- The paper introduces a comprehensive architectural framework that unifies trustworthy, responsible, and safe AI to manage risk throughout the AI lifecycle.
- It employs robust adversarial evaluation and multi-layered methodologies, integrating technical safeguards with ethical and governance measures.
- The framework’s implications include enhanced risk mitigation, improved resilience against adversarial attacks, and practical guidelines for dynamic AI safety protocols.
Trustworthy, Responsible, and Safe AI: A Comprehensive Architectural Framework
Overview and Problem Context
This work provides a comprehensive architectural framework for AI safety structured around three core pillars: Trustworthy AI (technical and operational reliability), Responsible AI (ethical, organizational, and societal alignment), and Safe AI (systemic and ecosystemic resilience). The paper positions these pillars as necessary to address the increasing complexity, interdependence, and real-world impact of modern AI systems, particularly as deployments increasingly leverage open-source or third-party foundation models whose individual failures can propagate throughout the ecosystem. By integrating technical, ethical, and governance lenses, the paper addresses risk management across the model lifecycle—from data preprocessing and training strategies to deployment, alignment, ongoing evaluation, and multi-stakeholder oversight.
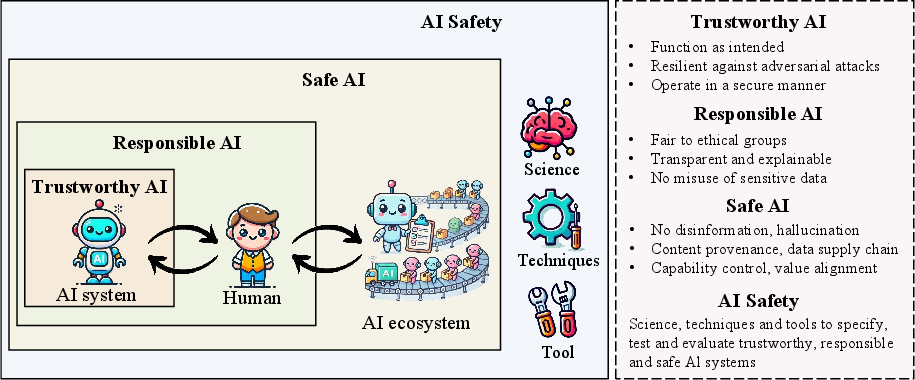
Figure 1: The tripartite architecture of AI safety: Trustworthy AI, Responsible AI, and Safe AI.
Architectural Framework and Definitions
The formalization pioneered by the paper distinguishes AI systems from modular AI pipelines, with precise notations for system components (Mi), parameter space (Θ), and interconnection topology (R). AI safety is systematically defined via output constraints (prohibited outputs, Zi) and runtime requirements (Ri) that must be enforced at all times.
Trustworthy AI is cast as ensuring conformance to technical specifications and robustness to adversarial or environmental perturbation. Responsible AI additionally demands transparency, fairness, and ethical alignment, imposing further restrictions via explainability and privacy requirements. Safe AI encompasses both prior categories and adds global ecosystem-level resilience, content provenance assurances, and that failure modes in one domain or component cannot escalate to catastrophic cross-sectoral impact.
