- The paper introduces SpeechLLM-as-Judges, a dual-stage LLM using Chain-of-Thought reasoning and GRPO for structured speech quality assessments.
- It leverages SpeechEval, a multilingual dataset with 32,207 speech clips and 128,754 annotations to ensure robust, interpretable evaluations across tasks.
- Experimental results show high alignment with human judgments and superior deepfake detection, marking a significant improvement over traditional tests.
SpeechLLM-as-Judges: Towards General and Interpretable Speech Quality Evaluation
Introduction
The paper "SpeechLLM-as-Judges: Towards General and Interpretable Speech Quality Evaluation" (2510.14664) addresses the ongoing challenge of evaluating synthetic speech quality, an increasingly pertinent issue with the rapid advancements in generative speech technologies. Traditional methods, such as MOS and AB preference tests, often fail to provide interpretative insights, limiting their utility for targeted improvements. The proposed SpeechLLM-as-Judges paradigm leverages LLMs to facilitate structured, explanation-based evaluations across diverse tasks and languages, enhancing both interpretability and generalization.
Methodology
To achieve this, the authors introduce SpeechEval, a comprehensive multilingual dataset comprising 32,207 speech clips and 128,754 annotations, which underpins the paradigm. SpeechEval covers several tasks: quality assessment, pairwise comparison, improvement suggestions, and deepfake detection. It is notable for its multilingual representation, including languages such as English, Chinese, Japanese, and French, which addresses the prevalent issue of language-constrained datasets.
The core of their approach is the SQ-LLM, a model fine-tuned in two stages: first, using instruction tuning with Chain-of-Thought (CoT) reasoning, and second, employing reward optimization via Generalized Policy Gradient Optimization (GRPO). This dual-stage training is designed to enhance the model's reasoning capabilities and alignment with human evaluative preferences.
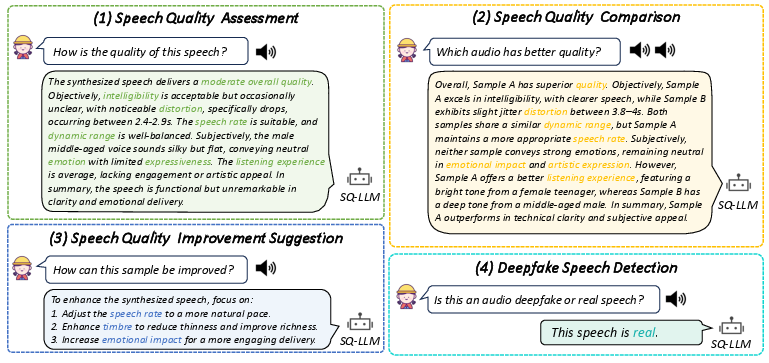
Figure 1: Example interactions showcasing the core capabilities of SpeechLLM-as-Judges. The model supports: speech quality assessment, comparison, improvement suggestion, and deepfake detection.
Dataset Construction and Annotation
The dataset, SpeechEval, is meticulously constructed through a multi-stage process involving diverse speech sources, including public corpora and synthetic speech from open-source generators and commercial TTS engines. The annotation protocol captures speech quality across three major aspects—production quality, content enjoyment, and overall quality—further subdivided into eight subdimensions.
The annotation workflow incorporates a human-in-the-loop system assisted by LLM-generated descriptions, which annotators refine. This iterative process ensures high-quality, linguistically diverse annotations, vital for training robust models capable of generalizing well across tasks and languages.
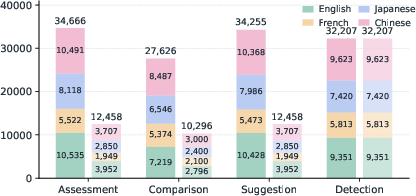
Figure 2: Per-task statistics across four languages, highlighting both the number of audio items (light color) and annotations (solid color).
SQ-LLM Model and Training
The SQ-LLM architecture integrates a speech encoder with a speech-aware language decoder utilizing Qwen2.5-Omni. By framing all tasks within an instruction-based framework, SQ-LLM can perform various quality evaluation tasks using natural language prompts and structured outputs.
The inclusion of CoT reasoning facilitates dimension-wise prediction generation, providing a layer of detailed reasoning which guides the final evaluative decisions. The GRPO stage further refines this process by aligning outputs with human evaluative metrics using reward functions that assess helpfulness, relevance, accuracy, and level of detail.
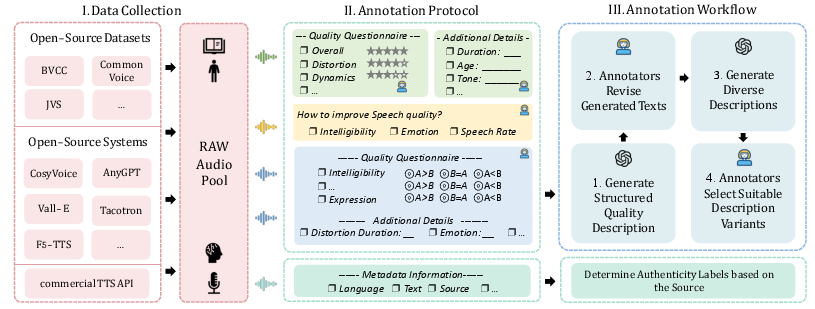
Figure 3: Overview of the SpeechEval data construction process, including data collection (left), task-specific annotation protocols (middle), and a human-in-the-loop annotation workflow with LLM assistance (right).
Experimental Results
The paper reports that SQ-LLM consistently outperforms baseline models across all evaluation tasks. Specifically, it shows high accuracy in both speech quality assessments and deepfake detection, with significant improvements in interpretability due to the structured reasoning process.
Quantitative metrics such as Pearson correlation coefficients and BLEU scores demonstrate the model's heightened alignment with human judgments, particularly in nuanced tasks like speech quality comparison and improvement suggestions. Moreover, the diverse multilingual dataset enables robust performance across languages, a critical step forward in developing generalized speech evaluation systems.
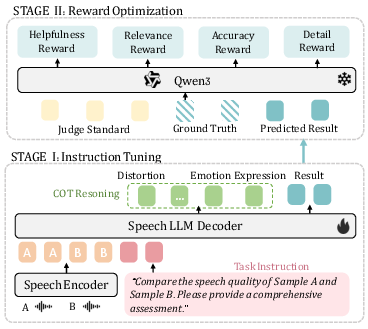
Figure 4: Overview of SQ-LLM training. Stage I uses instruction tuning with dimension-wise CoT reasoning. Stage II applies multi-aspect feedback for refinement.
Conclusion and Implications
The research presented in SpeechLLM-as-Judges expands the boundaries of speech quality evaluation by combining LLM capabilities with structured evaluative tasks, yielding a model that is not only accurate but also interpretable and generalizable. This work suggests a promising trajectory for future developments in TTS evaluation frameworks, emphasizing the need for models that can seamlessly operate across linguistic and contextual boundaries.
This approach's applicability extends beyond mere assessment, holding potential for integration into speech synthesis feedback loops and real-time quality control in conversational AI systems. Future research could explore further scaling of SpeechEval to include additional languages and nuanced aspects of speech, such as emotional expressiveness, continuing to push the envelope in automated speech quality evaluation.