- The paper introduces PICO, which reliably distinguishes semantic content from stylistic interference using prototype iterative construction.
- It employs semantic probability calculation based on positive embedding interactions and statistical sign distribution to weight feature contributions.
- Experimental evaluations show improvements of 5.2% to 14.1% over state-of-the-art methods in tasks like image-text retrieval and captioning.
Reliable Cross-modal Alignment via Prototype Iterative Construction
Introduction
The paper "Reliable Cross-modal Alignment via Prototype Iterative Construction" (2510.11175) introduces a novel model, PICO, aimed at enhancing cross-modal alignment by effectively managing non-semantic information such as stylistic variations. The necessity for this arises from the limitations of traditional methods which assume embeddings to solely carry semantic information, often leading to biases and information loss due to the presence of style information.
PICO seeks to address these challenges by distinguishing semantic from stylistic information and using a sophisticated framework that quantifies and properly weights the interaction between feature columns. This paper contributes to the cross-modal alignment domain by introducing a methodology for reliable semantic probability assessment, leveraging prototype iterative construction, and integrating a performance feedback-based weighting function.
Methodology
The PICO framework relies on fine-grained cross-modal alignment, diverging from conventional methods by incorporating weighted interactions to account for non-semantic aspects (Figure 1).
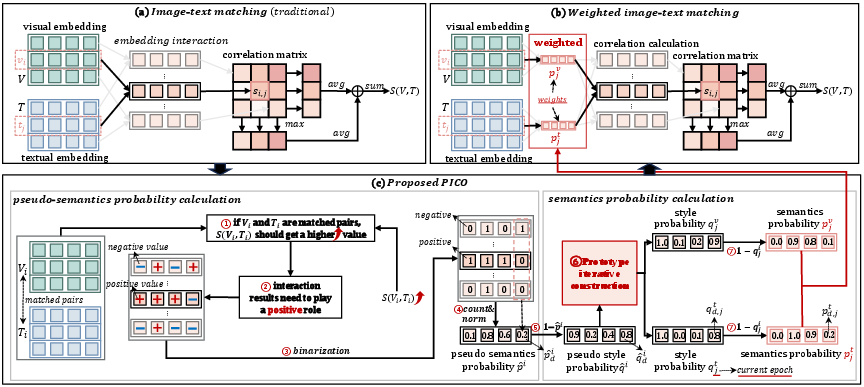
Figure 1: Overview of PICO. The process involves weighted fine-grained cross-modal alignment, statistical analysis, prototype extraction, and iterative refinement.
Semantic Probability Calculation
A core aspect of PICO is calculating semantic probabilities for each feature column by analyzing positive embeddings interactions. This involves identifying pseudo-semantic probabilities via statistical sign distribution analysis of interaction results, which are then used as weights during embedding interactions. Such a setup aims to privilege feature columns representing semantic content over stylistic interferences.
Prototype Iterative Construction
The extraction of pseudo-style prototypes plays a pivotal role in the reliability of determining semantic probabilities. These prototypes are refined using an iterative construction mechanism where initial prototypes, created during early training stages, are incrementally updated based on performance feedback from recall metrics (Figure 2).
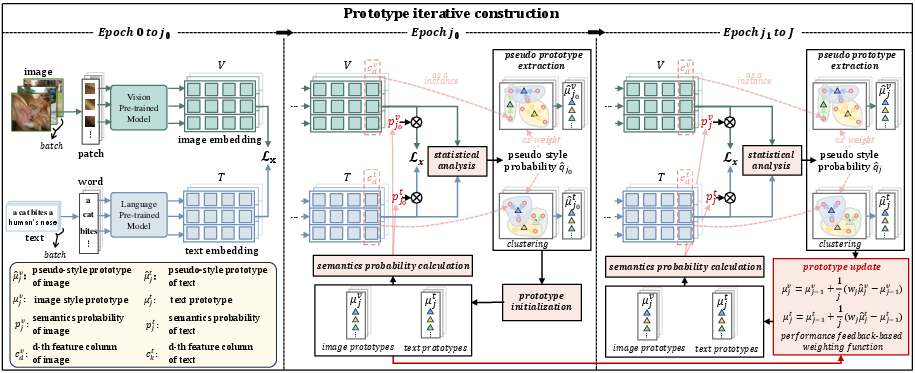
Figure 2: Prototype iterative construction process. The model refines style prototypes through iterative updates based on performance feedback.
To ensure the adaptive and meaningful weighting of prototype contributions, PICO incorporates a performance feedback-based function which assigns greater weights to prototypes that contribute positively to alignment performance improvements. This approach assures that the model is sensitive and responsive to changes in semantic prototype quality over time, thereby enhancing its overall learning curve and alignment accuracy.
Results
Extensive experimental evaluations demonstrate PICO's superior performance across various benchmarks and backbones, exhibiting improvements of 5.2\% to 14.1\% over state-of-the-art methods. This is largely attributable to PICO's effective management of non-semantic information and dynamic adaptation of semantic probabilities based on alignment performance (Table 1).

Figure 3: Images with different expression styles can correspond to the same text, demonstrating embedding of both semantic and non-semantic information.
Discussion
PICO's methodological advances offer both practical and theoretical implications for cross-modal alignment. Practically, the framework presents a robust approach to managing stylistic interference, making it highly applicable to tasks like image-text retrieval and captioning. Theoretically, it challenges existing paradigms by incorporating non-semantic considerations into alignment processes, prompting re-evaluation of how embeddings are traditionally interpreted and utilized.
Potential future developments may explore extending PICO's principles to other multi-modal tasks and refining its components for improved efficiency and scalability across larger datasets and varied domains.
Conclusion
The study presents a significant stride in reliable cross-modal alignment through prototype iterative construction, demonstrating the potential for enhanced accuracy and robustness in multi-modal embeddings by tactfully mitigating the interference of non-semantic information. As cross-modal tasks grow in complexity and variety, methodologies like PICO could become central to advancing the field and pushing the boundaries of multi-modal understanding.