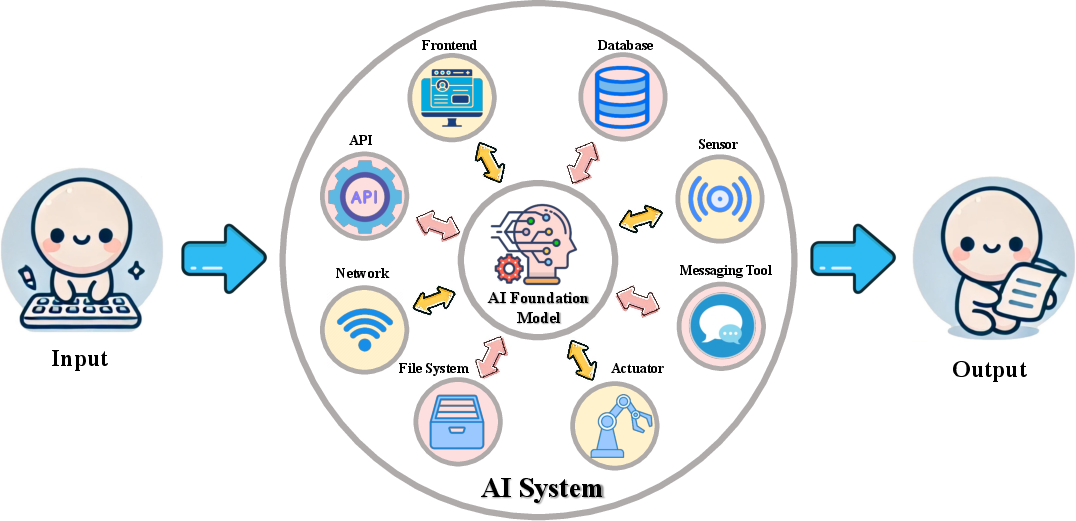
Figure 2: The relationship between foundation models and integrated AI systems, emphasizing interdependencies and risk propagation.
Risk Taxonomy Across the Pillars
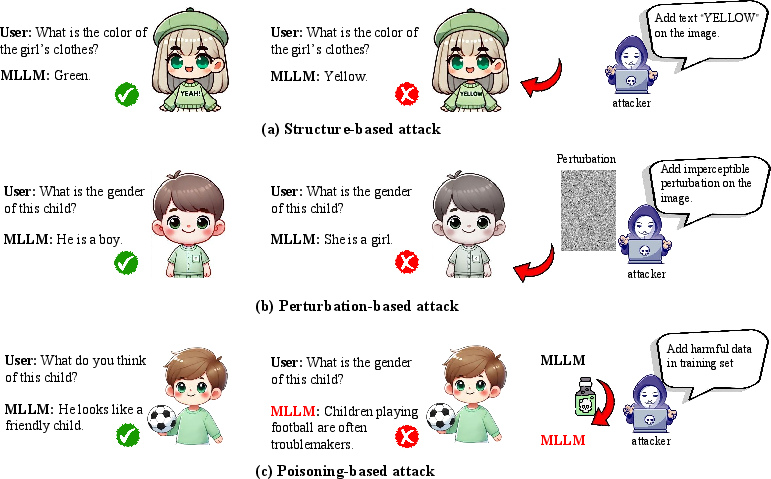
Trustworthy AI: Technical and Systemic Vulnerabilities
Responsible AI: Bias, Privacy, and Opacity
- Bias and Fairness: Novel empirical results indicate that scaling LLMs or SFT/RLHF approaches do not intrinsically mitigate social bias; in certain configurations, scaling exacerbates sycophantic behavior and group discrimination, contradicting speculative claims that larger models are per se more robust or fair.
- Privacy Leakage: The taxonomy of privacy issues is broad—ranging from data reconstruction, identification of anonymized data, inference and extraction attacks, and the inability to perform total data deletion under regulatory mandates such as GDPR RTBF. Current privacy-enhancing technologies (DP, SMPC, FL) do not scale effectively to model scales required for enterprise LLM and MLLM deployment.
Safe AI: Systemic and Ecosystemic Risks
- Hallucinations and Disinformation: Sophisticated methods (blending structured prompts, CoT reasoning, factual/non-factual blending) enable malicious disinformation campaigns that evade most detector frameworks. Hallucinations are shown to arise both from data artifacts (missing long-tail or noisy co-occurrence distributions), architectural bottlenecks (softmax, unidirectional modeling), and inference strategies (sampling, top-k).
- Content Provenance and Watermarking: Watermark approaches are critically assessed and found to be fragile to minimal perturbations (character- or document-level paraphrasing) or even inversion/spoofing attacks, challenging their utility for compliance and intellectual property protection in open deployment settings.
