The Curious Case of Curiosity across Human Cultures and LLMs
Abstract: Recent advances in LLMs have expanded their role in human interaction, yet curiosity -- a central driver of inquiry -- remains underexplored in these systems, particularly across cultural contexts. In this work, we investigate cultural variation in curiosity using Yahoo! Answers, a real-world multi-country dataset spanning diverse topics. We introduce CUEST (CUriosity Evaluation across SocieTies), an evaluation framework that measures human-model alignment in curiosity through linguistic (style), topic preference (content) analysis and grounding insights in social science constructs. Across open- and closed-source models, we find that LLMs flatten cross-cultural diversity, aligning more closely with how curiosity is expressed in Western countries. We then explore fine-tuning strategies to induce curiosity in LLMs, narrowing the human-model alignment gap by up to 50\%. Finally, we demonstrate the practical value of curiosity for LLM adaptability across cultures, showing its importance for future NLP research.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies curiosity — the urge to ask questions and learn — and how it looks different in people from different countries. It then checks whether today’s AI LLMs show those same differences when they “act” like people from different cultures. The authors introduce a tool called CUEST to measure how closely LLMs match human curiosity across cultures, and they try ways to make LLMs more curious and culturally aware.
What questions did the researchers ask?
They focused on three simple questions:
- Do people from different countries show different styles and interests when they ask questions online, and do LLMs copy these patterns?
- Can we train LLMs to be more curious in a way that respects cultural differences?
- Does adding curiosity actually help LLMs do better on cultural understanding tasks?
How did they study it?
Think of their approach like comparing music tastes and styles:
- They looked at “songs” (questions people ask) from many countries.
- They compared those to “songs” created by LLMs pretending to be from those countries.
- They checked both the “style” of the questions (how they’re written) and the “playlist” choices (which topics each country is most curious about).
- They also checked their results against “music theory” — well-known social science theories about culture — to see if patterns made sense.
Here’s what they did in everyday terms:
- Human questions: They used real questions from Yahoo! Answers posted by people in 18 countries, across 16 topics (like family, health, arts). Questions in local languages were translated to English to compare fairly.
- LLM questions: They asked several AI models to role-play (“Assume you are from <country>…”) and generate:
- Questions on the same topics (to capture style)
- Rankings of which topics people in that country would be most curious about (to capture content preferences)
- CUEST evaluation (their measurement framework) had three parts:
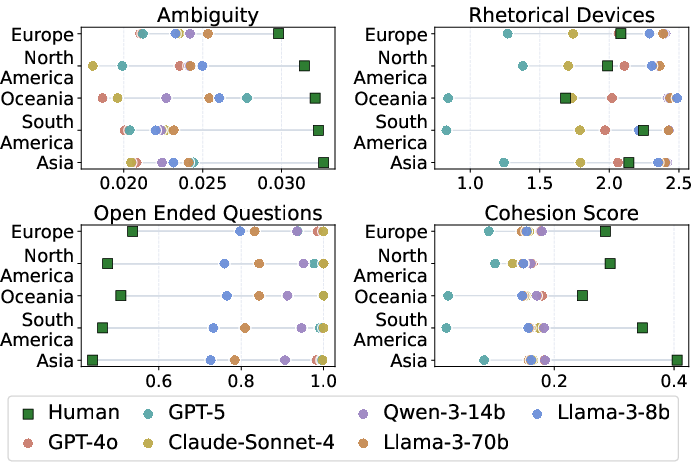
- Ambiguity: Could the question be understood in more than one way? (Ambiguity can signal deeper exploration.)
- Rhetorical devices: Does it use creative language (like metaphors) to explore ideas?
- Open-endedness: Is there more than one possible answer?
- Cohesion: Do the ideas in the question connect smoothly?
- 2) Topic Preference Alignment (content): Do the model’s favorite topics for each country match the human patterns?
- 3) Grounding in Social Science: They compared patterns with well-known cultural theories (like Hofstede’s dimensions, Schwartz’s values, and Hall’s high/low context communication) to see if the curiosity patterns made cultural sense.
