PatentVision: A multimodal method for drafting patent applications
Abstract: Patent drafting is complex due to its need for detailed technical descriptions, legal compliance, and visual elements. Although Large Vision LLMs (LVLMs) show promise across various tasks, their application in automating patent writing remains underexplored. In this paper, we present PatentVision, a multimodal framework that integrates textual and visual inputs such as patent claims and drawings to generate complete patent specifications. Built on advanced LVLMs, PatentVision enhances accuracy by combining fine tuned vision LLMs with domain specific training tailored to patents. Experiments reveal it surpasses text only methods, producing outputs with greater fidelity and alignment with human written standards. Its incorporation of visual data allows it to better represent intricate design features and functional connections, leading to richer and more precise results. This study underscores the value of multimodal techniques in patent automation, providing a scalable tool to reduce manual workloads and improve consistency. PatentVision not only advances patent drafting but also lays the groundwork for broader use of LVLMs in specialized areas, potentially transforming intellectual property management and innovation processes.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Below is a consolidated list of specific knowledge gaps, limitations, and open questions left unresolved by the paper. These items are intended to guide future research and development.
- Dataset scope and generalization: The dataset is restricted to CPC code G06F; cross-domain generalization to other technical fields (e.g., mechanical, chemical, biomedical) is untested.
- Dataset availability and reproducibility: It is unclear whether the 230K sample dataset (and preprocessing scripts) will be released; reproducibility details (licenses, cleaning steps, splits) are missing.
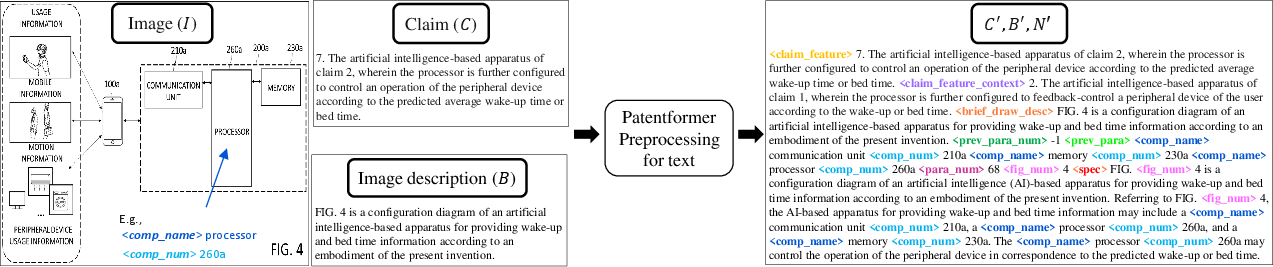
- Simulated component extraction: Component names/numbers are extracted from specification text rather than directly from images; a robust image-based pipeline (OCR for TIFF/PDF, layout analysis, symbol parsing) is not implemented or evaluated.
- Single-figure paragraph assumption: Training assumes each paragraph describes only one figure and removes cross-figure lines; impact on multi-figure reasoning and realistic drafting is unaddressed.
- Claim-to-paragraph mapping noise: The heuristic mapping (average cosine similarity + BLEU) may introduce alignment errors; no ground-truth validation or error analysis of mapping quality is provided.
- Patent-specific evaluation: Metrics are generic NLG scores; there is no assessment of claim coverage, §112 support (enablement, written description, antecedent basis), figure-reference correctness, or image-grounding fidelity.
- Human expert evaluation: No blinded, attorney-level evaluation or user study compares outputs against human-drafted specifications for legal adequacy and technical accuracy.
- Visual grounding verification: The paper does not measure whether generated text accurately describes spatial/functional relations in drawings (e.g., component numbering, connectivity); no visual-grounding or layout-aware metrics.
- Failure mode analysis: There is no systematic analysis of errors (hallucinated components, incorrect figure numbers, scope drift, added matter, incoherence across paragraphs).
- Interactive agent not realized: Chat/instruction-following capabilities are proposed but not implemented or evaluated; effects of user-in-the-loop guidance on quality and safety are unknown.
- Full specification structure: The approach focuses on figure-related paragraphs; generation of complete, legally structured sections (background, summary, detailed description, advantages, embodiments) is not demonstrated or evaluated.
- Long-document coherence: Cross-paragraph coherence across entire specifications and handling of very long contexts are not quantitatively assessed (e.g., section-level consistency, references between sections).
- Brief descriptions dependency: While removal of image descriptions (B) is tested, the method’s robustness to noisy, incomplete, or absent brief descriptions during training and in more complex figures is not analyzed.
- Image resolution trade-offs: Higher resolutions improve performance, but compute/latency/cost trade-offs and optimal resolution for production use are not characterized.
