- The paper introduces neural speech assessment models that act as differentiable loss functions, aligning training with human perceptual quality.
- The paper details the MetricGAN paradigm and its enhancements, which use perceptual gradients to robustly optimize speech enhancement models.
- The paper illustrates how these models drive intelligent downstream decisions, improving model selection and beamforming accuracy under diverse conditions.
Neural Speech Assessment: From Evaluation to Optimization in Downstream Speech Processing
Introduction
The paper "From Evaluation to Optimization: Neural Speech Assessment for Downstream Applications" (2509.01889) provides a comprehensive review and synthesis of the evolution and integration of neural speech assessment models within modern speech processing pipelines. The work addresses the longstanding disconnect between traditional objective metrics and human auditory perception, highlighting the limitations of both intrusive, reference-based measures and subjective listening tests. The central thesis is that neural speech assessment models, trained to align with human judgments or established metrics, are not only effective for evaluation but also serve as differentiable, perceptually aligned proxies that can directly guide the optimization of speech generation and enhancement systems. The paper further explores the use of these models as decision engines for downstream tasks, such as model selection and beamforming, and discusses the implications, challenges, and future directions for the field.
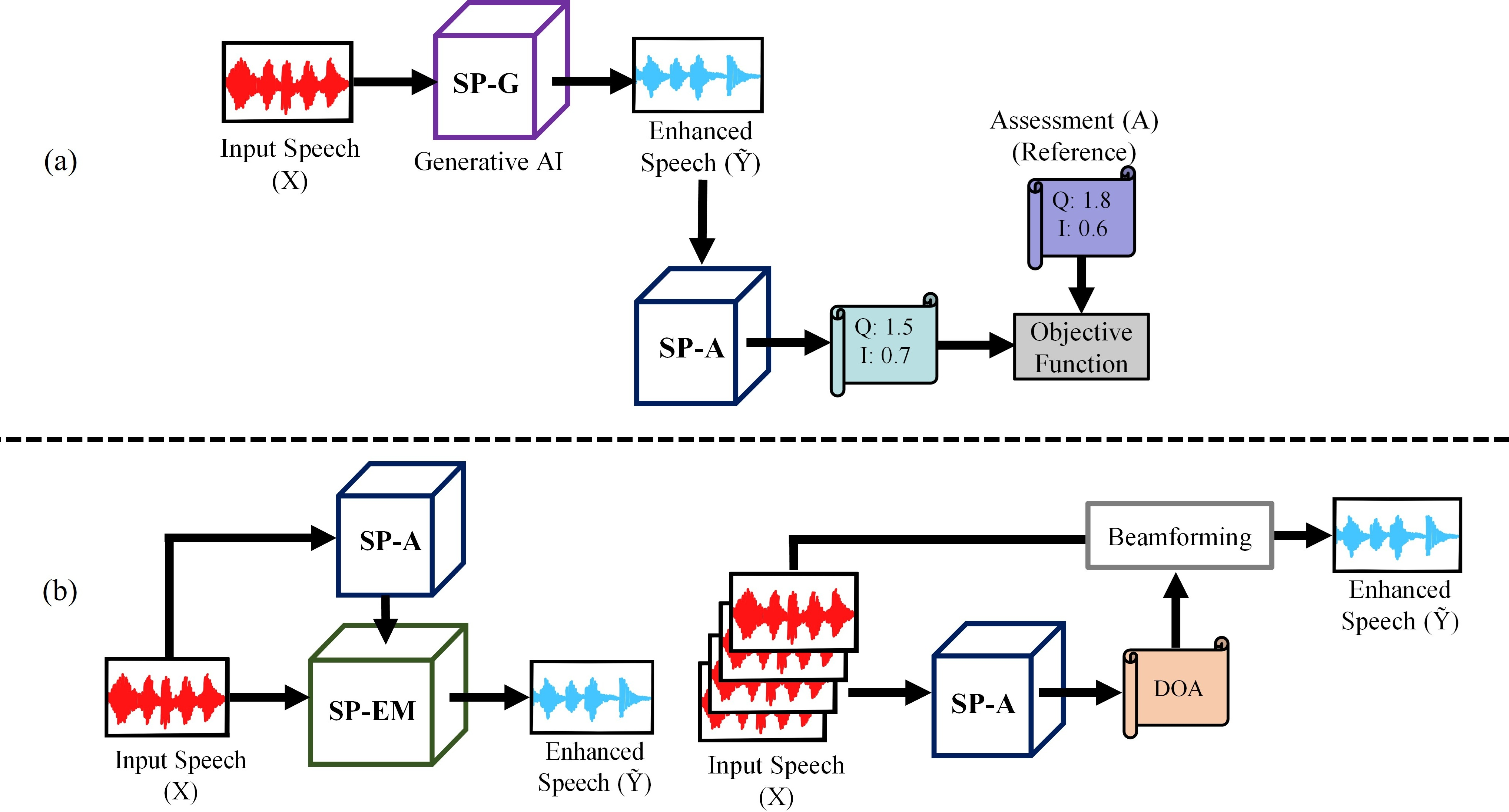
Figure 1: Neural speech assessment supports two major downstream applications: (1) serving as a differentiable perceptual proxy to guide the optimization of speech generation models, and (2) enabling the detection of key speech characteristics for more precise and efficient downstream processing.