- Making LLMs more curious (fine-tuning): They tried two training strategies on the best-performing model:
- Full fine-tuning (changing many model weights)
- Adapter fine-tuning (adding a small “attachment” that teaches new behavior without changing the whole model)
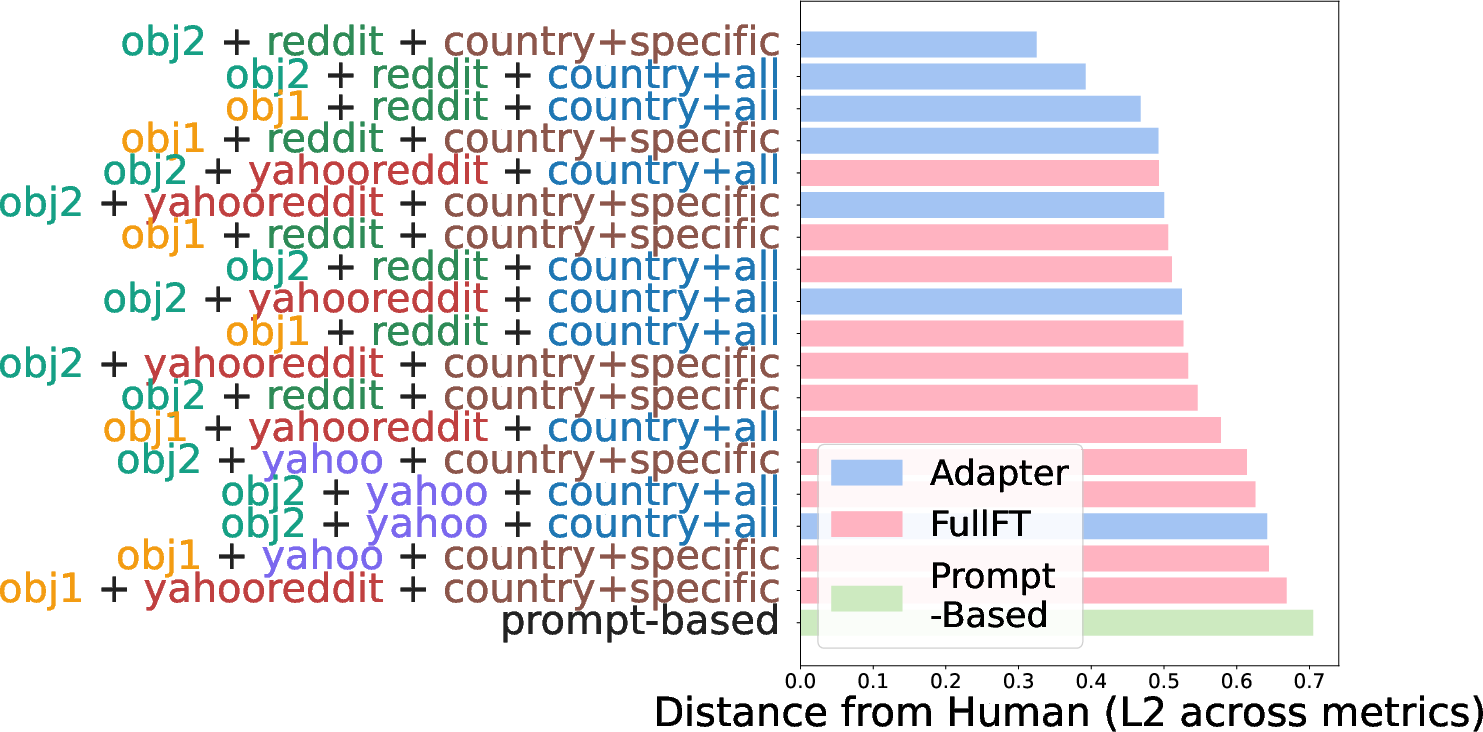
- They trained on questions from Yahoo! Answers and from country-specific Reddit communities. They tested two training styles:
- obj1: “Write one question from a person in <country>” (direct)
- obj2: Add a short “setup” sentence before the question, like a mini conversation, to encourage natural curiosity.
- Inherent curiosity test: They gave models short statements (some general, some country-specific) that naturally invite follow-up questions, then checked:
- Curiosity rate: Does the model ask a question at all?
- Relevance: Is the follow-up question on-topic?
What did they find, and why does it matter?
