
- When the mapping step finds more accurate 3D points, it “corrects” older points in the tracker to prevent drift from building up.
In everyday terms: EC3R-SLAM sprinkles “breadcrumbs” (features), keeps only the most important photos (keyframes), quickly builds small 3D chunks (submaps) with a smart model, and then snaps those chunks together while constantly checking “have I been here before?” to keep everything straight.
What did they find?
- Accuracy: It matches or beats many state‑of‑the‑art systems on popular benchmarks (TUM RGB‑D, 7‑Scenes, Replica), especially in keeping the map consistent when revisiting places.
- Speed and memory: It runs in real time (often 30–45 FPS) and uses under about 10 GB of GPU memory, which is much lower than similar methods that need 20 GB or more.
- Works without calibration: It estimates the camera’s internal settings on the fly, so you don’t need a special setup process.
- Runs on everyday hardware: It works not only on a powerful desktop but also on a laptop (8 GB VRAM) and even an NVIDIA Jetson Orin NX (a small, low‑power computer used in robots).
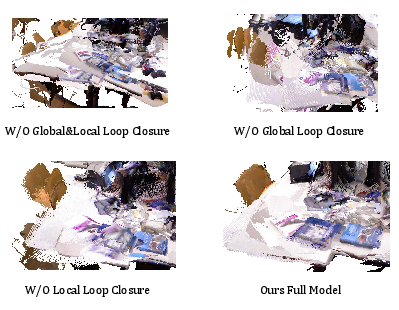
- Why the consistency is better: Using both local and global loop closures together greatly reduces drift (the slow “sliding off” of the map over time). Their ablation study shows accuracy drops a lot if you remove these loop checks.
Why does it matter?
- Easier real‑world use: Robots, drones, AR/VR headsets, and phones could build accurate 3D maps and know their location in real time without a careful camera setup step.
- Runs on cheaper hardware: Lower memory and faster speed mean it can work on small devices, not just expensive GPUs.
- More reliable maps: Combining fast feed‑forward 3D with strong loop closures creates consistent maps that don’t fall apart over time, which is crucial for navigation and interaction.
In short, EC3R-SLAM shows you can get fast, accurate, and consistent 3D mapping from a single camera—even without knowing the camera’s exact settings—while keeping the system lightweight enough for real robots and portable devices.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research:
- Memory usage claims are inconsistent across the paper (e.g., “<10 GB” in the abstract vs. 31–45 GB reported in tables); provide a rigorous per-component VRAM breakdown, standardized measurement protocol, and clarify which backbone/configuration (VGGT vs. Fast3R) achieves sub-10 GB.
- Intrinsic parameter estimation is central to the pipeline but not evaluated: quantify accuracy and stability of intrinsics predicted by VGGT/Fast3R against ground truth across different cameras, and assess impacts on tracking/mapping when intrinsics are inaccurate.
- No handling or evaluation of lens distortion, zoom, or varying focal lengths: analyze robustness to smartphone/fisheye lenses, rolling shutter, and auto-zoom/focus changes; consider modeling distortion and intrinsics drift over time.
- Global loop retrieval relies solely on feed-forward model embeddings and homography verification; provide precision/recall metrics, false-positive rates, and comparisons to NetVLAD/SALAD/DBoW baselines to validate retrieval quality and reliability.
- Homography-based loop verification may fail in high-parallax, non-planar scenes; evaluate and ablate alternative geometric checks (fundamental/essential matrix, PnP-based verification, pose-graph residual checks).
- Thresholds and hyperparameters (e.g., τ1, τ2, τp, τglobal, τlocal, N=5) are fixed and heuristic; conduct sensitivity analysis, dataset-wise tuning, and explore adaptive/learned thresholding to improve robustness across environments.
- The number of frames per submap (N=5) is chosen without analysis; investigate trade-offs between N, accuracy, consistency, runtime, and memory, including adaptive submap sizing for long trajectories or scene complexity.
