- The paper introduces a unified framework that combines feed-forward 3D models with SLAM for efficient monocular 3D reconstruction.
- It employs a hierarchical Gaussian scene representation with LoD control to optimize rendering fidelity and computational efficiency.
- Experimental evaluations demonstrate superior pose accuracy and reconstruction quality across diverse indoor and outdoor benchmarks.
ARTDECO: Efficient and High-Fidelity On-the-Fly 3D Reconstruction with Structured Scene Representation
ARTDECO introduces a unified framework for real-time, high-fidelity 3D reconstruction from monocular image sequences, integrating feed-forward 3D foundation models with SLAM-based optimization and a hierarchical Gaussian scene representation. The system is designed to address the trade-offs between accuracy, robustness, and efficiency that have historically limited the practicality of monocular 3D reconstruction for applications in AR/VR, robotics, and real-to-sim content creation.

Figure 1: ARTDECO delivers high-fidelity, interactive 3D reconstruction from monocular images, combining efficiency with robustness across indoor and outdoor scenes.
System Architecture
ARTDECO's pipeline consists of three tightly integrated modules: frontend, backend, and mapping. The frontend leverages feed-forward models (MASt3R for matching and π3 for loop closure) to estimate relative poses and categorize frames into keyframes, mapper frames, or common frames. The backend refines keyframe poses via loop closure detection and global bundle adjustment, ensuring multi-view consistency and drift reduction. The mapping module incrementally reconstructs the scene using a hierarchical semi-implicit Gaussian representation, with level-of-detail (LoD) control for scalable rendering.
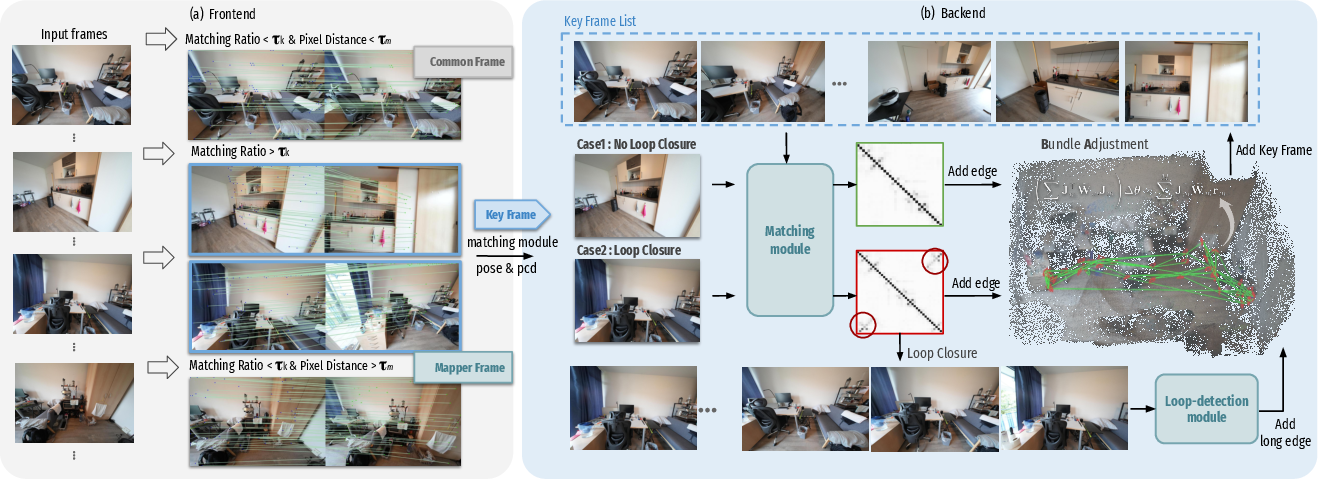
Figure 2: Frontend and backend modules. The frontend aligns incoming frames and classifies them; the backend performs loop detection and global pose optimization.
Hierarchical Gaussian Scene Representation
ARTDECO employs a hierarchical Gaussian representation, where each primitive encodes position, spherical harmonics, scale, opacity, and local features. The mapping module uses multi-resolution Laplacian of Gaussian (LoG) analysis to identify regions requiring refinement, inserting new Gaussians only where necessary. LoD-aware rendering is achieved by assigning each Gaussian a distance-dependent parameter dmax, enabling efficient, scale-consistent rendering and suppressing flickering artifacts.