Main findings:
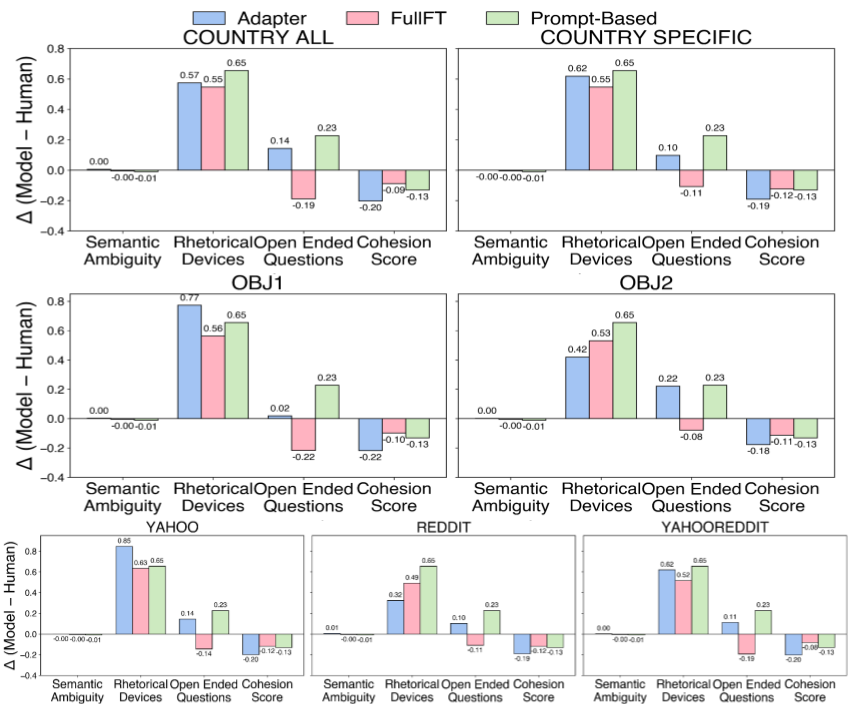
- LLMs flatten cultural differences. Human questions vary a lot by country, but LLM-generated questions look more similar across countries and lean toward Western styles. In style:
- Humans: more ambiguity and stronger cohesion (ideas connect closely).
- LLMs: more open-ended questions (broad, general).
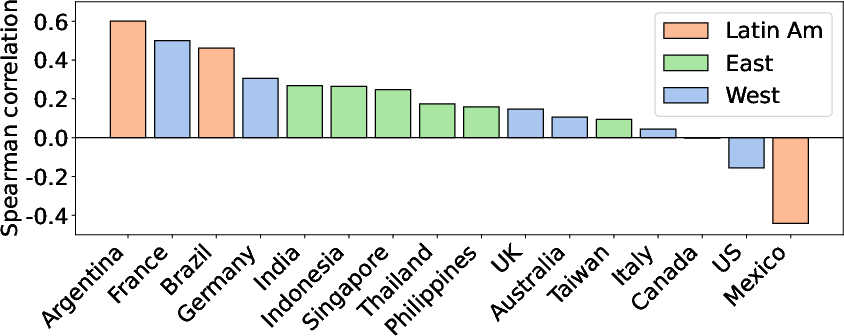
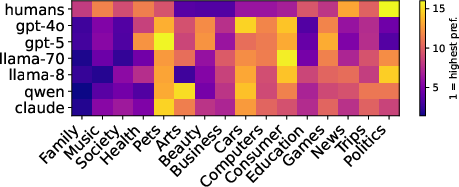
- Topic preferences diverge. LLMs often favored topics like “Family and relationships” or “Music and entertainment,” while humans prioritized things like “Arts and humanities,” “Beauty and style,” and “Business and finance.” Only one model (LLaMA-3-8b) showed modest positive agreement with human topic rankings; others didn’t match well.
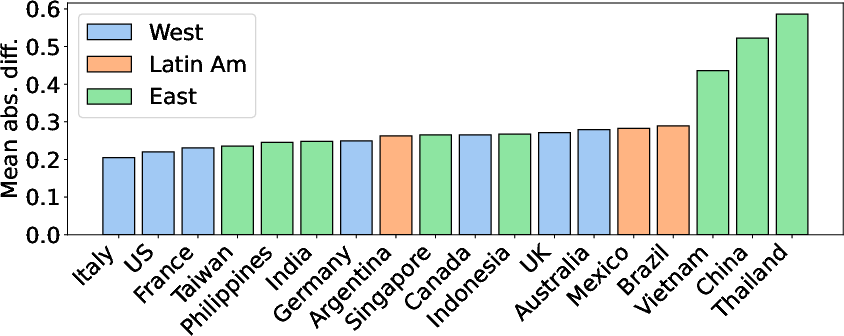
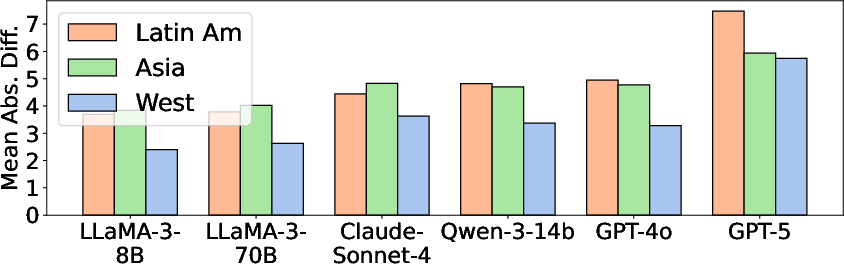
- Social science grounding shows gaps. Models aligned better with Western countries than with Eastern or Latin American ones. Some cultural theories matched the data (e.g., “Openness vs. Conservation” from Schwartz), while others didn’t (e.g., Hall’s high/low context), even for humans, likely because online platforms reduce social pressure and cultures change over time.