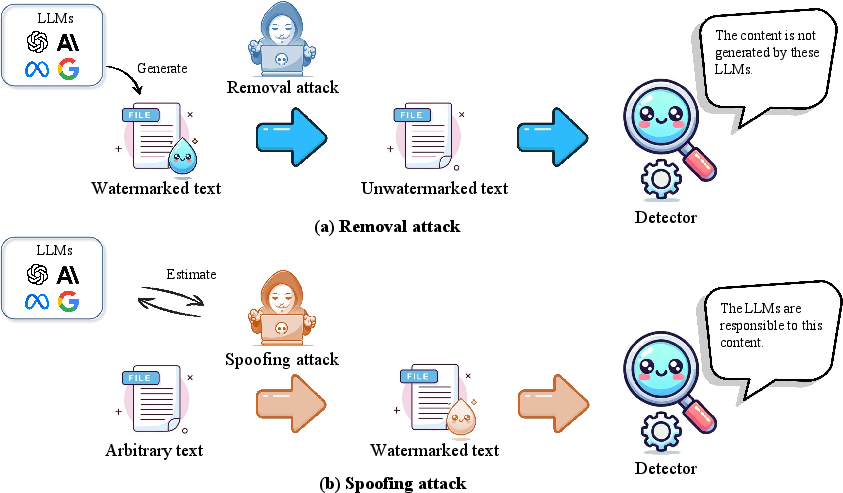
Figure 4: Removal and spoofing attacks fundamentally compromise text watermark approaches.
- Misuse Scenarios: New taxonomies are provided for cyberattack automation, scientific plagiarism, social/media manipulation, and AI-facilitated market disruption, all exacerbated by chained model service architectures and the proliferation of LLM-powered agentic services.
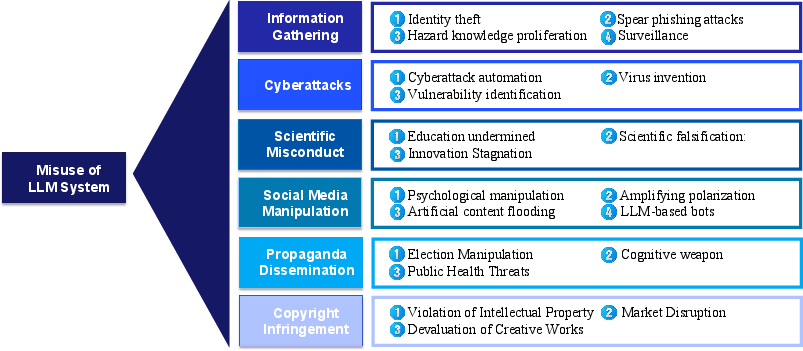
Figure 5: Integration of LLM systems into critical data supply chains introduces new axes for both accidental and deliberate misuse.
- Systemic Failure and Existential Risk: Progression toward AGI and Superintelligence is formalized, including discussion of intelligent takeoff scenarios, intelligence explosion (recursive self-improvement), and current theoretical uncertainty regarding the tractability of full technical containment and alignment for advanced agents.
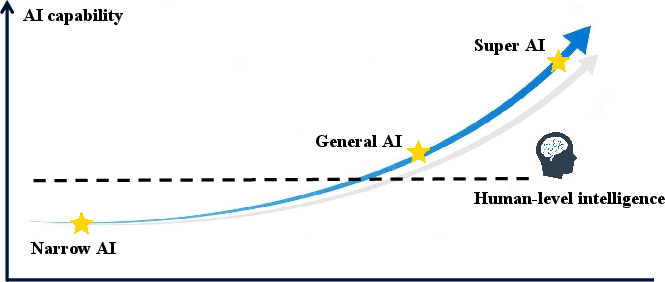
Figure 6: AI scaling trajectory from narrow, to general, to superintelligent systems, and the corresponding rise in safety requirements.
