- The paper introduces a unified latent representation (UniLat) that combines geometry and appearance in a single-stage 3D generation pipeline.
- It utilizes a flow-matching Transformer and a Uni-VAE architecture to achieve high-quality asset synthesis with reduced geometry-texture misalignment.
- UniLat3D demonstrates competitive performance against state-of-the-art methods, offering efficient generation and extensibility for multimodal applications.
UniLat3D: Geometry-Appearance Unified Latents for Single-Stage 3D Generation
Introduction and Motivation
UniLat3D introduces a unified latent representation for high-fidelity 3D asset generation, addressing the limitations of conventional two-stage 3D generative pipelines that separately synthesize geometry and appearance. Prior diffusion-based frameworks, such as TRELLIS, typically decouple geometry and texture synthesis, resulting in geometry–texture misalignment and increased computational cost. UniLat3D proposes a single-stage approach, encoding both geometry and appearance into a compact latent space (UniLat), which is directly denoised from noise via a flow-matching model. This design streamlines the generation process, improves alignment between geometry and appearance, and enhances efficiency and extensibility.

Figure 1: Gallery of UniLat3D. The method generates high-quality 3D assets in seconds.
Unified Latent Representation and Architecture
UniLat Variational Autoencoder (Uni-VAE)
The core of UniLat3D is the Uni-VAE, which compresses high-resolution sparse features into a dense, low-resolution latent tensor zuni∈RM×M×M×d, where d is the channel dimension and M is the spatial resolution after compression. The encoding pipeline consists of:
- Sparse Visual Feature Extraction: Multi-view features are projected onto activated surface voxels.
- Sparse Appearance Encoding: Features are aggregated and encoded using a sparse Transformer.
- Sparse Feature Densification: Sparse latents are converted to dense tensors, filling empty space with zeros.
- Densified Feature Compression: Dense features are downsampled via 3D convolutions to form UniLat.
The decoder upsamples UniLat to high-resolution dense features, followed by sparsification and decoding into either 3D Gaussian splats or meshes. The mesh decoder employs hierarchical octree-style upsampling and sparse convolutions, supporting resolutions up to 5123.
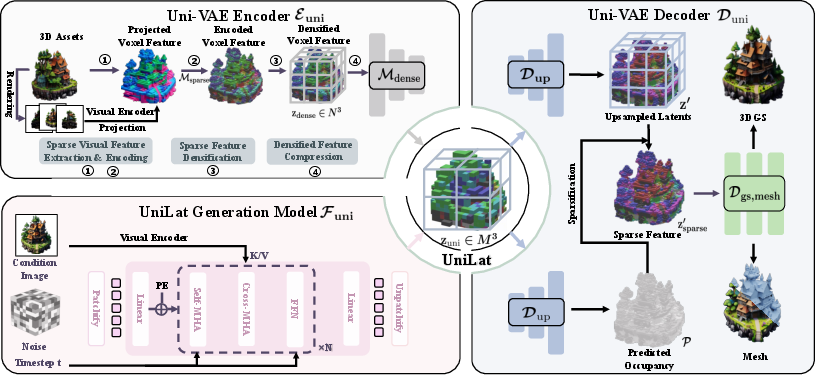
Figure 2: Illustration of the UniLat3D framework. The encoder compresses 3D assets into UniLat, which is denoised by a single flow model and decoded into target 3D representations.
Single-Stage Flow-Matching Generation
UniLat3D employs a single flow-matching Transformer to map Gaussian noise directly to the unified latent space, conditioned on an input image. This eliminates the need for separate geometry and appearance generation stages. The flow model is trained using rectified flow matching loss, with classifier-free guidance and DINOv3 as the image encoder.
Implementation Details
- Training: Both Uni-VAE and flow models are trained on 64 GPUs for two weeks, using Adam optimizer and FlashAttention-3 for efficient Transformer training.
- Datasets: Training utilizes 450k assets from Objaverse (XL), ABO, 3D-FUTURE, and HSSD, with multi-scale voxelization for occupancy supervision.
- Evaluation: Performance is assessed on Toys4K and a self-collected complex set, using PSNR, SSIM, LPIPS for reconstruction, CLIP score and FDDINOv2 for appearance, and ULIP/Uni3D for geometry.
Experimental Results
Qualitative and Quantitative Comparisons
UniLat3D demonstrates superior appearance fidelity and geometric quality compared to state-of-the-art two-stage models (TRELLIS, Hunyuan3D-2.1, Step1X-3D, TripoSR), achieving better correspondence with input images and competitive mesh quality. Notably, UniLat3D is trained solely on public data, yet matches or exceeds commercial models in both appearance and geometry.

Figure 3: Qualitative comparisons with other methods. UniLat3D achieves superior performance and better correspondence with input images.

Figure 4: Additional qualitative comparisons with other methods.

Figure 5: Qualitative comparisons with commercial models. UniLat3D shows competitive performance even with only publicly available training data.

Figure 6: 3D mesh assets generated by UniLat3D.
Efficiency
- 3D Gaussian Generation: 8 seconds on a single A100 GPU, reduced to 3 seconds with FlashAttention-3.
- Mesh Generation: 36 seconds, attributed to higher resolution and post-processing.
Ablation Studies
- Latent Resolution: Higher UniLat resolutions yield improved reconstruction metrics; UniLat3D matches or surpasses TRELLIS at lower resolutions, indicating efficient feature fusion.
- Condition Encoder: DINOv3 outperforms DINOv2 for complex object generation, improving FDDINOv2.
User Study
A user study with 19 participants over 23 prompts shows UniLat3D is preferred for both image alignment and object quality, receiving over 35% of votes, outperforming other leading models.
Theoretical and Practical Implications
UniLat3D’s unified latent space offers several advantages:
- Alignment: Direct fusion of geometry and appearance mitigates misalignment issues inherent in two-stage pipelines.
- Efficiency: Single-stage generation reduces inference time and computational overhead.
- Extensibility: The compact latent prior can be integrated into large multimodal models, facilitating cross-modal understanding and generation.
- Scalability: The architecture supports high-resolution outputs and can be extended to 4D representations and scene-level generation.
Limitations and Future Directions
- Data Quality: Current training is limited to public datasets; incorporating higher-quality or proprietary data could further enhance performance.
- Flow Model Scalability: Training flow models at higher latent resolutions increases computational cost; future work may explore block-wise computation and lightweight attention mechanisms.
- Generalization: Extending UniLat to 4D, part-level, and scene-level representations, and integrating with multimodal models, remains an open research direction.
Conclusion
UniLat3D presents a unified, single-stage framework for 3D asset generation, encoding geometry and appearance into a compact latent space and directly denoising from noise via a flow-matching model. The approach achieves state-of-the-art appearance and geometry quality, competitive efficiency, and strong extensibility, setting a new paradigm for scalable and versatile 3D generation. Future work should focus on scaling data quality, optimizing flow models for higher resolutions, and extending the unified latent representation to broader generative tasks.