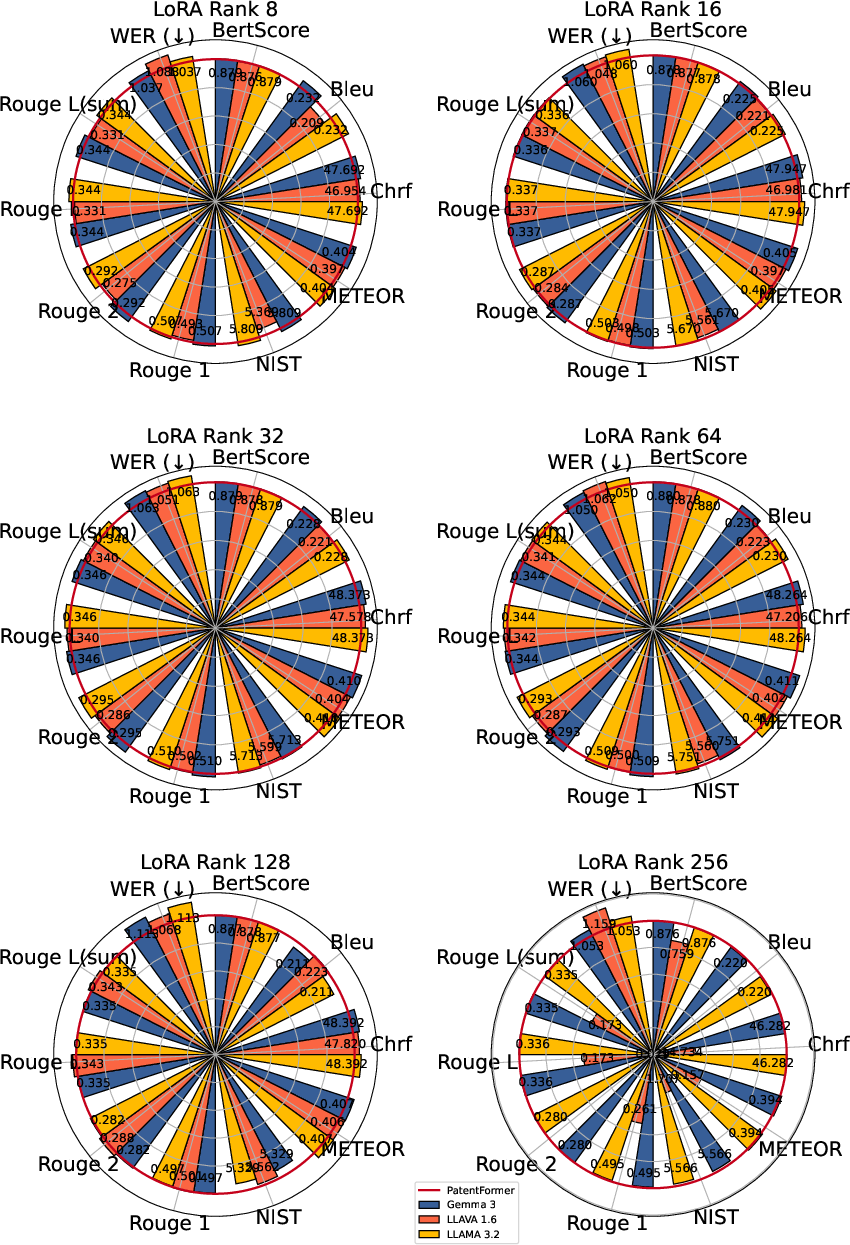
- Hyperparameter breadth: Training explores LoRA ranks and epochs but not other strategies (e.g., adapters, prefix-tuning, full fine-tuning), regularization (dropout, augmentation), or learning-rate schedules.
- Context tag ablation: The contribution of each enriched context signal (special tags for figure numbers, component names/numbers, paragraph indices) is not isolated via ablations.
- Baseline breadth: Comparisons are limited to PatentFormer; stronger baselines (modern LVLMs with instruction tuning, retrieval-augmented generation, or structured grounding) and human baselines are absent.
- Sample size and statistics: The 1,000-instance test set is sampled due to inference cost; sampling bias, statistical significance, and confidence intervals are not reported.
- Modality alignment methods: There is no integration of OCR, object detection/segmentation, or graph representations linking component numbers to image regions; approaches for improved multimodal alignment remain unexplored.
- Jurisdiction/style diversity: Generalization to other patent offices (EPO, JPO), languages, and drafting conventions/styles is not assessed.
- Drawing format robustness: Robustness to varied drawing sources (rasterized TIFF/PDF, CAD exports, scanned hand drawings) and domain-specific symbology is untested.
