- The paper introduces an adaptive, semantic-aware test-time search strategy that dynamically adjusts candidate sampling and reward functions.
- It significantly improves video quality and semantic alignment under imaginative, long-distance prompts, outperforming baseline methods by approximately 8.83%.
- The study establishes LDT-Bench and ImageryQA for rigorous benchmarking, laying a foundation for future research in multimodal generative models.
Adaptive Test-Time Search for Imaginative Video Generation: The ImagerySearch Framework
Motivation and Problem Setting
Text-to-video (T2V) generative models have achieved high fidelity in realistic scenarios, but their performance degrades sharply when tasked with imaginative prompts involving rarely co-occurring concepts and long-distance semantic dependencies. This limitation is rooted in both the semantic dependency constraints of current models and the scarcity of imaginative training data. Existing test-time scaling (TTS) methods, such as Best-of-N, particle sampling, and beam search, use static search spaces and reward functions, which restrict their adaptability to open-ended, creative scenarios.

Figure 1: Illustration of semantic dependency scenarios; models struggle with long-distance semantics, but ImagerySearch generates coherent, context-aware motions.
ImagerySearch: Semantic-Distance-Aware Test-Time Search
ImagerySearch introduces a prompt-guided, adaptive test-time search strategy for video generation, comprising two principal components:
- Semantic-distance-aware Dynamic Search Space (SaDSS): The search space is modulated according to the semantic span of the prompt. Semantic distance is computed as the average embedding distance between key entities (objects and actions) in the prompt, using a text encoder (e.g., T5 or CLIP). The number of candidates sampled at each denoising step is dynamically adjusted:
Nt=Nbase⋅(1+λ⋅Dˉsem(p))
where Nbase is the base sample count and λ is a scaling factor.
- Adaptive Imagery Reward (AIR): The reward function incorporates semantic distance as a soft re-weighting factor, incentivizing outputs that better align with the intended semantics. The reward for each candidate video is:
RAIR(x^0)=(α⋅MQ+β⋅TA+γ⋅VQ+ω⋅Rany)⋅Dˉsem(x^0)
where MQ, TA, VQ are VideoAlign metrics, and Rany is an extensible reward (e.g., VideoScore, VMBench).
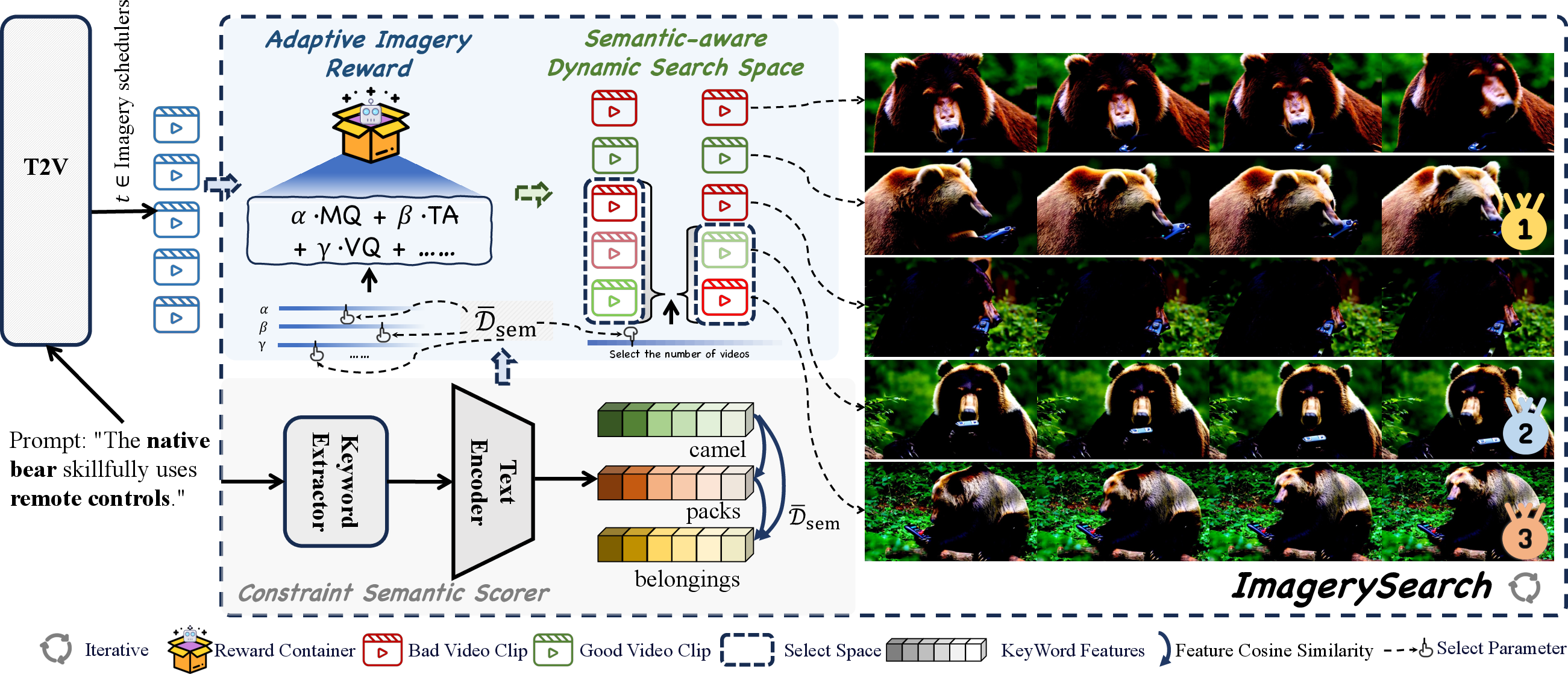
Figure 2: Overview of ImagerySearch; prompts are scored for semantic distance, guiding both candidate sampling and reward evaluation at key denoising steps.
The search is triggered at a limited set of denoising steps (the "Imagery Schedule"), focusing computational resources on pivotal stages where semantic correspondence is most efficiently captured.
