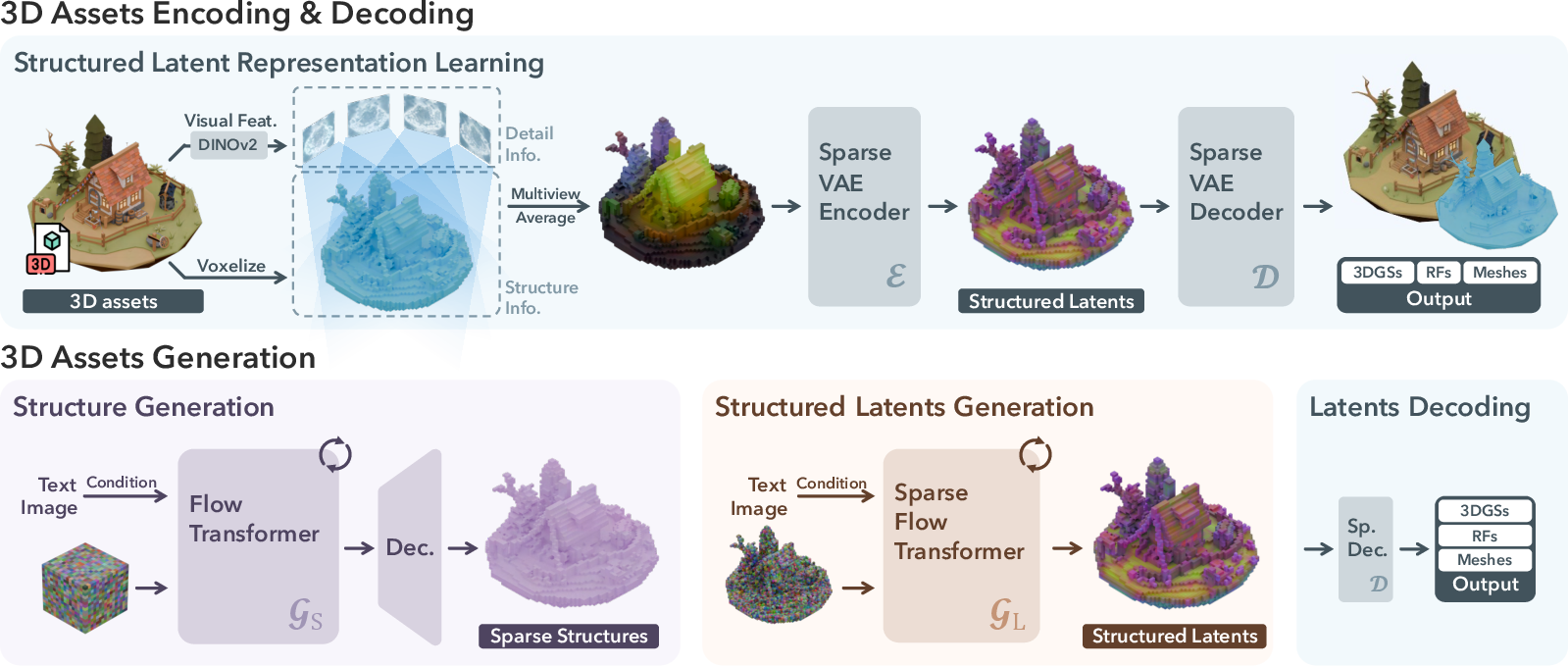
- The paper introduces a novel Structured Latent (SLat) representation that encodes both geometry and appearance for scalable, high-fidelity 3D asset generation.
- It combines sparse 3D grids with dense multiview visual features using a sparse VAE in a two-stage pipeline to support various 3D formats.
- Experimental results demonstrate superior reconstruction fidelity and versatile editing capabilities, with significant implications for AR/VR and digital media.
Structured 3D Latents for Scalable and Versatile 3D Generation
The paper "Structured 3D Latents for Scalable and Versatile 3D Generation" presents a novel 3D generation method that can create versatile and high-quality 3D assets in multiple formats such as Radiance Fields, 3D Gaussians, and meshes. The key innovation is the introduction of a Structured LATent (SLat) representation which combines sparse 3D grids with dense multiview visual features to represent both geometry and appearance. This document outlines the paper's methodology, experimental results, and practical applications for implementing its concepts.
Methodology Overview
The proposed methodology revolves around the SLat representation, which is designed to enable scalable and diverse 3D generation. The approach can be divided into the following major components:
- Structured Latent Representation:
- Visual Feature Aggregation:
- Features are extracted from multiview images using a pre-trained DINOv2 encoder and are aggregated to derive the structured latent representation.
- Sparse VAE and Decoding:
- A sparse VAE is used to encode the visual features into structured latents.
- The decoding process supports various output formats by mapping the latents to 3D Gaussians, Radiance Fields, or meshes.
- Two-Stage Generation Pipeline:
- The framework employs a two-stage generation pipeline. The first stage generates the sparse structure, and the second stage generates the local latents.
- Rectified flow transformers are used for efficient generation, leveraging the sparsity of the representation.
Experimental Results
The authors conducted extensive experiments to demonstrate the effectiveness of their method:
- Reconstruction Fidelity:
- SLat achieved superior reconstruction fidelity across various 3D formats compared to existing methods. It excels in both appearance and geometric accuracy.
- Generation Results:
- Quantitative and Qualitative Comparisons:
- The proposed method outperformed previous works in various metrics such as Fréchet Distance and CLIP score, affirming its superior quality and alignment with input prompts.
- User Study:
- A user study highlighted a strong preference for the assets generated by the proposed method, further validating its high-quality output.
Practical Applications
The SLat representation and the accompanying generation pipeline offer several practical applications:
- Versatile 3D Asset Generation:
- The method supports the generation of multiple 3D formats and is capable of producing high-fidelity 3D models from text or image inputs.
- 3D Editing and Composition:
- The locality and structure of the representation facilitate flexible 3D editing, such as detail variation and region-specific modifications without retraining.
- Scalable Multi-modal Applications:
- The framework is adaptable to various output formats, making it suitable for diverse applications in gaming, AR/VR content creation, and digital media.
Conclusion
The structured latent representation (SLat) for scalable and versatile 3D generation presents a significant advancement in the field of 3D asset creation. By integrating sparse 3D grids with dense visual features, the proposed method offers high-quality 3D assets in various formats and supports flexible editing capabilities. The results show promise for diverse real-world applications, enabling scalable and efficient 3D content generation. The availability of code and models on their project page facilitates further exploration and adoption within the community.