- Weighted Umeyama Sim(3) registration is used without robustness analysis; detail how weights (from confidence maps) affect outlier rejection and degeneracies, and compare to RANSAC-based Sim(3) estimators under noise and mismatches.
- Information matrix Ωij in pose graph optimization is unspecified; define how measurement uncertainties are computed from confidence maps and registration residuals, and ablate their impact on convergence and final accuracy.
- No full bundle adjustment (BA) or joint optimization of intrinsics/extrinsics/dense geometry; compare pose-graph-only optimization to BA in accuracy, consistency, and runtime, especially for long sequences and large loops.
- Point correction strategy (replacing local sparse points with “accurate” global points) lacks uncertainty modeling; quantify drift reduction, failure cases when feed-forward geometry is wrong, and integrate uncertainty propagation to avoid bias.
- Scalability to very long sequences and large-scale outdoor environments is not evaluated quantitatively (only qualitative visuals on some datasets); measure database growth, PGO runtime, memory footprint, and loop-mapping overhead as scene size increases.
- Dynamic scenes, heavy motion blur, and texture-poor/repetitive environments are not analyzed; benchmark failure modes (tracking loss, false loops, mis-registrations) and propose mitigation strategies (dynamic object filtering, robust matching).
- Initialization requirements (first submap to estimate intrinsics) and reinitialization after tracking loss are not discussed; study robustness to poor initializations and define recovery mechanisms.
- Scheduling and compute overhead of global loop mapping (decoder inference for top-N candidates) isn’t characterized; quantify its latency and impact on real-time performance under frequent loops, and design gating/back-off strategies.
- The keyframe database is stored on CPU; assess data transfer bottlenecks, latency in retrieval for loop detection, and optimize I/O for real-time operation on resource-constrained devices.
- Fairness of the “uncalibrated” comparison protocol (using GeoCalib on baselines) is not examined; evaluate sensitivity of baseline performance to calibration quality and provide matched protocols (e.g., feed-forward intrinsics vs. GeoCalib) for apples-to-apples comparisons.
- Only the Fast3R variant runs on Jetson Orin NX; investigate how to make the VGGT-based pipeline fit within 8–16 GB VRAM constraints (e.g., submap tiling, mixed precision, CPU offloading) and report associated accuracy/runtime trade-offs.
- No quantitative evaluation of multi-view consistency across submaps beyond PGO metrics; introduce metrics for inter-submap alignment errors, map warping, and loop closure quality to substantiate consistency claims.
- Dense map representation is a raw point cloud; study memory growth, compression, and conversion to surfaces (meshes, implicit fields) to improve storage, rendering, and downstream utility.
- The approach is monocular-only; explore integration with IMU (VIO), multi-camera, or depth sensors to reduce drift, improve robustness, and expand applicability.
- Generalization and domain gaps are only partially addressed; evaluate on large outdoor datasets (KITTI, Oxford RobotCar), dynamic urban scenes, and diverse camera models to quantify cross-domain performance without retraining.
- Confidence usage is limited to weighting in Sim(3); investigate broader uncertainty-aware design (e.g., confidence-weighted tracking, loop verification, and PGO) for principled handling of noisy predictions.
- Code availability is promised but not yet public; emphasize reproducibility by documenting training/inference settings, exact hyperparameters, and measurement protocols to enable independent validation.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim example of usage from the text.
- 3D Gaussian Splatting (3DGS): A real-time radiance field representation using Gaussian primitives for fast rendering and mapping. "3D Gaussian Splatting(3DGS)~\cite{kerbl20233d}-based methods (MonoGS~\cite{matsuki2024gaussian}, Splat-SLAM~\cite{sandstrom2025splat}, Hi-SLAM2~\cite{zhang2024hi})."
- absolute trajectory error (ATE): A metric measuring the difference between estimated and ground-truth camera trajectories. "Accuracy is measured by RMSE-ATE (root-mean-square error of absolute trajectory error) [m]"
- bag-of-words: A place recognition approach that represents images as unordered collections of visual word occurrences. "place recognition techniques, which can be implemented using either traditional bag-of-words models~\cite{DBoW3}"
- camera extrinsics: Parameters describing a camera’s pose (rotation and translation) in the world coordinate system. "the camera parameters (intrinsics and extrinsics)."