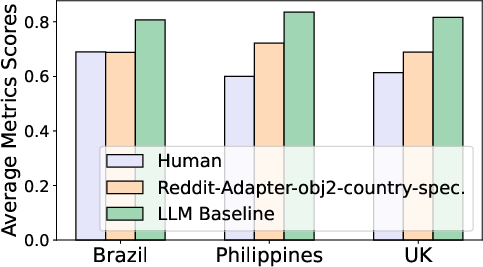
- Training can make models more curious and more culturally aligned. Adapter fine-tuning, especially with Reddit data and the conversational training style (obj2), worked best. It reduced the gap between human and model curiosity by up to about 50% (depending on the measure).
- Inherent curiosity improved. Adapter-tuned models asked follow-up questions far more often (about 75% of the time) and kept them relevant, while fully fine-tuned models asked fewer (about 20%).
- Curiosity helps on real tasks. When models first asked themselves one or two sub-questions before answering, they did better on three cultural benchmarks (judging social norms, answering culture knowledge questions, and cultural commonsense). The biggest gains came when combining curiosity prompting with the curiosity-trained model.
Why this matters:
- Friendlier, fairer AI: If LLMs understand that curiosity looks different across cultures, they can ask better follow-up questions, avoid stereotypes, and fit local norms more respectfully.
- Better performance: Curiosity isn’t just “cute” — it helps models reason more carefully and make better decisions in culturally sensitive tasks.
What could this change in the future?
- Build-in curiosity as a skill: Training LLMs to ask thoughtful, culturally aware questions can make them more helpful and adaptable everywhere.
- Respect cultural variety: Instead of using one-size-fits-all behavior, models can learn to match different communication styles and interests.
- Safer cultural alignment: Adapter-based methods can add culture-aware curiosity without overwriting a model’s general knowledge, reducing the risk of losing other abilities.
- Better benchmarks and training: The CUEST framework can guide future research on how LLMs ask questions, not just how they answer them.
Overall, this paper shows that curiosity is a powerful tool for making AI more inclusive, more accurate, and more human-aware across different cultures.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of gaps that are missing, uncertain, or left unexplored, framed to be concrete and actionable for future research.
- Dataset representativeness and temporal validity: Yahoo! Answers is an older, English-heavy, anonymous platform with unknown user demographics and time ranges; verify whether it meaningfully reflects current, national curiosity patterns and complement it with contemporary, native-language Q&A sources, search logs, and region-specific forums.
- Translation-induced distortion: Quantify how machine translation alters rhetorical devices, ambiguity, and cohesion across cultures; run bilingual human audits and use multilingual models to generate/analyze questions in native languages to minimize translation bias.
- Construct validity of curiosity metrics: Validate whether ambiguity, open-endedness, cohesion, and rhetorical devices reliably measure curiosity cross-culturally; develop and test psychometrically grounded measures (e.g., information gap magnitude, epistemic vs. social curiosity typologies) with diverse human annotations.
- Theory grounding via LIWC: The mapping from question text to Hofstede/Schwartz/Hall constructs using LIWC is not validated cross-culturally; build and evaluate culturally sensitive coding schemes and consider contemporary frameworks (e.g., narrative identity, intersectionality, microcultures) to avoid over-reliance on legacy models.
- Persona prompting validity: Assess whether LLMs truly adopt cultural personas versus merely echo stereotypes; perform manipulation checks, vary prompt formulations systematically, and measure prompt sensitivity and robustness across models.
- Statistical rigor and reporting: Provide per-country/topic sample sizes, confidence intervals, effect sizes, multiple-comparisons corrections, and power analyses; expand beyond three random seeds to characterize inter-run variability and ensure replicability.
- Attribution of “Western alignment” and flattening: Test hypothesized causes (pretraining corpora composition, RLHF/safety tuning) with controlled ablations across model variants and training pipelines to move beyond speculation.
- Topic preference operationalization: Question frequency as a proxy for national curiosity is confounded by platform dynamics; incorporate ground-truth preference signals (surveys, search trends, media consumption) and explain negative correlations observed for certain countries (e.g., UK, Mexico).
- Fine-tuning data representativeness: Country subreddits may reflect diaspora, English-speaking minorities, or moderation artifacts; audit the cultural authenticity of Reddit data and source country-local platforms to reduce sampling bias.
- Lexical augmentation limitations: Simple synonym/word-swap augmentation may distort style and rhetorical features; evaluate human-perceived fidelity and use paraphrase/back-translation or style-controlled augmentation instead.
