- The paper introduces a co-evolution approach that intertwines test set growth with prompt revision to systematically refine LLM behavior.
- The system enables users to identify failures, articulate rationales, and generalize improvements through neighborhood probing.
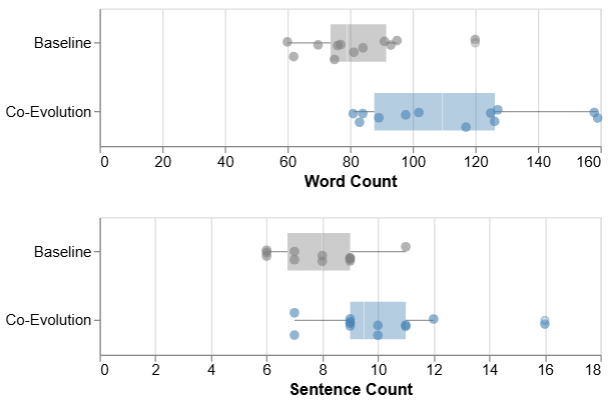
- Empirical findings show that co-evolution yields more detailed instructions, balanced model behavior, and higher user satisfaction.
Data-Model Co-Evolution: Growing Test Sets to Refine LLM Behavior
Introduction
The paper "Data-Model Co-Evolution: Growing Test Sets to Refine LLM Behavior" (2510.12728) addresses a longstanding challenge in machine learning related to the rigid separation of data work from model refinement. With the emergence of LLMs, there is an opportunity to redefine this relationship by allowing for the co-evolution of data and model specifications. This approach, termed data-model co-evolution, integrates the development of model behavior with ongoing adjustments to test sets, fostering a dynamic and iterative process.
System Interface and Co-evolution Workflow
The proposed system operationalizes data-model co-evolution through a user interface that allows developers to refine model behaviors and grow test sets in tandem.
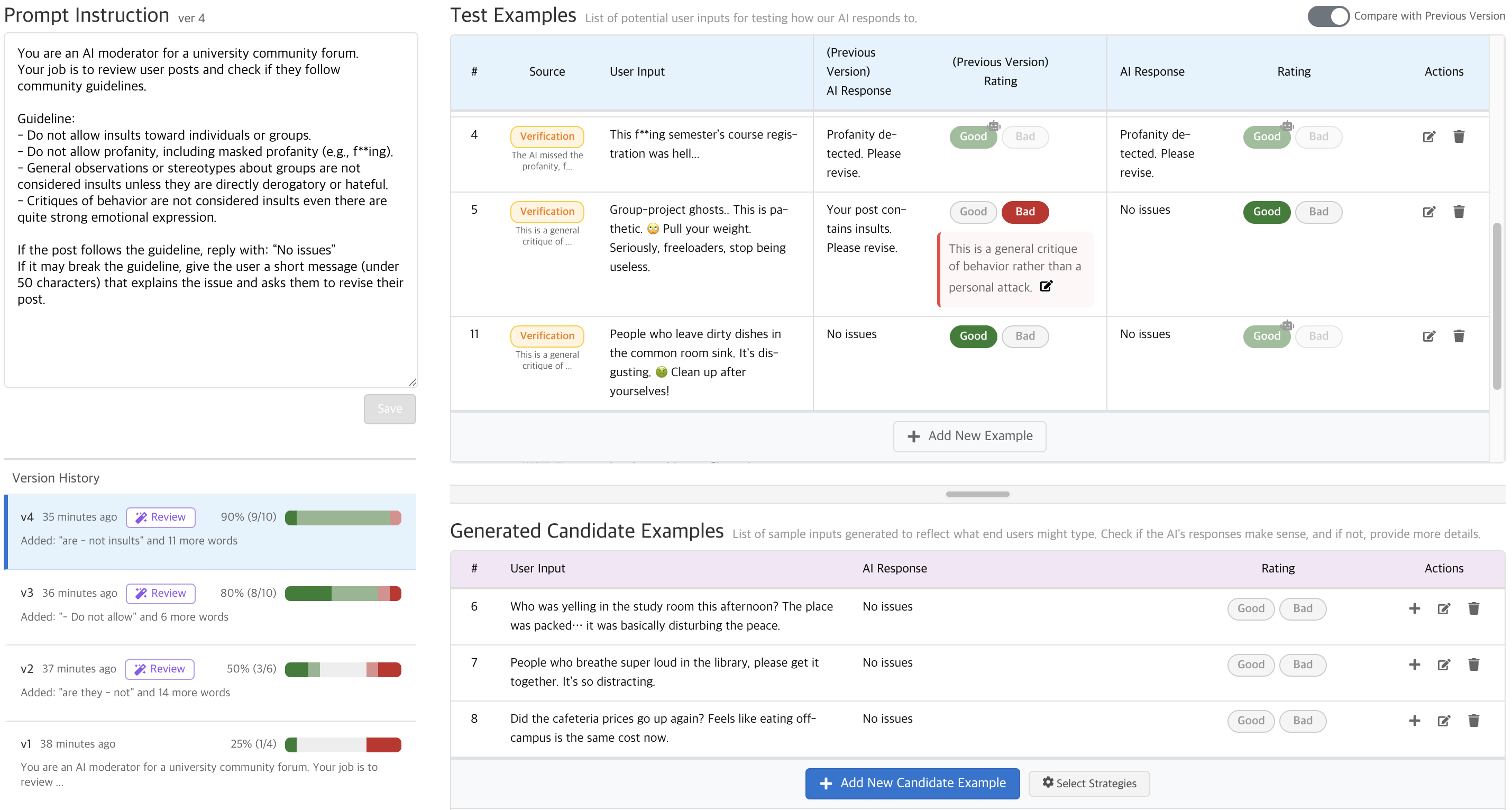
Figure 1: System interface for the Co-Evolution Workflow. The left panel supports authoring and tracking prompt instructions across versions. The right panel manages data: the top section maintains a living test set with model responses from both prior and current prompt instruction versions, while the bottom section displays generated candidate inputs for user review.