- camera intrinsics: Parameters defining a camera’s internal geometry (e.g., focal length, principal point). "the camera parameters (intrinsics and extrinsics)."
- Chamfer Distance: A symmetric distance measure between two point sets used to evaluate reconstruction quality. "symmetric Chamfer Distance."
- confidence maps: Per-pixel estimates indicating the reliability of predicted quantities like depth. "the corresponding confidence maps that quantify the reliability of each depth estimate"
- data association: The process of linking observations across frames to maintain consistent tracks or map points. "both local and global loop closures are incorporated to ensure mid-term and long-term data association"
- DBoW3: A library for visual bag-of-words place recognition used in SLAM. "bag-of-words models~\cite{DBoW3}"
- decoder (prediction decoder): The network module that predicts outputs (e.g., depth, camera parameters) from feature embeddings. "fed into the prediction decoder "
- embeddings: Learned vector representations of images or features used for matching, retrieval, or decoding. "the image encoder produces image feature embeddings:"
- feed-forward 3D reconstruction: Reconstruction performed in a single forward pass without iterative optimization. "a mapping module based on a feed-forward 3D reconstruction model"
- Feed-Forward Inference: One-pass network inference without iterative refinement. "\subsubsection{Feed-Forward Inference}~"
- global loop closure: A long-term association mechanism that detects and enforces consistency when revisiting places. "We employ a novel approach for global loop closure."
- homography: A planar projective transformation used to verify geometric consistency between image pairs. "RANSAC homography estimation."
- image encoder: The network component that converts images into feature embeddings. "the image encoder produces image feature embeddings:"
- inlier ratio: The fraction of matched points consistent with an estimated geometric model. "from which the inlier ratio $\tau_{\text{inlier}$ is computed."
- information matrix: The inverse of the covariance used to weight residuals in graph optimization. "where denotes the information matrix associated with the measurement."
- intrinsics: See camera intrinsics; internal calibration parameters of the camera. "the camera parameters (intrinsics and extrinsics)."
- Iterative Closest Point (ICP): An algorithm to refine rigid alignment between point clouds by iteratively matching closest points. "followed by fine registration via Iterative Closest Point (ICP)~\cite{besl1992method}."
- keyframe: A selected frame that serves as a reference for mapping and optimization. "the current frame is promoted to a new keyframe."
- keyframe buffer: A temporary storage of selected keyframes awaiting batch processing in mapping. "The keyframe buffer consists of two components:"
- Levenberg--Marquardt algorithm: A nonlinear least-squares optimization method blending gradient descent and Gauss–Newton. "the optimization is carried out using the Levenberg--Marquardt algorithm implemented in PyPose~\cite{wang2023pypose}"
- Lie algebra: The vector space associated with a Lie group used for minimal pose parameterization and local updates. "mapped to a minimal representation in of the associated Lie algebra"
- Lie-group optimization: Optimization performed on manifolds defined by Lie groups to respect geometric constraints. "which enables efficient Lie-group optimization on ."
- local loop closure: A mid-term association mechanism to align nearby frames for local consistency. "we integrate a local loop closure mechanism immediately after the tracking stage"
- logarithmic mapping: The mapping from a Lie group element to its Lie algebra (tangent space). "using the logarithmic mapping function ."
- monocular dense SLAM: SLAM using a single camera to estimate dense geometry and trajectory. "The application of monocular dense Simultaneous Localization and Mapping (SLAM)"
- NeRF: Neural Radiance Fields; a neural representation of 3D scenes for view synthesis and reconstruction. "NeRF~\cite{mildenhall2021nerf}-based methods (GlORIE-SLAM~\cite{zhang2024glorie}, GO-SLAM~\cite{zhang2023go})"
- NetVLAD: A CNN-based global descriptor for place recognition using VLAD aggregation. "NetVLAD~\cite{arandjelovic2016netvlad}"
- optical flow: Pixel-wise motion estimation between consecutive frames used for keyframe selection. "selecting keyframes via optical flow"
- Perspective-n-Point (PnP): The problem of estimating camera pose from 2D–3D correspondences. "Perspective--Point (PnP) problem"
- perspective projection function: The function projecting 3D points into the image plane under a pinhole model. "where denotes the perspective projection function."
