- The paper introduces MLBCAP, a collaborative multi-LLM framework that significantly outperforms human-written captions through robust quality assessment and selection.
- It employs a three-module approach combining quality filtering, diverse caption generation utilizing multiple models, and refined judgment for optimal caption output.
- Human evaluations confirm its effectiveness, demonstrating enhanced clarity and accessibility in conveying scientific figure information.
Multi-LLM Collaborative Caption Generation in Scientific Documents
Abstract
The task of scientific figure captioning is complex, requiring the generation of contextually appropriate descriptions of visual content. This paper introduces Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address current limitations by employing specialized LLMs for distinct sub-tasks. The approach involves a three-module framework: quality assessment to filter low-quality captions, diverse caption generation using multiple LLMs, and judgment for selecting and refining the best caption. Human evaluations demonstrate the superiority of captions produced by MLBCAP over those written by humans.
Introduction
Scientific figures are a vital component of academic communication, providing a succinct method to present complex information. Captions are crucial to elucidate visual elements, offering essential context and enhancing the comprehension of the insights a figure conveys. Automated caption generation is imperative for improving clarity and facilitating scholarly communication.
Existing methods primarily treat figure captioning as an image-to-text or text summarization task. Image-to-text approaches often miss domain-specific nuances, while text summarization methods may overlook vital visual details. Furthermore, caption quality in existing datasets, including those from arXiv, is often poor, adversely affecting model training. This paper proposes MLBCAP, which merges both textual and visual modalities.
MLBCAP addresses these challenges through a unified framework, integrating data cleaning, diverse generation, and post-editing processes. The system is designed to create both long and short caption versions, accommodating different publication requirements.
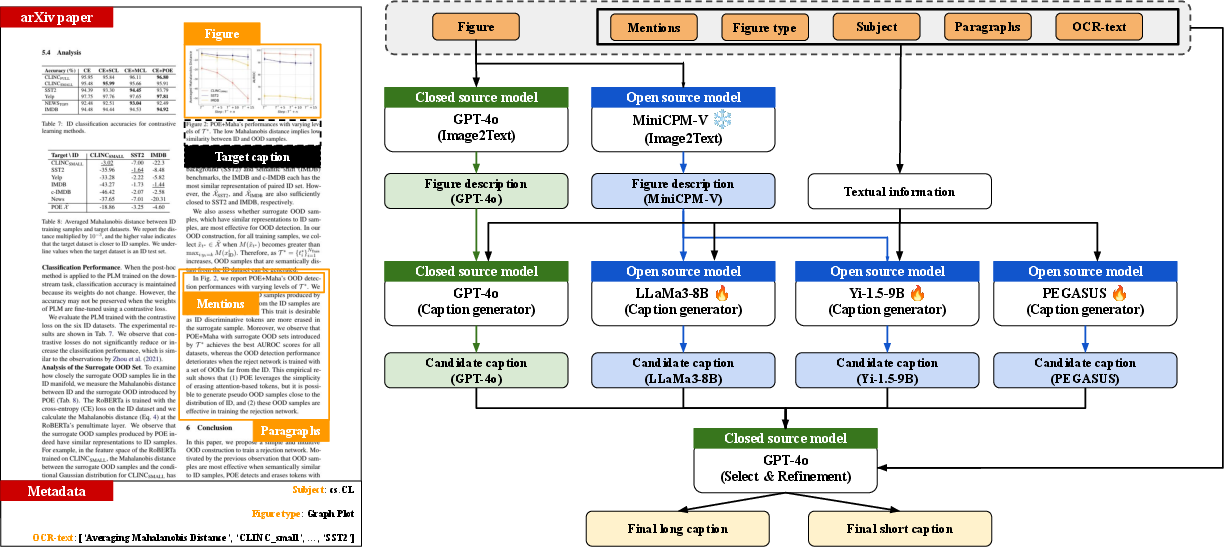
Figure 1: Overview of the collaborative framework integrating multiple LLMs for caption generation in scientific documents.
Collaborative techniques with LLMs have demonstrated exceptional task performance but are limited by model-specific biases. Ensemble approaches have been studied for selecting optimal model responses, but they have not been widely applied to figure captioning.
In scientific document captioning, previous work has developed datasets like FigureSeer and DVQA, addressing the limitations of prior models in generating relevant captions. Recent advancements have emphasized text summarization using figure-related paragraphs and OCR outputs, but these often lack visual detail integration.
Evaluation in NLG tasks typically relies on metrics like BLEU and ROUGE, although these frequently exhibit low correlation with human judgment. New approaches advocate using LLMs as reference-free metrics for better alignment with human evaluations.
Methodology
Quality Assessment
Leveraging GPT-4o, a synthetic dataset is created to assess caption quality. LLaVA, fine-tuned on this dataset, predicts caption quality across the training data, filtering the highest-rated samples. Evaluation shows significant agreement with GPT-4o's assessments.
Diverse Caption Generation
The framework employs four models: GPT-4o, LLaMA-3-8B, Yi-1.5-9B, and Pegasus. Each offers unique capabilities in caption generation, collaboratively contributing to a diverse candidate pool. GPT-4o uses few-shot prompting, while MiniCPM-V generates figure descriptions that inform caption creation, enhancing particular model outputs.