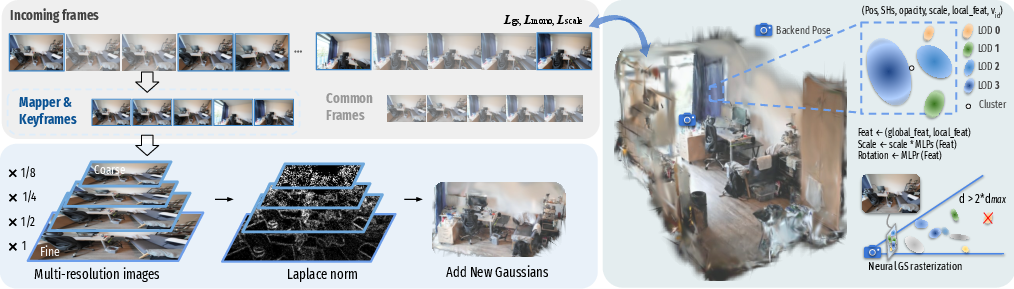
Figure 3: Mapping process. Keyframes and mapper frames add new Gaussians; LoG analysis guides refinement; common frames contribute via gradient-based updates.
Integration of Feed-Forward Models and SLAM
ARTDECO's key innovation is the modular integration of feed-forward 3D foundation models for pose estimation, loop closure, and dense point prediction. MASt3R provides robust two-view correspondences and metric pointmaps, while π3 enhances loop closure detection with multi-frame geometric priors. Pose estimation is performed via weighted Gauss–Newton optimization, with joint refinement of focal length when intrinsics are unknown. The backend's factor graph connects keyframes based on ASMK similarity and geometric consistency, followed by global bundle adjustment in the Sim(3) group.
Training and Optimization Strategy
The system operates in a streaming fashion, initializing new Gaussians and optimizing the scene for K iterations upon arrival of keyframes or mapper frames. Common frames trigger only K/2 iterations, focusing on refinement. Training frames are sampled with a 0.2 probability from the current frame and 0.8 from past frames to mitigate local overfitting. After streaming, a global optimization is performed, with higher sampling probabilities for less-updated frames. Camera poses and Gaussian parameters are jointly optimized, propagating gradients to both positions and rotations.
Experimental Results
ARTDECO is evaluated on eight diverse indoor and outdoor benchmarks, including TUM, ScanNet, ScanNet++, VR-NeRF, KITTI, Waymo, Fast-LIVO2, and MatrixCity. Reconstruction quality is measured by PSNR, SSIM, and LPIPS; pose accuracy by ATE RMSE; and efficiency by FPS. ARTDECO consistently achieves state-of-the-art results, outperforming both SLAM-based and feed-forward baselines in rendering fidelity, localization accuracy, and runtime.

Figure 4: Qualitative comparisons against popular on-the-fly reconstruction baselines. ARTDECO preserves high-quality rendering details in complex environments.

Figure 5: More Qualitative Reconstruction Results.
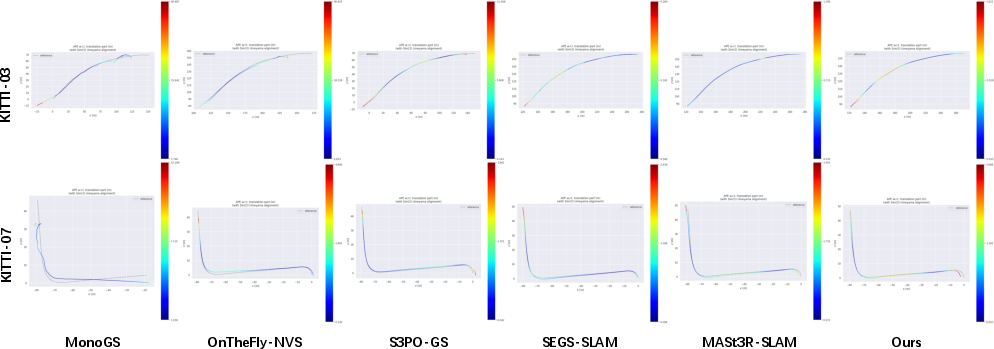
Figure 6: Qualitative Comparison of Trajectories across Different Methods on the KITTI Dataset.