- Model generalization: Fine-tuning and adapter results are shown only for LLaMA-3-8b; test portability of adapter-based curiosity induction across diverse model families, sizes, and guardrailed deployments.
- Inherent curiosity evaluation scope: Current evaluation is single-turn with two human annotators; expand to multi-turn, cross-cultural raters, measure appropriateness and user satisfaction, and detect over-questioning or intrusive behavior.
- Safety, bias, and ethics: Curiosity induction can amplify stereotypes, privacy violations, or culturally inappropriate probing; design guardrails, consent-aware questioning policies, and harm audits across sensitive domains and cultures.
- Multilingual/dialectal coverage: Extend CUEST beyond English to native languages, dialects, and code-switching contexts; develop multilingual rhetorical device detectors and language-specific feature sets.
- Rhetorical devices measurement: Translation likely obscures figurative language; build annotated corpora and classifiers for rhetorical devices that are robust across languages and cultural styles.
- Downstream evaluation breadth: Improvements are shown on three English-centric benchmarks; test impact on real-world applications (e.g., tutoring, health advice, customer support) across cultures and languages, including longitudinal outcomes.
- Curiosity vs. deliberation confound: Disentangle gains due to curiosity-driven questioning from generic increases in deliberation tokens (e.g., chain-of-thought); run ablations (self-ask vs. CoT vs. structured questioning) with controlled token budgets.
- Curiosity calibration: Determine context-sensitive question-asking rates and triggers (uncertainty, cultural mismatch) to avoid user burden; develop metrics and policies for adaptive, situation-appropriate curiosity.
- Stereotype reinforcement dynamics: LLM alignment improves when human curiosity matches stereotypes; design detection/mitigation methods for stereotype reliance in question generation and test with counter-stereotypical scenarios.
- Hall’s high/low-context non-alignment: Both human and model results diverge from expected patterns; revisit measurement instruments by analyzing contextualized discourse (conversations, narratives) instead of standalone questions.
- Country grouping granularity: The Western/Eastern/Latin classification is coarse; investigate subregional, urban/rural, socio-economic, age, and gender segments to capture within-country cultural variability.
- Reproducibility and openness: Closed-source models limit replication; release complete prompts, seeds, sampling/decoding settings, generated datasets, and evaluation scripts to standardize CUEST replication.
- Temporal dynamics: Analyze how curiosity styles and topic preferences shift over time (e.g., pre/post major cultural events) and whether LLMs capture these temporal trends.
- Human annotation of curiosity quality: Move beyond limited subjective evaluation to build cross-cultural annotation campaigns labeling curiosity type, intensity, and appropriateness; report inter-annotator agreement and adjudication procedures.
- Metric robustness under translation: Conduct controlled experiments with parallel corpora to estimate how translation affects ambiguity/cohesion scores and calibrate metrics accordingly.
- Benchmark cultural validity: NormAd, CulturalBench, and Cultural Commonsense are English-centric; develop multilingual versions and country-specific variants and test cross-lingual transfer and fairness.
- Integration into training pipelines: Specify how curiosity can be systematically integrated into RLHF or post-training (e.g., curiosity-sensitive reward models, adaptive questioning policies) and evaluate trade-offs with safety and efficiency.
Practical Applications
Below is an overview of practical, real-world applications that stem from the paper’s findings, methods (CUEST), and demonstrated innovations (adapter-based curiosity induction and “prompt-ask” workflows). Items are grouped by deployability horizon and, where relevant, mapped to sectors and potential tools or workflows. Each item includes assumptions or dependencies that may affect feasibility.
Immediate Applications
- Culture-adaptive customer support and sales assistants (software; industry)
- Use adapter-based fine-tuning (LoRA) on a performant base model (e.g., LLaMA‑3‑8B) to induce curiosity and add a “prompt-ask” step so assistants ask one or two clarifying questions before resolving tickets or making recommendations.
- Workflow: CUEST-scored evaluation → adapter fine-tuning with obj2 conversational scaffolding → runtime “curious-ask” guardrail (Self‑Ask style) → deploy per market persona.
- Assumptions/dependencies: Availability of representative regional conversational data (e.g., Reddit, local forums), safe RLHF integration, translation fidelity for non-English queries, and monitoring to avoid stereotyping.
- Culturally aware triage and intake in healthcare (healthcare; industry/public sector)
- Incorporate curiosity-driven follow-up questions during symptom collection, social determinants screening, or mental health check-ins to reduce misinterpretation across cultural contexts.
- Tools: Adapter-fine-tuned “curious” module, CUEST linguistic metrics (ambiguity, cohesion) for QA of prompts, and audit on Cultural Commonsense benchmarks.