Judgment
GPT-4o selects and refines the highest-quality caption, generating both long and short versions. Expert preference for MLBCAP-produced captions is demonstrated through human evaluation, validating the superior effectiveness of this method.
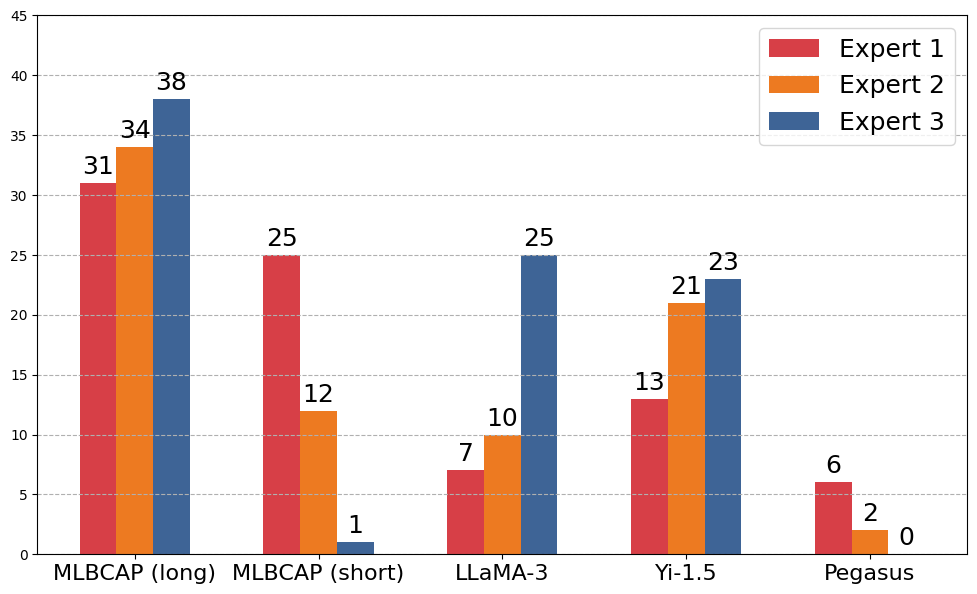
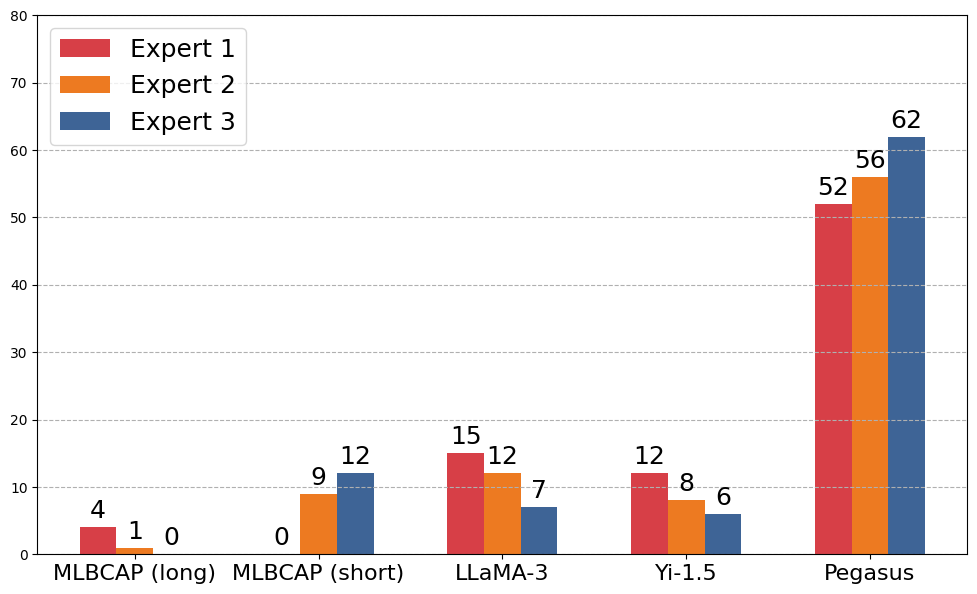
Figure 2: The human evaluation results for selecting captions based on quality. Captions generated by MLBCAP (long) are most frequently selected as high quality.
Experiments
Dataset
The study combines SciCap and SciCap+ datasets to enrich training diversification. High-quality examples undergo rigorous preprocessing, including the exclusion of suboptimal captions and deduplication.
Training Details
Training involves fine-tuning models over five epochs using techniques optimizing textual and visual inputs. Experiments utilize models such as GPT-4o, LLaVA, MiniCPM-V, LLaMA-3-8B, Yi-1.5-9B, and Pegasus.
Human Evaluation
Assessment reveals a strong preference for MLBCAP caption quality among experts, surpassing author-written captions. This reaffirmation of MLBCAP's efficacy underscores its transformative potential in scientific communication.
Conclusion
MLBCAP demonstrates a significant advancement in automatic scientific figure captioning. Through leveraging collaborative multi-LLM frameworks, it effectively integrates both textual and visual modalities. Human evaluations confirm its superiority over traditional methods in producing high-quality captions, offering a promising direction for future research and application.
In sum, MLBCAP highlights the value of integrating diverse LLM perspectives to enhance scientific document accessibility, aligning well with expert standards and preferences.