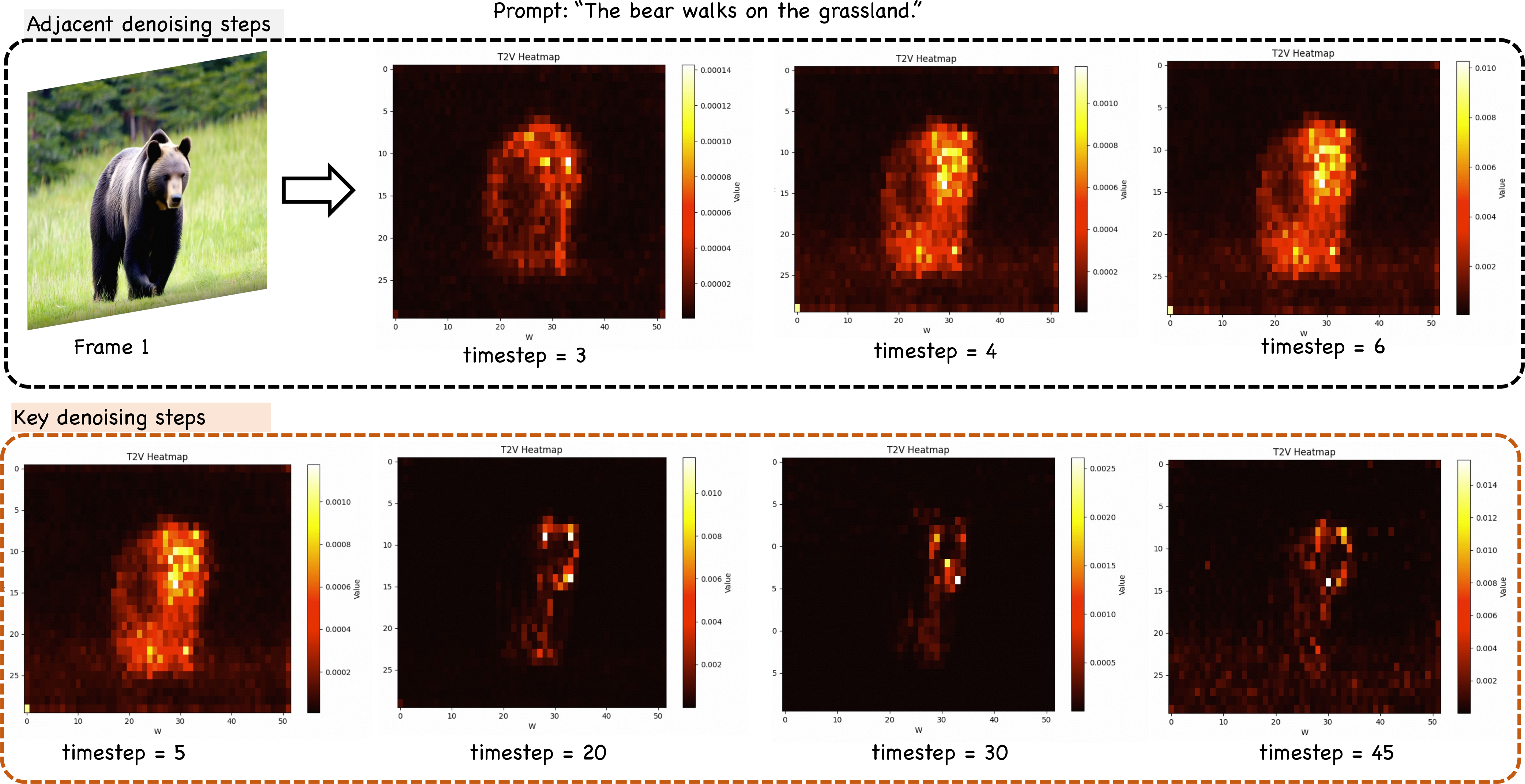
Figure 3: Visualization of attention at successive denoising steps; only key steps exhibit pronounced changes, justifying the Imagery Schedule.
LDT-Bench: Benchmarking Long-Distance Semantic Prompts
To rigorously evaluate generative models under imaginative scenarios, the paper introduces LDT-Bench, a benchmark specifically designed for long-distance semantic prompts. LDT-Bench comprises 2,839 prompts constructed by maximizing semantic distance across object–action and action–action pairs, derived from large-scale recognition datasets (ImageNet-1K, COCO, ActivityNet, UCF101, Kinetics-600).
Prompt generation leverages GPT-4o for fluency, with subsequent filtering by DeepSeek and human annotators. The benchmark includes an automated evaluation protocol, ImageryQA, which quantifies creative generation via:
- ElementQA: Targeted questions about object and action presence.
- AlignQA: Assessment of visual quality and aesthetics.
- AnomalyQA: Detection of visual anomalies.
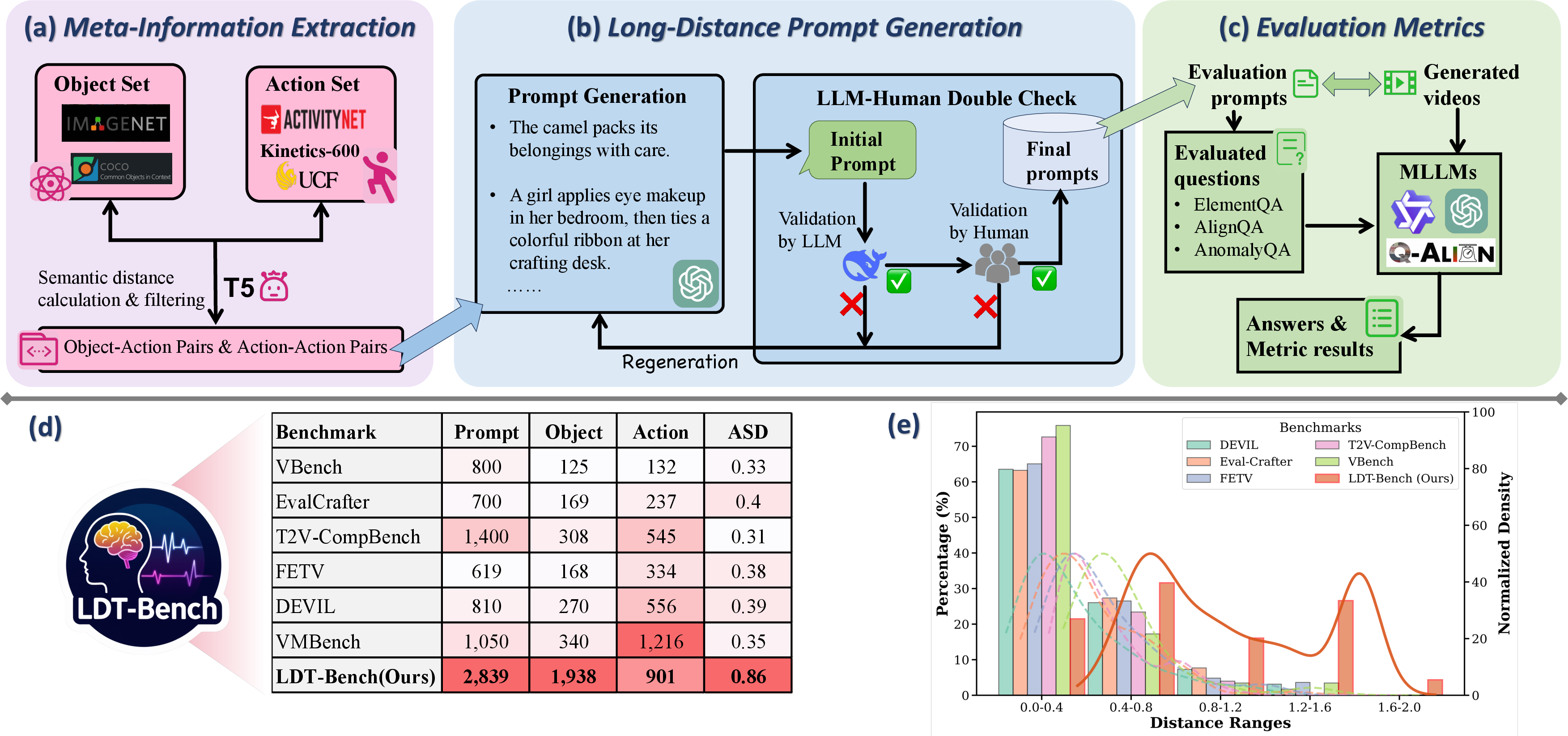
Figure 4: Construction and analysis of LDT-Bench; prompts cover a wide variety of categories and exhibit a semantic-distance distribution shifted toward longer ranges.