- place recognition: Identifying whether a current view corresponds to a previously seen place. "place recognition techniques"
- pose estimation: Determining the camera’s position and orientation from observations. "perform pose estimation"
- pose graph: A graph with nodes as poses (or submaps) and edges as relative constraints. "inserted into the pose graph."
- pose graph optimization: The process of jointly refining poses using the constraints in a pose graph. "performs pose graph optimization."
- projection matrices: Matrices encoding camera intrinsics and extrinsics used to map 3D to 2D. "using the projection matrices derived from ."
- RANSAC: A robust estimation technique to fit models in the presence of outliers. "we solve the problem using a RANSAC-based PnP algorithm"
- reprojection error: The pixel error between observed features and projected 3D points given a pose. "minimizes the reprojection error:"
- SALAD: A learning-based place recognition method leveraging global descriptors. "SALAD~\cite{izquierdo2024optimal}."
- similarity matrix: A matrix of pairwise similarity scores used to propose loop candidates. "We first construct a sparse similarity matrix"
- Sim(3): The similarity transformation group in 3D including rotation, translation, and uniform scaling. "We then estimate the optimal Sim(3) transformation"
- SO(3): The special orthogonal group representing 3D rotations. ""
- local sparse map: A set of sparse 3D points used by the tracker for efficient pose estimation. "Tracking in our system relies on a local sparse map"
- submap: A locally reconstructed map segment to be aligned into a global map. "generating local submaps that are subsequently fused into a global map."
- triangulation: Estimating 3D point positions from multiple 2D observations. "triangulation is performed to add new points into the local sparse map."
- Umeyama algorithm: A closed-form method for estimating similarity transforms between point sets. "Umeyamaâs closed-form Sim(3) algorithm~\cite{umeyama1991least}."
- uncalibrated reconstruction: Reconstructing geometry without known camera intrinsics. "\subsection{Uncalibrated reconstruction}"
- VGGT: A feed-forward multi-view 3D reconstruction model used for depth and camera prediction. "We adopt VGGT~\cite{wang2025vggt} to infer a local submap"
- VRAM (video random-access memory): GPU memory used to store activations, parameters, and intermediate data. "GPU memory (VRAM, video random-access memory)"
- XFeat: A learning-based feature detector/descriptor used for efficient matching. "we employ XFeat~\cite{potje2024xfeat}, an efficient learning-based feature matching network"
Practical Applications
Immediate Applications
Below are concrete, deployable applications that leverage EC3R-SLAM’s calibration-free, low-latency, low-VRAM dense monocular SLAM with multi-view-consistent loop closures. Each item lists sectors, indicative tools/workflows, and assumptions/dependencies to manage feasibility.