- Assumptions/dependencies: Clinical validation and safety review, HIPAA/GDPR compliance, interpreter/translation support, and bias audits to ensure curiosity doesn’t reinforce stereotypes.
- Cross-cultural tutoring and coaching (education; industry/academia)
- EdTech tutors that dynamically adjust question style (direct vs. indirect, open-endedness, rhetorical devices) by learner locale and background, increasing engagement and comprehension.
- Workflow: CUEST alignment checks per target cohort → adapter fine-tuning with obj2 → in-session “curious-ask” routine for formative assessment.
- Assumptions/dependencies: Curriculum alignment, teacher oversight, multilingual capabilities, and data to calibrate Hall’s high/low-context adaptations.
- Content localization and UX research (media/marketing/product; industry)
- Use CUEST to compare human vs. model topic preferences and question styles across countries, guiding localized content strategy (e.g., campaign Q&A, help center, onboarding).
- Tools: Topic Preference Alignment (Spearman/Kendall), LIWC-based theory grounding for tone/style audits, A/B testing with “curious-ask” interactions.
- Assumptions/dependencies: Reliable market data per locale; guardrails to avoid over-reliance on Western stereotypes seen in baseline LLMs.
- Safer automation via clarifying questions (platform safety/compliance; industry/policy)
- Before executing sensitive actions (account changes, financial transfers, content moderation), assistants ask culture-aware clarifying questions to reduce false positives/negatives.
- Workflow: “Prompt-ask” interstitial + risk-aware policies → evaluate gains (e.g., NormAd accuracy improvements) → phased rollout.
- Assumptions/dependencies: Latency budgets, user tolerance for extra steps, and robust privacy/consent handling.
- Survey and questionnaire design assistants (academia/policy; social science)
- Authoring tools that recommend culturally appropriate question framing (ambiguity, open-endedness, rhetorical devices) to improve response quality in international studies.
- Tools: CUEST’s linguistic metrics; LIWC grounding with Hofstede/Schwartz for tone calibration; generator that produces variants per country persona.
- Assumptions/dependencies: Domain expert review, multilingual nuance preservation, and avoidance of outdated stereotype templates.
- Cross-cultural onboarding for global teams (HR/L&D; industry)
- Microlearning bots that model curiosity through context-aware questions about workplace norms, meetings, feedback styles, and social rituals by region.
- Tools: Adapter-based “curiosity” induction; NormAd-derived scenarios; “curious-ask” interactions for reflective practice.
- Assumptions/dependencies: Organizational buy-in, content validation by local employees, and privacy-preserving analytics.
- Personal assistants for travel and daily life (consumer software; daily life)
- Travel planning and etiquette helpers that ask clarifying questions (e.g., dietary norms, social rituals) to reduce misunderstandings and improve recommendations.
- Workflow: Country persona → curiosity prompts → follow-up question generation → refined plan.
- Assumptions/dependencies: Up-to-date local data, language support, and careful handling of local sensitivities.
- Model evaluation pipelines for R&D (software; academia/industry)
- Integrate CUEST into model QA to measure cultural curiosity alignment (linguistic facets, topic preferences, theory grounding) before deployment to new markets.
- Tools: Open-source CUEST repo; benchmark suite (NormAd, CulturalBench, Cultural Commonsense); adapter vs. full FT comparators.
- Assumptions/dependencies: Internal evaluation resources, dataset licenses, and versioning discipline.
Long-Term Applications
- Curiosity-aware RLHF and training objectives (software; academia/industry)
- Build training pipelines that optimize for culture-aware curiosity (asking relevant clarifying questions) alongside helpfulness/safety, reducing Western-centric flattening.
- Potential product: “Curiosity-RLHF” module that co-optimizes curiosity rate and relevance with fairness constraints.
- Assumptions/dependencies: Scalable multilingual datasets, new reward models, and careful safety alignment to avoid intrusive or biased questioning.
- Multilingual, culturally grounded LLMs beyond translation (software; industry/academia)
- Native-language training that preserves rhetorical devices, indirectness, and cohesion—improving alignment in East Asian and Latin American contexts where baseline gaps were largest.
- Tools: Curiosity corpora in local languages; regional Reddit/online forums; language-specific LIWC-like lexicons.
- Assumptions/dependencies: Data acquisition, community partnerships, and region-specific evaluation standards.
- Regulatory and standards development for cultural adaptability (policy; public sector/industry)
- Create audit standards that include curiosity alignment (CUEST) as part of fairness and global deployability certifications (ISO/IEEE-like).
- Potential workflow: Pre-market audit → periodic re-certification → incident reporting tied to cultural misinterpretation metrics.
- Assumptions/dependencies: Multi-stakeholder consensus, measurement validity, and non-discrimination enforcement.