Figure 5: Analysis of LDT-Bench prompt suite; distributions and word clouds highlight the diversity and semantic span of prompts.
Experimental Results and Analysis
ImagerySearch is evaluated on both LDT-Bench and VBench, using Wan2.1 as the backbone. It consistently outperforms general models (Wan2.1, Hunyuan, CogVideoX, Open-Sora) and TTS baselines (Video-T1, EvoSearch) in terms of imaging quality and semantic alignment, especially under long-distance semantic prompts.

Figure 6: Qualitative comparison; ImagerySearch produces more vivid actions under long-distance semantic prompts than other methods.

Figure 7: (a) ImagerySearch maintains stable performance as semantic distance increases; (b-e) AIR delivers superior scaling behavior as inference-time computation increases.
ImagerySearch achieves an 8.83% improvement over the baseline on LDT-Bench and the highest average score on VBench, with pronounced gains in dynamic degree and subject consistency. Robustness analysis shows that ImagerySearch maintains nearly constant scores as semantic distance increases, while other methods exhibit greater variance and degradation.
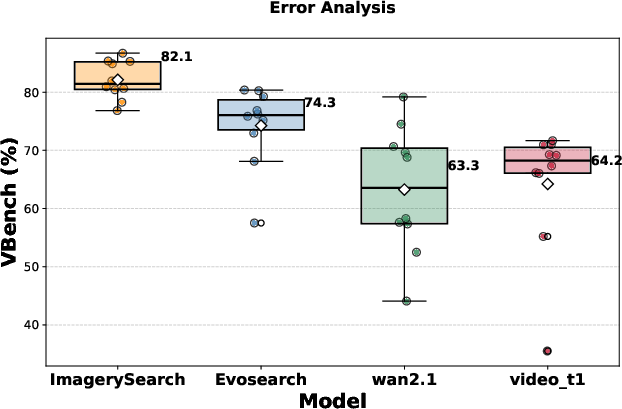
Figure 8: Error analysis; ImagerySearch attains the highest mean with the tightest spread on VBench scores for long-distance semantic prompts.
Ablation and Module Analysis
Ablation studies confirm the complementary benefits of SaDSS and AIR. Dynamic search space adjustment yields higher scores than static configurations, and the ImagerySearch search strategy outperforms alternatives such as Best-of-N and particle sampling. Reward-weight analysis demonstrates that dynamic adjustment achieves optimal performance across varying weights.

Figure 9: Reward-weight analysis; MQ and VQ trends are stable, while TA varies, supporting dynamic adjustment for imaginative scenarios.
Qualitative Examples
Additional examples on LDT-Bench and VBench further illustrate ImagerySearch's capacity to generate coherent, contextually accurate videos for imaginative, long-distance prompts.

Figure 10: More examples on LDT-Bench; frame sampling demonstrates vivid and coherent video generation.

Figure 11: More examples on VBench (Part I); ImagerySearch maintains quality across diverse prompts.

Figure 12: More examples on VBench (Part II); consistent performance on complex action–action scenarios.
Implications and Future Directions
The adaptive test-time search paradigm introduced by ImagerySearch demonstrates that semantic-distance-aware modulation of both search space and reward functions is critical for advancing video generation beyond the constraints of training data. The strong numerical results on LDT-Bench and VBench indicate that dynamic adaptation at inference can substantially improve model robustness and creativity, even without additional training.
The release of LDT-Bench provides a standardized testbed for evaluating imaginative video generation, enabling more rigorous benchmarking and facilitating future research on open-ended generative tasks. The modularity of the semantic scorer and reward function allows for integration with alternative encoders and metrics, supporting extensibility.
Future work may explore more flexible and context-sensitive reward mechanisms, integration with reinforcement learning-based fine-tuning, and scaling to longer video sequences and more complex compositional prompts. The approach also suggests broader applicability to other generative modalities (e.g., text-to-image, multimodal synthesis) where semantic distance and compositionality are key challenges.
Conclusion
ImagerySearch establishes a robust framework for adaptive test-time search in video generation, effectively addressing the limitations of semantic dependency and data scarcity in imaginative scenarios. By dynamically adjusting the inference search space and reward function according to prompt semantics, ImagerySearch achieves state-of-the-art results on both LDT-Bench and VBench, with especially strong gains for long-distance semantic prompts. The methodology and benchmark set a new standard for evaluating and improving creative generative models, with significant implications for future research in open-ended video synthesis and multimodal generation.