- Real-time indoor navigation and mapping for mobile robots
- Sectors: robotics, logistics/warehouse, hospitality, healthcare
- Tools/workflows: integrate EC3R-SLAM as a ROS2 node; run on NVIDIA Jetson Orin NX; use XFeat-based frontend and feed-forward mapping; export POIs and traversability layers to planners (Nav2)
- Assumptions/dependencies: textured static or quasi-static scenes; adequate lighting; monocular camera availability; compute ≥ Jetson Orin NX class; rolling-shutter motion kept moderate
- AR spatial anchoring and occlusion on laptops and embedded GPUs
- Sectors: AR/VR, retail, real estate, training
- Tools/workflows: run EC3R-SLAM on Windows/Linux laptops with discrete GPUs for live room mapping; stream poses and point clouds to Unity/Unreal via a plugin for persistent anchors and occlusion
- Assumptions/dependencies: consumer GPU with ~10 GB VRAM; stable framerate ≥30 FPS; moderate camera motion; static scenes during capture
- Low-cost indoor surveying and quick digital twins
- Sectors: AEC (architecture, engineering, construction), facility management
- Tools/workflows: walk with a monocular camera (webcam/GoPro) and laptop; export dense point cloud (PLY/OBJ) for meshing; align to floor plans; QA with loop closures to reduce drift
- Assumptions/dependencies: minimal moving people/equipment; consistent lighting; mesh post-processing pipeline (Poisson/TSDF) available
- UAV/UGV operations in GPS-denied indoor spaces
- Sectors: security, industrial inspection, warehousing
- Tools/workflows: deploy on UGV/UAV with Jetson; fuse EC3R-SLAM poses with IMU in an EKF; use global loop closure for long corridors/loops; produce maps for mission replanning
- Assumptions/dependencies: sufficient scene texture; latency budget supports flight control; safety constraints; propeller vibration mitigated
- Rapid construction progress capture
- Sectors: AEC, project management
- Tools/workflows: daily site walkthrough with monocular camera; generate per-day submaps; Sim(3) pose graph merges weekly; export deltas for progress tracking and clash checks
- Assumptions/dependencies: scene changes are captured as new submaps; consistent capture routes improve loop detection; dust/low light may require camera gain tuning
- Asset and product scanning for e-commerce and museums
- Sectors: e-commerce, cultural heritage, digitization
- Tools/workflows: controlled turntable or handheld capture; export point clouds to meshing and texture bake; pipeline to 3D asset platforms (glTF/USDZ)
- Assumptions/dependencies: controlled lighting; minimal specularities/transparent objects; background segmentation if needed
- Academic research baseline for uncalibrated SLAM
- Sectors: academia, R&D labs
- Tools/workflows: use open-source code as a baseline; reproduce benchmarks (TUM-RGBD, 7-Scenes, Replica); plug-in new loop detectors or feed-forward backbones (e.g., Fast3R) for ablations
- Assumptions/dependencies: access to datasets and GPU; adherence to evaluation protocols
- Bootstrapping datasets with self-calibrated trajectories
- Sectors: vision research, dataset curation
- Tools/workflows: run EC3R-SLAM on raw videos to estimate intrinsics, poses, and dense maps; export for downstream tasks (SfM comparison, learning supervisory signals)
- Assumptions/dependencies: domain similarity to training distribution; check intrinsic plausibility on first frames
- Public-sector infrastructure audits with commodity hardware
- Sectors: government, civil engineering
- Tools/workflows: equip field teams with laptops + webcams; capture corridors, small facilities; generate consistent maps for maintenance tickets and accessibility compliance
- Assumptions/dependencies: worker training for capture paths; privacy procedures for bystanders; data retention policies
- Daily-life room scanning for move-in planning and DIY
- Sectors: consumer apps, home improvement
- Tools/workflows: laptop webcam capture; export scale-adjusted point cloud/floor plan; place virtual furniture in AR tools
- Assumptions/dependencies: approximate scale alignment (e.g., known wall length or reference object); well-lit space; stable handheld motion
Long-Term Applications
These applications are promising but need further research, scaling, or engineering (e.g., robustness in challenging scenes, model compression, or broader integrations).