- Personalized cultural profiles and adaptive dialogue (software; industry)
- Assistants that infer and continuously update a user’s cultural interaction preferences (directness, topic interests, curiosity tolerance) to personalize question-asking behavior.
- Tools: On-device preference learning; privacy-preserving signals; adaptive “curious-ask” controllers.
- Assumptions/dependencies: Strong privacy/consent models, transparency, and opt-in controls.
- Cross-cultural decision support in finance and public services (finance/government; industry/public sector)
- Loan officers’ assistants or benefits eligibility systems that use curiosity-driven questioning to surface context (e.g., informal employment norms, family obligations).
- Workflow: Policy-compliant “prompt-ask” layer → adjudication rationale logging → fairness audits.
- Assumptions/dependencies: Regulatory approval, explainability requirements, and rigorous bias testing.
- Social media and community design to reduce misinterpretation (platform design; industry/academia)
- “Curiosity by default” interaction features (gentle clarifying questions before posting/replying) to reduce cross-cultural misunderstandings and polarization.
- Tools: Lightweight “curious-ask” nudges; localized phrasing; A/B testing of conflict reduction.
- Assumptions/dependencies: User acceptance, measurable harm reduction, and abuse prevention.
- Embodied AI and service robots (robotics/hospitality/healthcare; industry)
- Robots that adapt questioning style to local norms (indirectness in high-context cultures, direct clarification in low-context), improving guest experiences and patient interactions.
- Tools: On-device adapters; sensor-informed contextual question generation; CUEST-based evaluations.
- Assumptions/dependencies: Real-time compute, safety certification, and multimodal integration.
- Crisis response and humanitarian assistance (public sector/NGO)
- Field assistants that ask culturally sensitive clarifying questions in disaster relief, refugee services, or public health outreach to avoid harmful misunderstandings.
- Workflow: Offline-capable “curious-ask” packs; region-specific adapters; post-incident review metrics (curiosity rate/relevance).
- Assumptions/dependencies: Low-resource deployment, local language support, and ethical guidelines.
- Cultural analytics for policy and foresight (academia/policy)
- Track shifts in societal openness, uncertainty avoidance, and topic curiosity over time using CUEST-like metrics, informing cultural diplomacy or education reforms.
- Tools: Time-series pipelines; LIWC/construct grounding; dashboards with region/country segmentation.
- Assumptions/dependencies: Ethical data sourcing, longitudinal coverage, and interpretability safeguards.
- Enterprise localization “OS” (software; industry)
- Platform layer orchestrating question-style adaptation across products (support, marketing, onboarding) with centralized CUEST scoring and adapter deployment per locale.
- Assumptions/dependencies: Integration cost, governance for stereotype avoidance, and cross-team alignment.
- Cross-cultural clinical decision support (healthcare; industry/academia)
- Diagnostic systems that ask culturally aware clarifying questions about symptoms, diet, and home remedies to improve accuracy in diverse populations.
- Assumptions/dependencies: Clinical trials, medical liability frameworks, and guardrails against bias.
In all cases, the paper’s evidence supports two design pillars that underpin these applications:
- Evaluation-first deployment: Use CUEST to measure linguistic alignment, topic preferences, and theory-grounded scores per target market before shipping.
- Curiosity-as-a-mechanism: Add a “curious-ask” step (prompt-ask) and, when feasible, adapter-based curiosity induction (obj2 + conversational scaffolding) to improve cultural adaptability and downstream task performance.
Glossary
- Adapter-based fine-tuning: A parameter-efficient method that adds small adapter modules to a model’s layers to specialize behavior without updating all weights. "adapter-based fine-tuning achieves the best performance and generates contextually relevant questions in conversations."
- Ambiguity: The degree to which a question or statement can be interpreted in multiple ways, inviting exploration. "ambiguity: captures the degree to which a question invites multiple interpretations, which is central to curiosity as it leads to exploration"
- Cohesion score: A quantitative measure of how well a text connects ideas using cohesive devices and linking concepts. "cohesion score: measures how well a question links concepts together -- connecting ideas can show deeper engagement"
- Cultural personas: Prompted identities that instruct models to generate content from the perspective of a specific country or culture. "LLM-generated questions and topic preferences (using cultural personas)."
- CulturalBench: A benchmark of human-verified questions across regions to probe cultural understanding. "CulturalBench is a set of 1,227 human-verified questions from 45 regions across different topics to probe cultural understanding (we use the Hard subset)"
- Cultural Commonsense: An evaluation that tests models’ ability to reason about culturally specific everyday inferences. "Cultural Commonsense tests models’ ability to reason about culturally specific everyday inferences (we use the English fill-in-the-blanks subset on country customs)"
- CUEST: An evaluation framework for measuring human–LLM alignment in curiosity across cultures via linguistic, topic, and theory-based analyses. "We introduce CUEST: a framework combining linguistic and content analysis with cultural grounding to analyze human and LLM curiosity questions across cultures."