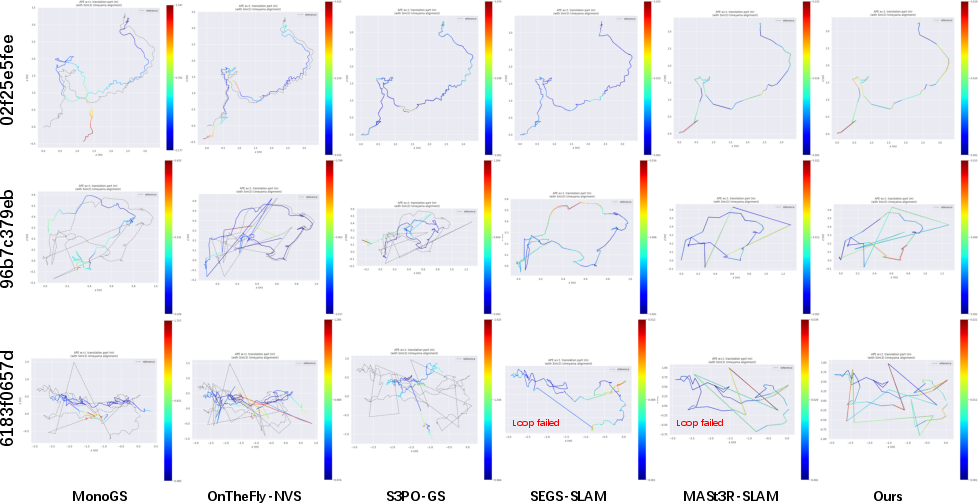
Figure 7: Qualitative Comparison of Trajectories across Different Methods on the ScanNet++ Dataset.
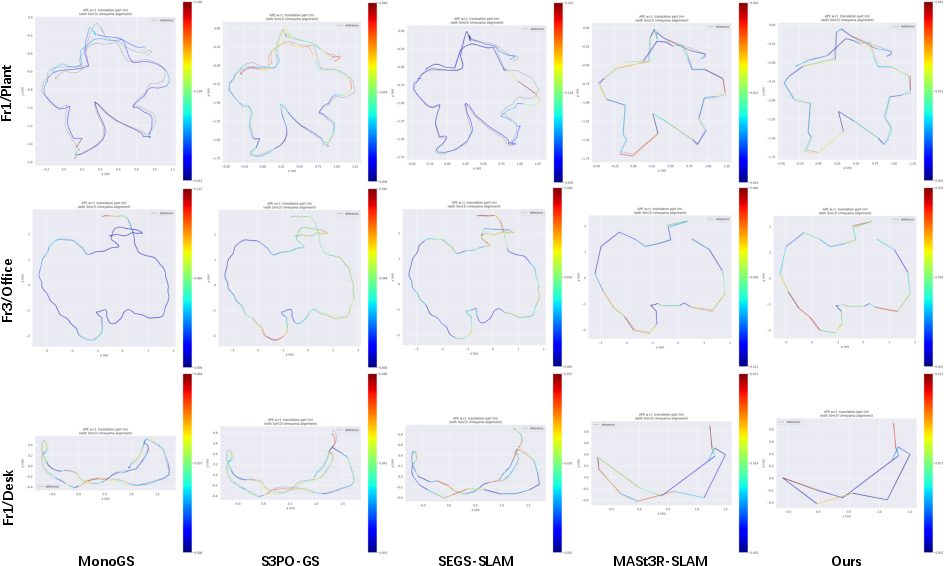
Figure 8: Qualitative Comparison of Trajectories across Different Methods on the TUM Dataset.
Numerical results highlight ARTDECO's superiority:
- On ScanNet++, ARTDECO achieves PSNR 29.12, SSIM 0.918, LPIPS 0.167, and ATE RMSE 0.018, outperforming all baselines.
- On KITTI, ARTDECO achieves PSNR 23.17, SSIM 0.765, LPIPS 0.299, and ATE RMSE 1.36, with robust tracking and rendering.
- Runtime is competitive, with ARTDECO running faster than all but OnTheFly-NVS, justified by its higher pose accuracy.
Ablation studies confirm the importance of hierarchical LoD, structural Gaussians, and the hybrid frontend/backend design. Disabling loop closure or using dense keyframes degrades localization, while omitting LoD or mapper frames reduces reconstruction fidelity.
Limitations and Future Directions
ARTDECO's reliance on feed-forward 3D foundation models introduces sensitivity to noise, blur, and out-of-distribution inputs. The system assumes consistent illumination and sufficient parallax; violations can cause drift or artifacts. Future work should focus on uncertainty estimation, adaptive model selection, and stronger priors to enhance generalization and reliability in unconstrained real-world scenarios.
Conclusion
ARTDECO demonstrates that combining feed-forward priors with structured Gaussian representations and SLAM-based optimization enables efficient, robust, and high-fidelity on-the-fly 3D reconstruction from monocular image sequences. The framework achieves near per-scene optimization quality with SLAM-level efficiency and feed-forward robustness, providing a practical solution for large-scale real-to-sim pipelines. ARTDECO's modular design and hierarchical scene representation offer a promising foundation for future research in scalable, interactive 3D digitization for AR/VR, robotics, and digital twins.