- Safety/legal controls: No automated constraints or validation to prevent outputs that violate §112 (e.g., added matter, indefiniteness), nor tools to flag risky content; integration of legal checkers is an open need.
- Workflow and deployment: Inference cost, memory footprint, latency, and scalability for real-world drafting workflows are not quantified; the claimed scalability remains unsubstantiated.
- Data quality and annotation: Details on expert annotation guidelines, quality control, and inter-annotator agreement are missing; potential biases in dataset construction are not analyzed.
- Prior art and novelty: The system does not incorporate retrieval of prior art or novelty constraints; risks of inadvertently echoing existing art and methods to mitigate this are not addressed.
- Instruction schema transparency: The prompt/instruction design for the interactive agent (once implemented) is unspecified, hindering reproducibility and comparative evaluation.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example.
- Ablation study: A controlled analysis that varies or removes components to assess their impact on model performance. "Ablation study"
- Autocomplete Effectiveness (AE) ratio: A metric proposed to evaluate how effectively a model can autocomplete text. "introduced the Autocomplete Effectiveness (AE) ratio"
- Bertscore: A semantic similarity metric that uses BERT embeddings to evaluate generated text against references. "Bertscore"
- Big Bird: A transformer architecture with sparse attention designed for long sequences. "Big Bird"
- BLEU score: An n-gram overlap metric commonly used to evaluate machine translation and text generation. "BLEU score"
- Chrf: A character n-gram F-score metric used to evaluate text generation quality. "Chrf"
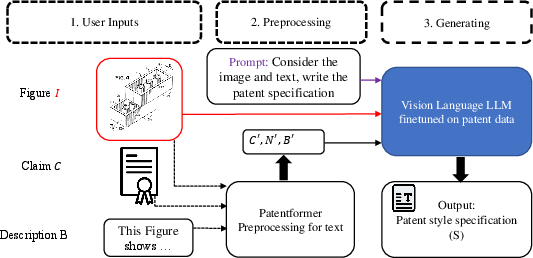
- claim+diagram-to-specification: A multimodal task mapping patent claims and associated drawings to specification paragraphs. "claim+diagram-to-specification"
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "cosine similarity"
- CPC code ('G06F'): A Cooperative Patent Classification code for electronic digital data processing. "CPC code, 'G06F'"
- Dependent claim: A patent claim that references a previous claim and adds further limitations. "dependent claim"
- Gemma 3: A large vision-LLM variant used as a base model in the framework. "Gemma 3"
- Hi-Transformer: A hierarchical transformer architecture for efficient long-document modeling. "Hi-Transformer"
- Image-Text-to-Text: A multimodal setup where images and text are inputs used to generate text outputs. "Image-Text-to-Text"
- Independent claim: A patent claim that stands alone, defining the invention without referencing other claims. "independent claim"
- Large Vision-LLMs (LVLMs): Models that jointly process visual and textual inputs to understand and generate multimodal content. "Large Vision-LLMs (LVLMs)"
- Linformer: A transformer variant that reduces self-attention complexity to linear for efficiency. "Linformer"
- LLAVA 1.6: A large vision-LLM combining a language backbone with visual encoders/adapters. "LLAVA 1.6-13B"
- LLaMA 3.2-11B: A LLM variant with 11B parameters used as a base in experiments. "LLaMA 3.2-11B"
- Longformer: A transformer designed for long documents using sliding-window and global attention. "Longformer"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique for large models. "LoRA"
- LoRA rank: The rank hyperparameter controlling the capacity of LoRA adapters during fine-tuning. "LoRA ranks"
- METEOR: A text generation evaluation metric leveraging stemming, synonyms, and alignment. "METEOR"
- NIST: An evaluation metric emphasizing informative n-grams over frequent ones for text generation. "NIST"
- Patent specification: The detailed, formal description of the invention in a patent document. "patent specifications"
- PatentFormer: A text-only model/pipeline for patent specification generation used as a baseline. "PatentFormer"
- PatentVision: The proposed multimodal framework that integrates text and images to generate patent specifications. "PatentVision"
- ROUGE: Recall-oriented metrics for evaluating text by n-gram overlap with references. "ROUGE scores (R-1, R-2, R-L, and R-Lsum)"
- Tokenizer: The component that splits text into tokens for model processing. "tokenizer of the LLM"
- USPTO: United States Patent and Trademark Office, the U.S. agency overseeing patents and trademarks. "USPTO provides patent drawings in .TIFF or .PDF formats"
- WER: Word Error Rate; a metric quantifying the error rate between generated and reference text. "WER"
Collections
Sign up for free to add this paper to one or more collections.