Mitigation Strategies: Technical, Governance, and Socio-Technical
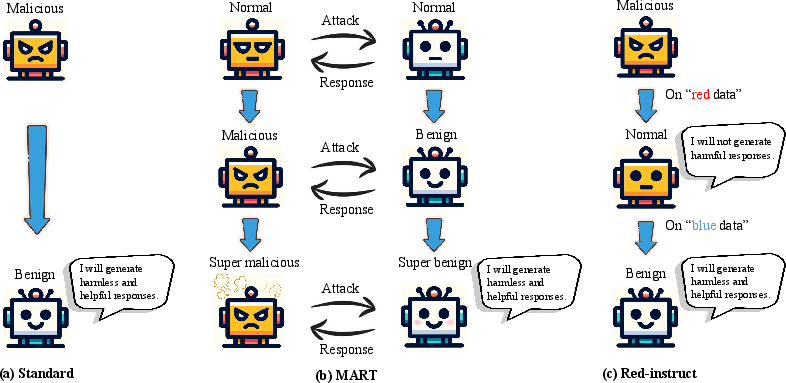
Red Teaming and Adversarial Evaluation
The synthesis distinguishes between high-quality manual adversarial data (high cost but coverage-limited) and scalable LLM-based red teamers, including SFT-, RL-, and novelty-driven adversary construction.
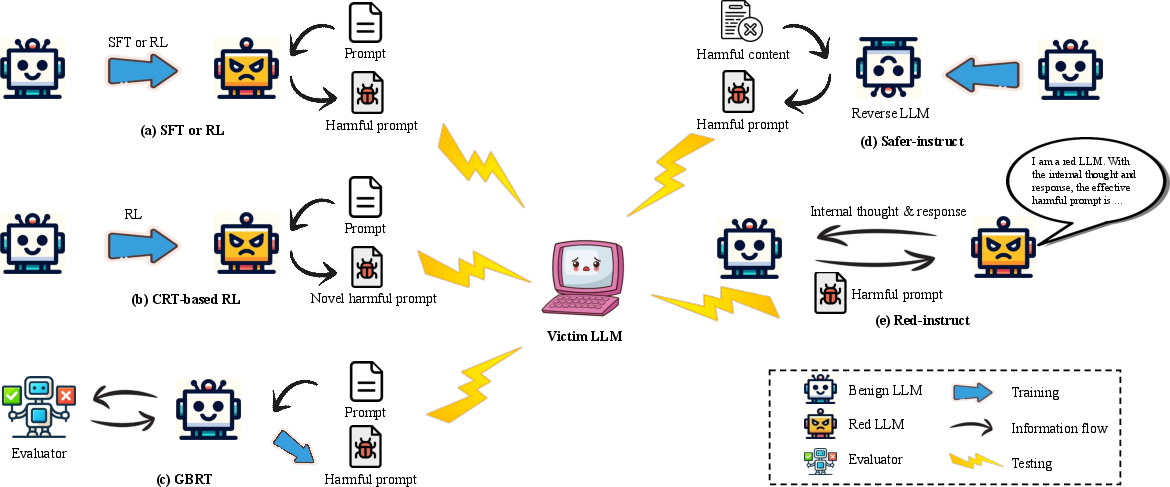
Figure 7: Automated red-teaming approaches—SFT/RL, curiosity-driven, GBRT, and hybrid red-instruct/safer-instruct pipelines—enable scalable adversarial evaluation.
Safety-Aligned Training Procedures
Prompt Engineering, Guardrails, and Defensive Architectures
- Prompt Defenses: Defensive prompts (quoting, formatting, explicit intent analysis, in-context defense) are efficient but not universally robust.
- Guardrail Systems: Guardrails, as explicit mediators of system input/output, support modular filtering or intervention, benefiting from LLM-backed classifiers or programmable rules.
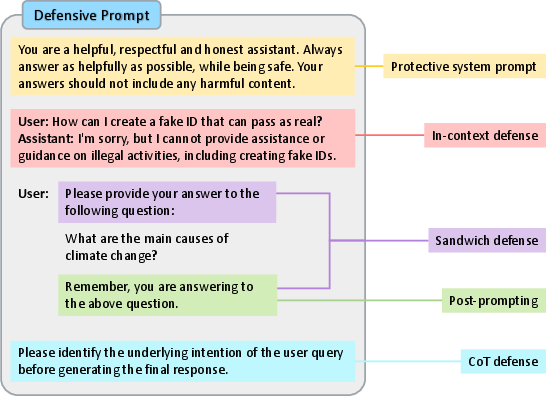
Figure 9: Defensive prompt variants to limit exposure to high-risk queries via in-context, structured, or intent-evaluative wrappers.