- F-stat: A statistic from ANOVA used to compare variances across groups; here used to quantify cross-cultural variance differences. "F-stat:$7.33)$ -- LLMs tend to flatten cross-cultural differences."
- Grounding in Social Science Constructs: Situating analyses within established cultural theories to interpret patterns meaningfully. "Grounding in Social Science Constructs to contextualize curiosity within established cultural frameworks."
- Hall's high-context vs low-context: A cultural communication dimension contrasting implicit, indirect styles with explicit, direct styles. "Hall's high context cultures rely on implicit cues, and tentativeness, meaning curiosity often manifests in indirect forms."
- Hofstede's Cultural Dimensions: A framework of national culture dimensions used to analyze cross-cultural differences. "Hofstede's Cultural Dimensions: We operationalize 4 dimensions related to curiosity:"
- Indulgence-Restraint (IR): A Hofstede dimension contrasting enjoyment and hedonism with discipline and control. "Indulgence-Restraint (IR): indulgent culture frame curiosity as playful and hedonic, while restrained cultures emphasize discipline and self-control"
- Individualism-Collectivism (IC): A cultural dimension contrasting self-oriented with group-oriented values and inquiry. "Individualism-Collectivism (IC): expressing as a self-related inquiry or a social exploration"
- Kendall correlation: A rank correlation measure (Kendall’s tau) assessing ordinal association between rankings. "We now compare culture-specific LLM topic preferences with the human-authored ones using Spearman and Kendall correlations () ($1=$ very similar to humans, $0=$ unrelated, inverse)."
- L2 distance: The Euclidean distance metric used to quantify differences between model and human scores. "x-axis show model-human distances (L2) (averaged across metrics and countries)."
- LIWC: Linguistic Inquiry and Word Count, a psycholinguistic lexicon used to compute category-based text scores. "We compute LIWC scores corresponding to the above dimensions, showed in Fig~\ref{fig:liwc_ss}."
- Long-/Short-term orientation (LSO): A Hofstede dimension contrasting future-oriented with present/past pragmatic focus. "Long-/Short-term orientation (LSO): if curiosity is future oriented or present/past-oriented and pragmatic"
- MAE (Mean Absolute Error): The average absolute difference between values; used to summarize alignment gaps. "Social Science Theory Alignment: Region-wise MAE for models shows West vs East/Lat Am. Differences are prominent across models."
- Mean absolute differences: The average of absolute differences between model and human scores across countries. "Fig.~\ref{fig:regionwise_ling} presents the mean absolute differences between models and humans for each country."
- NormAd: A framework for measuring LLMs’ cultural adaptability via judgments of social acceptability across countries. "NormAd contains culturally-grounded social situations across 75 countries and tests modelsâ judgments of social acceptability (we restrict to binary (acceptable vs.\ not acceptable) and exclude neutral)"
- Open-endedness: A property of questions that allow broad, unconstrained answers and invite exploration. "open-endedness: reflects whether a question allows broad answers, similar to curiosityâs drive for knowledge-seeking."
- Rhetorical devices: Figurative or creative language constructions that shape expression and can enhance curiosity. "rhetorical devices: refers to creative or exploratory phrasing that can enhance curiosity expression"
- RLHF (Reinforcement Learning from Human Feedback): A training paradigm that aligns models using human preference signals. "less aggressive RLHF, whereas larger models undergo heavier RLHF and safety tuning, which can ``sanitize'' outputs toward generic, Western-normative patterns"
- Safety tuning: Additional alignment and constraint procedures applied to models to regulate outputs. "less aggressive RLHF, whereas larger models undergo heavier RLHF and safety tuning, which can ``sanitize'' outputs toward generic, Western-normative patterns"
- Self-Ask: A prompting strategy where a model generates and answers sub-questions to improve reasoning. "inspired by Self-Ask"
- Spearman correlation: A rank correlation measure (Spearman’s rho) assessing monotonic relationships between rankings. "We now compare culture-specific LLM topic preferences with the human-authored ones using Spearman and Kendall correlations () ($1=$ very similar to humans, $0=$ unrelated, inverse)."
- Topic Preference Alignment: Evaluating alignment by comparing model-vs-human topic rankings to capture content-level curiosity. "Topic Preference Alignment to examine content preferences,"
- WEIRD: An acronym for Western, Educated, Industrialized, Rich, and Democratic populations, highlighting sampling bias. "may bias our study towards WEIRD (Western, Educated, Industrialized, Rich and Democratic) notions"
Collections
Sign up for free to add this paper to one or more collections.