Differentiable Perceptual Proxies: Surrogates for Human and Metric-Based Evaluation
Traditional loss functions such as MSE and MAE, while computationally efficient and differentiable, exhibit poor correlation with human perception, often resulting in over-smoothed and unnatural speech outputs. Intrusive objective metrics like PESQ and POLQA offer improved perceptual alignment but are non-differentiable and require clean reference signals, limiting their utility in real-world, reference-free scenarios.
Neural speech assessment models address these limitations by learning to approximate complex, non-differentiable metrics or subjective human ratings in a fully differentiable manner. Early models such as Quality-Net (BLSTM-based) and STOI-Net were trained to predict PESQ and STOI scores, respectively, using only the degraded signal as input. This non-intrusive design is critical for deployment in practical, real-time systems.
The field has since advanced to models trained directly on large-scale human-rated datasets, such as DNSMOS and MaskQSS, enabling the capture of perceptual subtleties and domain-specific characteristics (e.g., speech distorted by face masks). These models serve as surrogates for human judgment, providing gradients that can be used to optimize speech generation models for subjective quality.
Integration into Optimization: The MetricGAN Paradigm
The integration of neural speech assessment models as active loss functions in model training is exemplified by the MetricGAN framework. Here, a GAN architecture is repurposed such that the discriminator is a neural speech assessor trained to predict a target metric (e.g., PESQ), while the generator is the speech enhancement model. The discriminator provides a differentiable, contextually adaptive loss signal, enabling the generator to optimize directly for perceptual quality.
MetricGAN+ introduces several enhancements, including training the discriminator on noisy, clean, and enhanced speech for stronger anchoring, experience replay to prevent forgetting, and per-frequency sigmoid activations for flexible noise suppression. These engineering improvements yield significant gains in both stability and perceptual quality.
The unsupervised extension, MetricGAN-U, leverages non-intrusive assessors (e.g., DNSMOS) to enable training on unpaired, real-world noisy data, removing the dependency on parallel corpora and facilitating robust, scalable model development.
Direct Human Preference Optimization
A notable development is the direct optimization of models for subjective human preference. The HL-StarGAN system for face-masked speech enhancement demonstrates a two-stage process: first, a neural assessor (MaskQSS) is trained on human-rated, mask-distorted speech; second, the enhancement model is optimized to maximize the assessor's predicted MOS. This human-in-the-loop approach enables the creation of systems that are explicitly tuned to the target user experience, rather than proxy metrics.
Neural Assessment as a Decision Engine
Beyond optimization, neural speech assessment models are increasingly used as decision engines in downstream processing. In ensemble-based speech enhancement, models such as Quality-Net are used to select the optimal output from a set of specialized models, each trained for different conditions (e.g., SNR, speaker gender). The ZMOS framework extends this to zero-shot model selection, leveraging latent quality embeddings for clustering and efficient inference.
In beamforming, the IANS framework employs STOI-Net to predict intelligibility scores for candidate DOA angles, selecting the angle that maximizes intelligibility. This approach yields performance comparable to systems with oracle DOA information and demonstrates strong cross-lingual robustness, highlighting the potential for neural assessors to drive adaptive, perception-aware signal processing.
Implications, Limitations, and Future Directions
The integration of neural speech assessment models as differentiable, perceptually aligned proxies represents a significant methodological advance, enabling direct optimization for human-perceived quality and facilitating new capabilities such as unsupervised learning and adaptive model selection. Empirical results consistently demonstrate substantial improvements in both objective and subjective metrics over traditional approaches.
However, several challenges remain. Generalization and calibration are persistent issues, particularly when assessors are deployed on unseen data or novel systems. Multi-metric optimization—jointly accounting for clarity, naturalness, and intelligibility—remains an open problem, with potential solutions including multi-objective training and the use of multiple discriminators. Interpretability and diagnostic capabilities are also critical for practical deployment, as is the need for personalization to adapt to individual listener preferences and hearing profiles.
Conclusion
Neural speech assessment models have fundamentally reshaped the landscape of speech processing, bridging the gap between computational evaluation and human perception. By serving as both evaluators and differentiable loss functions, these models enable direct, perception-driven optimization and intelligent downstream decision-making. Ongoing research into generalization, multi-metric assessment, interpretability, and personalization will be essential for realizing the full potential of these methods in next-generation audio technologies.