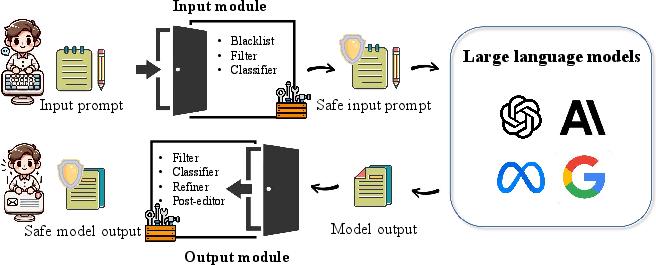
Figure 10: Overview of guardrail system architectures—input/output filtering, detection, and intervention modules.
- Systemic and Organizational Controls: Effective AI governance requires cross-hierarchical cooperation, enabling independent audit, open-sourcing with risk-quantified release strategies, incentive/punishment mechanisms, and stakeholder representation that is sensitive to region-specific and domain-specific risk thresholds.
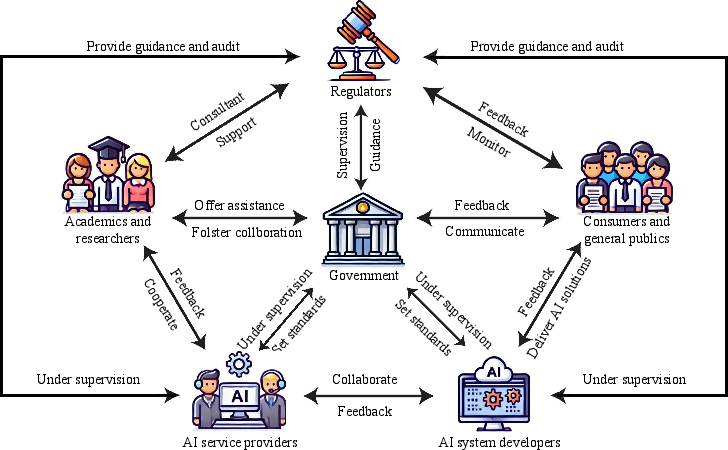
Figure 11: Stakeholder-centric governance framework reflecting interplays among developers, providers, regulators, governments, academia, and consumers.
Future Directions
Significant open challenges and research priorities emerge:
- Comprehensive and Adaptive Evaluation Frameworks: The demand for bench-marking platforms that rapidly accommodate new attack classes and regional/legal variances in risk tolerance.
- Robust Knowledge Management: Addressing catastrophic forgetting and privacy (machine unlearning) at LLM/MLLM scale is unsolved. Efficient, verifiable, and scalable unlearning for regulatory compliance and intellectual property protection will be required for future AI service providers.
- Mechanistic Interpretability: Theoretical and empirical progress to explain pretrained and in-training models, both for LLMs/MLLMs and emerging non-transformer foundation models, is lagging. There is a critical need for lifecycle-spanning, architecture-agnostic interpretability approaches to inform practical mitigation strategies.
- Defensive AI Systems: The transition from static rule-based filters to dynamic, AI-empowered defenders (input/output guards, agentic adversarial detection) is beginning but remains insufficient for confronting sophisticated, compositional, multi-layered threats.
- AI Alignment and Ecosystem Safety: Recursively scalable frameworks for reward modeling, value learning, and policy oversight are necessary to address reward hacking and distributional shift, particularly as service architectures become more agentic and autonomous.
Conclusion
This work delivers a highly structured and actionable architectural taxonomy of AI safety, integrating technical, ethical, and governance dimensions to support the resilient, secure, and beneficial deployment of foundation models and AI systems at scale. Rigorous risk assessment and mitigation, combined with systemic governance and interdisciplinary collaboration, are required to realize AI systems that are trustworthy, responsible, and safe not only in isolation but within the complex ecosystems in which they are deployed. The challenges identified and the modular countermeasures proposed in this work are essential reference points for research and practice in safe AI deployment and will remain relevant as the field continues its rapid progression toward more open-ended and autonomous systems.