- Smartphone-grade, on-device dense SLAM
- Sectors: mobile AR, consumer apps
- Tools/workflows: quantize/distill VGGT-like decoder and XFeat; leverage NPUs/Neural Engines (Core ML/NNAPI); Vulkan/Metal backends
- Assumptions/dependencies: model compression to <1–2 GB memory; aggressive batching and on-device feature caching; energy constraints
- Outdoor autonomous driving with monocular cameras
- Sectors: automotive, ADAS
- Tools/workflows: integrate EC3R-SLAM as a visual odometry/mapping prior in multi-sensor stacks (LiDAR, radar, GPS/IMU); adapt loop closures to long-range, high-dynamic scenes
- Assumptions/dependencies: robust scale handling outdoors; dynamic object filtering; weather/illumination robustness; regulatory validation
- Multi-agent collaborative mapping
- Sectors: robotics, defense, public safety
- Tools/workflows: multiple agents share submap graphs; cloud service runs global pose graph optimization; conflict resolution across Sim(3) constraints
- Assumptions/dependencies: time sync, comms QoS, loop verification across agents, privacy and security of shared maps
- Semantic and task-aware dense mapping
- Sectors: warehouse automation, inspection, AR
- Tools/workflows: fuse semantic segmentation/instance detection to label maps (shelves, hazards); export navigable affordances for planners or AR occlusion with semantics
- Assumptions/dependencies: additional inference budget for semantics; training on domain-specific classes; consistent calibration-free semantics across sessions
- Lifelong, versioned digital twins with change detection
- Sectors: facility management, smart buildings
- Tools/workflows: periodic re-scans create submap deltas; detect structural changes; maintain version control and audit trails
- Assumptions/dependencies: stable alignment across months; robust loop closures under scene evolution; storage and governance for versioning
- Privacy-preserving, on-device SLAM for sensitive environments
- Sectors: healthcare, finance, government
- Tools/workflows: process-only-on-device; export minimal map/pose traces; optional homomorphic encryption for cloud optimization; PII scrubbing of RGB
- Assumptions/dependencies: compliance frameworks (HIPAA/GDPR); performance under encrypted or redacted data flows; auditability
- Robustness in adverse conditions (low light, motion blur, texture-poor)
- Sectors: security, mining, disaster response
- Tools/workflows: integrate event cameras or NIR sensors; train domain-robust features; adaptive exposure and motion-aware keyframe logic
- Assumptions/dependencies: sensor fusion engineering; retraining on edge cases; increased compute budget
- Photorealistic rendering pipelines initialized by EC3R
- Sectors: media, digital content, simulation
- Tools/workflows: use EC3R poses/point clouds to warm-start NeRF/3DGS; reduce convergence time; package as a DCC plugin
- Assumptions/dependencies: asset-quality requirements; multi-view color consistency; GPU time for final rendering
- First responder and disaster mapping from bodycams
- Sectors: public safety, emergency management
- Tools/workflows: real-time mapping on ruggedized devices; share submaps to a command center; navigate collapsed or GPS-denied structures
- Assumptions/dependencies: extreme motion/blur; smoke/dust; safety certification; resilient networking
- Precision agriculture and environmental monitoring
- Sectors: agriculture, conservation
- Tools/workflows: monocular drones mapping fields/forests; fuse altimeter/GPS for scale correction; longitudinal change analysis
- Assumptions/dependencies: texture uniformity in crops; outdoor lighting variability; scale anchoring via external sensors
- Insurance and finance: rapid 3D claims assessment
- Sectors: insurance, fintech
- Tools/workflows: adjusters capture monocular videos; generate metric-consistent maps for cost estimation; store map provenance
- Assumptions/dependencies: chain-of-custody requirements; scale verification via known dimensions; tamper-evident data logging
Notes on Key Assumptions and Dependencies
- Scene characteristics: static or slowly changing scenes with sufficient texture and lighting favor immediate deployment; highly dynamic, reflective, or texture-poor scenes require additional modeling or sensors.
- Compute/memory: immediate deployments assume ≥8–10 GB VRAM GPUs or Jetson Orin NX; smartphone-class deployments require model compression and NPU offload.
- Scale and accuracy: monocular systems need scale anchoring (known dimensions, barometer/GPS/IMU fusion) when metric accuracy is critical.
- Robustness: rolling-shutter and motion blur are manageable with cautious motion and keyframe logic; adverse conditions may need sensor fusion (IMU/event/NIR).
- Compliance: applications in regulated domains (healthcare, public safety) require privacy, security, and auditability provisions.
- Integration: ROS2, Unity/Unreal, BIM/IFC, and cloud PGO pipelines are typical integration endpoints for productization.
Collections
Sign up for free to add this paper to one or more collections.