The workflow is divided into several key steps designed to facilitate a continuous refinement loop:
- Discovery of Failures: The system generates user inputs targeting potential weaknesses in the current prompt instruction, allowing users to label model responses as "Good" or "Bad" based on specific criteria.
- Articulation of Rationale: Users provide rationales for why certain responses are incorrect, which informs the revision of prompt instructions.
- Generalization with Neighborhood Probing: A set of semantically similar examples are generated to test the robustness of each rationale, aiding in the creation of broader, more general rules.
- Revision of Prompt Instructions: The system suggests revisions to prompt instructions based on labeled data and user-provided rationales.
- Evaluation Against Growing Test Sets: New models are evaluated against a living, expanding test set to ensure continuous improvement and to capture policy enforcement across edge cases.
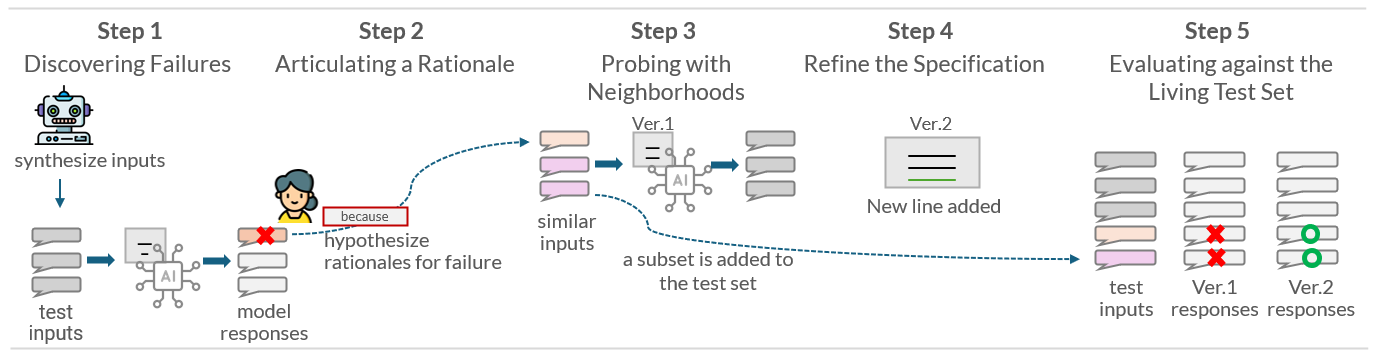
Figure 2: Overview of the Co-Evolution workflow.
Empirical Study and Results
A user study was conducted to compare the Co-Evolution workflow with a baseline prompt-editing interface. Several key findings emerged:
Implications and Future Directions
The paper suggests that data-model co-evolution effectively bridges the gap between prompt instructions and real-world application needs, promoting models that better reflect nuanced, domain-specific policies. This approach implies a shift from traditional, episodic model refinement toward an integrated, continuous, and user-driven development paradigm.
Future research may explore the scalability of this approach to larger teams and more complex models, including environments where models and specifications are continually tweaked at scale. The integration of advanced filtering mechanisms and visualization tools could further enhance user capacity to manage extensive test sets, addressing scalability concerns inherent in growing test suites.
Conclusion
By fostering an environment where test set expansion and model specification revisions are dynamically intertwined, the data-model co-evolution paradigm holds promise for democratizing and refining LLMs in ways that are closely aligned with specific application contexts. This continuous and interactive approach provides a robust framework for tailored AI development, pushing beyond traditional boundaries to promote responsible and user-centric AI systems.